动态主题模型 Dynamic Topic Models

动态主题模型 Dynamic Topic Models

CreateAMind
发布于 2026-06-08 14:10:46
发布于 2026-06-08 14:10:46
动态主题模型 Dynamic Topic Models
https://mimno.infosci.cornell.edu/info6150/readings/dynamic_topic_models.pdf


摘要
开发了一系列概率时间序列模型,用于分析大型文档集合中主题的时间演变。该方法是在表示主题的多项分布的自然参数上使用状态空间模型。开发了基于卡尔曼滤波和非参数小波回归的变分近似,以对潜在主题进行近似后验推断。除了提供顺序语料库的定量预测模型外,动态主题模型还为了解大型文档集合的内容提供了一个定性的窗口。通过分析《科学》(Science)杂志从1880年到2000年经过OCR(光学字符识别)处理的档案,对这些模型进行了演示。
1. 引言
管理电子文档档案的爆炸式增长需要新的工具来自动组织、搜索、索引和浏览大型集合。机器学习和统计学领域的近期研究开发了新技术,利用层次概率模型在文档集合中寻找词语模式(Blei 等,2003;McCallum 等,2004;Rosen-Zvi 等,2004;Griffiths 和 Steyvers,2004;Buntine 和 Jakulin,2004;Blei 和 Lafferty,2006)。这些模型被称为“主题模型”,因为发现的模式通常反映了组合形成文档的潜在主题。这种层次概率模型很容易推广到其他类型的数据;例如,主题模型已被用于分析图像(Fei-Fei 和 Perona,2005;Sivic 等,2005)、生物数据(Pritchard 等,2000)和调查数据(Erosheva,2002)。
在可交换主题模型(exchangeable topic model)中,假设每个文档的词语是从多项分布的混合中独立抽取的。混合比例是为每个文档随机抽取的;混合分量(即主题)由所有文档共享。因此,每个文档以不同的比例反映这些分量。这些模型是大型非结构化文档集合的一种强大的降维方法。此外,文档级别的后验推断对于信息检索、分类和主题导向的浏览非常有用。将词语视为可交换的是一种简化,这与识别每个文档内语义主题的目标是一致的。然而,对于许多感兴趣的集合,文档可交换的隐式假设是不恰当的。诸如学术期刊、电子邮件、新闻文章和搜索查询日志等文档集合都反映了不断演变的内容。例如,《科学》杂志的文章《Laborde教授的大脑》(The Brain of Professor Laborde)可能与《通过揭示潜在的皮层内连接重塑皮层运动图》(Reshaping the Cortical Motor Map by Unmasking Latent Intracortical Connections)这篇文章处于同一条科学脉络上,但1903年的神经科学研究与1991年相比看起来大不相同。文档集合中的主题随时间演变,明确地对潜在主题的动态进行建模是很有意义的。
在本文中,我们开发了一种动态主题模型,该模型捕获按时间顺序组织的文档语料库中主题的演变。我们通过分析《科学》杂志100多年来经过OCR处理的文献来证明其适用性,该杂志由托马斯·爱迪生于1880年创立并一直出版至今。在该模型下,文章按年份分组,每年的文章源于一组从上一年的主题演变而来的主题。
在随后的章节中,我们扩展了经典的状态空间模型,以指定主题演变的统计模型。然后,我们开发了高效的近似后验推断技术,用于从顺序文档集合中确定不断演变的主题。最后,我们展示了定性结果,证明动态主题模型如何允许以新的方式探索大型文档集合;并展示了定量结果,证明与静态主题模型相比,其具有更高的预测精度。
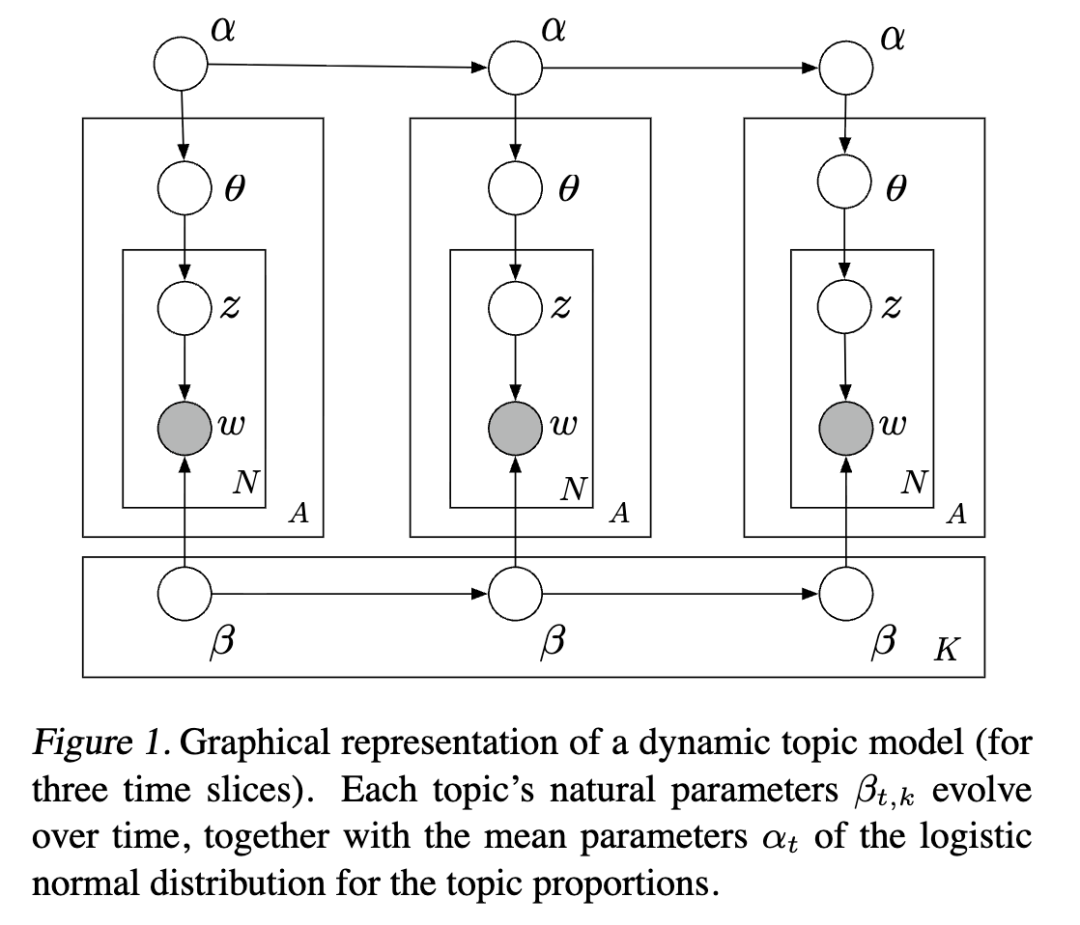
2. 动态主题模型
虽然传统的时间序列建模一直关注连续数据,但主题模型是专为分类数据设计的。我们的方法是在潜在主题多项式的自然参数空间上,以及在用于建模文档特定主题比例的对数正态分布的自然参数上使用状态空间模型。

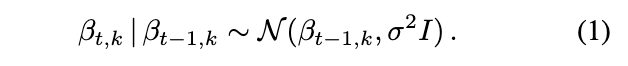
因此,我们的方法是通过在动态模型中链式连接高斯分布,并将生成的值映射到单纯形,从而对成分随机变量序列进行建模。这是对逻辑正态分布(Aitchison, 1982)在时间序列单纯形数据(West and Harrison, 1997)上的扩展。


3. 近似推断
在自然参数上处理时间序列使得能够使用高斯模型来描述时间动态;然而,由于高斯模型和多项分布模型之间的非共轭性,后验推断是难以处理的。在本节中,我们提出一种用于近似后验推断的变分方法。我们使用变分方法作为随机模拟的确定性替代方案,以便处理文本分析中典型的大型数据集。虽然吉布斯采样(Gibbs sampling)已有效地用于静态主题模型(Griffiths and Steyvers, 2004),但非共轭性使得采样方法对于这种动态模型更加困难。

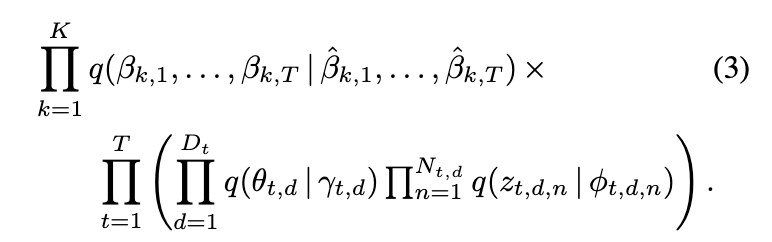

3.1. 变分卡尔曼滤波

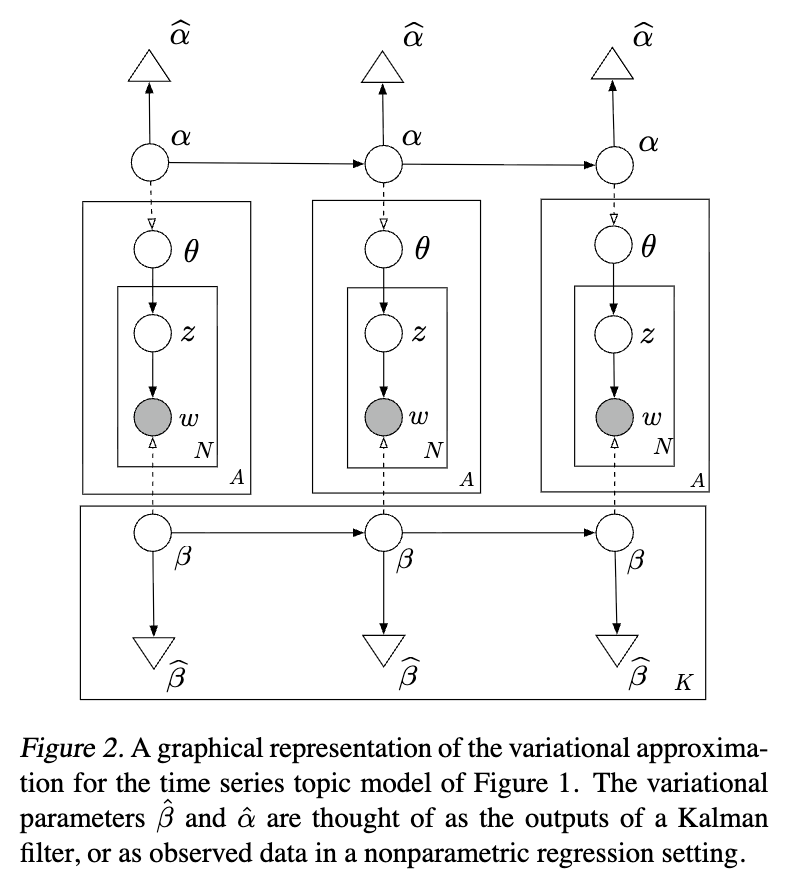

3.2. 变分小波回归


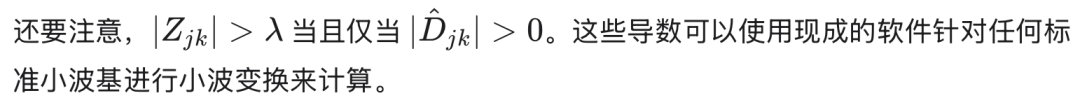
运行此算法和卡尔曼变分算法以近似一元语法模型(unigram model)的示例结果如图3所示。这两种变分近似都平滑了一元语法计数中的局部波动,同时保留了可能表明期刊内容发生显著变化的尖锐峰值。虽然拟合结果与使用标准小波回归对(归一化)计数进行拟合的结果相似,但这些估计值是通过最小化 KL 散度获得的,这与标准变分近似中的做法一致。
在第2节的动态主题模型中,算法本质上与上述描述的相同。然而,我们不是根据真实观测计数来拟合观测值,而是根据公式(3)中文档级变分分布下的期望计数来拟合它们。
4. 《科学》杂志的分析
我们分析了来自《科学》(Science)杂志的30,000篇文章的一个子集,涵盖了1881年至1999年这120年间每年的250篇文章。我们的数据由JSTOR (www.jstor.org) 收集,这是一个非营利组织,它通过在原始印刷期刊上运行光学字符识别(OCR)引擎来维护一个在线学术档案库。JSTOR 对生成的文本建立索引,并通过关键词搜索提供对原始内容扫描图像的在线访问。
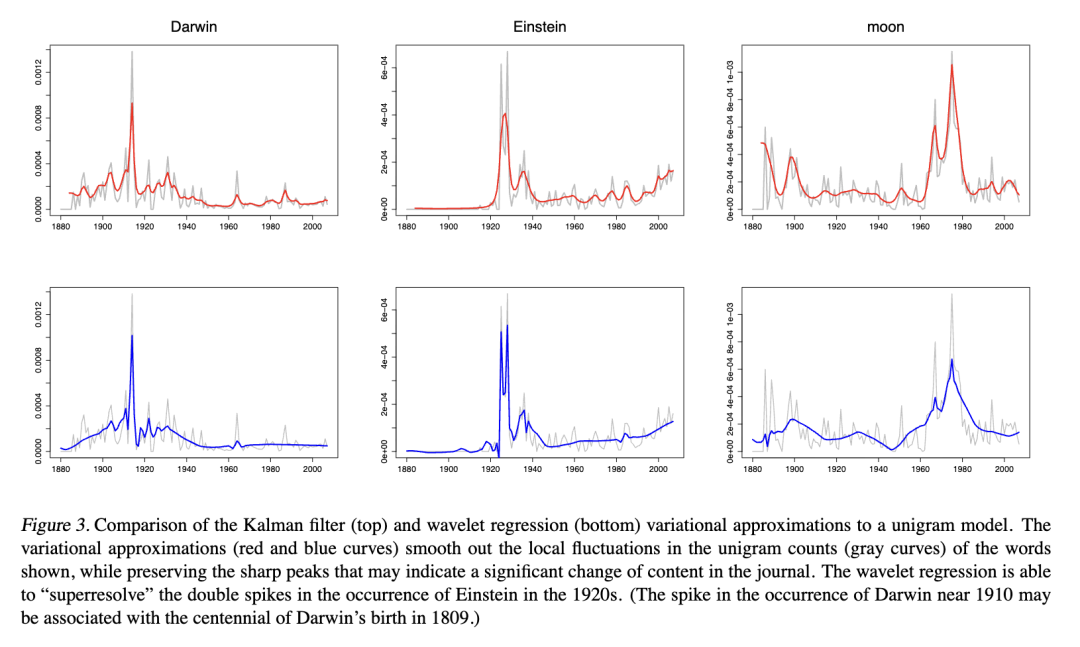
我们的语料库由大约750万个单词组成。我们通过将每个词提取词干至其词根、去除功能词以及去除出现次数少于25次的词来修剪词汇表。总词汇量为15,955。为了探索该语料库及其主题,我们估计了一个包含20个分量的动态主题模型。在一台1.5GHz PowerPC Macintosh笔记本电脑上,后验推断大约花费了4小时。图4展示了其中两个结果主题,根据使用卡尔曼滤波变分近似估计的后验平均出现次数,显示了这些主题在每十年中的前几个词。图中还展示了几十年来体现这些主题的示例文章。如图所示,该模型捕捉到了不同的科学主题,并可用于检查其中词语使用的趋势。
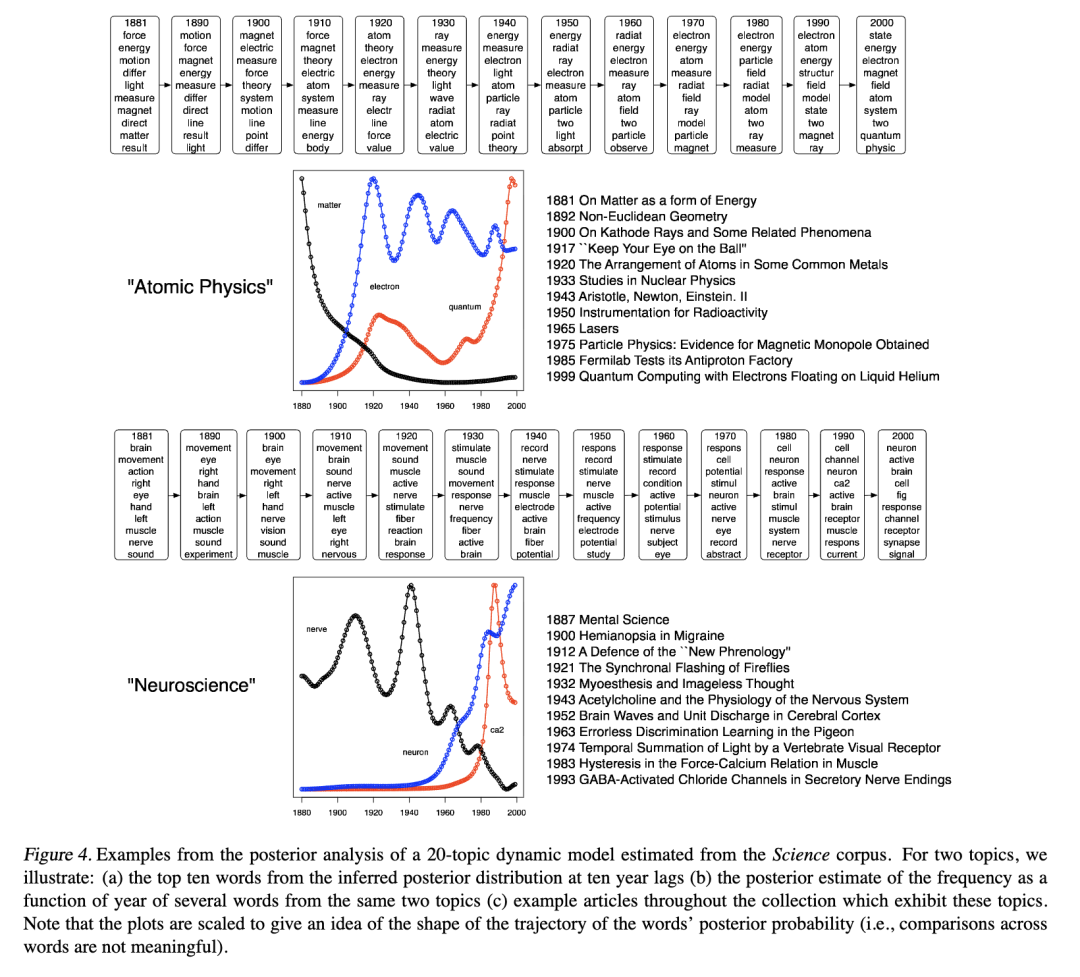
为了定量验证动态主题模型,我们考虑了根据往年所有文章预测《科学》杂志下一年内容的任务。我们比较了三种20主题模型的预测能力:根据往年所有数据估计的动态主题模型、根据往年所有数据估计的静态主题模型,以及仅根据前一年数据估计的静态主题模型。所有模型均估计至相同的收敛标准。根据所有往年数据估计的主题模型和动态主题模型在同一点进行初始化。
动态主题模型表现良好;与其他两个模型相比,它总是赋予下一年的文章更高的似然值(图5)。有趣的是,每种模型的预测能力随年份推移而下降。我们可以暂时将其归因于科学语言专业化程度的提高。
原文链接:https://mimno.infosci.cornell.edu/info6150/readings/dynamic_topic_models.pdf
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号