Nat. Commun. | 面向可解释生物医学图像分析的通用基础模型

Nat. Commun. | 面向可解释生物医学图像分析的通用基础模型

DrugAI
发布于 2026-06-08 14:16:31
发布于 2026-06-08 14:16:31
随着人工智能逐渐进入临床实践,生物医学图像分析不仅需要高准确率,更需要能够向医生清晰展示诊断依据。然而,目前大多数医学视觉语言模型虽然能够生成诊断结论,却无法准确指出结论对应的病灶区域;而现有分割模型虽然能够定位病变,却无法生成具有临床意义的诊断描述。这种“能解释但不能定位”或“能定位但不能解释”的割裂状态,成为医学AI落地的重要障碍。
研究人员提出了UniBiomed,这是首个面向“可溯源生物医学图像解读(Grounded Biomedical Image Interpretation)”的通用基础模型。该模型创新性地融合多模态大语言模型与Segment Anything Model,实现诊断描述生成与病灶区域分割的统一建模。研究团队构建了包含2700万组图像—区域标注—文本描述三元组的大规模训练数据集,覆盖10种生物医学成像模态。在70个内部数据集和14个外部数据集上的大规模验证表明,UniBiomed在图像分割、疾病识别、区域感知诊断、视觉问答以及报告生成等任务上均达到当前最佳性能。研究结果显示,该模型能够同时提供诊断结论及其视觉证据,为更可信、更可解释的医学人工智能系统奠定基础。

近年来,多模态人工智能推动了医学影像分析的快速发展。CT、MRI、超声、病理切片以及眼底图像等生物医学图像蕴含丰富的解剖结构和病理信息,而医生撰写的诊断报告则提供了对这些视觉信息的高级语义解释。理论上,将视觉与语言信息进行深度融合,能够帮助AI系统实现接近临床专家水平的综合判断。
然而,现有模型大多存在明显局限。一类模型专注于图像分割,能够准确勾画器官、病灶或细胞区域,但无法给出诊断解释;另一类视觉语言模型则能够生成疾病诊断和医学报告,却难以指出其判断依据来自图像中的哪些区域。这导致医生无法验证模型结论是否建立在正确的视觉证据之上,从而影响临床可信度。
研究人员认为,真正可用于临床实践的医学AI系统应同时具备两项能力:能够生成准确诊断结果,并能够同步定位对应病灶区域。这种同时生成诊断描述和视觉定位结果的能力被称为“Grounded Interpretation(可溯源解读)”。为此,他们开发了UniBiomed,希望建立统一框架,实现从细胞到器官尺度的可解释医学图像分析。
方法
UniBiomed建立在多模态大语言模型(MLLM)与Segment Anything Model(SAM)的深度融合之上。系统首先利用视觉编码器和大语言模型分析输入图像及用户指令,生成诊断描述和医学解释;随后将模型生成的语义信息与用户指令共同编码为语言提示,引导SAM对对应的病灶区域进行精确分割。
为了支持统一训练,研究人员构建了覆盖CT、MRI、X光、超声、病理图像、眼底图像等十种成像模态的超大规模数据集。所有数据被转换为统一的视觉问答格式,使模型能够在同一框架下学习图像分割、疾病识别、视觉问答、区域分类和报告生成等任务。通过联合训练,模型不仅能够学习视觉定位能力,也能够获得丰富的医学知识和诊断推理能力,从而实现真正意义上的可溯源医学图像解读。
结果
构建首个通用可溯源生物医学图像基础模型
研究人员首先构建了覆盖十种成像模态的训练体系。整个数据集包含2700万个图像—文本—区域标注三元组,是目前规模最大的生物医学可溯源解读数据资源之一。
这些数据不仅包含传统分割掩码和边界框标注,还配套丰富的诊断描述、医学知识和临床报告。通过统一的VQA格式组织数据,不同任务能够在同一个模型中协同训练。
这种统一训练策略使得分割任务能够提升疾病识别能力,而视觉问答和报告生成任务则进一步增强模型的语义理解能力,形成多任务互相促进的学习机制。
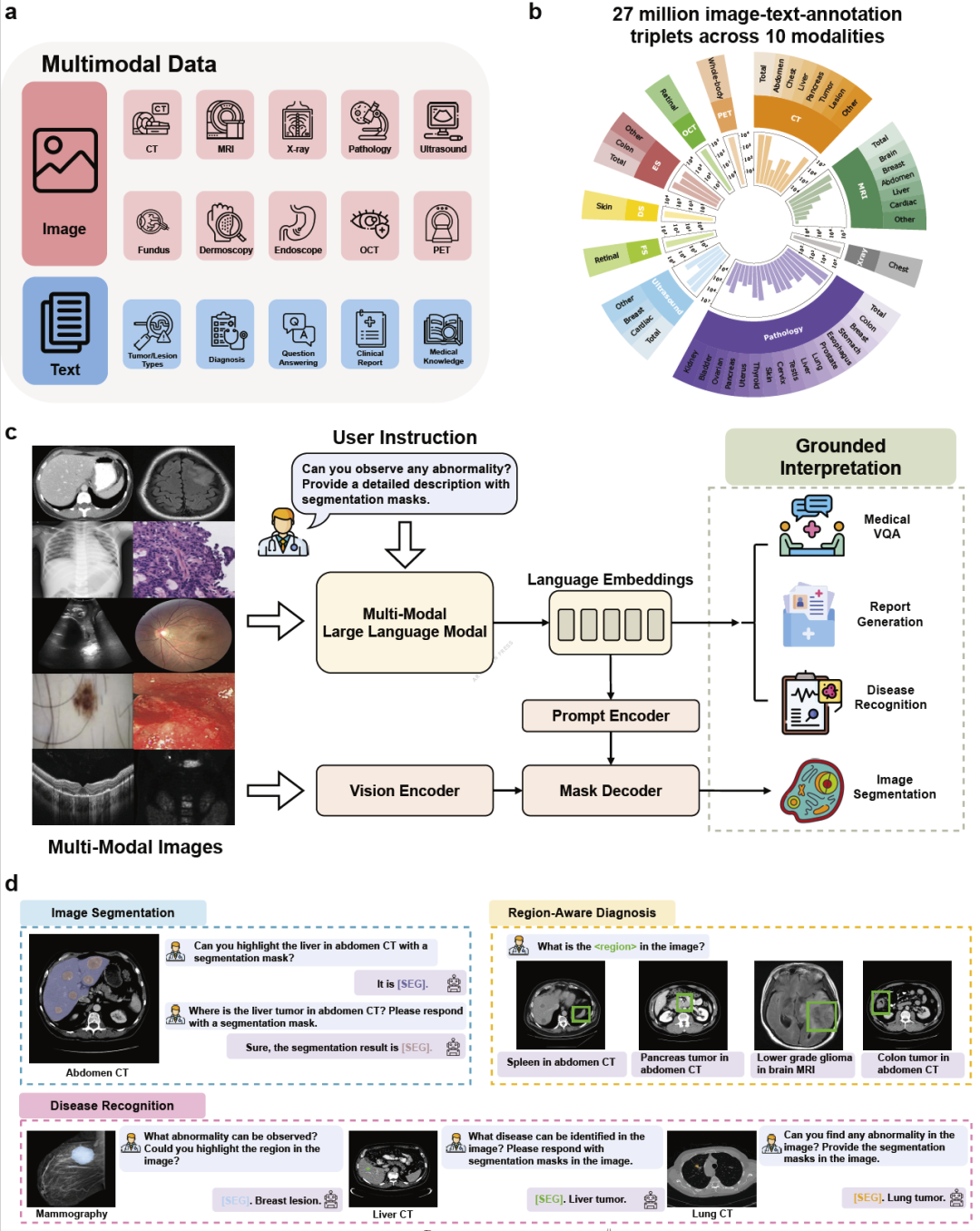
图1: UniBiomed总体框架与2700万规模生物医学可溯源解读数据集构建流程。
在生物医学图像分割任务中达到新的性能纪录
研究人员在46个内部数据集和14个外部数据集上,将UniBiomed与MedSAM、SegVol、SAT以及BiomedParse等代表性基础模型进行了系统比较。
结果显示,UniBiomed在60个数据集上的平均Dice得分较此前最先进模型BiomedParse提高10.25个百分点。在内部验证集和外部验证集上,性能提升分别达到9.13%和13.95%。
研究人员进一步分析发现,性能提升的重要原因在于UniBiomed能够同时利用分割数据、视觉问答数据和报告生成数据进行训练,而现有分割模型通常仅依赖分割标注数据。这使得模型获得更具泛化性的视觉表示能力,并能够适应不同成像模态和疾病类型。
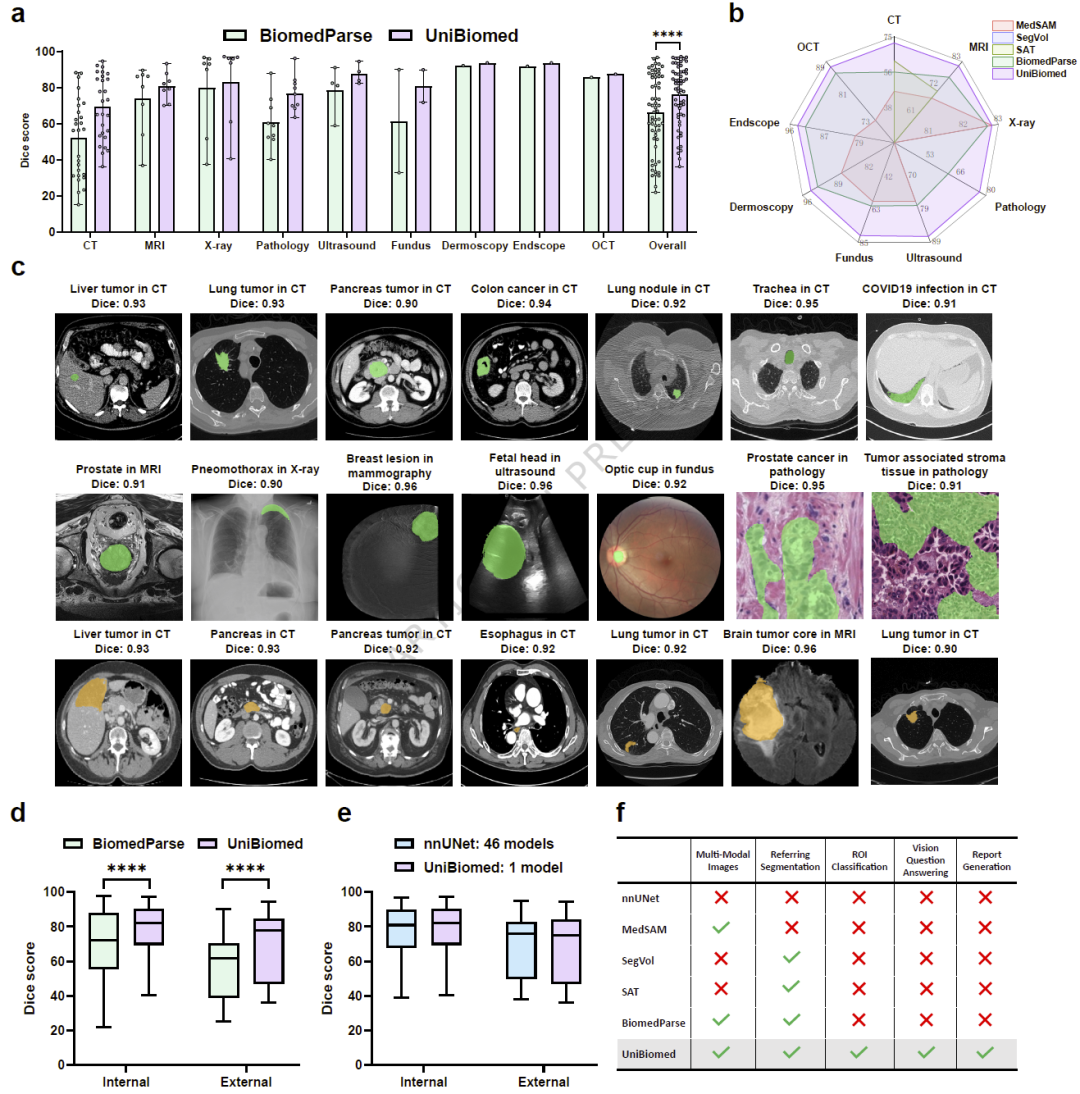
图2: UniBiomed与主流生物医学分割基础模型在60个数据集上的性能比较。
实现端到端疾病识别与病灶定位
疾病识别是医学视觉问答中的核心任务之一。然而现有医学大模型通常只能输出疾病名称,却无法指出病变所在位置。
为解决这一问题,研究人员提出“Grounded Disease Recognition(可溯源疾病识别)”任务,要求模型同时完成疾病分类和病灶分割。
研究团队构建了覆盖15类异常病变的数据集,包括肝癌、肺癌、胰腺肿瘤、脑肿瘤、乳腺病变、新冠肺炎感染以及视网膜病变等。实验结果显示,UniBiomed在病灶分割Dice和疾病识别准确率两个指标上均优于LISA和GLaMM等先进方法。其中疾病识别准确率提升3.29%,分割性能提升3.86%。
更重要的是,UniBiomed无需医生提前告诉模型病变类型,也无需人工提供病灶框选提示,即可自动完成病灶识别和定位,实现真正的端到端诊断流程。
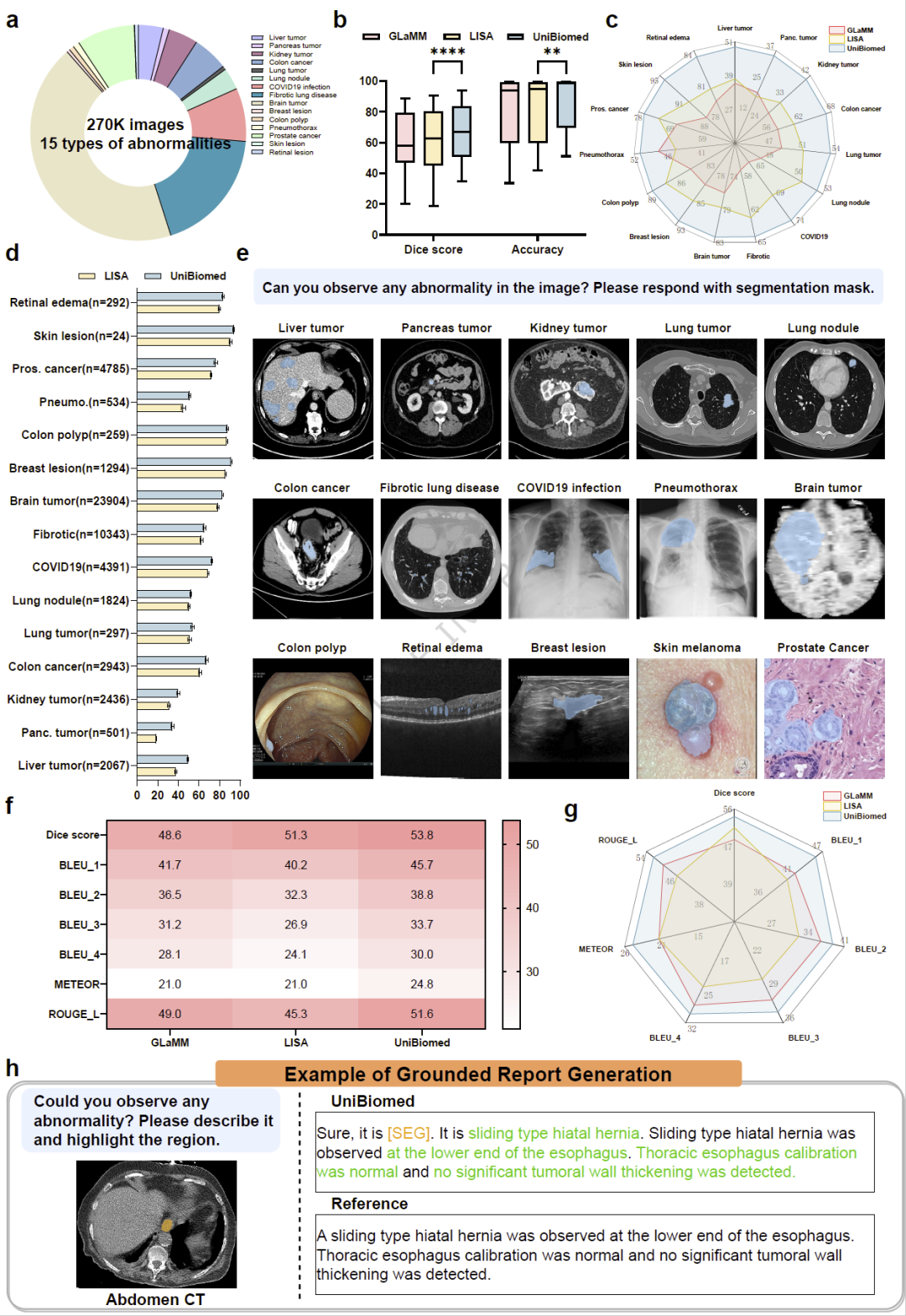
图3: UniBiomed在可溯源疾病识别任务中的表现及15类异常病变验证结果。
实现可溯源医学报告生成
研究人员进一步验证模型在Grounded Report Generation(可溯源报告生成)任务中的能力。该任务要求模型不仅生成完整临床报告,还需同步标注报告中所涉及的解剖结构或病灶区域。
在RadGenome数据集上的实验表明,UniBiomed同时获得最高的分割性能和报告生成性能。无论是BLEU、METEOR还是ROUGE指标,均超过现有医学视觉语言模型。研究人员认为,这种统一生成视觉证据与诊断描述的能力,使AI报告更容易被医生审核和验证,从而增强临床可信度。
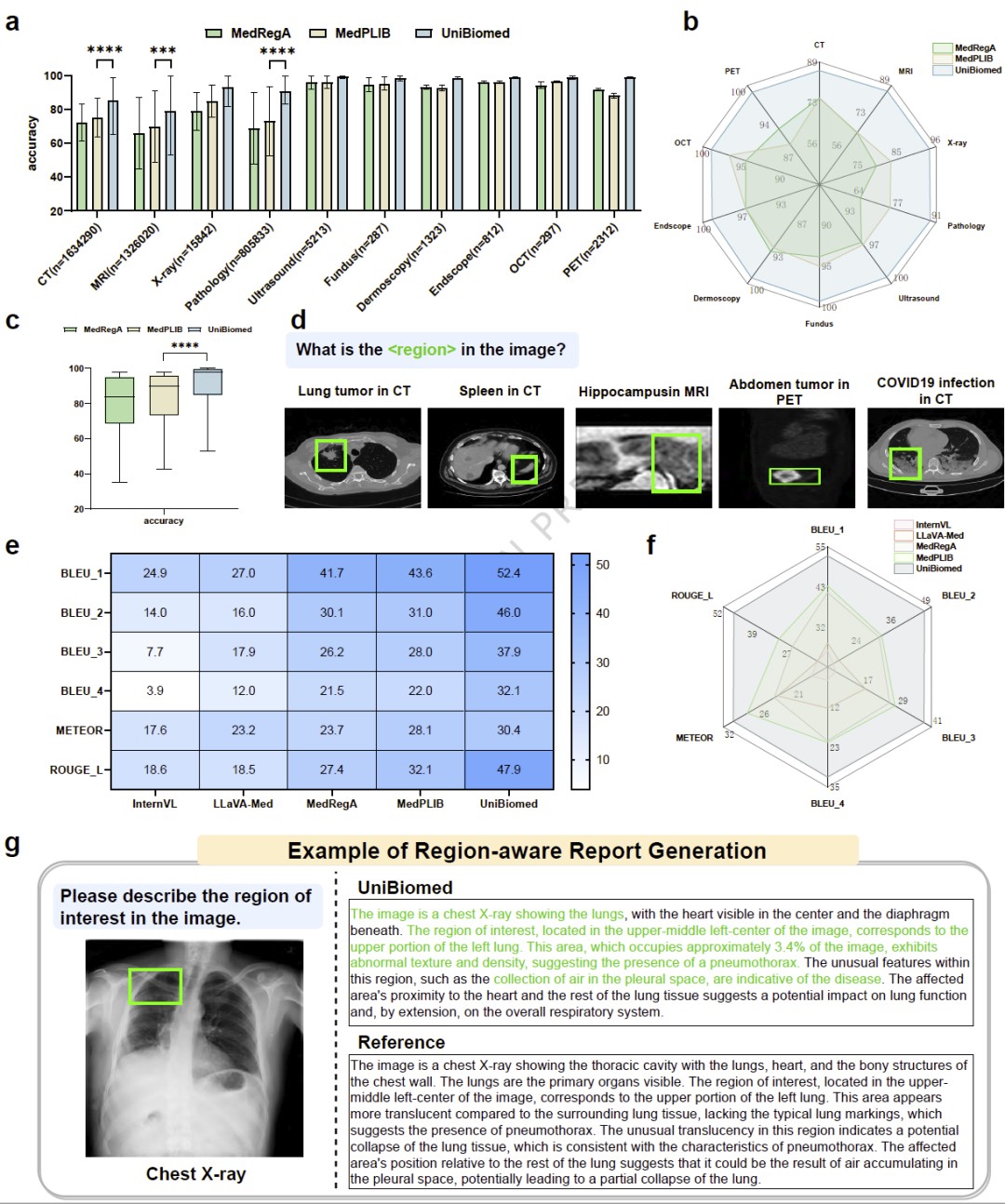
图4: UniBiomed在可溯源医学报告生成任务中的性能与典型案例。
显著提升区域感知诊断能力
为了评估模型对局部区域的理解能力,研究人员进一步测试了ROI分类和区域报告生成任务。在十种不同成像模态上,UniBiomed获得93.38%的平均分类准确率,相比此前最佳模型提升8.32个百分点。
在MedTrinity大规模区域诊断基准上,模型生成的区域报告质量也明显优于现有方法。系统不仅能够准确识别指定区域中的病变类型,还能够自动生成详细病理描述。
案例分析显示,无论是前列腺病理切片、胸部X线还是CT图像,模型均能够准确理解区域内容并生成符合临床表达习惯的诊断文本。
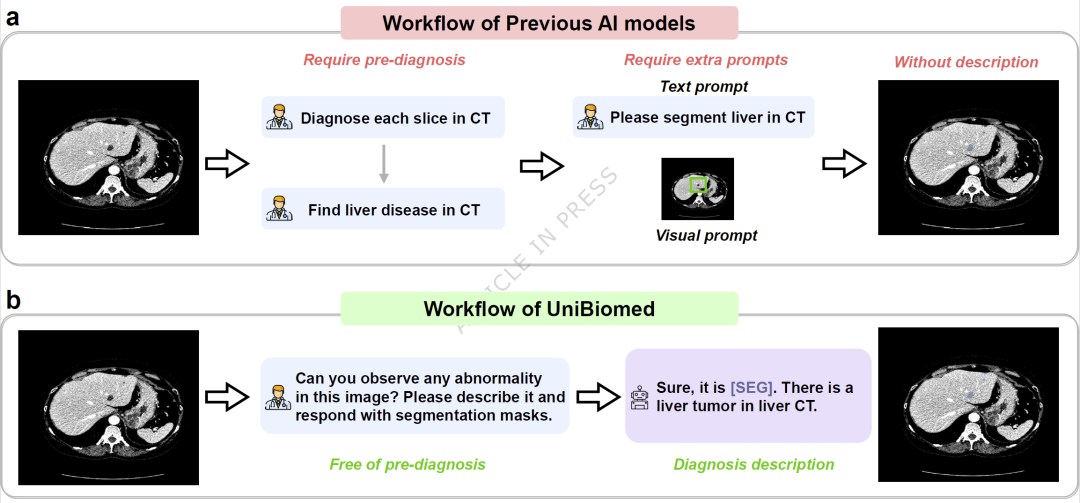
图5: UniBiomed在ROI分类与区域感知报告生成任务中的表现。
推动医学影像分析流程变革
研究人员进一步评估了UniBiomed对临床工作流程的影响。
传统医学分割模型通常需要医生首先浏览全部影像,确定病灶位置,然后输入文本提示或手工绘制边界框,引导模型完成分割。相比之下,UniBiomed只需输入统一指令,即可自动完成异常检测、病灶定位和诊断解释。
在肺癌、肝癌和胰腺癌CT扫描的阅读测试中,放射科医生认为UniBiomed明显减少了人工交互步骤,提高了分析效率,并更符合真实临床工作流程。研究人员认为,这种从“辅助分割工具”向“自动诊断助手”的转变,代表了医学人工智能发展的重要方向。
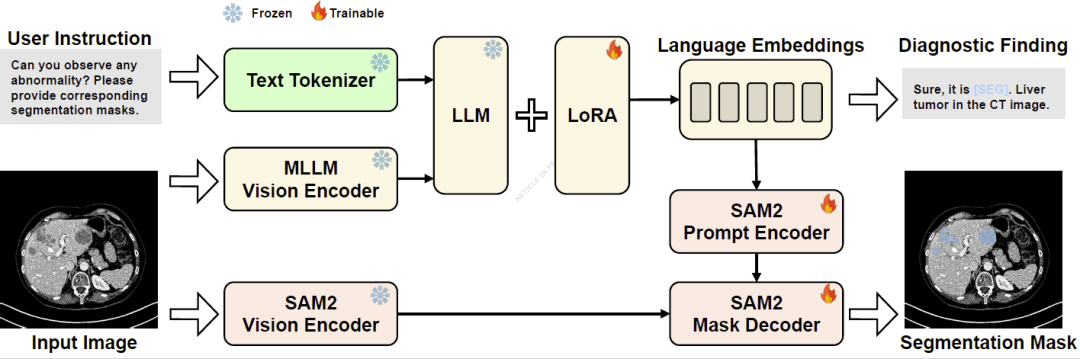
图6: UniBiomed驱动的端到端医学影像分析流程及临床应用场景。
讨论
研究人员提出了UniBiomed这一面向可溯源生物医学图像解读的通用基础模型,实现了诊断描述生成与病灶定位的统一建模。与现有医学大模型只能回答问题或生成报告不同,UniBiomed能够同步提供视觉证据和语言解释,使模型决策过程更加透明和可信。
研究结果表明,统一训练是模型成功的重要原因。通过联合利用图像分割、视觉问答、区域诊断和报告生成等多种数据资源,UniBiomed获得了更强的泛化能力,并在84个数据集上展现出优异性能。特别是在疾病识别、区域感知诊断和报告生成等复杂任务中,模型均实现了显著突破。
研究人员同时指出,目前模型对于极罕见疾病仍然受限于标注数据规模,未来需要持续扩充数据集并加强真实临床环境验证。此外,如何将通用基础模型与医学智能体系统结合,也将成为下一阶段的重要研究方向。
整理 | DrugOne团队
参考资料
Wu, L., Nie, Y., He, S. et al. A universal foundation model for grounded biomedical image interpretation. Nat Commun (2026).
https://doi.org/10.1038/s41467-026-73986-1

内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号