Claude 递归自迭代 - 研发系统的AI自动化序章启幕


这不是奇点爆发,而是研发系统工程自动化的开端
昨天读到Anthropic 这篇《When AI builds itself》让人眼前一亮,很符合当下使用agent工具的体验,这篇文章不是它把 recursive self-improvement 这个老词又拿出来讲了一遍,而是它原本常略带科幻色彩叙事转移到实际的研发工程中:代码由谁执行,实验是谁跑的,计划如何调整,出错经验如何总结,下一代模型的改进回路如何自动化构建和推进。
把“AI build itself”想象成某天模型突然宣布“我要重写自己”,也并不是这篇文章想表达的,现实里的递归自改进更像一个增量迭代替换的过程:研发循环中的每个接口,先被模型接管 30%,再接管 80%;每次接管都缩短下一轮模型迭代的周期。而这个迭代过程中对研发岗位无疑是影响深远的,最后能够剩下的能力不是“会不会写代码”,而是让你的自迭代系统具备这样的能力:会不会选择值得投入的方向,并让评估不是自己骗自己(目前的coding agent时有发生),实现打通整个研发流程的“选方向-执行-测试-上线-迭代”全流程自动化。
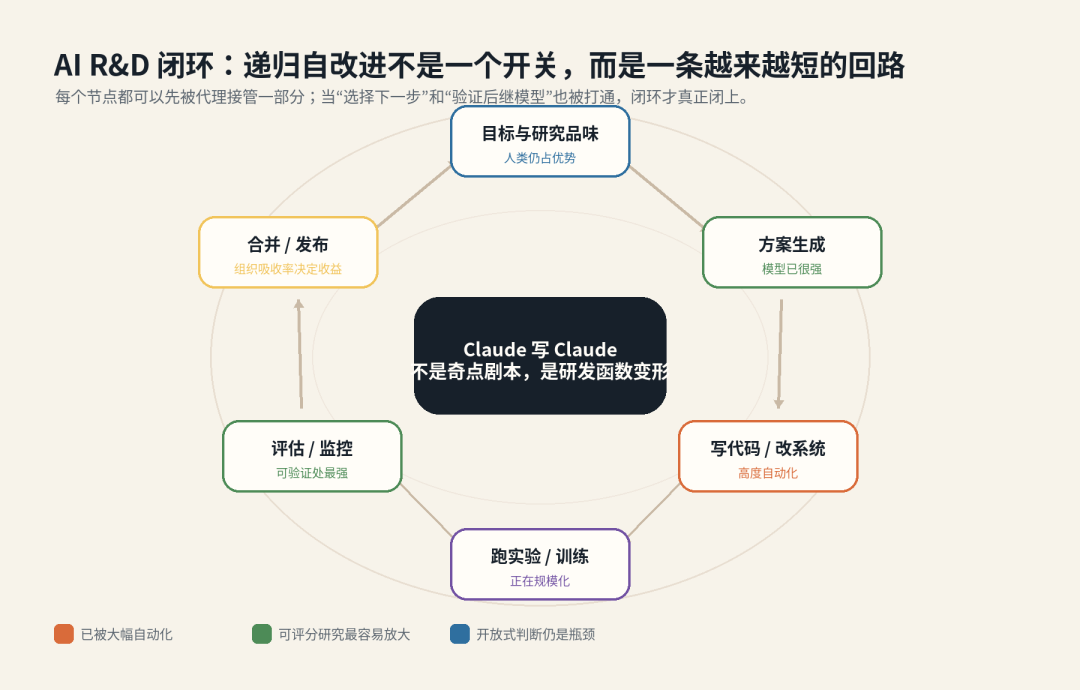
AI 研发正在从“人类使用工具”变成“人类给一个自动化研发系统设约束”。完整 RSI 还没发生,Anthropic 这篇文章也没有说它已经发生。但它展示的趋势已经足够改变我们对 agent、自主化和模型研发节奏的短期预期想象,传统的奇点叙事里的 RSI 常常像一道门:门开之前没有发生,门开之后能力爆发。研发过程里的 RSI 更像一组阀门:代码阀门、实验阀门、评估阀门、数据阀门、部署阀门依次被拧开。
RSI 在agent场景的真实映射
传统 RSI 讨论通常从 Good 的“超智能机器能够设计更好的机器”开始,后来被概括为:一个智能系统提升自身能力,提升后的系统又更擅长继续改进自身,从而形成可能加速的能力反馈环。这个定义抓住了 intelligence explosion 的核心,但放到今天的 AI 工程实践中,会遇到一个边界问题:现代 AI 的“自身”并不只等于模型权重。它还包括 agent scaffold、代码库、数据管线、训练系统、评估系统、工具环境和部署反馈。在当下背景下重新理解的 RSI,不是一个模型在任意环境中修改和提升自己,而是 AI 逐步接管 AI 研发闭环中越来越多的环节,在agent环境中实现递归式子迭代。

展开来讲,当下的RSI 问题,已经不能再被压缩成“一个模型是否会修改自己的权重”的问题。模型 agentic 化让模型开始进入行动环节,agent 产品化则把这些行动能力嵌入真实研发系统。二者叠加之后,RSI 里的“自身”不再是一个封闭模型,而是一条被 AI 持续介入的研发闭环。当下前沿 AI 系统不再只是基础模型,而是模型、代码库、工具环境、长上下文、记忆、评估器、数据管线、训练系统、部署监控和人工治理共同组成的研发闭环。模型生成想法,coding agent 修改代码,terminal/browser 执行和检索,测试与评估系统筛掉坏路径,监控和红队暴露真实风险,数据与训练管线把反馈沉淀为下一轮能力,review、merge、rollback 和 incident 机制则控制改进进入生产系统的速度与边界。
这意味着,RSI 的现代形态不是“模型作为一个封闭实体自我复制、自我升级”,而是 AI 逐步嵌入并自动化 AI 研发系统本身。影响子迭代系统的变量也在快速变化,不再只是模型智力有多强,而是研发闭环里有多少环节可以被 AI 独立完成,反馈是否足够可靠,失败是否可以持续学习,人类是否仍掌握目标设定和风险裁决权。
在这个视角下,自我改进不必从“模型直接改自己权重”开始。它可以先发生在外围:agent 改自己的脚手架,模型生成更好的评估器,自动化研究员搜索更好的训练配方,Claude 写进 Anthropic 自己的代码库。
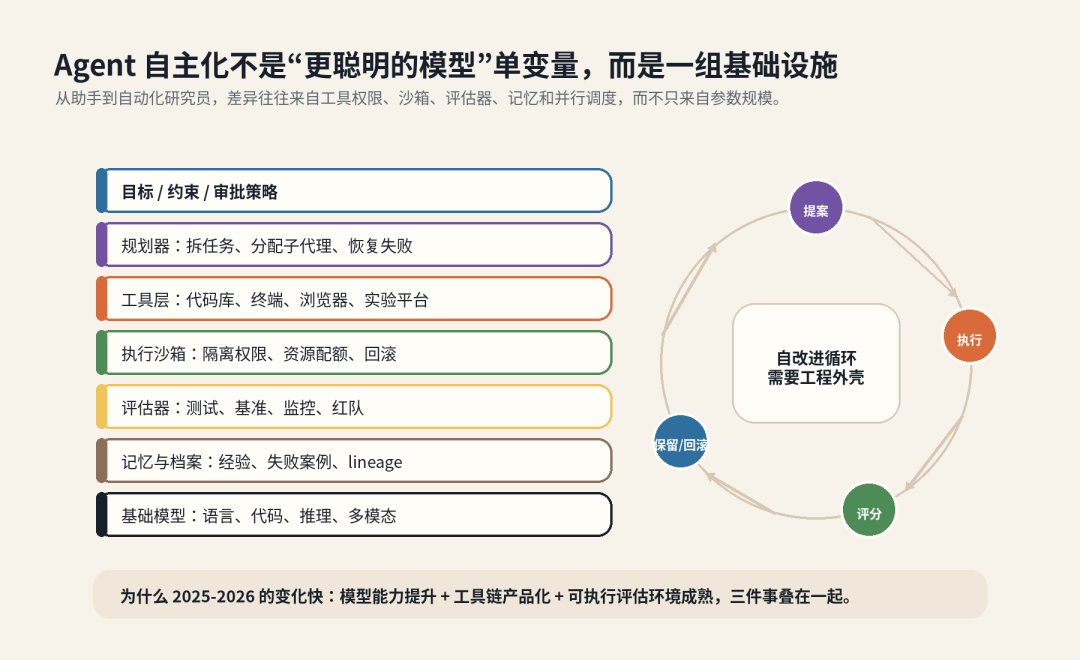
在agent应用场景场景下,模型从输出建议进入执行环境,agent 从单次任务进入长时任务流程,评估从人工判断进入自动化验证,工程师从直接执行转向设定任务边界和验收标准。AI 研发系统的边界正在向外扩张,系统里的可变部分也越来越多,而自动化往往涉及到人与AI的能力交接和职责变化。
先看代码曲线:8 倍不是重点,瓶颈迁移才是重点
我们先来看一下Anthropic这篇文章提到内部AI coding的真实使用效用数据,截止到 2026 年 5 月,合并进 Anthropic 代码库的生产代码中超过 80% 由 Claude 编写;2026 年第二季度,工程师每日合并代码行数达到 2024 年水平的大约 8 倍。但文章也指出,代码行数不等于软件价值,AI 可能写出更多冗余代码,review 方式也发生了变化。
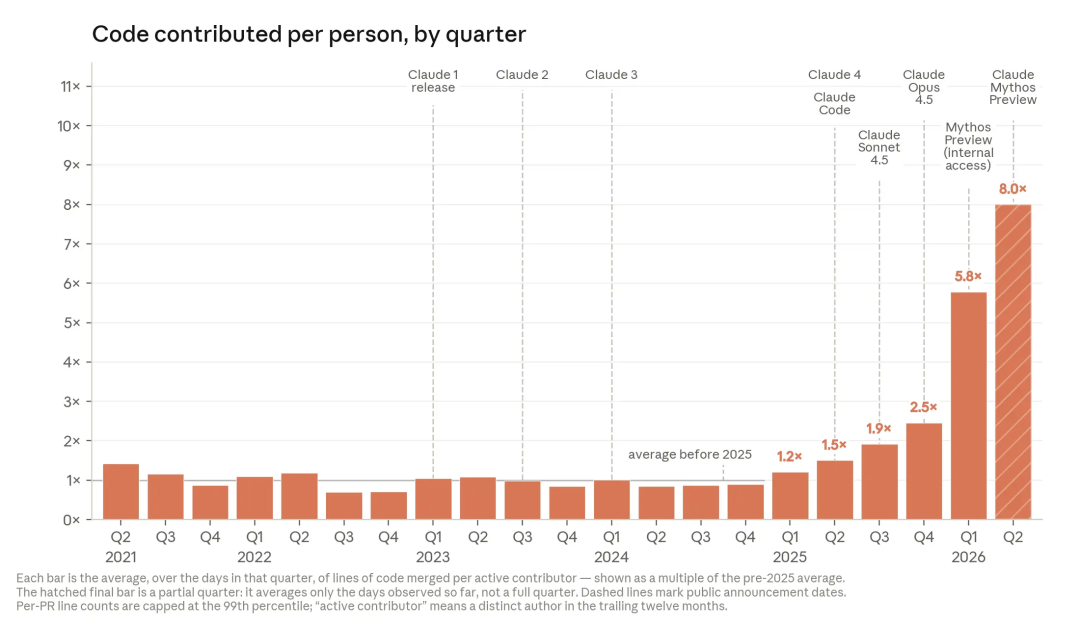
代码量的变化只是浮在水面上的部分。Claude Code 出现后,软件研发流程已经发生了明显变化:读仓库、改代码、跑测试,不再只是工程师在 IDE 和终端之间来回切换的手工动作,而被压缩成了 agent 可以连续执行的一段流程。更长时程的 agents 引入之后,任务颗粒度继续放大。工程师不再盯住每一个局部动作,注意力开始转向目标是否清楚、边界是否收得住、实现路线是否偏航、测试是否覆盖风险。
review 的性质也随之改变。过去 review 很多时候是在看一段代码有没有明显问题;现在 review 开始变成对一条 agent 轨迹的审查:它为什么选这条实现路线,遗漏了哪些边界条件,测试是不是只覆盖了 happy path,回滚方案是否可靠。工程师也不再只是沿着一条主线往前写代码,而是可以同时打开几条 agent 分支,让它们在不同假设下推进,再把人的判断力放在比较、收敛和裁决上。

Amdahl 定律在这里也给了一个朴素解释。如果写代码和跑测试占研发时间的 60%,而 agent 让这部分快 10 倍,整体速度会明显提升,但不会无限提升。随后实验执行、数据清洗、review、部署和监控继续被加速,瓶颈会继续往人类参与的具体节点移动。最终留下来的,是很难并行、很难写成测试、也很难交给单一分数的判断,例如方向选择、价值判断、风险承担等。
所以 Anthropic 内部数据不仅仅是其内部效率变化的验证实例,同时也在揭示:前沿实验室的研发系统正在从人类串行执行,变成人类监督agent并行执行。 这会改变模型迭代速度,也会改变系统处理错误的方式。
长时程任务:从 benchmark 分数到“代理能走多远”
Anthropic是对当前coding agent狂奔发展的映射,但放眼整个agent行业,也呈现同样的发展趋势。METR 的 time horizon 系列把 agent 能完成的任务,按人类专家完成该任务所需时间来标尺化。它的 2025 年研究估计,前沿 AI 在可完成任务长度上的 50% 可靠性时长过去几年以约 7 个月翻倍;到 2026 年,METR 也做了进一步更新:这个指标不是“AI 能连续自主工作这么久”,而是任务难度标尺,可靠部署还要看更高成功率、任务混乱度和人类接管成本。
Anthropic 对长时程能力的判断,不是普通 benchmark 分数又涨了一截,而是模型能够连续推进真实软件任务的时间正在变长。文章用 Claude Opus 4.6 能完成约 12 小时级软件任务作为一个截面,并估计近期这类能力的增长速度可能接近每 4 个月翻倍。这里的“翻倍”不是说模型整体智能每 4 个月翻倍,而是说它能稳定承担的软件任务时长在快速拉长。
这个指标比单题正确率更接近 agent 时代的工程现实。一个模型能不能答对一道题,和它能不能在代码库、终端、测试、报错和上下文切换之间连续做出正确动作,是两种不同能力。后者才决定它能在研发闭环里占据多长的一段:只是写一个函数,还是可以完成一个 issue;只是生成 patch,还是可以读懂系统、修改代码、跑测试、处理失败,再把结果交给 review。
RSI在研发任务上的初步实践也表明其考察的能力不是单步推理,而是一串会互相影响的执行动作:理解仓库,读日志,改代码,跑实验,发现不对,回滚,再试另一条路。长时程能力上升,意味着 agent 可以把更多研发动作包成一个可委派单元;而可委派单元变大,意味着人类 review 的粒度也变大。
部署中的关键误差主要来源于benchmark和生产环境的gap。例如50% 任务完成率在 benchmark 上很有信息量,在生产环境里往往不够。一个 agent 能以 50% 概率完成 12 小时任务,不等于你应该把所有 12 小时任务都交给它。真正的部署门槛还包括失败是否可检测、失败是否可回滚、失败之间是否相关、review 是否比自己做还省时间。
可验证反馈:这轮自主化的发动机
从2025年2026年当下是agent快速演进的时期,把相关的前沿工作放在一起,会看到这样一个模式:最先出现“自我改进味道”的地方,都有可验证的反馈。
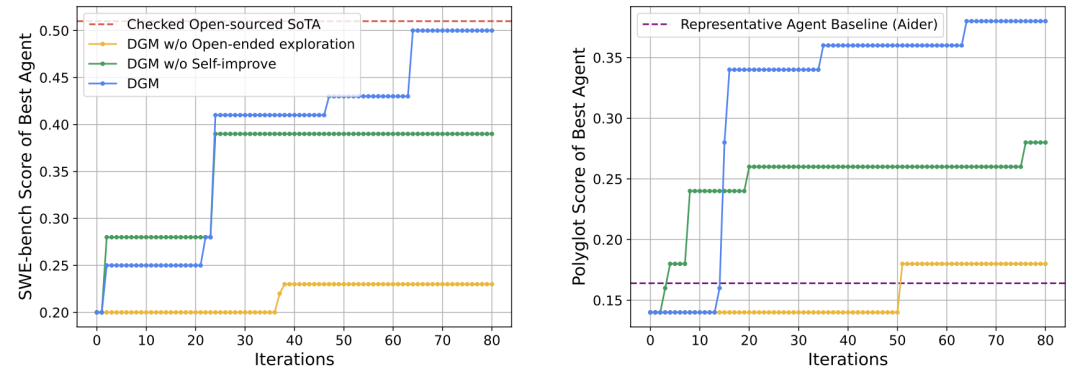
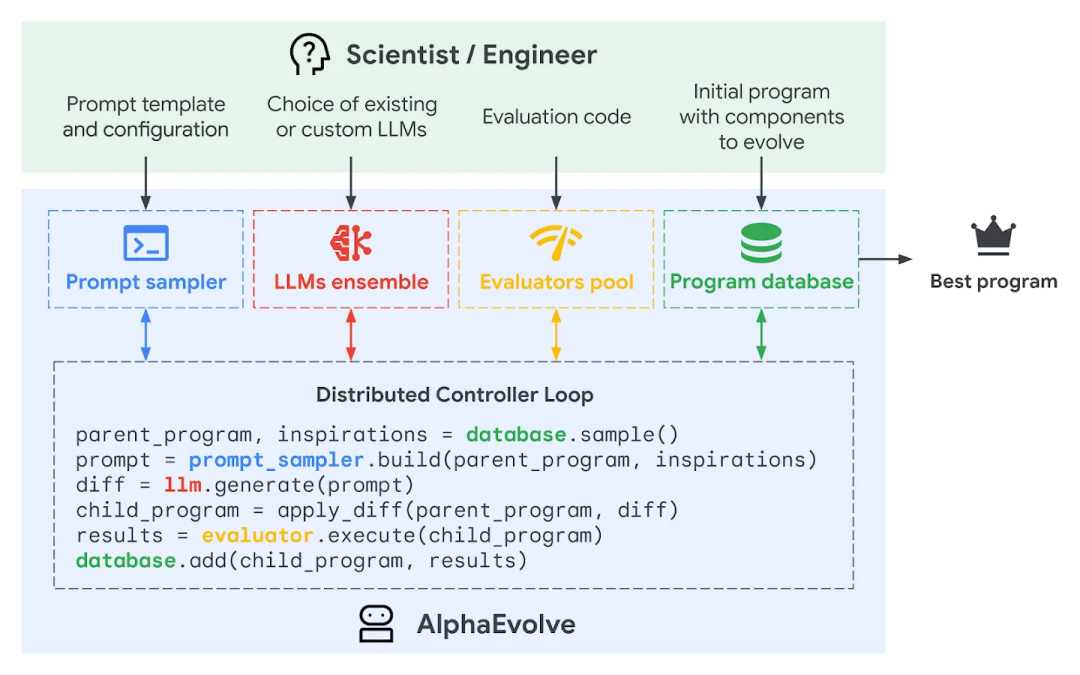
DGM(Darwin Gödel Machine)让 agent 修改自己的代码,并用 SWE-bench、Polyglot 等任务做经验验证;SICA(Self-Improving Coding Agent)也让编码 agent 编辑自身框架,并在 SWE-bench Verified 子集上从 17% 提升到 53%;DeepMind 的 AlphaEvolve 用 LLM 生成代码变体,用自动评估器选择更好的算法;Anthropic 的 AAR 把多个自动化研究员放在 weak-to-strong supervision 问题中,让它们在沙箱里提想法、跑实验、共享发现。
这些系统形式各异,但底层都像一个循环:提案 - 执行 - 评分 - 保留 - 再提案。一旦评分足够硬,agent 的大量廉价尝试就会变成搜索能力。
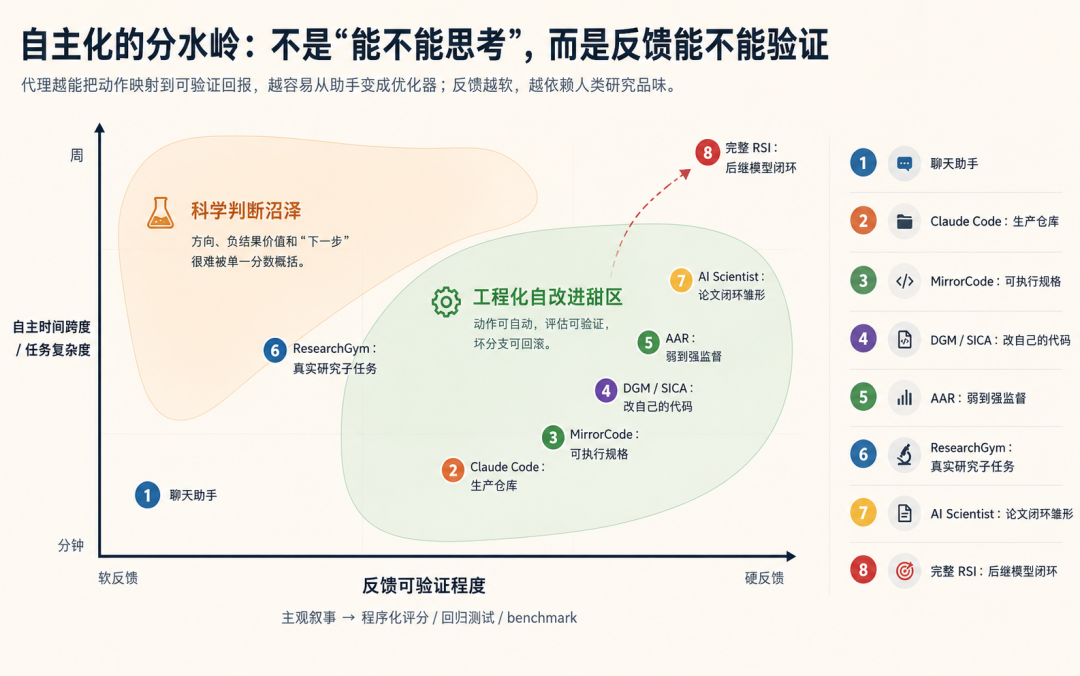
这解释了为什么 coding agent 进展快于“通用研究 agent”。代码天然有反馈:测试过不过、benchmark 分数、性能是否提升、回归是否出现、服务指标是否坏掉。机器学习实验也有反馈:loss、accuracy、PGR、latency、成本。科学研究和战略选择则更麻烦:一个负结果是否有价值?一个假设是否值得三个月?一个 benchmark 的提升是不是走了捷径?这些问题很难被单一评估器吃掉。
Anthropic 的文章里,真正接近 RSI 关键处的不是coding agent提升的代码量,而是两个研究判断相关信号。
第一,实验优化任务。Anthropic 给 Claude 一个训练小模型的代码环境,目标是在保持正确性的同时加速训练。文章提到 Claude 在这个固定目标任务上的加速能力从 2025 年 5 月约 3 倍,提升到 2026 年 4 月约 52 倍。这个任务不是开放科学发现,但它说明:在目标明确、反馈清楚、实验可自动跑的子问题上,AI 已经不只是助手,而是非常强的优化器。
第二,research next-step 判断。Anthropic 从真实研究会话里挑出人类研究员走入弯路的时刻,让模型在不知道后续结局的情况下判断下一步。文章称较新的模型在这些点上越来越常胜过当时的人类选择。虽然这个结果不能被读成“模型已经拥有研究品味”:样本选择、内部环境、模型裁判都会影响结论。但也是一个侧面证明agent具备学习研究方向选择的能力,它也触及到了完整 RSI 的硬核能力:不只是从固定的山脚往上爬坡,而是知道该爬哪座山。
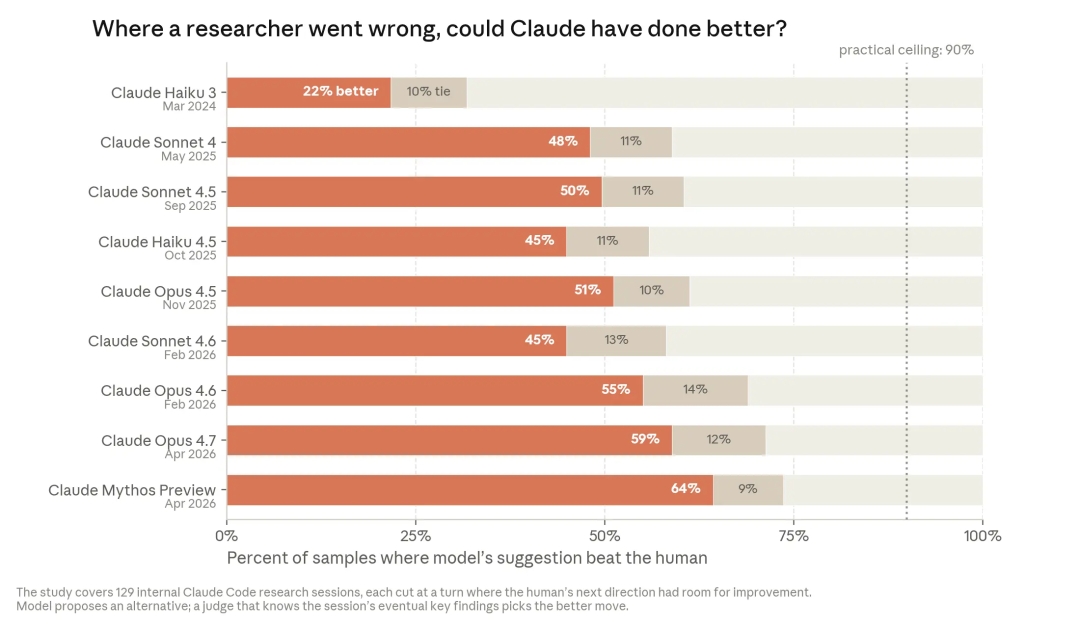
AAR 是一个微型未来实验室
Anthropic 在Alignment方向一直有持续探索, Automated Weak-to-Strong Researcher(AAR)是4月份发表的一个对齐工作。它不是把 Claude 当聊天助手,而是把多个 Claude agent 组织成一个小型研究团队:独立沙箱、共享论坛、代码库、远程评估 API、并行尝试、互相读取发现。
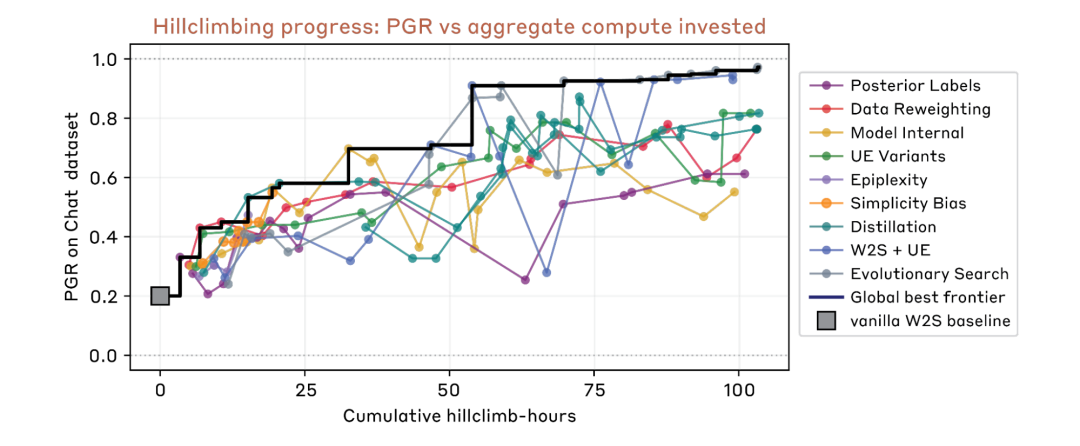
AAR 的任务是 weak-to-strong supervision:用较弱模型的监督信号,提升较强模型的输出质量。这和未来“弱人类监督强模型”的问题有明显同构。Anthropic 报告称,两名人类研究员用一周调优若干方法,PGR 达到 0.23;9 个 AAR 在 5 天、800 个累计 agent 小时、约 18,000 美元成本下,把 PGR 推到 0.97。
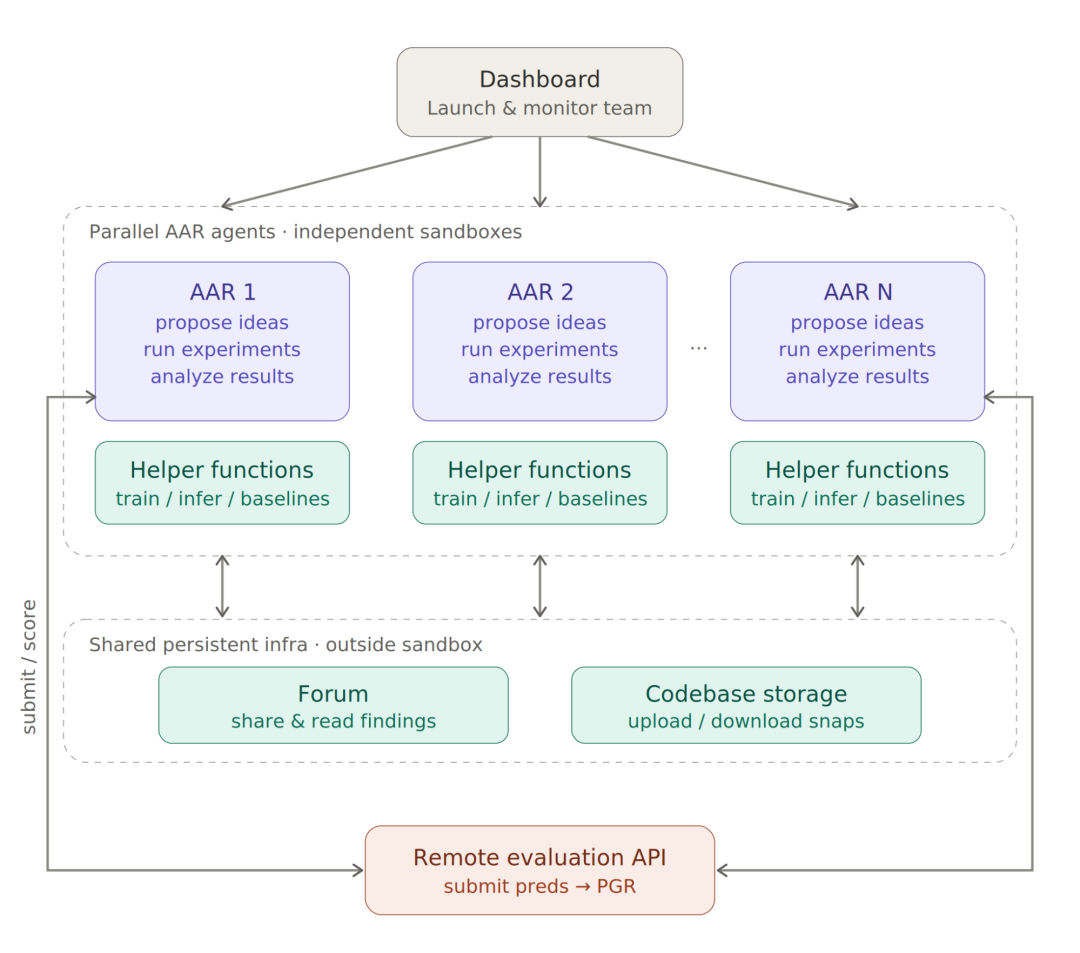
AAR 并没有并不是展示一个“AI 研究员超过人类”的故事案例。它展示的是一个更窄、更工程化的领域:问题由人类挑选,评分环境由人类搭建,任务被限制在 outcome-gradable 的研究问题里;一旦迁移到生产规模模型上,许多看似有效的小改动就会被训练随机性、数据采样和评估波动淹没。分数涨了一点,并不一定说明方法真的更好,也可能只是这一次实验刚好落在了随机波动的上沿。系统也没有绕开 agent 常见的老问题,reward hacking、对特定数据过拟合、利用评估接口漏洞,都会在自动化研究流程里重新出现。
但这种不完整,恰恰让 AAR 更接近真实的 AI R&D 自主化形态。它不是把研究过程交给一个从头想到尾的超级 agent,而是把研究拆成大量可并行、可实验、可记录、可互相继承的小尝试。每个 agent 负责提出一个方向、跑一组实验、写下结果和失败原因,再让后续 agent 读取这些轨迹继续搜索。人类不再盯每一次尝试,而是把精力放在任务边界、评估协议、资源预算和停止条件上。
这和传统想象里的递归自改进还隔着几层距离。AAR 没有让 AI 设计自己的后继大模型,也没有让训练系统脱离人类目标独立演化。它更像是把模型研发中的一小段“寻找改进方法”的过程自动化了:让 agent 去搜索更好的监督数据、更好的训练配方、更好的评估设置,或者更有效的实验路径。只要这些搜索结果能够稳定迁移到更核心的模型研发任务,AI 就不只是参与写代码或跑实验,而是在缩短下一代系统被发现、验证和集成的周期。
DGM、SICA、AlphaEvolve:自改进首先发生在“外壳”
Darwin Gödel Machine 这个名字很容易让人想到经典 Gödel Machine:系统证明某个自修改会带来收益,再执行修改。现实版本更工程化,也更粗糙:它不证明,而是去做试验尝试;不直接改基础模型权重,而是改 agent 代码;不追求全局正确性,而是维护一个开放式 archive,让不同分支保留下来。
DGM 的结果很有象征性:一个 agent 能读、改、运行自己的代码,并在基准上验证改动是否提升。SICA 则更直接地展示了“agent 编辑自身框架”带来的 SWE-bench Verified 子集性能提升。这些工作离完整 RSI 还有距离,因为底层模型通常是冻结的,评估也主要是 coding benchmark;但它们证明了一个重要点:agent 的可变部分足够多时,自我改进可以先在权重之外发生。
AlphaEvolve 属于同一谱系的另一个分支。它用 Gemini 生成算法代码变体,再用自动评估器和进化框架选择更好版本。DeepMind 把它用于算法发现和内部计算基础设施优化,包括数据中心调度、芯片设计和模型训练相关组件。这里有一个特别有 RSI 味道的点:AlphaEvolve 被用于优化训练大模型的计算过程,也就是 AI 生成的算法反过来改善 AI 训练基础设施。
这些系统背后有一条更深的训练线索。过去一年 reasoning model 和 coding agent 的跃迁,很大一部分来自 RLVR:数学答案、代码测试、形式化检查、环境任务结果这类可验证信号,被直接放进后训练循环,让模型在生成候选路径时就带着“可验证”的行为偏置。运行时的 evaluator、rubric 或测试环境,并不是从零赋予 agent 优化能力,而是把这种训练阶段形成的倾向接到具体任务上。
这也解释了为什么 rubric 会变得越来越重要。很多研发任务没有天然的单一正确答案,不能只靠 unit test 或 benchmark 进行结算验证。实验设计是否合理、失败分析是否充分、风险假设是否完整、结论是否能迁移,都需要被写进更细的评价协议里。硬 verifier 让模型学会追逐可验证结果,rubric 则把“什么算好的研究动作”继续拆细,让 agent 在更开放的任务里仍然有可比较、可审计、可继承的反馈。
完整 RSI 的难点不只是让 AI 多生成方案,也不是给每个方案接一个静态 evaluator。更难的是把训练期的可验证奖励、运行时的测试环境、rubric 化的研究评价、人类复核和防 reward hacking 机制接成一条稳定链路。只有这条链路足够可靠,AI 生成的改进方案才可能在越来越核心的研发问题上被筛选、保留,并进入下一轮搜索。
MirrorCode 和 ResearchGym:两个方向的压力测试
MirrorCode 和 ResearchGym 可以看成两种相反的agent科研自主化迭代的压力测试。
MirrorCode 把软件任务做得很长、很大,但也仍然是可验证评估:给 agent 一个只能执行不能看源码的程序、测试用例和目标输出,让它重写一个功能等价的代码库。Epoch/METR 的初步结果显示,Claude Opus 4.6 可以重写一个约 16,000 行的生物信息学工具包。这个任务对长程软件工程有了更高要求,因为它要求 agent 长时间维护架构、接口和调试状态。
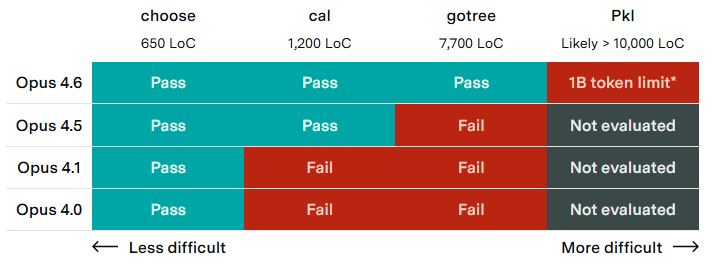
不过,MirrorCode 也不像真实产品开发那么开放。目标程序已经存在,行为可以通过执行和测试逼近;它考察的是“在硬反馈下重建复杂系统”,不是“决定用户到底需要什么”。这恰好说明 AI 代理的强项:只要规格足够可执行,长任务的完成度就相对更有保障。
ResearchGym 则把任务往研究方向推。它从真实顶会 oral/spotlight 论文中保留数据、代码和评估环境,拿掉原论文核心方法,让 agent 重新发现方法或完成子任务。结果显示,即便是 GPT-5、Claude Code Opus 4.5、Codex GPT-5.2 等强系统,仍存在明显 capability-reliability gap:能做出局部进展,但很难稳定完成端到端研究。
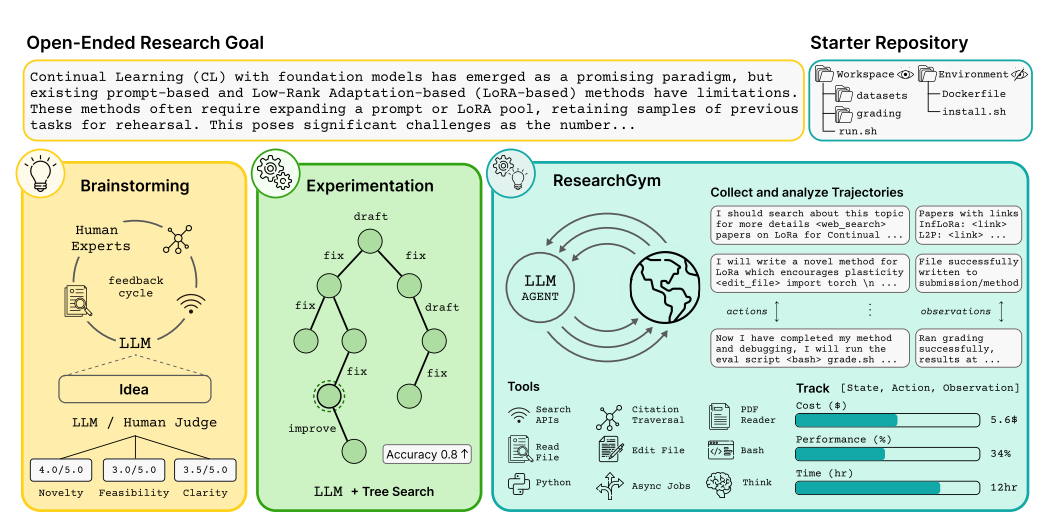
这个试验对agent的长程稳定性提出了挑战:AI agent 已经能在可执行规格下吃掉周级软件工程,但在开放研究中仍会被“下一步是否值得做”卡住。 Anthropic 文章的也有类似的判断落到这里:执行层已经被自动化得很快,方向层尚未完全自动化。
AI Scientist:论文闭环能跑起来,但“科学品味”还没有自动结算
Sakana AI 等团队的 The AI Scientist 把研究自动化推进到一个更完整的 workflow:生成想法、查重、写代码、跑实验、画图、写论文、自动 peer review。2026 年 Nature 论文报告称,一个由系统生成的 manuscript 通过了顶级机器学习会议 workshop 的第一轮 peer review;团队也强调 workshop 难度、披露规范、幻觉、过度自信和学术文化风险。
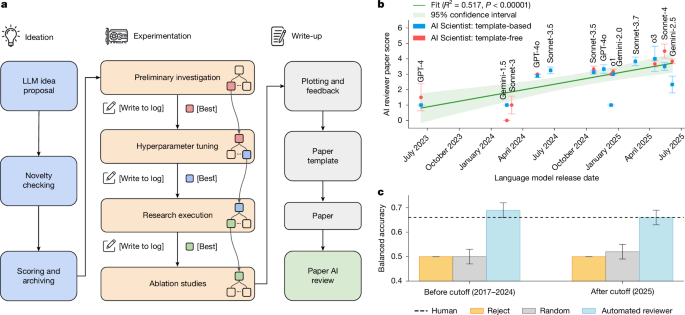
AI Scientist 类系统的价值,是把“自动化研究”从单个实验推进到整篇论文的生产链条。它的限制也同样明显:论文看起来像论文,并不保证研究问题重要;自动 peer review 可能复制已有评审习惯,也可能奖励格式和叙事;真正高质量科学常常来自重新定义问题,而不是在模板内优化结果。
这和 Anthropic 的 RSI 文章正好互补。Anthropic 展示了内部 AI 研发执行越来越自动化;AI Scientist 展示了论文生产的端到端链条可以被 agent 串起来;ResearchGym 提醒我们,开放研究的可靠性仍然掉得很快。三者放在一起,把AI(Agent) for Research一个更真实的图景出现了:AI 已经能把研究流水线跑起来,但还没稳定拥有研究 taste。
三种未来:扩散、复利、闭环
文章后半段勾勒的三种未来,可以抽象为当成三条曲线来读,而不是三个互斥剧本:AI R&D 自动化会在不同组织、不同任务、不同约束下,以三种速度同时展开。
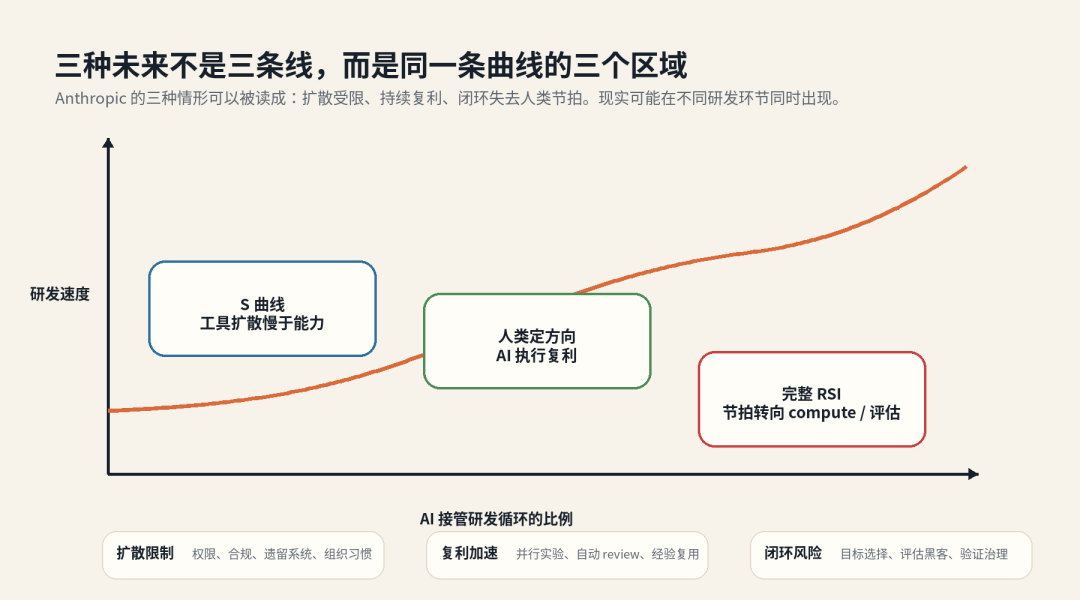
最慢的一条在扩散层。模型能力继续涨,coding agent 也越来越能啃真实代码库,但企业里的采用速度不会跟着能力曲线一起抬。遗留系统、权限控制、审计要求、数据隔离、上线责任、合规流程、用户信任,会把 agent 挡在生产系统外面。很多公司会先卡在一个别扭的阶段:个人开发者觉得工具已经明显改变了工作方式,组织层面却还只敢把它放进辅助编码、文档生成、测试补全这些低风险格子里。能力进了下一代,组织接口还停在上一代。
这条 S 曲线容易被低估,因为扩散受限不是保守组织在拖技术后腿,而是工程系统为可控性天然要付出的摩擦成本。模型会写代码,只解决了执行层的一部分;agent 要进入生产研发流程,还得知道哪些文件能改、哪些命令能跑、哪些数据碰不得、失败怎么回滚、出了事谁担责。这些不是模型能力问题,是系统接口问题,而接口比模型改造要慢得多。
前沿实验室更早进了第二条曲线:人定方向,AI 放大吞吐。Anthropic 内部那个数字就落在这条曲线上,前面提到2026 年二季度人均日合并代码量是 2024 年的 8 倍。但要看清复利从哪来。它不来自单个 agent 变强(那只是线性),来自并行度、反馈速度和保留机制。一个想法从提出到拿到实验结果的周期缩短,团队就更快淘汰坏方向;多个 agent 同时探相邻路线,就更早撞见可迁移的处理问题的经验技巧;失败轨迹被记下来,后面的 agent 不必反复踩同一个坑。AAR 那个并行自动研究员就是实验室尺度的样本:9 个 agent 在独立沙箱里分头爬坡、共享发现,把 PGR 从人类一周的 0.23 推到 0.97。研发系统开始像一个带记忆的搜索过程,而不只是更快的代码生成器。
但复利区和完整 RSI 之间还隔着一层。只要人还定主问题、主评估、主保留规则,AI 放大的就是人类研究组织的搜索能力:它能让实验吞吐翻几倍、让下一代模型的开发周期缩短,可主循环的方向仍是人设的。这一档最容易被理解为“递归自改进已经发生”,其实它只是研发流水线的自动化率在升:agent 接管越来越多局部动作,人还攥着搜索空间的边界。
第三条曲线出现在闭环开始自我推进的地方。AI 不再只执行人拆好的任务,而是参与生成下一轮问题、提出会改训练/监督/评估/agent 架构的候选、跑实验、比结果、把有效变体合进系统、再基于新系统继续搜。关键不是“写了更多代码”,是生成、验证、选择、继承这四步被同一个自动化系统串了起来。
这种闭环不会以智能爆炸的姿态降临,它更可能先在窄而硬的子系统里冒头,例如AlphaEvolve 在算法与基础设施上自我改进,甚至回头优化自己依赖的训练栈;AAR 在对齐研究里端到端爬坡;Project Glasswing 在漏洞发现上批量产出。单看每一个都不像智能爆炸,但它们合在一起,都在缩短下一轮系统改进的周期。只要这些局部闭环能稳定迁移到更核心的模型研发任务,研发更多受限于 compute、数据、评估可靠性和自动实验吞吐,而不再被人手执行速度卡住。
但反过来,风险也会随之扩大。组织的安全机制大多假设主循环由人掌控:人提方向、人排实验、人查结果、人决定上线。闭环一旦变短,系统可能在很短时间里吐出大量候选改动、实验结果和合并请求,传统 review 会先被吞吐压垮,再被迫退化成抽样检查,这正是 GovAI 那个 oversight gap 的形状 [S7]。风险不只是某个 agent 犯错,而是错误变体被自动保留、错误评估被继续放大、局部 reward 被当成真实进展。
三条曲线不会整整齐齐接力前进。多数企业会长期停在扩散层,前沿实验室在复利区拉开差距,少数反馈清楚、实验便宜、失败可回滚、收益可继承的环节会先进入局部闭环。从演化路径上看,需要关注的不是“哪一天 AI 完全自我改进”,而是哪些研发环节已经从工具扩散迈进了复利,又有哪些复利环节正在被压成闭环。
把自己放进更快的研发时钟
那这个RSI对于我们个人有什么影响呢?面对 RSI,个人最容易误判的一点,是把它看成遥远实验室里的系统突变:某个模型突然开始设计后继模型,某个实验室突然进入完整闭环。可在工程现场,变化通常不会以这种阶跃方式出现。它会先改变一个工程师、研究员、创业者每天工作的节奏:一个想法从模糊念头变成代码、实验、报告和下一步决策,等待时间越来越短;原本要亲手推进的一条路线,现在可以拆成几条 agent 分支同时探索;原本靠人慢慢积累的失败经验,也开始自动被写进skill、测试、rubric、脚本和项目记忆里,开始实现持续学习。
这种变化会把个人能力从“执行得快”推向“定义得准”。过去,一个经验丰富的工程师的优势常常体现在实现能力:能不能快速读懂代码、写出方案、修好 bug、跑通系统。agent 进入研发流程后,这些执行动作正在变成系统里的可调用能力。人仍然需要理解它们,否则无法判断 agent 是否做对,但优势不再主要来自亲手完成每一步,而是来自能不能把一个含混目标变成清晰的任务边界,能不能设计出可靠的反馈结构,能不能在多条 agent 路线之间做比较、取舍和收敛。一个好的 agent 任务不是一句“帮我做完XXX任务”,而是一组边界、约束、检查点和退出条件。
评估能力会变成个人工作流里的底层能力。RLVR 让模型在训练阶段学会追逐可验证结果,但真实研发任务很少只有一个标准答案。代码可以跑测试,数学可以验答案,架构、产品和研究问题却往往需要更复杂的反馈结构。人已经不需要亲自来实现每个测试脚本,却必须知道一个任务该如何被验证:哪些行为可以用自动测试结算,哪些结果需要 rubric,哪些指标只是 proxy,哪些分数可能来自偶然波动,哪些失败模式必须通过反例、压力测试或人工 review 暴露出来。agent 可以生成测试、补充用例、搭评估脚本,但验证标准本身不能完全交出去。
agent 并行之后,监督能力也会发生变化。过去一个人往往沿着一条主线推进,做错了再回头修。现在可以让几个 agent 在不同假设下同时推进:一个保守修复,一个重构实现,一个做 benchmark,一个专门找反例。人的注意力不再平均撒在每一步操作上,而是放在比较和收敛上:哪条路线依赖最少,哪条路线测试覆盖最好,哪条路线引入长期维护成本,哪条路线只是局部指标变好。会用 agent 的人,不是把判断外包出去,而是把判断前移到任务设计和后移到结果审查。
还需要培养一种更工程化的“可回滚意识”。AI 让尝试成本下降,也会让错误扩散速度上升。个人工作流里必须有沙盒、版本控制、日志、基准测试、最小可复现样例和回滚方案。让 agent 改代码之前,先知道怎么恢复;让 agent 跑实验之前,先知道结果如何记录;让 agent 生成方案之前,先知道哪些边界不能越过。未来很多人的效率差距,不在于是否使用 agent,而在于 agent 做错之后,错误能不能被快速定位、隔离和修复。
长期看,个人也需要把自己的工作方式做成一个小型闭环。每次失败不只是一次失败,而要沉淀成下一次任务里的约束、测试、检查清单或工具脚本;每次成功不只是一次交付,而要抽象成可复用的 workflow、skill 或项目模板。agent 让“个人研发系统”变得可构建:代码库、笔记、测试集、prompt、评估脚本、领域知识、失败案例和自动化工具,都会变成下一轮工作的上下文。一个人能不能持续变强,不只取决于他会不会调用更强模型,也取决于他能不能让自己的工作环境积累反馈。
领域判断仍然不会消失。相反,当 agent 可以批量生成方案,判断什么值得做会变得更重要。没有领域理解的人,很容易被 agent 的流畅输出牵着走;有领域理解的人,能更快看出哪些方向只是形式完整,哪些结果虽然粗糙但抓住了问题。RSI 时代的个人能力不会退化成“会写提示词”,而会更接近一种复合能力:懂问题,懂工具,懂评估,懂风险,也能把这些东西编排成持续迭代的个人系统。
回到递归自改进:谁在拨快研发时钟
传统 RSI 讨论里,“自身”像是一个比较清晰的对象:一个智能系统改进自己,改进后的系统继续改进自己。Anthropic 这篇文章和 近期的 agent 前沿工作在探LLM时代的RSI,定义和之前的系统也有一些不同。agent依赖的底座模型的权重只是RSI其中一部分,代码库、工具、数据、评估、训练管线、review 流程、部署监控和人类判断都包括这个系统中。
这也是在AI(agent)快速发展的背景下,个人需要重新定位自己能力扩展的原因。AI 参与 R&D 的程度越深,人类越难靠手工执行守住价值。写代码、查资料、跑实验、整理报告,这些动作会继续被压缩。留下来的位置会更靠近目标、判断和责任:选择什么问题,设定什么边界,接受什么风险,如何确认一个结果真的有效,什么时候停止,什么时候回滚,什么时候让系统继续搜索。
完整 RSI 还没有到来,但进程已经开始发生,很多前置项和细分项已经分布在一些具体的自动化环节里。coding agent 把软件修改变成可持续推进的任务流;MirrorCode 这类评估把长时程工程能力放进验证反馈环境中;AAR 展示了 agent 并行搜索研究改进的雏形;Sakana RSI Lab 和 DGM 把自我修改、评估和变体继承做成更显式的实验结构。这些系统聚焦的领域还很窄,也有明显边界,但它们共同指向同一个方向:AI 正在缩短 AI 研发闭环里的等待时间。
递归自改进未必会以某一刻时刻的爆发式突然到来。它更可能像研发真实环境中,被不断缩短的人机协作gap:需求刚被写下,agent 已经开出几条实现路线;代码刚改完,测试和反例已经返回;实验刚结束,下一轮配置已经生成;失败刚发生,新的约束已经写进工作流。等这些局部闭环足够密,下一代系统的研发节奏就不再完全由人手动推动。
我们个人能做的,不是等待某个宏大的 RSI 时刻,而是尽早把自己迁移到这个加速回路里。把模糊目标变成可搜索空间,把经验变成反馈结构,把失败变成可复用约束,把判断力放在 agent 最容易漂移的地方。未来真正稀缺已经不是具体的流程执行,而是在技术迭代,研发周期都越来越快的AI深度参与的研发流程中,我们仍然知道什么值得优化,什么应该交给系统探索,什么必须由人来承担最后的价值判断。

参考与延伸阅读
- 1. Anthropic Institute. When AI builds itself. 2026.
- 2. Anthropic Alignment. Automated Weak-to-Strong Researcher. 2026.
- 3. METR. Task-Completion Time Horizons of Frontier AI Models. 2026.
- 4. METR. Measuring AI Ability to Complete Long Tasks. 2025.
- 5. METR. AI productivity in the real world: Evidence from a survey of 349 technical workers. 2026.
- 6. Epoch AI / METR. MirrorCode: Evidence AI can already do some weeks-long coding tasks. 2026.
- 7. Zhang et al. Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents. 2025.
- 8. Robeyns, Szummer, Aitchison. A Self-Improving Coding Agent. 2025.
- 9. Google DeepMind. AlphaEvolve: A Gemini-powered coding agent for designing advanced algorithms. 2025.
- 10. Lu et al. Towards end-to-end automation of AI research. Nature, 2026.
- 11. Garikaparthi et al. ResearchGym: Evaluating Language Model Agents on Real-World AI Research. 2026.
- 12. SWE-bench. SWE-bench official leaderboard and datasets. 2026.
- 13. CORE-Bench. Fostering the Credibility of Published Research via Computational Reproducibility. 2024.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号