医疗AI智能体:构筑长效对话链路:智能体多轮对话记忆机制与上下文完整处理实践.132
原创
医疗AI智能体:构筑长效对话链路:智能体多轮对话记忆机制与上下文完整处理实践.132
原创
未闻花名
发布于 2026-06-09 08:44:11
发布于 2026-06-09 08:44:11
一、智能体多轮对话记忆
1. 基础定义
智能体的多轮对话记忆,是指AI智能体在连续人机交互过程中,留存历史交互信息、理解对话上下文逻辑、关联前后语义关系,并依托大语言模型实现连贯应答的核心能力。
- 单次问答属于“无记忆单轮交互”,模型仅依据当前用户提问生成结果;
- 而多轮对话记忆,会把用户历史提问、智能体历史回复、对话时序、语义关联、关键实体信息统一维护,让大模型具备类似人类记住聊天内容的基础认知。

2. 上下文处理的本质
大模型本身具备上下文窗口(Context Window)原生特性,模型无法脱离输入文本凭空记忆内容,所有多轮连贯效果都依赖:
- 1. 结构化存储历史对话数据;
- 2. 按照规范格式拼接历史上下文 + 当前用户问题;
- 3. 统一送入大模型 Prompt 层完成推理生成;
- 4. 迭代更新对话记录,形成闭环流转。
3. 无记忆和多轮记忆核心差异
- 单轮无记忆:每次请求独立隔离,不懂指代、不懂延续、无法关联前文实体;
- 多轮有记忆:支持代词指代承接、业务话题延续、历史条件复用、复杂多步骤任务串联执行;
这也是通用大模型升级为落地级业务智能体的必备基础能力。
二、基础知识理解
1. 大模型上下文窗口基础原理
主流大模型(Qwen、ChatGLM、Llama、GPT系列)均基于 Transformer 架构,依赖Token长度限制输入总量。
- Token:文本最小计算单元,汉字≈2Token,英文单词≈1Token;
- 上下文窗口上限:决定单次最多能塞入多少历史对话 + 当前提问;
- 核心限制:窗口容量有限,超长多轮必须做记忆压缩、摘要过滤、轻量化检索。
随着对话轮次增加,Token 消耗持续上升,直到触发窗口限制:
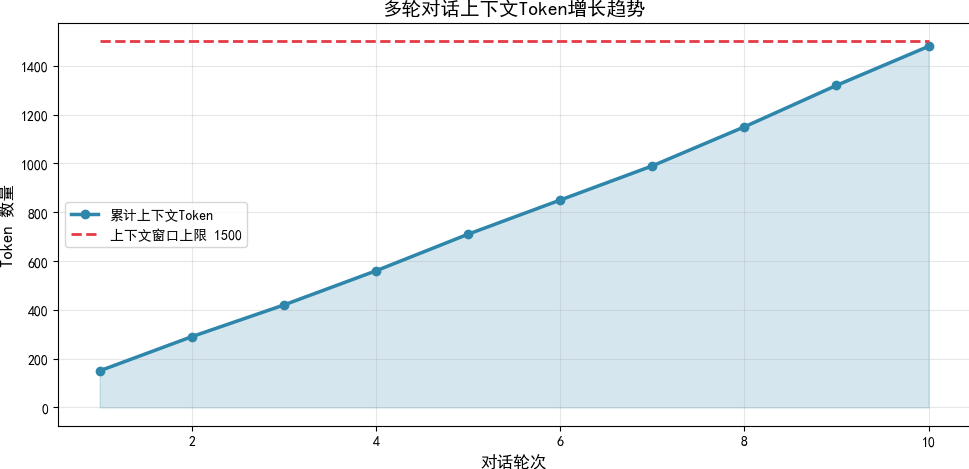
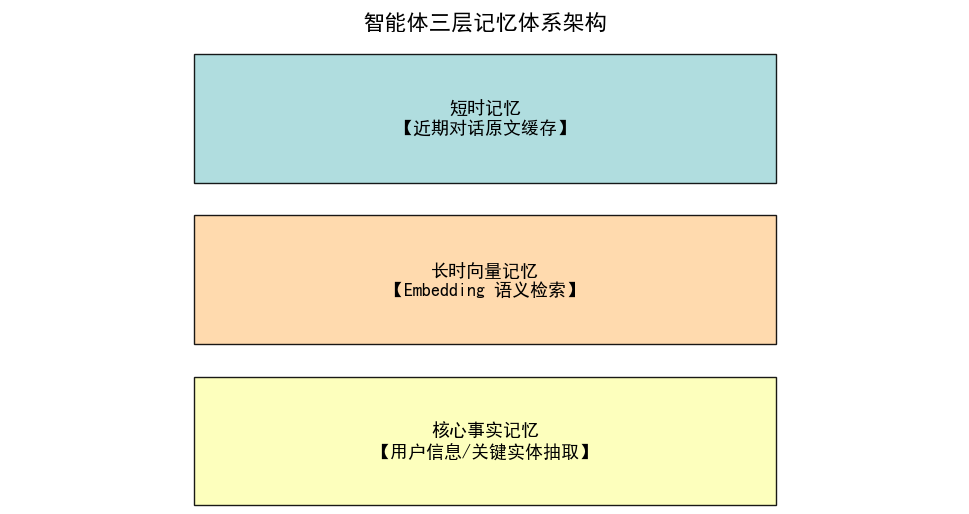
2. 智能体记忆分层体系
行业标准三层记忆架构,是上下文处理的基石:
2.1 短时记忆(上下文缓存记忆)
- 存放当前会话近期多轮原话,直接拼接进 Prompt,实时性最强、语义无损;受窗口长度严格约束。
2.2 长时记忆(向量知识库记忆)
- 对久远对话做 Embedding 向量化编码,存入向量数据库;
- 当前话题关联历史久远内容时,相似度检索召回关键片段,节约窗口空间。
2.3 核心事实记忆(实体固化记忆)
- 抽取用户固定信息(姓名、需求、偏好、业务参数)结构化存储,全局全局复用,无需重复对话提及。
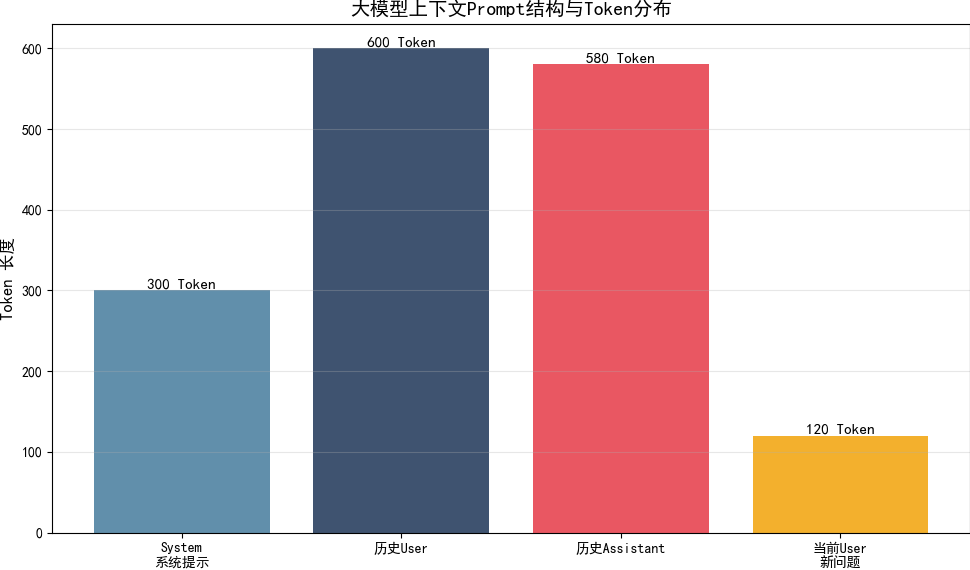
3. Prompt 上下文拼接规范基础
大模型遵循固定对话角色标记规范:
- system:系统人设、能力定义、全局指令;
- user:人类用户每一轮提问输入;
- assistant:智能体每一轮模型输出回复;
有序堆叠三者时序数据,就是基础上下文组织形式。
三、简单原理介绍
1. Transformer注意力机制支撑上下文理解
大模型依靠多头自注意力(Multi-Head Attention) 计算文本之间语义权重:
- 拼接后的完整上下文中,当前用户问题字词会与历史全部对话字词做关联权重计算,模型天然读懂:指代关系、逻辑递进、条件约束、话题延续。
- 若无历史上下文输入,注意力仅聚焦当前单句,无法实现连贯对话。
2. 缓存型短时记忆底层原理
基于内存、Redis做KV缓存存储:
- Key = 会话唯一ID
- Value = 有序List[{"role":"user/content"},{"role":"assistant/content"}]
- 读写毫秒级响应,无需磁盘 IO、无需向量检索,极致高效,适合近期高频对话复用。
3. 向量长时记忆底层原理

- 1. 调用Embedding 模型,如all-MiniLM、text-embedding 系列,把长对话文本转为高维数值向量;
- 2. 向量数据库构建索引存储,实现高密度快速相似度匹配;
- 3. 新问题向量化后,检索 Top-K 相似历史对话片段;
- 4. 将召回精简关键信息并入Prompt,突破原生上下文窗口长度限制。
4. 记忆压缩摘要原理
当轮次过多爆窗时,调用大模型轻量调用:对早期多轮对话浓缩核心语义、关键结论、实体信息,替代原始长篇原话,大幅节约 Token,同时保留核心上下文逻辑。
四、多轮对话记忆完整流程
1. 整体业务执行链路
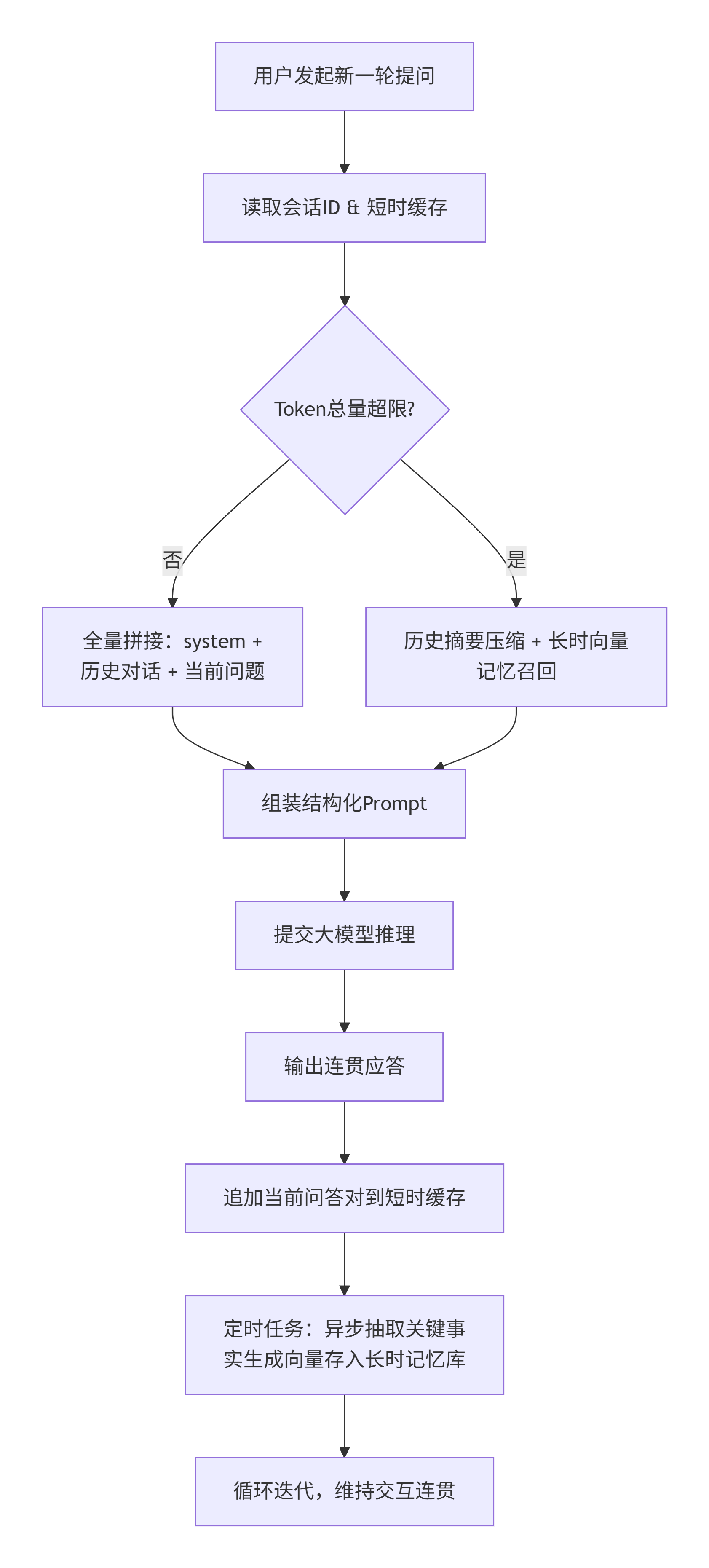
流程说明:
- 1. 用户发起新一轮提问请求;
- 2. 服务端读取当前会话 ID,调取短时原始对话缓存;
- 3. 判断上下文 Token 总量是否超限:
- 未超限:直接全量拼接 system + 历史 user/assistant + 当前 question;
- 已超限:触发历史摘要压缩 + 长时向量记忆召回关键信息;
- 4. 组装标准结构化 Prompt 提交大模型推理接口;
- 5. 大模型输出连贯上下文应答结果;
- 6. 将“当前提问 + 模型回复”时序追加写入短时记忆缓存;
- 7. 定时任务异步抽取关键事实、生成对话向量存入长时记忆库;
- 8. 持续循环迭代,维持全链路连贯交互。
2. 关键节点说明
- 1. 会话隔离:依靠session_id或conversation_id区分不同用户、不同聊天窗口,避免上下文串扰;
- 2. 时序有序性:严格保证对话时间线正序排列,乱序会直接导致语义理解错乱;
- 3. 动态裁剪策略:优先丢弃最早无效闲聊内容,保留核心业务关键轮次;
- 4. 记忆降噪:过滤重复语句、无意义语气词,降低Token消耗提升推理效率。
五、多轮记忆的核心价值
1. 对原生大模型的补足作用
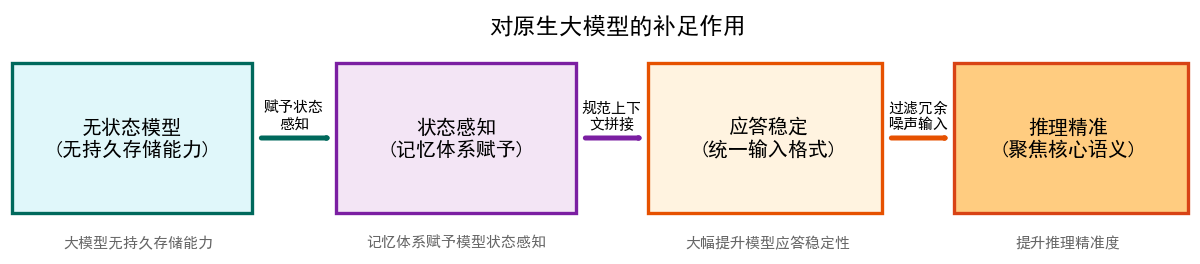
- 大模型本身无持久存储能力,是无状态模型,记忆体系赋予模型状态感知;
- 规范上下文拼接,统一输入格式,大幅提升模型应答稳定性;
- 分层记忆优化Token占用,缓解上下文窗口硬性瓶颈;
- 过滤冗余噪声输入,聚焦核心语义,提升推理精准度。
2. 对落地智能体的业务意义
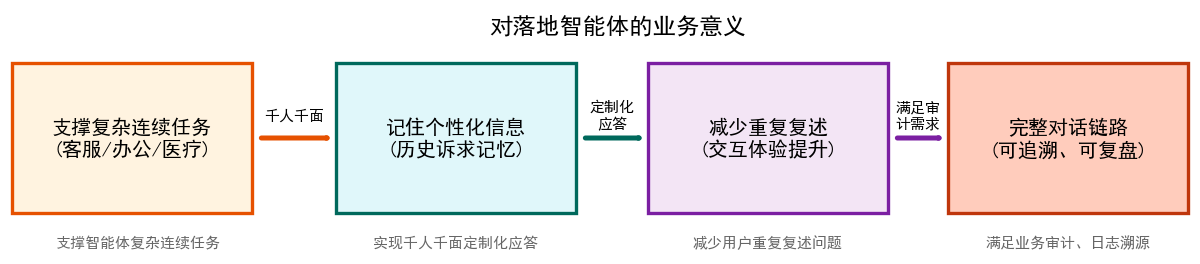
- 支撑客服智能体、办公智能体、医疗咨询智能体复杂连续任务;
- 记住用户个性化信息与历史诉求,实现千人千面定制化应答;
- 减少用户重复复述问题,交互体验直线提升;
- 构建可追溯、可复盘的完整对话链路,满足业务审计、日志溯源需求。
六、应用实践
1. 内存短时多轮上下文管理
实现了AI对话的多轮会话记忆管理功能,通过会话 ID 区分不同对话,存储用户与助手的交互记录,自动拼接系统人设提示词和历史对话形成完整上下文,支持会话初始化、新增对话轮次、获取完整上下文、清空记忆等操作,保障 AI 能基于历史对话连贯回答问题。
- 以session_id为维度隔离不同会话记忆,互不干扰
- 内置固定系统提示词,统一 AI 助手人设
- 结构化存储对话历史,按用户 / 助手角色有序记录
- 自动拼接系统提示 + 历史对话,生成大模型所需上下文
- 支持会话初始化、新增对话、清空记忆等核心管理操作
核心是AI多轮对话记忆管理,实现会话隔离、历史存储、上下文拼接,是大模型对话系统的基础记忆模块。
class ConversationMemory:
def __init__(self):
# 存储结构化对话列表
self.history_map = dict()
# 系统固定人设提示词
self.system_prompt = {"role": "system", "content": "你是专业智能助手,严格根据上下文连贯回答问题,理解前后语义关联。"}
def init_session(self, session_id: str):
"""初始化会话记忆"""
if session_id not in self.history_map:
self.history_map[session_id] = []
def add_round(self, session_id: str, user_input: str, assistant_reply: str):
"""新增一轮对话记录"""
self.init_session(session_id)
self.history_map[session_id].append({"role": "user", "content": user_input})
self.history_map[session_id].append({"role": "assistant", "content": assistant_reply})
def get_full_context(self, session_id: str):
"""获取拼接完成的完整上下文Prompt列表"""
self.init_session(session_id)
full_ctx = [self.system_prompt]
full_ctx.extend(self.history_map[session_id])
return full_ctx
def clear_memory(self, session_id: str):
"""清空指定会话记忆"""
if session_id in self.history_map:
self.history_map[session_id] = []
# 模拟调用演示
if __name__ == "__main__":
memory = ConversationMemory()
sid = "session_001"
# 模拟两轮交互
memory.add_round(sid, "介绍下什么是智能体", "智能体是具备感知、记忆、规划、执行能力的AI应用形态")
memory.add_round(sid, "它的多轮记忆核心是什么", "核心是上下文存储、结构化拼接、大模型注意力语义关联")
ctx_result = memory.get_full_context(sid)
for item in ctx_result:
print(f"{item['role']}: {item['content']}")输出结果:
system: 你是专业智能助手,严格根据上下文连贯回答问题,理解前后语义关联。 user: 介绍下什么是智能体 assistant: 智能体是具备感知、记忆、规划、执行能力的AI应用形态 user: 它的多轮记忆核心是什么 assistant: 核心是上下文存储、结构化拼接、大模型注意力语义关联
2. Token统计 + 上下文动态裁剪控制
实现大模型对话上下文的 Token 统计与历史裁剪功能,基于tiktoken库精准计算文本 Token 数,通过倒序遍历对话历史、从头部裁剪旧记录,保证总 Token 不超过设定上限,避免因上下文过长触发模型报错,保障多轮对话稳定运行,是大模型对话上下文管理的核心工具。
- 基于 OpenAI 官方tiktoken库统计 Token,统计结果精准匹配大模型规则
- 采用倒序遍历 + 正向恢复策略,优先保留最新对话,裁剪最早历史
- 动态裁剪上下文,严格控制总 Token 不超过设定阈值
- 适配大模型对话格式,直接处理结构化对话列表
- 可自定义最大 Token 限制,适配不同模型的上下文窗口
核心是大模型对话上下文 Token 管控,实现精准计数 + 智能裁剪,解决多轮对话超长超限问题。
import tiktoken
def count_token(text: str, encoding_name="cl100k_base") -> int:
"""统计文本Token数量"""
encoding = tiktoken.get_encoding(encoding_name)
token_list = encoding.encode(text)
return len(token_list)
def clip_conversation_history(history_list, max_token=2048):
"""从头部裁剪历史,保证总Token不超限"""
total_text = ""
# 倒序累加判断
clip_history = []
for msg in reversed(history_list):
temp_text = total_text + msg["content"]
if count_token(temp_text) > max_token:
break
total_text = temp_text
clip_history.append(msg)
# 恢复正序
clip_history.reverse()
return clip_history
# 使用示例
if __name__ == "__main__":
test_history = [
{"role":"user","content":"大模型上下文窗口是什么"},
{"role":"assistant","content":"是模型单次输入最大token长度限制"},
{"role":"user","content":"如何做多轮记忆优化"},
{"role":"assistant","content":"分层记忆+摘要压缩+向量检索协同优化"}
]
res = clip_conversation_history(test_history, 100)
print("裁剪后安全上下文:", res)输出结果:
裁剪后安全上下文: [{'role': 'user', 'content': '大模型上下文窗口是什么'}, {'role': 'assistant', 'content': '是模型单次输入最大token长度限制'}, {'role': 'user', 'content': '如何做多轮记忆优化'}, {'role': 'assistant', 'content': '分层记忆+摘要压缩+向量检索协 同优化'}]
3. Embedding 长记忆召回演示
实现AI对话长时记忆的向量检索功能,通过轻量嵌入模型将历史对话转为向量存储,用户提问时编码查询向量,用余弦相似度匹配召回最相关的历史片段,解决长对话记忆丢失问题,实现语义级精准检索,是大模型长时记忆系统的核心实现。
- 使用sentence-transformers轻量向量模型,高效生成文本嵌入
- 基于 ModelScope 本地下载模型,自定义缓存目录
- 余弦相似度计算匹配度,语义检索而非关键词匹配
- 支持 Top-K 召回,返回最相关的历史记忆片段
- 实现长时记忆语义检索,突破上下文长度限制
核心是大模型长时记忆向量检索,通过向量化 + 相似度匹配,实现历史对话语义级召回。
from sentence_transformers import SentenceTransformer
import numpy as np
from modelscope import snapshot_download
cache_dir = "D:\\modelscope\\hub"
embedding_model_dir = snapshot_download(
model_id="sentence-transformers/all-MiniLM-L6-v2",
cache_dir=cache_dir,
revision="master"
)
# 加载轻量通用嵌入模型
model = SentenceTransformer(embedding_model_dir)
# 模拟历史对话库
history_docs = [
"智能体依靠上下文拼接实现多轮连贯对话",
"短时记忆缓存近期原话,长时记忆向量存储久远内容",
"注意力机制是大模型理解上下文语义的底层核心"
]
# 向量化编码
doc_embeds = model.encode(history_docs)
def recall_top_similar(query: str, top_k=2):
"""相似度检索召回关键历史信息"""
q_embed = model.encode(query)
# 余弦相似度计算
sims = np.dot(doc_embeds, q_embed) / (np.linalg.norm(doc_embeds,axis=1)*np.linalg.norm(q_embed))
top_idx = np.argsort(sims)[::-1][:top_k]
return [history_docs[i] for i in top_idx]
# 测试检索
if __name__ == "__main__":
user_q = "大模型怎么理解多轮对话上下文"
recall_info = recall_top_similar(user_q)
print("召回长时记忆关键片段:")
for info in recall_info:
print("-", info)输出结果:
召回长时记忆关键片段: - 注意力机制是大模型理解上下文语义的底层核心 - 智能体依靠上下文拼接实现多轮连贯对话
4. 完整校验联动示例
实现大模型对话上下文拼接与 Token 超限检测功能,先统计系统提示、历史对话、新问题的总 Token 数,与设定的最大上下文长度对比,未超限则返回完整对话 prompt,超限则触发压缩与长时召回提示,是多轮对话上下文安全管控的核心逻辑。
- 基于tiktoken精准统计 Token,匹配大模型编码规则
- 自动拼接系统人设、历史对话、用户新问题生成标准 prompt
- 实时检测上下文是否超出最大 Token 限制
- 分状态返回结果:正常拼接 / 触发压缩召回
- 为长对话处理提供明确的分支判断依据
核心是大模型 prompt 构建 + Token 超限校验,实现对话上下文安全拼接,是衔接短时记忆与长时记忆的关键枢纽。
import tiktoken
# Token统计基础函数
def count_tokens(text: str) -> int:
enc = tiktoken.get_encoding("cl100k_base")
return len(enc.encode(text))
# 拼接+超限判断核心逻辑
def build_prompt_with_check(system_prompt, history_msg, new_query, max_context_tokens=2048):
base_text = system_prompt
# 先累加基础+新问题
total = base_text + new_query
final_history = history_msg.copy()
# 超限则触发压缩召回分支标识
if count_tokens(total + "\n".join([m["content"] for m in final_history])) > max_context_tokens:
return {"status":"overflow","msg":"需要摘要压缩+长时向量召回","prompt":None}
else:
full_ctx = [{"role":"system","content":system_prompt}] + final_history + [{"role":"user","content":new_query}]
return {"status":"ok","msg":"全量拼接通过","prompt":full_ctx}
# 使用演示
if __name__ == "__main__":
sys_p = "你依托上下文连贯回答问题"
his = [{"role":"user","content":"介绍多轮记忆"},{"role":"assistant","content":"依靠上下文缓存与向量记忆协同"}]
res = build_prompt_with_check(sys_p, his, "它超限怎么处理?")
print(res)输出结果:
{'status': 'ok', 'msg': '全量拼接通过', 'prompt': [{'role': 'system', 'content': '你依托上下文连贯回答问题'}, {'role': 'user', 'content': '介绍多轮记忆'}, {'role': 'assistant', 'content': '依靠上下文缓存与向量记忆协同'}, {'role': 'user', 'content': '它超限怎么处理?'}]}
七、总结
智能体多轮对话上下文处理核心逻辑可以收拢为一套极简闭环:原生大模型属于无状态 AI,本身记不住任何聊天内容,所有连贯对话效果,全依靠工程层面搭建的分层记忆体系落地。首先依靠短时内存或Redis缓存有序时序对话,严格按照 system-user-assistant 标准格式拼接上下文,依托 Transformer 多头注意力机制,让模型读懂前后语义、代词指代、话题延续;其次受限于大模型上下文 Token 窗口硬性约束,必须引入 Token 计数、动态裁剪、对话摘要压缩技术,避免超长轮次导致报错或性能暴跌;针对超远期历史交互,则结合 Embedding 模型做文本向量化,通过向量相似度检索召回核心关键信息,构筑长时记忆能力。
今天我们这套上下文处理机制,补齐了大模型无持久状态的先天短板,把单次孤立问答升级为连续闭环交互;在实际智能体落地中,无论是业务客服、任务规划型智能体还是各类咨询场景,稳定规范的多轮记忆管理都是底座核心。在实践落地中,务必结合 Token 动态裁剪与分层记忆策略平衡性能与成本,规避上下文溢出引发的语义断裂问题;同时可依据业务场景灵活调整摘要粒度与向量召回 Top-K 数量,让智能体的上下文理解既高效精准,又贴合真实交互需求,为各类复杂智能体业务筑牢稳定可靠的对话根基。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号