CodeBuddy Security:AI 时代的代码安全新范式——从发现到确证闭环

CodeBuddy Security:AI 时代的代码安全新范式——从发现到确证闭环

云鼎实验室
发布于 2026-06-09 11:19:06
发布于 2026-06-09 11:19:06
一、2026 年春,找漏洞这件事起了变化
在 2026 年的今天,AI Agent 驱动的漏洞挖掘已经从学术议题走向了工业化应用。
一个标志性的事件:Anthropic 发布的 Claude Mythos Preview 在 OpenBSD 中找到了一个藏了 27 年的漏洞,还在 FreeBSD NFS 场景下自己构造了多数据包的利用链,在沙箱里成功触发了漏洞。大模型不再只是读代码,它开始自己找线索、自己验证、自己写 exploit——从被动应答的工具,向能自主规划与执行的 AI Agent 演进。
Anthropic 随即将这套能力投入规模化运转,启动了 Project Glasswing 项目。第一个月,就从系统级关键软件中挖出 10,000+ 高危漏洞;扫描 1,000 多个开源项目,人工复审真阳性率超过 90%。而这些漏洞中,超过 99% 至今未修补。漏洞被挖出的速度已经远超修复的速度,行业瓶颈正从"如何发现漏洞"转向"如何验证和修复漏洞"。
二、AI 审计凭什么被看好
通用大模型在安全领域的跨界突破,让整个安全行业重新评估了 AI Agent 的潜力。业内开始意识到,通用模型在代码理解、逻辑推理和自主执行(Agentic)上的整体提升,能够直接转化为高效的代码审计能力。
Agent 之所以在此展现出独特优势,核心在于它不仅能推断代码背后的设计逻辑与语义上下文,还能自主构造验证路径来确认漏洞是否真实存在,而这正是传统静态分析(SAST)工具难以触及的盲区。
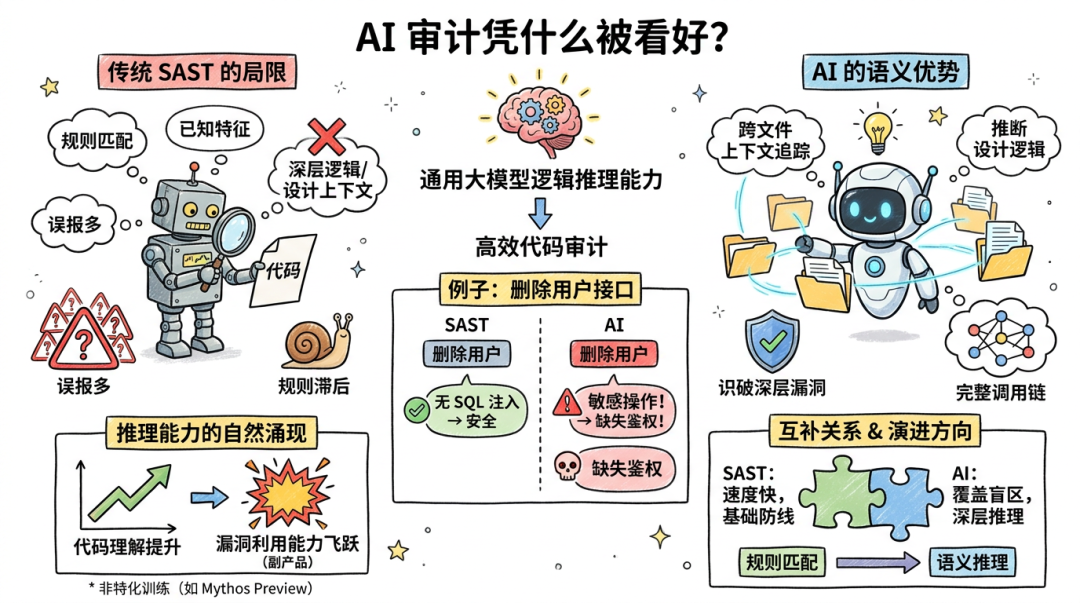
传统 SAST 的局限与 AI Agent 的优势
传统 SAST(静态代码分析)工具主要通过规则或数据流匹配来识别已知特征漏洞。由于不运行程序且缺乏语义与逻辑上下文,其局限非常明显:
- 深层逻辑与设计漏洞难以识别:SAST 难以理解代码背后的设计意图和跨组件状态交互。虽然它能检出已知模式的特征漏洞,却无法识别出需要追踪多步状态变迁才能触发的复杂缺陷——如协议状态机中的整数溢出、跨模块的越权路径、或多条件耦合的竞态窗口。
- 误报多、规则滞后:规则集难以及时覆盖快速迭代的系统架构与业务逻辑,在复杂的调用逻辑中极易产生大量误报,导致人工研判成本高。
举个例子。一个删除用户的接口:
传统 SAST 看到没有 SQL 注入风险就判定安全。它不会想到检查有没有鉴权。模型能理解"删除用户"是敏感操作,从而发现"缺失权限校验"这个逻辑漏洞——该做却没做的事。
Agent 审计的优势就在这里。它能结合代码的上下文背景,跨文件追踪数据流,拼出完整的调用链或协议交互过程,发现 SAST 看不到的深层复杂漏洞。
能力的自然涌现
有意思的是,这种审计能力不是专门训练出来的。
Anthropic 的研究表明,他们没有对 Mythos Preview 做漏洞挖掘的特化训练。漏洞利用能力的飞跃,是代码能力、逻辑推理和自主执行能力整体提升后自然涌现的副产品。数据很直观:在 Firefox 引擎漏洞测试中,Mythos Preview 成功构造 exploit 181 次,上一代 Opus 4.6 只有 2 次;在 OSS-Fuzz 基准测试中,上一代模型只能到 Tier 3,Mythos Preview 在 10 个完全打补丁的目标上达到了 Tier 5(完整控制流劫持)。AI 在代码审计与漏洞利用上的综合能力确实上了一个台阶。
SAST 和 AI 是互补的
虽然 AI 的审计能力有了明显提升,但这并不意味着传统 SAST 会被淘汰。SAST 速度快、结果确定、运行成本极低,仍是不可或缺的基础防线;而大模型的语义推理则覆盖了 SAST 无法触达的深层逻辑与设计盲区,两者是互补关系。
从规则匹配走向语义推理,是代码审计未来的演进方向。但模型能力强不等于能直接进生产——把它放进企业流水线,会立刻撞上几个现实问题。
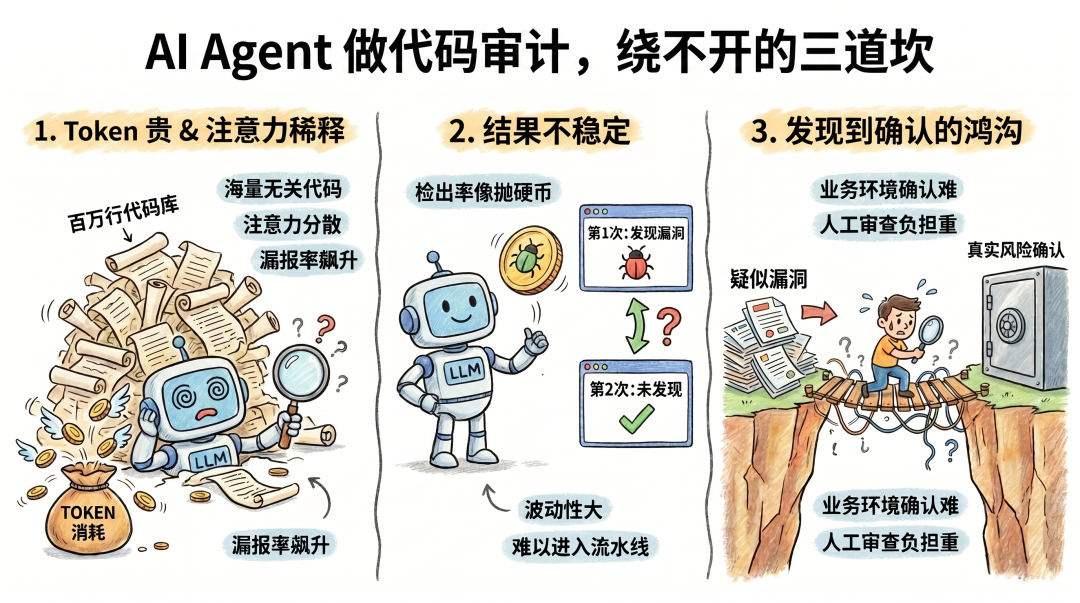
三、直接拿大模型做审计,会撞上三堵墙
大模型语义推理强,但直接拿来做企业级代码扫描,会撞上三个现实问题。
Token 太贵,注意力还会被稀释
大型项目代码库动辄百万行。全量喂给大模型,Token 消耗和计算开销是小事,更要命的是海量无关代码会稀释模型注意力,漏报率飙升。我们在一个项目上做过对比:传统规则扫描检出 219 个发现,大模型独立扫描只检出 28 个。大量常规漏洞都没扫出来。花了很多钱,还漏了很多洞。
结果不稳定
同一个仓库、同样的提示词,跑 10 次,可能 5 次报出了某个漏洞,另外 5 次压根没注意到那个文件。检出率跟抛硬币差不多。但如果你直接把那段代码指给它看,它每次都能找出漏洞。问题不在分析能力,在注意力——代码库太大,它有时候看到了,有时候没看到。SAST 逐文件逐规则扫,跑 100 次结果都一样。这种波动性使其难以进入企业发布流水线,你没法跟开发团队说"这个漏洞今天有、明天可能就没有了"。
从扫描发现到确认漏洞,隔着一道鸿沟
白盒审计里,拿到扫描发现只是起步。判断一个漏洞到底是否有真实危害,要花大量精力。要确认模型提出的漏洞是不是误报、利用的攻击向量是否可达,安全边界是否真的被突破,实际操作中非常麻烦,因为这往往涉及到具体业务环境。经常是"AI 找洞 3 分钟,安全人员协同业务确认 3 天",人工审查负担根本没降下来。
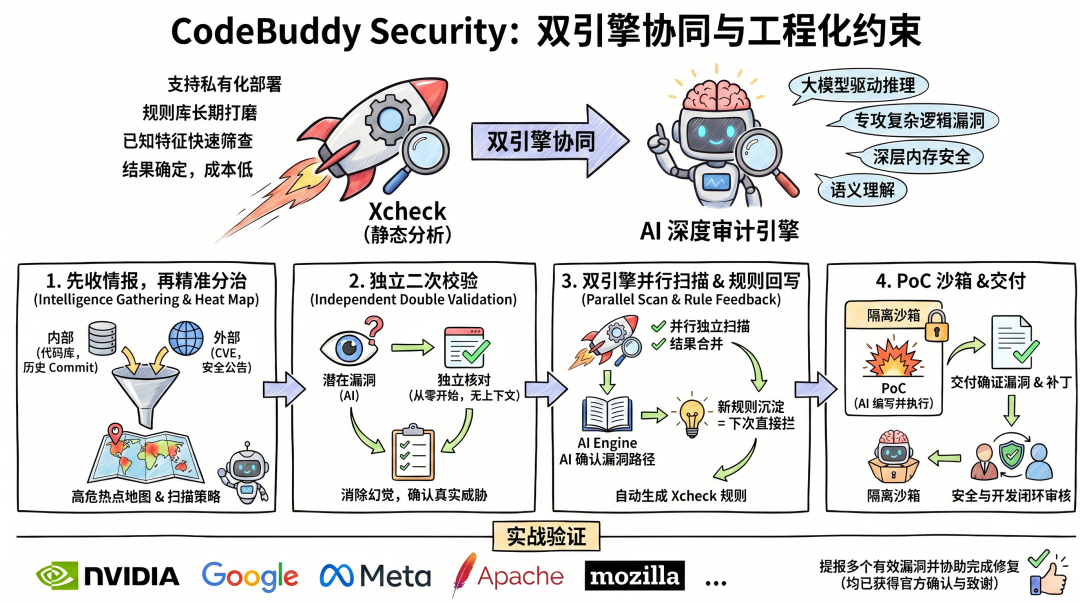
四、 CodeBuddy Security 是怎么做的
今年 1 月,腾讯安全云鼎实验室做了一轮 AI Agent 漏洞挖掘的探索(《未来已来:漏洞挖掘智能体VulnAgent 发现两个Suricata 高危漏洞,并获官方致谢!》)。之后我们在内部多个项目上尝试应用,证实了从发现到验证的完整链路可以工程化落地,并在此基础上,逐步将其打磨并产品化为 CodeBuddy Security。
CodeBuddy Security 的核心思路是 双引擎协同 与 工程化约束。我们把腾讯安全云鼎实验室自研的 AI 深度审计引擎 与静态分析工具 Xcheck 结合起来,构建起一套漏洞挖掘与验证的闭环:
- AI 深度审计引擎:以 CodeBuddy(腾讯自研 AI Coding Agent)为执行底座,专攻传统静态分析因缺乏语义理解和运行时状态建模能力而难以追踪的复杂路径漏洞(如跨模块内存安全缺陷、协议状态机问题及业务逻辑漏洞)。
- Xcheck:支持私有化部署,源码不出网。其规则库在腾讯内部长期安全运营中持续打磨(主流框架和高危函数覆盖充分,并支持自定义扩展),在已知特征漏洞的筛查上速度快、结果确定、成本低。
情报驱动的模块级扫描
系统先定位高风险模块,优先分配深度分析资源。
系统从两路汇入情报:一是从代码库内部提炼——分析目录结构、历史 Commit 的安全信号、高危业务模块;二是拉取外部情报,包括与该项目相关的 CVE 记录、安全公告、已知漏洞修复补丁。两路合在一起定扫描策略:把代码库按模块拆成一批聚焦任务,AI 深度扫描引擎每次只处理一个模块及其关联热点,多轮渐进覆盖整个项目。
模型的注意力不会被海量无关代码稀释,成本随轮次摊薄,不用一次砸进去。
独立二次校验,过滤单次分析的误判
在定位到潜在漏洞后,系统会引入独立的二次校验流程。校验过程完全不依赖前序的分析上下文,而是从零开始重新校验:漏洞代码是否真实存在?触发路径是否真的可行?
这种相互隔离的双重核对,本质上是一个自我证伪的过程。它能有效过滤掉那些看似合理但实际上无法触发的低价值漏洞,消除单次分析中越分析越容易"自我确信"的幻觉,最终筛选出真实存在的安全威胁。
双引擎并行扫描,漏洞自动沉淀为检测规则
Xcheck 与 AI 深度扫描引擎并行独立扫描,结果合并去重,兼顾覆盖率与准确率。此外,AI 每确认一个漏洞路径,就自动生成对应的 Xcheck 检测规则,沉淀进规则库。
每发现一个新的漏洞模式,Xcheck 就多一条可复用的规则。AI 找过的漏洞,下次由静态引擎直接拦,不用再花算力。
PoC 沙箱:在隔离环境里跑通漏洞
静态分析的结论始终是推断。最后一关是在隔离的沙箱里搭建目标环境,由 AI 深度扫描引擎编写 PoC 并实际执行,拿到实打实的攻击证据。
交付给安全人员的不只是一个发现,而是带 PoC 的确证漏洞。通过验证的漏洞自动生成修复补丁,Web 控制台统一展示全部细节,安全与开发团队完成闭环审核。
实战验证
这套以工程架构约束大模型的思路,已经在实战中得到了验证:目前,团队已将该方案应用到大量主流开源基础设施、深度学习框架和底层系统模块中,陆续向 NVIDIA、Google、Meta 等行业巨头,以及 Apache、Mozilla、OISF 等知名开源社区提报了多个有效漏洞并协助完成修复(均已获得官方确认与致谢)。
同时,该方案也已逐步接入腾讯内部发布流水线,在代码上线前为业务规避安全风险。
五、结语:从高效发现走向确证闭环
Agent 时代的代码安全,需要回到工程视角看问题。
模型对代码语义的理解、逻辑推理的深度、以及自主执行能力持续提升,让我们能突破传统静态分析的天花板、触达那些深藏在复杂状态交互中的隐蔽漏洞——这是 AI 漏洞挖掘最重要的底座。但要在企业环境里稳定运行、被流水线信任,仅靠模型还不够,还需要工程架构来约束幻觉、控制成本、把每一次发现与验证组织成可复现的闭环。
随着模型能力的持续提升,从漏洞挖掘到响应处置、从攻击检测到风险治理,整个安全工作流都有望被重新定义。AI 还在快速演进,智能化安全的形态也会随之不断变化;在真实场景中持续打磨、敏捷迭代,是我们应对不确定性最务实的方式。
图片
END
更多精彩内容点击下方扫码关注哦~
关注云鼎实验室,获取更多安全情报
图片
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号