【开源】共工skill技能包-助力技术面试

【开源】共工skill技能包-助力技术面试

AI 生命克劳德
发布于 2026-06-09 11:33:39
发布于 2026-06-09 11:33:39
最近我在做一个面向候选人的 skill。
目标就是:输入一份自己的简历,自动生成简历风险诊断、面试追问清单、模拟面试题和准备优先级。
- Git 项目地址:
https://github.com/yangchao228/gonggong-skills - 面试候选人 Skill 目录:
gongong-candidate-interview-coach
前段时间我先做过一个“技术面试官 skill”。
那个工具是给面试官用的:输入一份简历,帮面试官生成面试题、追问方向和评分要点。
做完以后我发现,这套能力反过来用,对候选人也很有价值。
如果 AI 能站在面试官视角拆简历、找风险、设计追问,那候选人完全可以在面试前,先用同一套视角审自己。
所以我拆出了这版面试者 skill。
它不是再给你一份通用题库。
它真正想解决的是一个更具体的问题:
在你真正坐到面试官对面之前,先知道自己哪里最容易被问穿。
一、最容易翻车的地方,叫追问
很多人准备技术面试,第一反应是刷题。
Redis、MySQL、MQ、JVM、分布式、项目设计,全都过一遍。
这些当然有用。
但真实面试里,很多人其实卡在自己的简历上。
比如简历里写:
“负责订单系统性能优化,接口耗时降低 40%。”
这句话看起来很漂亮。
但面试官真正会追的是:
- 原来慢在哪里?
- 你怎么定位出来的?
- 这 40% 是平均耗时,还是 P95?
- 优化范围是一个接口,还是整条链路?
- 你负责方案设计,还是其中一段实现?
- 上线后有没有副作用?
这些问题不考你会不会背概念。
它们在验证一件事:
这段经历,到底是不是你真实做过。
这就是候选人 skill 的价值起点。
它先不急着帮你准备答案,而是先把这些潜在追问翻出来。
二、这个 Skill 能帮面试者做什么?
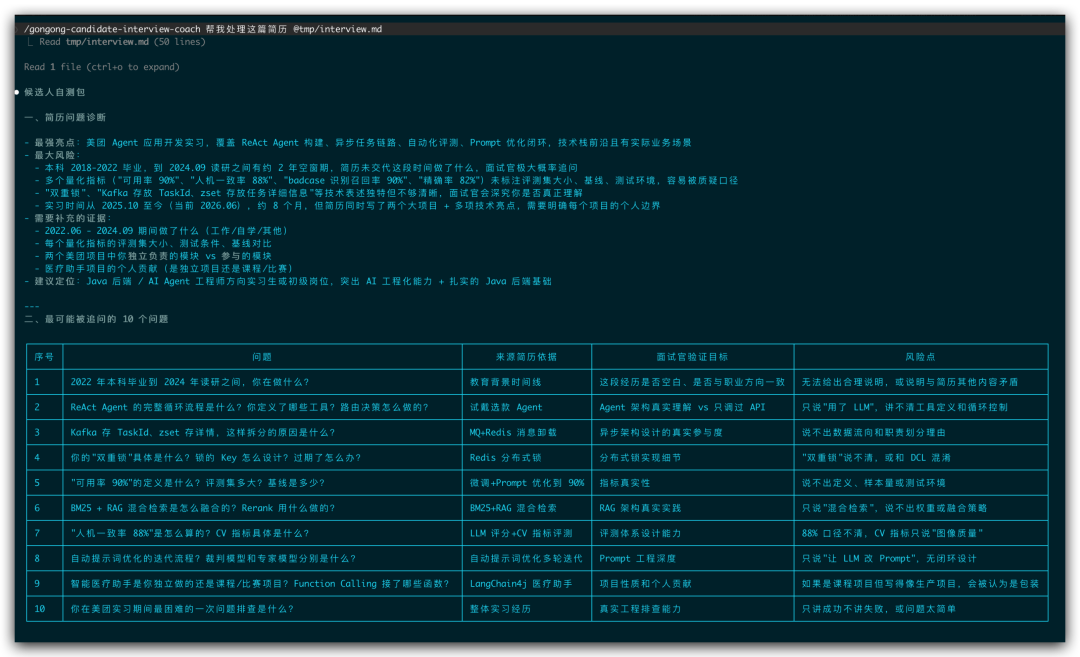
候选人自测包输出示例
候选人自测包输出示例
1.先做简历风险诊断
它会先看你的简历里哪些地方最值得警惕:
- 哪段经历最像亮点
- 哪段表述最空
- 哪个指标缺少口径
- 哪些技术栈只是写了名字
- 哪些地方像团队成果,但没说清个人贡献
这一步最大的好处是:
你会提前知道,简历里哪些地方看起来像加分项,实际可能是风险点。
很多候选人自己看简历,只会看“够不够强”。
面试官看简历,看的往往是“哪里可以继续追问”。
这个 skill 做的第一件事,就是把这两个视角对齐。
2.生成贴着简历的追问清单
通用题库的问题是太宽。
你准备了很多,但不一定打中自己的简历。
这个 skill 生成的问题,会绑定你的简历原句。
比如你写“使用 Redis 优化热点数据访问”,它不会只问“Redis 有哪些数据结构”。
它会继续追:
- 热点数据怎么识别?
- 缓存 key 怎么设计?
- 过期策略是什么?
- 数据一致性怎么处理?
- 出现缓存击穿时怎么兜底?
这类问题对面试者很有用。
因为你的准备会开始围绕自己的项目展开。
3.给出模拟面试题和自评标准
我不希望这个 skill 只停留在“指出问题”。
指出风险以后,它还会继续生成候选人自测包。
里面包括:
- 最可能被追问的 10 个问题
- 每道题的简历依据
- 面试官想验证什么
- 继续追问方向
- 参考回答框架
- 自评标准
- 准备优先级
这比“帮我生成一套 Java 面试题”更实用。
因为它会告诉你:
为什么会问这道题,你应该补什么证据,什么样的回答算有风险。
4.给出简历改写建议和准备优先级
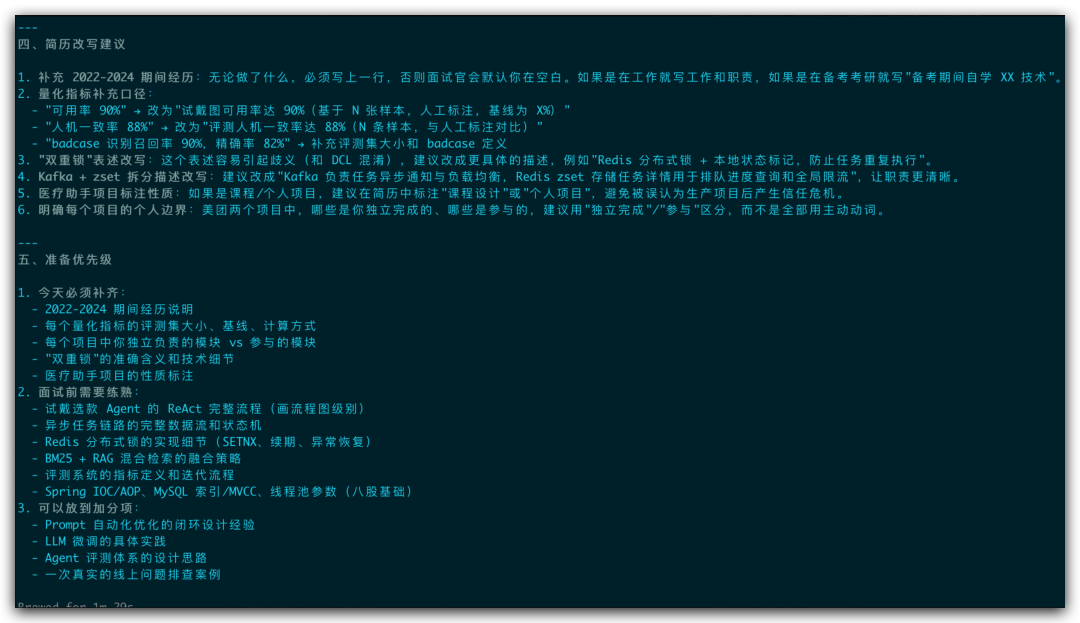
简历改写建议和准备优先级示例
简历改写建议和准备优先级示例
这个亮点很实用:它不会只说“你这里有问题”,还会告诉你怎么补。
比如哪些经历要补时间线,哪些指标要补样本量和基线,哪些项目要写清个人边界。
最后还会分出“今天必须补齐”“面试前需要练熟”“可以放到加分项”。
三、它会逼你补证据
举个例子。
不要只准备一句:
“我做了接口优化,耗时降低 40%。”
更稳的表达应该像这样:
“当时订单详情页在大促期间 P95 耗时偏高,主要慢在多次串行查库和部分字段重复计算。我负责排查链路和改造接口聚合逻辑,把两段串行查询改成并行,并对稳定字段加了本地缓存。上线后在相同压测口径下,P95 从 420ms 降到 260ms。后来复盘发现缓存失效策略还可以更细,这部分如果重做,我会先补监控再灰度。”
这段话没有多华丽。
但它有背景、职责、方案、数据口径和复盘。
面试官继续追问时,你不容易虚。
这也是我给这个 skill 设边界的原因:
- 不替候选人编造项目事实
- 不编指标、样本量和个人贡献
- 缺失信息必须标注“需要你补充”
- 如果某段经历经不起追问,要直接指出风险
面试准备不该只追求更漂亮的表达。
它应该让真实经历更清楚、更扎实,也更经得起追问。
四、如果你明天就要面试,可以怎么用?
我的建议很简单,别一步到位。
先把简历丢给这个 skill,让它做一轮反向审查。
第一步,看简历风险诊断。
先别急着润色,重点看哪些地方被标成“容易追问”“证据不足”“个人贡献不清”。
第二步,看追问清单。
每个高风险项目,至少准备两层追问。
第三步,补证据。
数据口径、个人职责、线上问题、失败复盘、方案取舍,这些比漂亮话更重要。
第四步,做自评。
如果一个项目你讲不清背景、职责、方案、结果和复盘,就先别急着把它写得更大。
五、我这次最大的感受
这次做面试者 skill,我最大的感受是:AI 可以把面试准备变成一套可执行流程。
它可以帮你发现盲区,模拟追问,整理回答框架,建立准备优先级。
但项目事实、真实细节、关键判断,还是要从你自己身上来。
工具越强,人越要清楚哪些部分不能外包。
对候选人来说,AI 可以帮你提前看到问题。
最后能不能讲清楚,靠的是你有没有真的做过,有没有认真复盘过,有没有把自己的经历整理成可验证的证据。
所以如果要把这次实践收成一句话,我会这么说:
AI 负责提前模拟面试官的追问,候选人负责把真实经历补成经得起追问的证据。
这才是这个面试者 skill 对我来说最有用的地方。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号