别再叫它'知识图谱'了,你连本体都没搞清楚

别再叫它'知识图谱'了,你连本体都没搞清楚

老周聊架构
发布于 2026-06-09 19:38:51
发布于 2026-06-09 19:38:51
你跟老板汇报说"我们要建知识图谱",老板兴奋地拍桌子。你说"第一步,我们得先搞本体建模",老板脸就黑了——"什么体?我们是做技术的,不是搞哲学的。"
2026年了,知识图谱已经成了技术圈的"政治正确"——做风控的说我们有知识图谱,做搜索的说我们有知识图谱,做供应链的说我们有知识图谱。
但你仔细一看,大部分所谓的"知识图谱",本质上就是一个关系型数据库的Graph版——把MySQL的表换成了Neo4j的节点和边,结构照抄,逻辑没变。
这就像把汽油车的发动机拆了,换上一块电池,然后跟人说"我们造了一辆电动车"。兄弟,底盘都没改,你换个动力源有什么用?
知识图谱的底盘,就是本体(Ontology)。
今天这篇文章,我们把这个被严重低估的"基建学科"讲透。
一、本体到底是什么?别被"哲学"吓跑
一说"本体论",很多工程师的第一反应是:这不是哲学家亚里士多德搞的东西吗?跟我写代码有什么关系?
关系大了。
用人话说:本体就是对某个领域"是什么"和"怎么关联"的一套形式化定义。
举个例子。你要做一个医疗问答系统,用户问"阿司匹林能治头疼吗?"你的系统要回答这个问题,就需要知道:
- "阿司匹林"是一种药物(概念分类)
- 药物有"适应症"这个属性
- "头疼"是一种症状(概念分类)
- 药物和症状之间存在"治疗"这个关系
把这些概念、属性、关系显式地、形式化地定义出来,就是本体。
没有本体的知识图谱是什么样的?就是一堆三元组:(阿司匹林, 治疗, 头疼)。看起来挺好,但当你的数据源里还有(Aspirin, treats, headache)和(乙酰水杨酸, 可用于, 头痛)的时候,你的系统就傻了——这三个是同一件事吗?
本体的核心价值:让机器理解"同一件事"到底是什么意思。

二、本体构建五步法:从需求到实例
本体构建不是拍脑袋画几个框框连几条线。它有一套成熟的方法论。我把它总结为五步法:
第一步:需求分析——你到底要回答什么问题?
本体不是越大越好,而是够用就好。
关键问题:
- 你的系统需要回答哪些类型的问题?
- 谁来用这个知识图谱?机器推理还是人类查询?
- 数据源有哪些?结构化的还是非结构化的?
一个经典的反面案例:某企业请了一个学术团队花了8个月,建了一个包含2000多个概念的"全量本体"。结果业务方只用到了其中47个概念。剩下的1953个概念,从来没有被实例化过。
我的建议:先列出你的Top 20核心问题,反推需要哪些概念和关系。
第二步:概念抽取——找出你领域的"名词"
概念(Class)是本体的骨架。这一步就是从领域知识中提取出核心概念并组织成层次结构。
以供应链领域为例:
1 物品(Thing)
2 ├── 产品(Product)
3 │ ├── 原材料(RawMaterial)
4 │ ├── 半成品(SemiFinished)
5 │ └── 成品(FinishedGoods)
6 ├── 组织(Organization)
7 │ ├── 供应商(Supplier)
8 │ ├── 制造商(Manufacturer)
9 │ └── 分销商(Distributor)
10 └── 地理位置(Location)
11 ├── 仓库(Warehouse)
12 ├── 工厂(Factory)
13 └── 港口(Port)关键原则:遵循"is-a"测试。 "原材料 is a 产品"——成立。"仓库 is a 组织"——不成立,所以仓库不应该放在组织下面。
第三步:关系定义——找出你领域的"动词"
概念之间通过关系(Property/Relation)连接。关系定义了"谁跟谁有什么关联"。
关系名称 | 定义域(Domain) | 值域(Range) | 说明 |
|---|---|---|---|
suppliesTo | Supplier | Manufacturer | 供应给 |
produces | Manufacturer | Product | 生产 |
storedIn | Product | Warehouse | 存储于 |
locatedIn | Warehouse | Location | 位于 |
hasComponent | FinishedGoods | RawMaterial | 包含组件 |
注意:关系是有方向的。 "供应商 suppliesTo 制造商"和"制造商 suppliedBy 供应商"是两个方向的同一件事。在OWL里可以用owl:inverseOf来定义反向关系。
第四步:属性设计——给概念加上"形容词"
数据属性(Data Property)描述概念的特征值:
1 Product:
2 - name: string
3 - sku: string
4 - unitPrice: decimal
5 - weight: decimal
6 - shelfLife: integer (天)
7
8 Supplier:
9 - companyName: string
10 - creditRating: string (A/B/C/D)
11 - leadTime: integer (天)
12 - annualCapacity: integer第五步:实例填充——骨架上长肉
有了概念、关系、属性这套骨架,最后一步就是往里填充具体的实例(Individual):
1 实例: "台积电"
2 类型: Manufacturer
3 属性: companyName="台积电", creditRating="A"
4 关系: produces → "A16芯片"
5 关系: locatedIn → "新竹科学园区"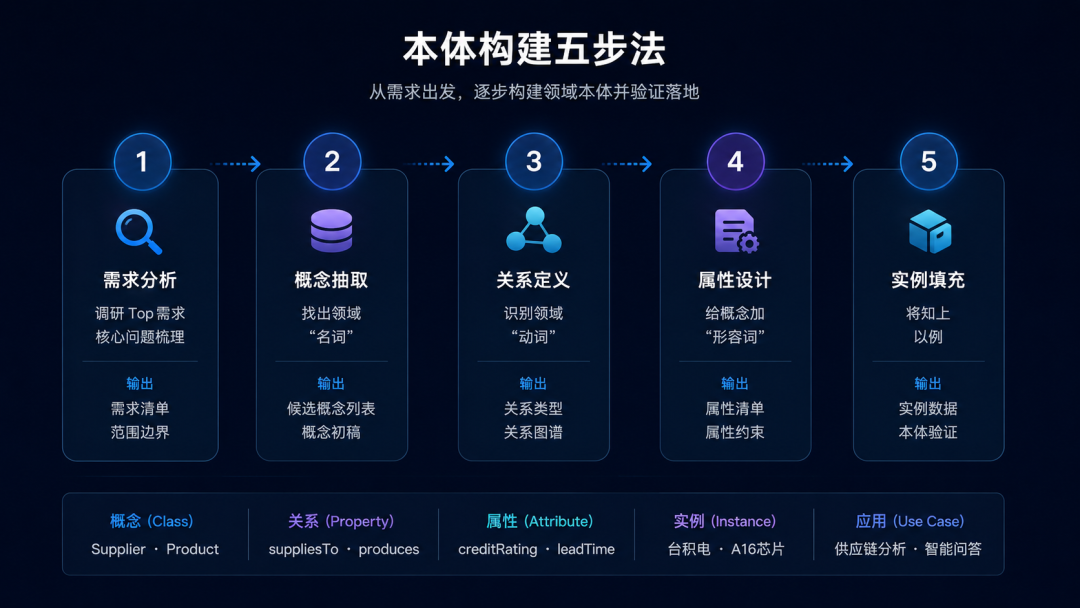
三、OWL:本体的"编程语言"
你不能用自然语言写本体——机器读不懂。你需要一种形式化的语言。OWL(Web Ontology Language)就是当前最主流的本体描述语言。
OWL的三个表达力等级
子语言 | 表达力 | 推理复杂度 | 适用场景 |
|---|---|---|---|
OWL Lite | 低 | 可判定 | 简单分类层次 |
OWL DL | 中 | 可判定(最坏指数级) | 大多数企业应用 |
OWL Full | 高 | 不可判定 | 学术研究(实际几乎没人用) |
99%的企业场景用OWL DL就够了。 它在表达力和推理效率之间取得了最佳平衡。
OWL的核心语法——用代码说话
用Turtle语法定义一个供应链本体的片段:
1 @prefix sc: <http://example.org/supply-chain#> .
2 @prefix owl: <http://www.w3.org/2002/07/owl#> .
3 @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
4 @prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
5
6 # 定义类
7 sc:Product a owl:Class .
8 sc:RawMaterial a owl:Class ;
9 rdfs:subClassOf sc:Product .
10 sc:Supplier a owl:Class .
11 sc:Manufacturer a owl:Class .
12
13 # 定义对象属性(关系)
14 sc:suppliesTo a owl:ObjectProperty ;
15 rdfs:domain sc:Supplier ;
16 rdfs:range sc:Manufacturer .
17
18 sc:suppliedBy a owl:ObjectProperty ;
19 owl:inverseOf sc:suppliesTo . # 反向关系
20
21 # 定义数据属性
22 sc:creditRating a owl:DatatypeProperty ;
23 rdfs:domain sc:Supplier ;
24 rdfs:range xsd:string .
25
26 # 定义属性约束——每个产品至少有一个供应商
27 sc:Product rdfs:subClassOf [
28 a owl:Restriction ;
29 owl:onProperty sc:suppliedBy ;
30 owl:minCardinality "1"^^xsd:nonNegativeInteger
31 ] .
32
33 # 不相交声明——供应商和制造商不能是同一个实体
34 sc:Supplier owl:disjointWith sc:Manufacturer .几个关键语法解释:
rdfs:subClassOf:定义继承关系,"原材料是产品的子类"owl:ObjectProperty:定义实体间的关系owl:DatatypeProperty:定义实体的属性值owl:Restriction+owl:minCardinality:约束条件,"每个产品至少有1个供应商"owl:disjointWith:互斥声明,"供应商和制造商是不同的概念"
Protégé:本体的"Visual Studio"
手写OWL语法效率太低。Protégé是斯坦福大学开发的本体编辑工具,可以可视化地创建和编辑本体,自动生成OWL代码,还能调用推理引擎验证一致性。

Protégé的核心能力:
- 可视化编辑:拖拽创建概念、关系、属性,所见即所得
- 推理验证:内置HermiT、Pellet等推理引擎,一键检查本体一致性
- SPARQL查询:直接在本体上跑查询,验证建模是否正确
- 导入导出:支持OWL/XML、Turtle、JSON-LD等多种格式
一个实用的小技巧:在Protégé里建好本体后,用推理引擎跑一次。如果推理器报告"不一致(Inconsistency)",说明你的本体有逻辑矛盾——比如你声明了"供应商和制造商不相交",但又创建了一个实例同时属于这两个类。这类错误在手写OWL时极难发现。
四、知识图谱全流程:从数据到图
有了本体这个骨架,接下来就是知识图谱的全流程构建。我把它分成四个阶段:
4.1 数据源梳理——你的数据在哪里?
数据类型 | 典型来源 | 抽取难度 | 示例 |
|---|---|---|---|
结构化数据 | MySQL、ERP、CRM | 低 | 订单表、客户表、产品表 |
半结构化数据 | JSON/XML/API | 中 | 供应商接口返回、配置文件 |
非结构化数据 | 合同PDF、新闻、邮件 | 高 | 招投标文件、行业报告 |
经验之谈:大多数企业80%的有价值知识藏在非结构化数据里,但80%的团队只处理了结构化数据。
4.2 知识抽取——从文本中挖三元组
知识抽取的核心任务是从各类数据源中抽取实体、关系、属性,形成三元组。
实体抽取(NER):
1 输入:"台积电于2025年Q3向苹果交付了500万颗A16芯片"
2
3 抽取结果:
4 实体1: 台积电 → Manufacturer
5 实体2: 苹果 → Manufacturer
6 实体3: A16芯片 → Product
7 属性: 交付数量=500万颗, 时间=2025年Q3关系抽取(RE):
1 三元组1: (台积电, suppliesTo, 苹果)
2 三元组2: (台积电, produces, A16芯片)
3 三元组3: (苹果, purchases, A16芯片)2026年,大模型在知识抽取上已经碾压了传统NLP方案。用Claude或GPT做Few-shot抽取,F1值普遍能到85%+,远超传统BERT-CRF的70%左右。
4.3 知识融合——最容易被忽视的"脏活"
你从10个数据源抽取了实体,结果发现:
- 数据源A叫"台积电"
- 数据源B叫"TSMC"
- 数据源C叫"台湾积体电路制造股份有限公司"
- 数据源D叫"台积电(南京)"
这是同一个实体吗?还是不同的实体?
知识融合要解决三个问题:
问题 | 说明 | 常用方法 |
|---|---|---|
实体消歧 | "苹果"是水果还是公司? | 上下文语义消歧、知识库链接 |
实体对齐 | "台积电"="TSMC"吗? | 字符串相似度 + 属性对比 + 图结构匹配 |
实体去重 | 同一个数据源里的重复 | 聚类 + 规则 |
这一步是整个知识图谱构建中最耗人力、最容易出错的环节。 我见过太多团队在实体抽取上花了3个月,在知识融合上花了6个月。
4.4 知识存储——为什么选图数据库?
知识图谱的存储方案主要有三类:
存储方案 | 代表产品 | 优势 | 劣势 |
|---|---|---|---|
原生图数据库 | Neo4j, TigerGraph | 图遍历性能强,Cypher/GSQL语法直观 | 超大规模下性能衰减 |
三元组存储 | Apache Jena, Blazegraph | 原生支持RDF/SPARQL,语义推理强 | 查询性能较弱 |
关系型改造 | MySQL + 邻接表 | 团队熟悉,迁移成本低 | 多跳查询性能差 |
大多数企业级场景,Neo4j是最稳妥的选择。 社区活跃度、文档质量、工具生态都是行业第一。而且Neo4j 5.x在多跳查询性能上有了质的飞跃。
五、本体论在业务场景中怎么用?
理论讲完了,来看看真实业务场景。
场景1:智能检索——让搜索"理解"你
传统关键词搜索:"感冒吃什么药"→匹配包含"感冒"和"药"的文档。
基于本体的语义搜索:
- 识别"感冒"→ 疾病概念,扩展到上位概念"上呼吸道感染"和下位概念"流感"
- 识别"药"→ 治疗药物,关联关系"treats"
- 查询图谱:所有
(Drug) -[treats]→ (感冒 OR 上呼吸道感染)的实例 - 返回:对乙酰氨基酚、布洛芬、奥司他韦……并标注各自适应症
搜索准确率从关键词匹配的60%提升到语义检索的85%+。
场景2:风控反欺诈——看见"看不见的关系"
一个人申请贷款,征信报告干干净净。但知识图谱发现:
- 他的紧急联系人B,是另一个逾期客户C的配偶
- C的公司D,跟他的工作单位E共享同一个注册地址
- E的法人F,在过去6个月内注册了12家公司
这些关系在传统的表结构里是看不见的。 但在图数据库里,一个3跳查询就能把整个关联网络拉出来。
场景3:企业架构——Palantir的"存在之道"
Palantir是本体论在企业级应用中的教科书级案例。
Palantir Foundry的核心不是算法,是Ontology Layer——一个统一的本体层,把企业内部所有数据源(ERP、CRM、IoT传感器、供应链系统)映射到同一套语义模型上。
Palantir CEO Alex Karp说过:"Our ontology is the single most important piece of intellectual property we have."——我们的本体是我们最重要的知识产权。
这不是在吹牛。 Palantir靠这套本体层,帮Airbus优化了供应链,帮美军做了战场态势感知,帮NHS管了疫情数据——而底层的技术核心,就是一个精心设计的本体。
国内也有类似的玩家。某头部云厂商的"数据中台"产品,核心就是一个行业本体库——金融版、制造版、医疗版——帮企业快速建立领域知识图谱。
六、本体论的2026:大模型时代的"文艺复兴"
你可能会问:大模型这么强了,还需要本体吗?
不仅需要,而且比以前更需要。
大模型的核心问题是幻觉(Hallucination)。它能生成流利的回答,但不保证正确。而本体+知识图谱提供了一个可验证的事实基础——大模型可以先查图谱,再生成回答,把幻觉率从20%降到5%以下。
这就是GraphRAG的核心思路:
1 用户提问 → 大模型理解意图 → 查询知识图谱 → 基于图谱结果生成回答微软2025年开源的GraphRAG论文,在多跳问答任务上比朴素RAG的准确率高了26个百分点。而GraphRAG的基础,就是一个自动构建的本体+知识图谱。
本体论不是被大模型取代了,而是成了大模型的"事实校验层"。
写在最后
本体论这个学科,诞生于2000年代的语义网(Semantic Web)运动。当年Tim Berners-Lee的愿景太超前了,技术和数据都不成熟,语义网没能成为主流。
但20年后的今天,大模型补上了"理解"的短板,图数据库补上了"存储"的短板,本体论终于等到了它的时代。
我的判断是:
2026-2028年,本体+知识图谱+大模型的组合,将成为企业AI应用的"标准三件套"。 不搞本体就上知识图谱,就像不打地基就盖楼——楼越高,塌得越快。
下一篇文章,我会手把手带你用Neo4j + Python + Claude,从零构建一个企业供应链知识图谱。理论讲完了,该撸代码了。
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号