中小企业必备AI数字员工,已开源,Claude Code/Codex 一句话安装,陆续更新中

中小企业必备AI数字员工,已开源,Claude Code/Codex 一句话安装,陆续更新中

Ai学习的老章
发布于 2026-06-09 20:16:41
发布于 2026-06-09 20:16:41

大家好,我是 Ai 学习的老章
我之前有一篇文章介绍 Claude 的 Agent 工作流# Claude 掀桌子了,放出 15 个 Agent 工作流,中小企业的“数字员工”正式上岗
但是,一是这些工作流都只能在 Claude app 中使用,要复刻也可以,就是麻烦一些;二是,这里面的“数字员工”感觉有点不接地气,不适合国内宝宝体质
我自己创建了很多适合自己的 Skills,用着非常顺手,比如 用 Skills 武装你的写作工作流 ,公开课 PPT,我个人使用的还有 AI 辅助写作、视频生成相关,还有编程相关,但是这些其实在企业尤其是中小企业中反而小众
我计划把自己创建/使用体验很好的 AI Agent Skill 开源,它们是我在日常工作中反复打磨出来的"数字员工"。第一批放出的几个——读邮件、解析文档、提取表格、采集素材,一条龙搞定那些重复性高但又不能出错的活儿
为什么叫"数字员工"
很多朋友一听 AI 就觉得高大上,觉得跟自己没关系,但实际上,比起遥远的 AGI 通用智能,中小企业更迫切需要的是能稳定执行具体任务的数字助手:
- 每天要手动查收邮件、下载附件、整理内容,很多阅后即焚,没有沉淀
- 拿到各种单据/或几百页的 PDF 合同,要提取里面的关键信息
- 做完分析报告,里面一堆 Markdown 表格要导出给领导看 Excel
- 需要从多个网页采集竞品资料,整理成文档
这些活儿,每一件都不难,但加在一起就是巨大的时间黑洞
我开源的这套 Skills,就是让 AI Agent(比如 Claude Code、Qoder、Cursor 等)变成你的专属数字员工,一个指令搞定整条链路
项目地址
GitHub:github⋅com/tjxj/z-skills
目前包含 5 个 Skill,后续会持续更新
一句话装到你的 Agent 工具里
这套 Skill 设计上走的是说人话优先,命令行参数只是锦上添花。不管你用的是 Claude Code、Codex、Qoder、Cursor,还是其它支持 Skill / Subagent 机制的 Agent 工具,都能一句话装上:
把 github⋅com/tjxj/z-skills 这个仓库里的 5 个 skill
克隆到本项目的 skill 目录,然后启用
Agent 会自己走 git clone、读 SKILL.md、装依赖、注册到工具的 skill 目录里。装完之后,后续所有使用都不需要你再记任何命令——你只管发指令,它负责调度
1. z-mail-reader — 邮件读取与实时监听
这是我最早做的一个 Skill,因为我实在受不了每天早上打开邮箱手动翻邮件了
它能做什么:
- 通过 IMAP 协议连接任意邮箱,按时间范围批量拉取邮件
- 自动下载所有附件到本地
- 自动提取正文中的内嵌图片(CID 内联图、HTML 外链图、Base64 嵌入图全支持)
- 输出结构化 JSON,Agent 可以直接生成摘要
- 支持 30 秒轮询实时监听,新邮件到了自动处理 + 系统通知
- 充分兼容中文邮件:自动识别 UTF-8 / GBK / GB2312 编码,不会乱码
使用前的一次性配置:
告诉 Agent:
帮我把 z-mail-reader 需要的邮箱环境变量配上,IMAP 地址 imapqqcom,
邮箱 your_email@qq com,授权码 xxx
主流邮箱(QQ / Gmail / 163 / Exchange / 企业邮箱)只需换一下 IMAP 地址即可。QQ 邮箱获取授权码:设置 → 账户 → POP3/IMAP/SMTP服务 → 开启 IMAP → 生成授权码
在 Agent 里一句话调它:
常用说法随便举几个:
读一下最近 7 天的邮件,给我生成一份摘要
拉一下这周邮件,附件都下下来
看一下 6 月 1 号到今天的邮件,重点提取合同类邮件
开始监听邮件,新邮件来了就推个系统通知给我
停一下邮件监听
Agent 会自动映射到 read_emails.py / listen_emails.py 上,补齐时间范围、输出路径这些参数。你不需要记任何命令。安装也一句话说人话,我这里写的 README 是专门为 Agent 使用优化过的
输出的目录结构很清晰:
mails/
└── 20260607_1430_项目进度汇报/
├── 报告.pdf # 附件
├── images/ # 正文图片
│ └── img_001.png
└── sum.md # Agent 生成的摘要
典型场景:每天早上上班让 Agent 先跑一遍,十几封邮件不到一分钟生成一份摘要清单,重要的附件已经下好、正文图片也提取出来了,手动那点翻邮件的麻烦可以永远省了
它也可以与后面的几个 Skills 联动,比如邮件附件的解析
2. z-smart-xparse — 智能文档解析
这个是文档解析的增强版,核心亮点是大 PDF 自动切分合并
实际工作中经常遇到几十 MB、几百页的 PDF(招标文件、合同、技术规范书),直接丢给解析 API 必然超限。这个 Skill 会自动检测文件大小和页数,超了就切成小块逐个解析,最后合并成一份完整结果
底层是 textin 的 xparse-cli,一句话安装:
告诉 Agent:
帮我装一下 xparse-cli 和 qpdf,z-smart-xparse 要用
它会自己走官方脚本 + brew/pip 装上。你只要看一下运行结果就行。按需出现,不需要不用都可以
判断逻辑:
条件 | 动作 |
|---|---|
≤ 5 MB 且 ≤ 100 页 | 直接解析 |
> 5 MB 或 > 100 页 | 自动切分 → 逐块解析 → 合并 |
默认每块 50 页(贴合免费 API 限制),配置付费 API 后可上调到 200 页一块,处理效率更高
支持格式超广:
- PDF、图片(免费 API,零配置)
- Word/PPT/Excel/HTML/OFD/RTF 等(需配置付费 API)
- PDF指定页码范围、字符级结构化输出
在 Agent 里一句话调它:
最主流的用法就是扔个文件过去:
把这份 report.pdf 转成 markdown
这份 300 页的招标书读一下,提取关键资质要求和评分规则
只解析 contract.pdf 的前 5 页
这是张扫描件合同,帮我转文本并提取表格
Agent 会自己判断:是否需要切分、是否需要付费 API、是否走 OCR,全部默认最合适路径。大文件的切分、逐块解析、合并也都是它后台走,你只看结果就行
典型场景:300 页的招标文件、扫描件合同、几十 MB 的技术规范书,丢给 Agent 一句“转成 markdown”,能直接拿到一份表格、标题层级都保留的本地文档
3. z-md-excel — Markdown 表格提取到 Excel
这个 Skill 看着简单,但用起来真的爽
做技术调研的时候,我习惯在 Markdown 里用表格整理对比信息。但汇报的时候领导要看 Excel,每次手动复制粘贴调格式简直要命
现在一句话搞定:把 xx.md 中的表格保存为 excel
亮点:
- 自动检测 Markdown 文件中的所有表格,每个表格一个 Sheet(名为 Table_1 / Table_2 …)
- 保留 GFM 对齐方式(左对齐、居中、右对齐)
- 自动去除 Markdown 格式(粗体、链接、代码标记等),输出干净文本
- 蓝色表头、自适应列宽、冻结首行,开箱即用的专业格式
- 自动跳过代码块里的“伪表格”,不会误识
在 Agent 里一句话调它:
把 xx.md 里的表格导出成 Excel
这份调研笔记里有三个对比表,都给我转成 Excel
把上面生成的 Markdown 表格保存为《产品调研.xlsx》
Agent 会自动调用 md2xlsx.py,多个表格会自动拆成多个 Sheet,你不需要手动指定任何参数
典型场景:技术选型对比、产品能力矩阵、供应商报价表,写的时候在 Markdown 里骨架清晰,交付的时候一句话转成带表头、冻首行、列宽适宜的 Excel,领导高兴
限制:只支持 GFM 管道式表格(| col1 | col2 |),不支持 HTML <table> 和嵌套表
4. z-excel-editor — Excel 全能编辑
这个 Skill 来自 Claude Code 开源社区(Anthropic 官方发布),我把它集成进来了,专门处理各种 Excel 操作
从创建新表格、编辑现有文件、添加公式、格式美化,到金融模型的专业规范(颜色编码、公式错误检测),一应俱全
核心能力:
- 使用 openpyxl 创建/编辑 .xlsx,保留公式和格式
- 内置 LibreOffice 公式重算脚本(
recalc.py),确保公式值实时更新 - 金融模型颜色规范:蓝色=输入值、黑色=公式、绿色=跨表引用、红色=跨文件引用、黄底=重点假设
- 数字格式规范:年份走文本、货币用
$#,##0、零值显示为-、负数走括号(123)、估值倍数0.0x - 设计哲学:公式优先,永远不要把 Python 算出的值硬写到单元格,保证源数据变了表能重算
- 自动扫描并报告公式错误(
#REF!、#DIV/0!、#VALUE!、#NAME?、#N/A),返回 JSON 错误定位
另外它要求交付的表一定 零公式错误,你丢一份凌乱的后台导出表给它,它会自己检错、重算、补公式,最后交一份能直接上报的 Excel
在 Agent 里一句话调它:
把这份 sales.xlsx 加上表头、合计公式和环比增长率
这份财务模型帮我扫一下公式错误,能修的顺手修了
把这张估值表按金融模型颜色规范重新整理(输入值蓝色、公式黑色、跨表引用绿色)
新建一份 2026 年运营预算表,带季度合计和全年合计公式
Agent 会调 openpyxl 写公式、用 LibreOffice 重算、扫错、修错,你只需要看最终输出
典型场景:业务数据表补公式加表头、财务模型扫错、估值表格式规范化、给领导交付颜色与公式都专业的报表
5. z-web-pack — 网页素材包采集
搭建个人知识库,分享一个我原创的 Skills这篇文章中我已经详细介绍过这个 Skills,但是大家应该没有看懂,这是建个人知识库的前置步骤,只做采集,最核心的是链接下钻和图片保存
在 Agent 里一句话调它:
把这些链接采集为《竞品分析》素材包:xxx
这是 5 个同主题的官方文档链接,帮我准备一份完整资料包,只采同域
Agent 会自动调 collect_web_pack.py,补齐 --title--max-depth--max-pages 这些参数,抓不到的页面会自动走 jina ai 兜底
输出一个完整的素材包:
2026-06-08-竞品分析/
├── README.md # 素材包概览
├── 00-research-brief.md # 研究简报
├── 01-link-inventory.md # 链接清单
├── 02-image-inventory.md # 图片清单
├── 03-reading-map.md # 阅读地图
├── MAIN-01-入口正文.md # 主文正文
├── LINKED-02-相关链接.md # 关联文章
└── assets/ # 本地图片
这里 MAIN-*.md 是你丢进去的入口文章,LINKED-*.md 是从正文里推出来的关联资料,全部转成本地 Markdown,图片下到 assets/ 后走本地相对路径,离线也能读
抓取策略上手动跳了很多坑:
- 先走常规 HTTP 抓正文
- GitHub 链接走 GitHub API / raw / README
- Markdown / JSON / 纯文本资源直接保存
- 实在抓不到或只抓到登录提示才用 r.jina.ai 兜底
自动排除侧边栏、广告、页脚、社交分享按钮、推荐阅读区这些噪音,只保留正文核心内容。同时跳过登录、订阅、隐私、服务条款、Cookie 这类与主题无关的页面
典型场景:文章选题的资料准备、竞品产品调研、文献综述、咨询类报告初期资料多点位采集。扔一批链接过去,一杯咖啡的时间拿到一份带本地图片、能离线读的完整资料包
重要提醒:需要根据实际情况定制
这里必须说清楚一件事——这些 Skill 不是拿来就能直接用的万能模板
每个企业的实际情况不同,直接复制粘贴也会遇到问题:
邮件系统差异:
我的案例写的是 QQ 邮箱(IMAP 地址 imap.qq.com),但你们公司可能用的是 Exchange、Gmail、企业微信邮箱甚至自建邮件服务器。IMAP 地址、授权方式、文件夹命名规则都不一样,需要改配置
文档解析需求不同:
有的企业主要处理扫描件 PDF(需要 OCR),有的主要处理 Word 合同(需要保留格式),有的需要提取表格数据做后续计算。解析精度、输出格式、后处理逻辑都要根据你的业务场景调整
目录结构和命名规则:
我的输出路径、文件命名方式是适配我自己工作流的。你需要改成适合你团队协作习惯的路径和命名规范
但这就是 Skill 的设计哲学——给你一个经过验证的骨架,你在上面长自己的肉
串联起来:Agent 工作流才是终极形态
单个 Skill 已经很有用了,但真正的威力在于把它们串成工作流。而串联起来之后,你在 Agent 里还是一句话触发整条链,中间各个 Skill 之间怎么传参、怎么调度,是 Agent 自己的事
下面这张图展示了一条完整的自动化链路,从收邮件到产出 Excel,全程无人值守:
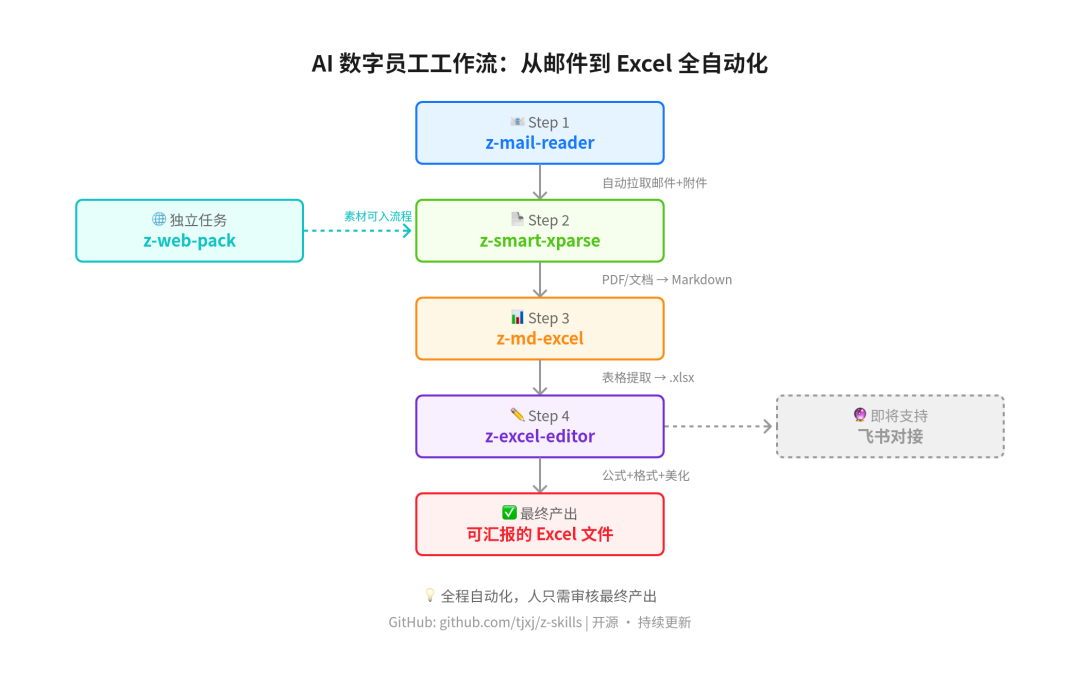
AI 数字员工工作流
AI 数字员工工作流
你在 Agent 里只需要说一句:
拉一下今天邮件,遇到 PDF 附件都解析成 markdown,
里面的表格导出为 Excel,最后补全公式、按金融模型颜色规范整理好
Agent 会依次调起 z-mail-reader、z-smart-xparse、z-md-excel、z-excel-editor,把上个产出作为下个输入,最终交一份可直接汇报的 Excel
拆解成链路看的话是这样的:
邮件到了 → z-mail-reader 自动拉取
↓
附件是 PDF → z-smart-xparse 解析成 Markdown
↓
Markdown 里有表格 → z-md-excel 导出 Excel
↓
Excel 需要加工 → z-excel-editor 添加公式、美化格式
↓
最终产出一份可直接汇报的 Excel 文件
整条链路下来,从收到邮件到产出结果,全程自动化,人只需要审核最终产出
其实这几个 Skill 可以任意组合,再举几个听得出场景的例子:
场景一:竞品产品周报
z-web-pack 多入口采集竞品资料 → 输出主文 + 关联 Markdown
↓
z-md-excel 把产品能力对比表输出为 Excel
↓
z-excel-editor 加上表头、公式、颜色规范 → 汇报用 Excel
场景二:招标文件快速合规
z-mail-reader 拉招标邮件 + 下载附件
↓
z-smart-xparse 解析数百页招标书 → 输出 Markdown
↓
Agent 读 Markdown、提取关键指标 → 生成快速合规报告
场景三:财务月报闭环
z-mail-reader 拉业务部门发过来的月度报表邮件
↓
z-smart-xparse 解析附件中的 PDF / Excel 源表
↓
z-excel-editor 按金融模型规范重构报表 + 扫公式错误
后面我还计划对接飞书,实现更多自动化场景:
- 邮件摘要自动推送到飞书群
- 文档解析结果自动写入飞书多维表格
- 定时采集竞品信息,自动更新飞书文档
总结
这套开源 Skill 集合,本质上是把 AI Agent 从"聊天机器人"变成"能干活的数字员工"
为什么要走 Skill 这条路、而不是直接跟大模型对话:
- 流程可复现:一次写好,千次复用,不会因为提示词措辞不同而出现偏差
- 可审核可调试:脚本、参数、输出都是明文的,出了问题能定位
- 跨 Agent 工具:Claude Code、Qoder、Cursor 都能跳,不被单一厂商锁定
- 多个 Skill 能串起来:上一个的输出是下一个的输入,拼出真正的全流程自动化
适合什么人用:
- 中小企业里负责信息处理、文档管理的同事
- 想用 AI Agent 自动化日常工作流的技术/半技术人员
- 正在用 Claude Code / Qoder / Cursor 等 Agent 工具的开发者
- 想看看"别人是怎么写 Skill 的"、照着骨架去创建自己专属数字员工的同学
我会持续更新更多实用 Skill,欢迎 Star 关注 🌟
如果你有什么日常工作中的痛点想做成 Skill,评论区告诉我,说不定下一个就安排上了
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号