打造成长型大模型的技术思路

打造成长型大模型的技术思路

Goblin-顾浩
发布于 2026-06-15 20:15:21
发布于 2026-06-15 20:15:21
这是一个非常前沿且具有挑战性的想法。在目前的AI架构中,模型通常分为“训练态”和“推理态”,二者是分离的。我们总会期望AI是能进化的,也就是所谓“边聊天边进化”的成长型大模型,核心要解决的是持续学习(Continual Learning)和灾难性遗忘(Catastrophic Forgetting)的问题。
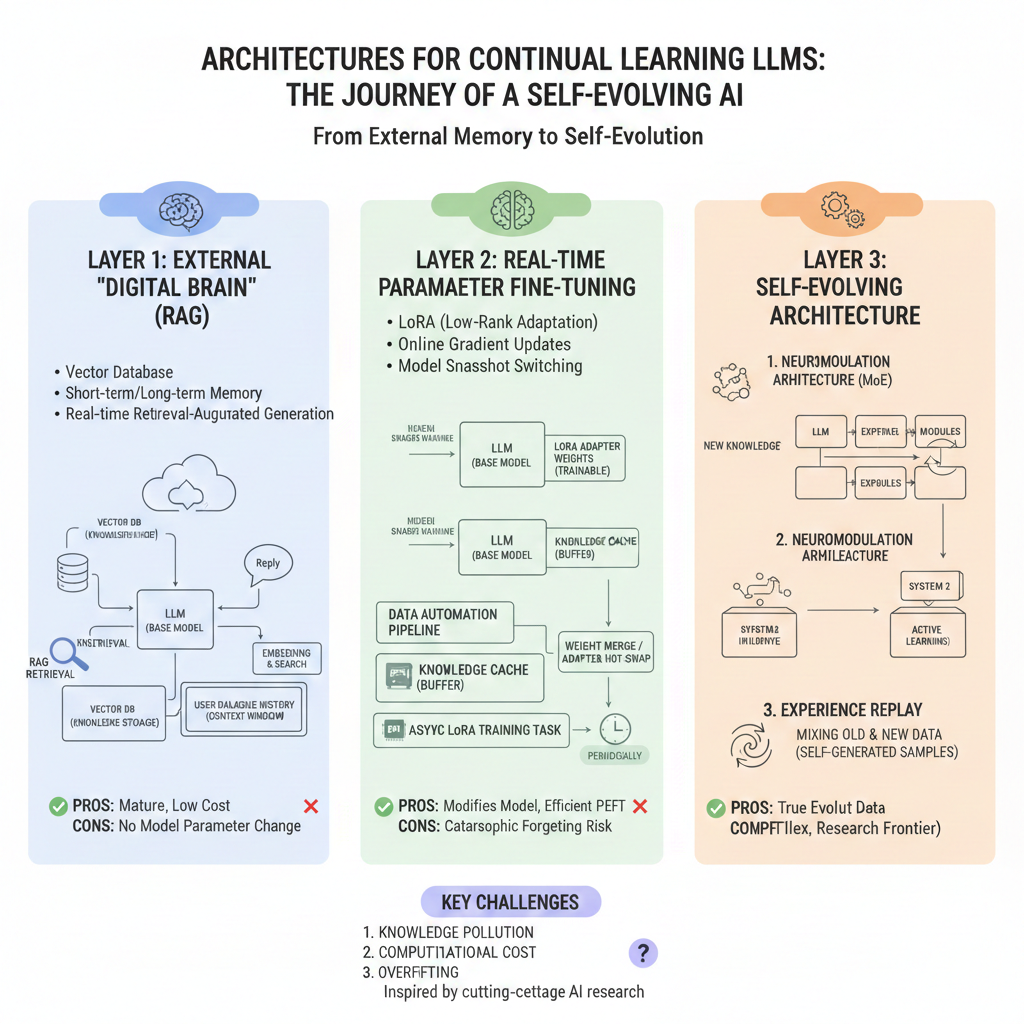
实现这一目标的三层技术路线,从“外挂式”到“内生式”深度递进,我大概整理了下思路:
第一层:外挂“数字大脑” (RAG + 动态记忆仓)
这是目前最成熟、成本最低的路线。它不改变模型参数,而是给模型穿上一层“记忆外壳”。
- 技术细节:
- 向量数据库(Vector DB): 实时将你和它的对话、你教给它的知识进行 Embedding(向量化),存入向量数据库。
- 长短期记忆切换: 模仿人类,短期对话存在上下文(Window),长期知识存入向量库。
- 实时检索增强(RAG): 模型在回答你之前,先去向量库里“搜一下”之前你教过它的相关内容。
- 成长感: 你教它的东西,它能通过检索“想起来”,看起来像是在不断学习。
第二层:实时参数微调 (Online PEFT / LoRA)
这进入了“改变模型本体”的层面。让模型在空闲时间或对话间隙,对自己进行小规模的“在线微调”。
- 技术路线:
- LoRA (Low-Rank Adaptation): 这种技术只训练模型极少量的旁路参数(通常小于1%)。你可以为每个用户或每个知识领域维护一个轻量级的 LoRA 权重。
- 在线梯度更新: 当系统判定你提供的是“高质量新知识”时,自动触发一个小批量的训练任务。
- 模型快照切换: 训练完成后,无缝热替换模型权重。
- 核心难点: 这种方法容易导致“灾难性遗忘”——模型记住了新知识,却可能突然忘了怎么写代码。
第三层:高深路线——自进化框架 (Self-Evolving Architecture)
这是目前顶级实验室(如 OpenAI, DeepMind)正在探索的方向,让模型具备“自我优化”的逻辑闭环。
1. 神经调节与自适应门控 (Neuromodulation)
模拟生物大脑的神经调节机制。引入**MoE(混合专家模型)**架构,当有新知识进来时,模型不是修改所有权重,而是自动分配或新建一个“专家模块”来承载这部分知识。
2. 双系统架构 (Dual-System Theory)
- 系统1(直觉系统): 冻结的大模型底座,负责基础语言能力和通用常识。
- 系统2(思考/学习系统): 一个较小的、可高度活跃更新的学习器。它负责消化你的新知识,并在后台与“系统1”进行“知识对齐”。
3. 经验回放 (Experience Replay) 与生成式重放
为了防止模型变傻,在训练新知识时,系统会从旧的训练集中抽取一部分数据,或者让模型自我生成一些旧知识的样本,和新知识混合在一起训练。这叫“温故而知新”。
深入实施方案:你可以如何搭建?
如果你想亲手实现一个简易版,可以参考这个流程:
- 数据自动标注器: 用一个更强的模型(如 GPT-4o)作为“导师”,实时监测你的对话,将有价值的信息提取成
Instruction: ... Response: ...的训练格式。 - 异步微调管道: * Step A: 对话产生的知识进入缓存区。
- Step B: 当缓存积累到一定量(如50条),自动启动一个 LoRA 训练任务(在后台 GPU 运行)。
- Step C: 训练完成后,使用 Merge 或是 Adapters 动态加载 技术,让你的对话界面无感切换到新版本。
我用Nano Banana 帮我画了张图:
潜在的技术风险
- 知识污染: 如果你教了它错误的东西,它会产生“幻觉”并固化在参数里。
- 算力成本: 虽然 PEFT 很省,但频繁的训练和权重加载依然对硬件有要求。
- 过拟合: 针对单一用户过度的持续学习,会让模型变得越来越“偏执”,丧失通用性。
目前实现这类还有不少路要走,但是这个一定会是未来的方向,让我们一起期待
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号