用户行为分析:事件埋点与数据洞察


作者: HOS(安全风信子) 日期: 2026-05-25 主要来源平台: GitHub 摘要: 数据驱动是产品迭代的基础。本文系统讲解用户行为分析系统的实现方法,涵盖事件模型设计(Who-What-When-Where-How五要素)、埋点规范(客户端与服务端埋点对比)、数据仓库选型(Hive/BigQuery/Snowflake)、漏斗分析与留存分析核心方法论。并通过Python代码实现完整的事件采集、清洗、存储与分析流程,帮助产品团队构建数据驱动的决策体系,发现用户痛点并指导产品迭代方向。
目录- 引言:数据驱动产品迭代的核心方法论
- 第一章 事件模型设计:用户行为的数字化表达
- 1.1 事件模型的核心概念
- 1.2 事件的数学定义与形式化表达
- 1.3 事件模型的五要素详解
- 1.3.1 Who:用户身份识别
- 1.3.2 What:用户动作定义
- 1.3.3 When:时间维度
- 1.3.4 Where:事件场景
- 1.3.5 How:交互方式
- 1.4 事件模型的设计原则
- 1.5 事件模型的可视化表示
- 第二章 埋点规范:数据采集的艺术与科学
- 2.1 埋点的基本概念与分类
- 2.2 客户端埋点深度解析
- 2.2.1 Web端埋点技术实现
- 2.2.2 App端埋点技术实现
- 2.3 服务端埋点深度解析
- 2.3.1 服务端埋点的优势
- 2.3.2 服务端埋点Python实现
- 2.4 客户端埋点与服务端埋点对比
- 2.5 埋点规范与质量控制
- 2.5.1 埋点命名规范
- 2.5.2 埋点质量校验
- 第三章 数据仓库:用户行为数据的存储架构
- 3.1 数据仓库概述与选型标准
- 3.2 主流数据仓库对比
- 3.3 Hive数据仓库设计与实现
- 3.4 BigQuery数据仓库设计
- 3.5 Snowflake数据仓库设计
- 第四章 漏斗分析:转化率与流失点识别
- 4.1 漏斗分析的核心概念
- 4.2 漏斗分析的理论模型
- 4.2.1 漏斗模型的形式化定义
- 4.2.2 漏斗分析的关键指标
- 4.3 漏斗分析的系统实现
- 4.4 漏斗分析的可视化
- 4.5 漏斗分析SQL示例
- 第五章 留存分析:Cohort分析与留存曲线
- 5.1 留存分析的核心概念
- 5.2 留存率的形式化定义
- 5.3 Cohort分析的实现
- 5.4 留存分析的可视化
- 5.5 核心留存指标体系
- 5.6 留存分析SQL示例
- 第六章 实践:构建完整的用户行为分析系统
- 6.1 系统架构设计
- 6.2 完整代码实现
- 6.3 系统部署与运维
- 6.3.1 Docker部署配置
- 6.3.2 docker-compose编排
- 参考链接
- A. 埋点系统完整代码
- A.1 Web端SDK完整实现
- A.2 数据分析服务完整实现
- 1.1 事件模型的核心概念
- 1.2 事件的数学定义与形式化表达
- 1.3 事件模型的五要素详解
- 1.3.1 Who:用户身份识别
- 1.3.2 What:用户动作定义
- 1.3.3 When:时间维度
- 1.3.4 Where:事件场景
- 1.3.5 How:交互方式
- 1.4 事件模型的设计原则
- 1.5 事件模型的可视化表示
- 2.1 埋点的基本概念与分类
- 2.2 客户端埋点深度解析
- 2.2.1 Web端埋点技术实现
- 2.2.2 App端埋点技术实现
- 2.3 服务端埋点深度解析
- 2.3.1 服务端埋点的优势
- 2.3.2 服务端埋点Python实现
- 2.4 客户端埋点与服务端埋点对比
- 2.5 埋点规范与质量控制
- 2.5.1 埋点命名规范
- 2.5.2 埋点质量校验
- 3.1 数据仓库概述与选型标准
- 3.2 主流数据仓库对比
- 3.3 Hive数据仓库设计与实现
- 3.4 BigQuery数据仓库设计
- 3.5 Snowflake数据仓库设计
- 4.1 漏斗分析的核心概念
- 4.2 漏斗分析的理论模型
- 4.2.1 漏斗模型的形式化定义
- 4.2.2 漏斗分析的关键指标
- 4.3 漏斗分析的系统实现
- 4.4 漏斗分析的可视化
- 4.5 漏斗分析SQL示例
- 5.1 留存分析的核心概念
- 5.2 留存率的形式化定义
- 5.3 Cohort分析的实现
- 5.4 留存分析的可视化
- 5.5 核心留存指标体系
- 5.6 留存分析SQL示例
- 6.1 系统架构设计
- 6.2 完整代码实现
- 6.3 系统部署与运维
- 6.3.1 Docker部署配置
- 6.3.2 docker-compose编排
- A.1 Web端SDK完整实现
- A.2 数据分析服务完整实现
引言:数据驱动产品迭代的核心方法论
本节为你提供的核心技术价值:理解用户行为分析在产品生命周期中的战略地位,掌握从事件采集到数据分析的完整链路。
在当今数据爆炸的时代,产品决策早已从"经验驱动"转向"数据驱动"。无论是初创公司的快速迭代,还是成熟产品的精细化运营,都离不开对用户行为的深刻理解。用户行为分析(User Behavior Analytics,UBA)作为产品数据分析的核心领域,旨在通过系统化的方法采集、存储、分析用户与产品的交互数据,挖掘用户真实需求,发现产品问题,指导产品迭代方向。
然而,构建一套完善的用户行为分析系统并非易事。它涉及多个技术领域的交叉:前端事件采集、后端服务架构、数据仓库设计、海量数据处理、以及高级分析方法(如漏斗分析、留存分析、 cohort 分析等)。任何一个环节的疏漏都可能导致数据质量问题,进而影响分析结论的可靠性。
本文将从事件模型设计出发,系统讲解用户行为分析的理论基础;深入探讨埋点规范与数据采集最佳实践;对比主流数据仓库的技术特点与选型依据;详细阐述漏斗分析与留存分析的方法论;最后通过完整的代码实现,展示如何构建一个端到端的用户行为分析系统。通过本文的学习,读者将掌握构建企业级用户行为分析系统的核心能力。
第一章 事件模型设计:用户行为的数字化表达
1.1 事件模型的核心概念
本节为你提供的核心技术价值:掌握事件模型的五要素框架(Who-What-When-Where-How),理解事件模型如何将用户行为转化为可分析的结构化数据。
事件模型(Event Model)是用户行为分析的基础数据模型。它将用户与产品的每一次交互抽象为一个"事件"(Event),并通过结构化的方式记录事件的详细信息。在事件模型中,最核心的是"五要素"框架:
- Who(谁):触发事件的用户身份标识
- What(什么):用户执行了什么动作
- When(何时):事件发生的时间
- Where(何地):事件发生的场景
- How(如何):事件是如何发生的
这个框架最早由Google Analytics的工程团队提出,并在业界得到广泛应用。MIT的Human Dynamics Lab研究表明,通过这五个维度的数据,可以完整还原用户的交互行为轨迹1。
1.2 事件的数学定义与形式化表达
从数学角度来看,事件可以定义为一个五元组:
其中:
:用户唯一标识符,用于识别触发事件的用户身份
:事件名称,描述用户执行的动作类型
:事件发生的时间戳,精确到毫秒级别
:事件上下文,包含用户代理、设备信息、地理位置等环境信息
:事件属性,包含该事件特有的扩展信息
以一个电商平台的"用户下单"事件为例:
{
"user_id": "u_12345",
"event_name": "place_order",
"timestamp": 1716200000000,
"context": {
"device": "iPhone 14 Pro",
"os": "iOS 17.4",
"browser": "Safari",
"screen_width": 393,
"screen_height": 852,
"language": "zh-CN",
"ip": "223.71.176.1",
"country": "China",
"city": "Shanghai"
},
"properties": {
"order_id": "ord_98765",
"total_amount": 299.00,
"currency": "CNY",
"payment_method": "wechat_pay",
"item_count": 3,
"category": ["electronics", "accessories"]
}
}这个结构清晰地表达了事件的完整信息,为后续的数据分析和挖掘奠定了基础。
1.3 事件模型的五要素详解
1.3.1 Who:用户身份识别
用户身份识别是事件模型的基础。在用户行为分析中,我们需要准确识别每个事件的触发者。常见的用户标识方案包括:
标识类型 | 说明 | 优点 | 缺点 |
|---|---|---|---|
User ID | 登录用户的唯一标识 | 精确、可跨设备关联 | 需要用户登录 |
Device ID | 设备的唯一标识 | 覆盖未登录用户 | 无法跨设备关联 |
Cookie ID | 浏览器Cookie标识 | 实现简单 | 易被清除、跨设备问题 |
Anonymous ID | 匿名生成的UUID | 隐私友好 | 无法跨会话关联 |
在实际应用中,通常采用"匿名ID + 登录ID"的混合方案:未登录用户使用匿名标识,登录后将其行为与登录ID关联。Mixpanel和Amplitude等主流分析平台都采用了这种方案2。
1.3.2 What:用户动作定义
用户动作是事件模型的核心,它描述了用户执行了什么操作。事件命名应遵循以下规范:
命名规范:
- 使用小写字母和下划线(snake_case)
- 采用"动词_名词"结构,如
click_button、view_page、add_to_cart - 避免使用通用名称如
action、event、click - 保持命名的一致性,避免同一动作多种命名
事件分类:
- 页面事件(Page Event):用户访问页面时自动触发
- 点击事件(Click Event):用户点击元素时触发
- 交互事件(Interaction Event):用户与产品交互时触发
- 系统事件(System Event):系统自动触发,如 App 启动、后台切换
1.3.3 When:时间维度
时间戳是用户行为分析的关键维度。高质量的时间数据需要满足以下要求:
- 精确性:精确到毫秒,避免时间歧义
- 时区一致性:统一使用UTC或服务器本地时区
- 时钟同步:客户端设备时钟可能存在偏差,需要校准
import time
from datetime import datetime, timezone
# 获取当前时间戳(毫秒)
timestamp_ms = int(time.time() * 1000)
# 将时间戳转换为可读格式
dt = datetime.fromtimestamp(timestamp_ms / 1000, tz=timezone.utc)
print(f"UTC时间: {dt.isoformat()}")
# 本地时区转换
local_dt = dt.astimezone()
print(f"本地时间: {local_dt.strftime('%Y-%m-%d %H:%M:%S')}")1.3.4 Where:事件场景
事件场景描述了事件发生的环境信息,包括:
- 客户端信息:设备型号、操作系统、浏览器、屏幕分辨率
- 网络环境:IP地址、网络类型(WiFi/4G/5G)
- 地理位置:国家、省份、城市(通过IP或GPS获取)
- 应用版本:App版本号、构建号
- 页面信息:URL、页面标题、来源页面
这些信息对于理解用户行为的环境因素至关重要。例如,通过分析不同设备用户的转化率,可以发现产品在特定设备上的体验问题。
1.3.5 How:交互方式
交互方式描述了用户如何与产品进行交互,包括:
- 交互元素:触发事件的UI元素信息(ID、类名、文本)
- 交互类型:点击、滑动、输入、语音等
- 交互状态:元素的状态变化(展开/收起、选中/未选中)
- 交互结果:操作是否成功、错误信息等
1.4 事件模型的设计原则
优秀的事件模型设计应遵循以下原则:
1. 原子性原则:每个事件应描述一个不可分割的用户动作。避免将多个动作合并为一个事件,如分别记录"加入购物车"和"进入结算页",而不是合并为"下单流程"。
2. 完整性原则:事件应包含足够的信息来回答可能的分析问题。在设计事件时,需要预判可能的分析场景,确保数据能够支撑这些分析。
3. 一致性原则:同一类型的事件应保持结构一致,属性命名和类型应有明确的规范。
4. 可扩展性原则:事件模型应支持灵活扩展,新增属性不应破坏现有结构。
5. 高效性原则:事件数据量庞大,设计时应考虑存储和查询效率,合理平衡数据精度与存储成本。
1.5 事件模型的可视化表示
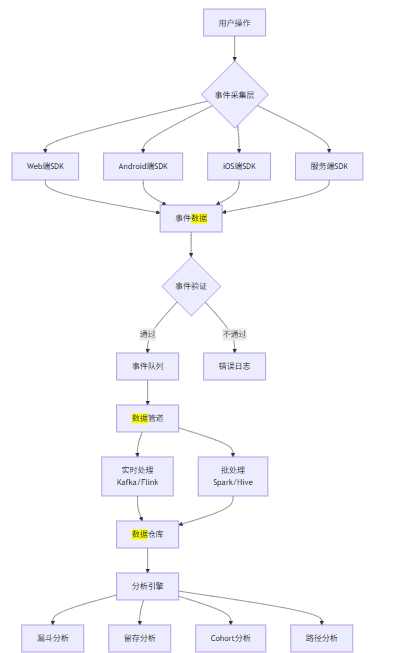
上图展示了从用户操作到数据仓库的完整事件流转路径。用户操作触发事件,通过各端SDK采集后,进入事件验证层,通过验证的事件进入队列,由实时处理和批处理两条路径汇入数据仓库,最终支撑各类分析场景。
第二章 埋点规范:数据采集的艺术与科学
2.1 埋点的基本概念与分类
本节为你提供的核心技术价值:掌握客户端埋点与服务端埋点的技术差异,理解何时使用哪种埋点方式,以及如何设计统一的埋点规范。
埋点(Tracking)是用户行为数据采集的具体实现方式。通过在产品代码中嵌入埋点代码,当用户触发特定行为时,埋点代码会收集相关数据并发送至数据服务器。埋点是用户行为分析的数据源头,其质量直接决定了分析结论的可靠性。
根据埋点的位置,可以分为客户端埋点和服务端埋点两大类。两种方式各有优劣,适用于不同的场景。
2.2 客户端埋点深度解析
客户端埋点是指在前端(Web、App、小程序等)进行的数据采集。其核心原理是通过监听用户的交互行为,在客户端本地完成数据收集和上报。
2.2.1 Web端埋点技术实现
Web端埋点主要通过以下几种方式实现:
1. 手动埋点(Code Integration)
手动埋点是最传统也是最精确的埋点方式。开发者需要在代码中显式调用埋点API来采集事件。
// 手动埋点示例
// 引入埋点SDK
const tracker = window.TrackerSDK.init({
projectId: 'proj_12345',
serverUrl: 'https://analytics.example.com/collect'
});
// 监听页面加载事件
window.addEventListener('load', () => {
tracker.track('page_view', {
page_url: window.location.href,
page_title: document.title,
referrer: document.referrer,
utm_source: getUrlParam('utm_source'),
utm_medium: getUrlParam('utm_medium'),
utm_campaign: getUrlParam('utm_campaign')
});
});
// 监听按钮点击事件
document.querySelector('#checkout-btn').addEventListener('click', () => {
tracker.track('click_button', {
button_text: '立即结算',
button_id: 'checkout-btn',
button_position: 'product_detail_page',
product_id: 'prod_88888',
product_name: 'iPhone 15 Pro'
});
});2. 全局监听埋点(Auto Tracking)
全局监听埋点通过拦截全局事件(点击、滚动、表单提交等),自动采集用户行为。这种方式可以降低埋点成本,但可能引入大量噪声数据。
// 全局点击监听埋点
class AutoTracker {
constructor(tracker) {
this.tracker = tracker;
this.init();
}
init() {
if (this.initialized) return;
this.initialized = true;
document.addEventListener('click', this.handleClick.bind(this), true);
this.scrollHandler = this.throttle(this.handleScroll.bind(this), 1000);
window.addEventListener('scroll', this.scrollHandler, { passive: true });
document.addEventListener('visibilitychange', this.handleVisibility.bind(this));
}
handleClick(e) {
const target = e.target;
if (target.tagName === 'HTML' || target.tagName === 'BODY') return;
const elementInfo = this.getElementInfo(target);
if (this.isInteractive(target)) {
this.tracker.track('element_click', {
element_text: elementInfo.text,
element_type: target.tagName.toLowerCase(),
element_id: target.id || null,
element_class: target.className || null,
element_path: elementInfo.path,
page_url: window.location.href,
page_title: document.title,
timestamp: Date.now()
});
}
}
getElementInfo(element) {
let text = element.textContent?.trim() || '';
if (text.length > 50) text = text.substring(0, 50) + '...';
const path = [];
let current = element;
while (current && current !== document.body) {
let selector = current.tagName.toLowerCase();
if (current.id) {
selector += `#${current.id}`;
path.unshift(selector);
break;
} else if (current.className) {
const classes = current.className.split(' ')
.filter(c => c && !c.includes(' '))
.map(c => `.${c}`)
.join('');
if (classes) selector += classes;
}
path.unshift(selector);
current = current.parentElement;
}
return { text, path: path.join(' > ') };
}
isInteractive(element) {
const interactiveTags = ['A', 'BUTTON', 'INPUT', 'SELECT', 'TEXTAREA'];
const interactiveTypes = ['submit', 'button', 'reset', 'radio', 'checkbox'];
return interactiveTags.includes(element.tagName) ||
interactiveTypes.includes(element.type) ||
element.onclick !== null ||
element.getAttribute('role') === 'button';
}
handleScroll(e) {
const scrollDepth = Math.round((window.scrollY / (document.body.scrollHeight - window.innerHeight)) * 100);
const depthBucket = Math.floor(scrollDepth / 25) * 25;
this.tracker.track('page_scroll', {
scroll_depth: depthBucket,
scroll_pixels: window.scrollY,
page_url: window.location.href
});
}
handleVisibility() {
this.tracker.track('page_visibility', {
is_visible: document.visibilityState === 'visible',
page_url: window.location.href,
timestamp: Date.now()
});
}
throttle(fn, limit) {
let inThrottle;
return function(...args) {
if (!inThrottle) {
fn.apply(this, args);
inThrottle = true;
setTimeout(() => inThrottle = false, limit);
}
};
}
}
const tracker = window.TrackerSDK.init({
projectId: 'proj_12345',
serverUrl: 'https://analytics.example.com/collect'
});
new AutoTracker(tracker);2.2.2 App端埋点技术实现
iOS端埋点(Swift)
import UIKit
import Foundation
class AnalyticsManager {
static let shared = AnalyticsManager()
private let serverUrl = "https://analytics.example.com/collect"
private var eventQueue: [String: Any] = []
private let queue = DispatchQueue(label: "com.analytics.queue")
private init() {
setupAutoTracking()
setupLifecycleTracking()
}
func trackPageView(pageName: String, properties: [String: Any]? = nil) {
var event: [String: Any] = [
"event_name": "page_view",
"page_name": pageName,
"timestamp": Int(Date().timeIntervalSince1970 * 1000),
"screen_width": UIScreen.main.bounds.width,
"screen_height": UIScreen.main.bounds.height
]
event["device_model"] = UIDevice.current.model
event["os_version"] = UIDevice.current.systemVersion
event["app_version"] = Bundle.main.infoDictionary?["CFBundleShortVersionString"] as? String ?? "unknown"
if let props = properties {
event.merge(props) { _, new in new }
}
sendEvent(event)
}
func track(eventName: String, properties: [String: Any]? = nil) {
var event: [String: Any] = [
"event_name": eventName,
"timestamp": Int(Date().timeIntervalSince1970 * 1000),
"locale": Locale.current.identifier
]
if let props = properties {
event.merge(props) { _, new in new }
}
sendEvent(event)
}
private func setupLifecycleTracking() {
NotificationCenter.default.addObserver(
self,
selector: #selector(appDidBecomeActive),
name: UIApplication.didBecomeActiveNotification,
object: nil
)
NotificationCenter.default.addObserver(
self,
selector: #selector(appDidEnterBackground),
name: UIApplication.didEnterBackgroundNotification,
object: nil
)
}
@objc private func appDidBecomeActive() {
track(eventName: "app_start", properties: ["start_type": "foreground"])
}
@objc private func appDidEnterBackground() {
track(eventName: "app_background")
}
private func sendEvent(_ event: [String: Any]) {
queue.async { [weak self] in
guard let self = self else { return }
var eventData = event
eventData["event_id"] = UUID().uuidString
eventData["session_id"] = self.getSessionId()
if let jsonData = try? JSONSerialization.data(withJSONObject: eventData),
let jsonString = String(data: jsonData, encoding: .utf8) {
self.httpPost(jsonString)
}
}
}
private func getSessionId() -> String {
let key = "analytics_session_id"
if let sessionId = UserDefaults.standard.string(forKey: key) {
return sessionId
} else {
let newSessionId = UUID().uuidString
UserDefaults.standard.set(newSessionId, forKey: key)
return newSessionId
}
}
private func httpPost(_ body: String) {
guard let url = URL(string: serverUrl) else { return }
var request = URLRequest(url: url)
request.httpMethod = "POST"
request.setValue("application/json", forHTTPHeaderField: "Content-Type")
request.httpBody = body.data(using: .utf8)
request.timeoutInterval = 5
URLSession.shared.dataTask(with: request) { _, response, error in
if let error = error {
print("Analytics error: \(error.localizedDescription)")
}
}.resume()
}
}
class ProductDetailViewController: UIViewController {
override func viewDidAppear(_ animated: Bool) {
super.viewDidAppear(animated)
AnalyticsManager.shared.trackPageView(
pageName: "product_detail",
properties: ["product_id": "prod_88888", "product_name": "iPhone 15 Pro"]
)
}
}Android端埋点(Kotlin)
package com.example.analytics
import android.app.Application
import android.content.Context
import android.os.Build
import android.provider.Settings
import android.util.Log
import kotlinx.coroutines.*
import org.json.JSONObject
import java.io.OutputStreamWriter
import java.net.HttpURLConnection
import java.net.URL
import java.nio.charset.StandardCharsets
class AnalyticsSDK private constructor(private val context: Context) {
companion object {
private const val TAG = "AnalyticsSDK"
private const val SERVER_URL = "https://analytics.example.com/collect"
@Volatile
private var instance: AnalyticsSDK? = null
fun getInstance(context: Context): AnalyticsSDK {
return instance ?: synchronized(this) {
instance ?: AnalyticsSDK(context.applicationContext).also { instance = it }
}
}
}
private val scope = CoroutineScope(Dispatchers.IO + SupervisorJob())
private val eventQueue = mutableListOf<JSONObject>()
private val sessionId = generateSessionId()
init {
if (context is Application) {
context.registerActivityLifecycleCallbacks(ActivityLifecycleCallback())
}
}
fun trackPageView(pageName: String, properties: Map<String, Any>? = null) {
val event = buildEvent("page_view", mapOf("page_name" to pageName).apply {
properties?.let { putAll(it) }
})
sendEvent(event)
}
fun track(eventName: String, properties: Map<String, Any>? = null) {
val event = buildEvent(eventName, properties ?: emptyMap())
sendEvent(event)
}
private fun buildEvent(eventName: String, properties: Map<String, Any>): JSONObject {
return JSONObject().apply {
put("event_id", generateUUID())
put("event_name", eventName)
put("timestamp", System.currentTimeMillis())
put("session_id", sessionId)
put("device_id", getDeviceId())
put("device_model", Build.MODEL)
put("os_version", Build.VERSION.RELEASE)
put("app_version", getAppVersion())
put("screen_width", context.resources.displayMetrics.widthPixels)
put("screen_height", context.resources.displayMetrics.heightPixels)
put("properties", JSONObject(properties))
}
}
private fun sendEvent(event: JSONObject) {
scope.launch {
synchronized(eventQueue) { eventQueue.add(event) }
flush()
}
}
private fun flush() {
val eventsToSend: List<JSONObject>
synchronized(eventQueue) {
if (eventQueue.isEmpty()) return
eventsToSend = eventQueue.toList()
eventQueue.clear()
}
try {
val url = URL(SERVER_URL)
val conn = url.openConnection() as HttpURLConnection
conn.apply {
requestMethod = "POST"
doOutput = true
setRequestProperty("Content-Type", "application/json")
connectTimeout = 5000
readTimeout = 5000
}
conn.outputStream.use { outputStream ->
OutputStreamWriter(outputStream, StandardCharsets.UTF_8).use { writer ->
val batchObject = JSONObject().apply {
put("events", JSONArray(eventsToSend))
put("batch_timestamp", System.currentTimeMillis())
}
writer.write(batchObject.toString())
writer.flush()
}
}
val responseCode = conn.responseCode
if (responseCode != HttpURLConnection.HTTP_OK) {
Log.e(TAG, "Failed to send events: $responseCode")
synchronized(eventQueue) { eventQueue.addAll(0, eventsToSend) }
}
conn.disconnect()
} catch (e: Exception) {
Log.e(TAG, "Error sending events", e)
synchronized(eventQueue) { eventQueue.addAll(0, eventsToSend) }
}
}
private fun getDeviceId(): String {
return Settings.Secure.getString(context.contentResolver, Settings.Secure.ANDROID_ID) ?: "unknown"
}
private fun getAppVersion(): String {
return try {
val packageInfo = context.packageManager.getPackageInfo(context.packageName, 0)
packageInfo.versionName ?: "unknown"
} catch (e: Exception) { "unknown" }
}
private fun generateSessionId(): String {
val prefs = context.getSharedPreferences("analytics", Context.MODE_PRIVATE)
return prefs.getString("session_id", null) ?: run {
val newSessionId = generateUUID()
prefs.edit().putString("session_id", newSessionId).apply()
newSessionId
}
}
private fun generateUUID(): String = java.util.UUID.randomUUID().toString()
inner class ActivityLifecycleCallback : android.app.Application.ActivityLifecycleCallbacks {
private var foregroundCount = 0
private var lastActiveTime = 0L
override fun onActivityStarted(activity: android.app.Activity) {
foregroundCount++
if (foregroundCount == 1) {
track(eventName = "app_foreground", properties = mapOf(
"last_active_duration" to (System.currentTimeMillis() - lastActiveTime)
))
}
}
override fun onActivityResumed(activity: android.app.Activity) {
trackPageView(activity.javaClass.simpleName)
}
override fun onActivityStopped(activity: android.app.Activity) {
foregroundCount--
if (foregroundCount == 0) {
lastActiveTime = System.currentTimeMillis()
track(eventName = "app_background")
}
}
override fun onActivityCreated(activity: android.app.Activity, savedInstanceState: android.os.Bundle?) {}
override fun onActivityPaused(activity: android.app.Activity) {}
override fun onActivityDestroyed(activity: android.app.Activity) {}
override fun onActivitySaveInstanceState(activity: android.app.Activity, outState: android.os.Bundle) {}
override fun onActivityPostCreated(activity: android.app.Activity, savedInstanceState: android.os.Bundle?) {}
override fun onActivityPostStarted(activity: android.app.Activity) {}
override fun onActivityPostResumed(activity: android.app.Activity) {}
override fun onActivityPostPaused(activity: android.app.Activity) {}
override fun onActivityPostStopped(activity: android.app.Activity) {}
override fun onActivityPostDestroyed(activity: android.app.Activity) {}
}
}2.3 服务端埋点深度解析
服务端埋点是指在后端服务器进行的数据采集。与客户端埋点相比,服务端埋点具有数据准确性高、用户行为覆盖完整等优点。
2.3.1 服务端埋点的优势
特性 | 客户端埋点 | 服务端埋点 |
|---|---|---|
数据准确性 | 受网络、设备环境影响 | 数据准确可靠 |
用户覆盖 | 依赖SDK安装率 | 覆盖所有用户请求 |
数据类型 | 用户可见行为 | 包含业务核心数据 |
实时性 | 依赖网络连接 | 可实时 |
用户标识 | 设备ID、Cookie | Session/User ID |
适用场景 | UI交互、页面浏览 | 订单、支付、核心业务 |
2.3.2 服务端埋点Python实现
"""
服务端埋点SDK - Python实现
"""
import json
import time
import uuid
import logging
from datetime import datetime, timezone
from typing import Dict, List, Optional, Any
from dataclasses import dataclass, field, asdict
from enum import Enum
import threading
import queue
import requests
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class EventBatchMode(Enum):
SYNC = "sync"
BATCH = "batch"
ASYNC = "async"
@dataclass
class EventContext:
ip: Optional[str] = None
user_agent: Optional[str] = None
country: Optional[str] = None
province: Optional[str] = None
city: Optional[str] = None
platform: str = "server"
version: str = "1.0.0"
def to_dict(self) -> Dict[str, Any]:
return {k: v for k, v in asdict(self).items() if v is not None}
@dataclass
class Event:
event_id: str = field(default_factory=lambda: str(uuid.uuid4()))
event_name: str = ""
user_id: Optional[str] = None
anonymous_id: Optional[str] = None
timestamp: int = field(default_factory=lambda: int(time.time() * 1000))
context: EventContext = field(default_factory=EventContext)
properties: Dict[str, Any] = field(default_factory=dict)
def to_dict(self) -> Dict[str, Any]:
return {
"event_id": self.event_id,
"event_name": self.event_name,
"user_id": self.user_id,
"anonymous_id": self.anonymous_id,
"timestamp": self.timestamp,
"datetime": datetime.fromtimestamp(self.timestamp / 1000, tz=timezone.utc).isoformat(),
"context": self.context.to_dict(),
"properties": self.properties
}
class ServerTrackSDK:
def __init__(
self,
project_id: str,
server_url: str,
batch_size: int = 100,
flush_interval: int = 5,
max_queue_size: int = 10000,
enable_retry: bool = True,
max_retry_times: int = 3
):
self.project_id = project_id
self.server_url = server_url.rstrip('/')
self.batch_size = batch_size
self.flush_interval = flush_interval
self.max_queue_size = max_queue_size
self.enable_retry = enable_retry
self.max_retry_times = max_retry_times
self._event_queue: queue.Queue = queue.Queue(maxsize=max_queue_size)
self._running = False
self._start_worker()
def _start_worker(self):
self._running = True
self._worker_thread = threading.Thread(target=self._worker_loop, daemon=True)
self._worker_thread.start()
self._timer_thread = threading.Thread(target=self._timer_flush, daemon=True)
self._timer_thread.start()
def _worker_loop(self):
while self._running:
try:
events = []
for _ in range(self.batch_size):
try:
event = self._event_queue.get(timeout=1)
events.append(event.to_dict())
self._event_queue.task_done()
except queue.Empty:
break
if events:
self._send_batch(events)
except Exception as e:
logger.error(f"Worker error: {e}")
def _timer_flush(self):
while self._running:
time.sleep(self.flush_interval)
self.flush()
def track(
self,
event_name: str,
user_id: Optional[str] = None,
anonymous_id: Optional[str] = None,
properties: Optional[Dict[str, Any]] = None,
context: Optional[EventContext] = None
) -> str:
event = Event(
event_name=event_name,
user_id=user_id,
anonymous_id=anonymous_id,
properties=properties or {},
context=context or EventContext()
)
try:
self._event_queue.put_nowait(event)
except queue.Full:
logger.warning("Event queue is full, dropping event")
return event.event_id
def track_page_view(
self,
page_url: str,
page_title: Optional[str] = None,
user_id: Optional[str] = None,
properties: Optional[Dict[str, Any]] = None
) -> str:
props = properties or {}
props.update({"url": page_url, "title": page_title})
return self.track("page_view", user_id=user_id, properties=props)
def track_purchase(
self,
order_id: str,
amount: float,
currency: str = "CNY",
user_id: Optional[str] = None,
properties: Optional[Dict[str, Any]] = None
) -> str:
props = properties or {}
props.update({"order_id": order_id, "amount": amount, "currency": currency})
return self.track("purchase", user_id=user_id, properties=props)
def flush(self):
events = []
while True:
try:
event = self._event_queue.get_nowait()
events.append(event.to_dict())
self._event_queue.task_done()
except queue.Empty:
break
if events:
self._send_batch(events)
def _send_batch(self, events: List[Dict[str, Any]]):
payload = {
"project_id": self.project_id,
"events": events,
"batch_timestamp": int(time.time() * 1000)
}
for attempt in range(self.max_retry_times if self.enable_retry else 1):
try:
response = requests.post(
f"{self.server_url}/batch",
json=payload,
headers={"Content-Type": "application/json"},
timeout=10
)
if response.status_code == 200:
logger.info(f"Successfully sent {len(events)} events")
return
except Exception as e:
logger.error(f"Error sending events: {e}")
if attempt < self.max_retry_times - 1:
time.sleep(1 * (attempt + 1))
def close(self):
self._running = False
self.flush()
logger.info("ServerTrackSDK closed")
# Flask集成示例
from flask import Flask, request, g
app = Flask(__name__)
analytics = ServerTrackSDK(
project_id="proj_12345",
server_url="https://analytics.example.com",
batch_size=50,
flush_interval=3
)
@app.before_request
def before_request():
g.start_time = time.time()
g.user_ip = request.headers.get('X-Forwarded-For', request.remote_addr)
g.user_agent = request.headers.get('User-Agent', '')
g.user_id = request.cookies.get('user_id')
@app.route('/api/products/<product_id>')
def get_product(product_id):
context = EventContext(ip=g.user_ip, user_agent=g.user_agent, platform="web")
analytics.track_page_view(
page_url=request.url,
page_title=f"商品详情-{product_id}",
user_id=g.user_id,
context=context
)
return {"product_id": product_id, "name": "示例商品"}
@app.route('/api/orders', methods=['POST'])
def create_order():
data = request.get_json()
analytics.track(
event_name="create_order",
user_id=g.user_id,
properties={
"order_id": data.get('order_id'),
"amount": data.get('amount'),
"item_count": len(data.get('items', []))
}
)
return {"success": True}
@app.route('/api/purchase', methods=['POST'])
def purchase():
data = request.get_json()
analytics.track_purchase(
order_id=data['order_id'],
amount=data['amount'],
currency=data.get('currency', 'CNY'),
user_id=g.user_id,
properties={"payment_method": data.get('payment_method'), "items": data.get('items')}
)
return {"success": True}
if __name__ == '__main__':
try:
app.run(host='0.0.0.0', port=5000)
finally:
analytics.close()2.4 客户端埋点与服务端埋点对比
维度 | 客户端埋点 | 服务端埋点 |
|---|---|---|
数据来源 | 浏览器/App | 服务器 |
覆盖范围 | 可见的交互行为 | 所有服务端请求 |
数据准确性 | 受网络、SDK状态影响 | 准确可靠 |
实时性 | 依赖网络连接 | 可实时 |
用户标识 | 设备ID、Cookie | Session/User ID |
适用场景 | UI交互、页面浏览 | 订单、支付、核心业务 |
数据完整性 | 可能丢失 | 完整记录 |
隐私合规 | 需要用户授权 | 可控性更强 |
最佳实践建议:
- 客户端埋点:用于采集用户与界面的交互行为,如点击、滚动、页面跳转等
- 服务端埋点:用于采集核心业务数据,如订单、支付、注册等,确保数据准确性
2.5 埋点规范与质量控制
2.5.1 埋点命名规范
EVENT_NAME_RULES = {
"page_view": "页面浏览",
"page_leave": "页面离开",
"click": "点击",
"long_press": "长按",
"input": "输入",
"submit": "提交",
"register": "注册",
"login": "登录",
"logout": "登出",
"purchase": "购买",
"add_to_cart": "加入购物车",
"remove_from_cart": "移出购物车",
"search": "搜索",
"filter": "筛选",
"sort": "排序"
}
PROPERTY_NAME_RULES = {
"page_name": "页面名称",
"page_url": "页面URL",
"element_id": "元素ID",
"element_text": "元素文本",
"product_id": "商品ID",
"product_name": "商品名称",
"category": "分类",
"price": "价格",
"quantity": "数量",
"order_id": "订单ID",
"amount": "金额",
"user_id": "用户ID",
"user_type": "用户类型"
}2.5.2 埋点质量校验
from typing import Dict, List, Any
from dataclasses import dataclass
from datetime import datetime
import json
@dataclass
class TrackValidationResult:
is_valid: bool
errors: List[str]
warnings: List[str]
def to_dict(self):
return {
"is_valid": self.is_valid,
"errors": self.errors,
"warnings": self.warnings
}
class TrackValidator:
REQUIRED_FIELDS = ["event_name", "timestamp"]
EVENT_WHITELIST = {
"page_view", "page_leave", "click", "long_press", "double_click",
"input", "submit", "reset", "register", "login", "logout",
"purchase", "add_to_cart", "remove_from_cart", "search",
"filter", "sort", "share", "comment", "favorite"
}
SENSITIVE_FIELDS = {
"password", "token", "secret", "credit_card", "id_card",
"phone", "email", "address", "real_name"
}
MAX_STRING_LENGTH = 1000
MAX_ARRAY_LENGTH = 100
MAX_OBJECT_KEYS = 50
def validate(self, event: Dict[str, Any]) -> TrackValidationResult:
errors = []
warnings = []
for field in self.REQUIRED_FIELDS:
if field not in event:
errors.append(f"Missing required field: {field}")
if "event_name" in event:
if not isinstance(event["event_name"], str):
errors.append("event_name must be string")
if "timestamp" in event:
if not isinstance(event["timestamp"], (int, float)):
errors.append("timestamp must be number")
elif event["timestamp"] > int(datetime.now().timestamp() * 1000) + 60000:
warnings.append("timestamp is in the future")
if "event_name" in event and event["event_name"] not in self.EVENT_WHITELIST:
warnings.append(f"event_name '{event['event_name']}' not in whitelist")
if "properties" in event:
prop_errors, prop_warnings = self._validate_properties(event["properties"])
errors.extend(prop_errors)
warnings.extend(prop_warnings)
if "properties" in event:
sensitive_errors = self._check_sensitive_data(event["properties"])
errors.extend(sensitive_errors)
return TrackValidationResult(
is_valid=len(errors) == 0,
errors=errors,
warnings=warnings
)
def _validate_properties(self, properties: Dict[str, Any]) -> tuple:
errors = []
warnings = []
if not isinstance(properties, dict):
errors.append("properties must be object")
return errors, warnings
if len(properties) > self.MAX_OBJECT_KEYS:
warnings.append(f"properties has too many keys: {len(properties)}")
for key, value in properties.items():
if not isinstance(key, str):
errors.append(f"property key must be string: {key}")
if isinstance(value, str) and len(value) > self.MAX_STRING_LENGTH:
warnings.append(f"string property '{key}' exceeds max length")
elif isinstance(value, list) and len(value) > self.MAX_ARRAY_LENGTH:
warnings.append(f"array property '{key}' exceeds max length")
return errors, warnings
def _check_sensitive_data(self, properties: Dict[str, Any]) -> List[str]:
errors = []
def check_recursive(obj, path=""):
if isinstance(obj, dict):
for key, value in obj.items():
current_path = f"{path}.{key}" if path else key
if key.lower() in self.SENSITIVE_FIELDS:
errors.append(f"Sensitive data found: {current_path}")
check_recursive(value, current_path)
elif isinstance(obj, list):
for i, item in enumerate(obj):
check_recursive(item, f"{path}[{i}]")
check_recursive(properties)
return errors
def validate_batch(self, events: List[Dict[str, Any]]) -> Dict[str, Any]:
results = []
valid_count = 0
invalid_count = 0
for event in events:
validation = self.validate(event)
results.append({
"event_id": event.get("event_id", "unknown"),
"event_name": event.get("event_name"),
**validation.to_dict()
})
if validation.is_valid:
valid_count += 1
else:
invalid_count += 1
return {
"total": len(events),
"valid": valid_count,
"invalid": invalid_count,
"valid_rate": f"{valid_count / len(events) * 100:.2f}%",
"results": results
}
validator = TrackValidator()
event = {
"event_id": "evt_12345",
"event_name": "purchase",
"timestamp": 1716200000000,
"user_id": "u_12345",
"properties": {
"order_id": "ord_98765",
"amount": 299.00,
"currency": "CNY"
}
}
result = validator.validate(event)
print(json.dumps(result.to_dict(), indent=2, ensure_ascii=False))第三章 数据仓库:用户行为数据的存储架构
3.1 数据仓库概述与选型标准
本节为你提供的核心技术价值:掌握主流数据仓库(Hive、BigQuery、Snowflake)的技术特点与适用场景,学会根据业务需求选择合适的存储方案。
数据仓库是用户行为分析系统的核心组件,负责存储和管理海量的用户行为数据。一个优秀的数据仓库需要满足以下核心需求:
- 海量存储:支持PB级别的数据存储
- 高效查询:支持秒级甚至毫秒级的查询响应
- 可扩展性:能够弹性扩展存储和计算能力
- 成本效益:在性能和成本之间取得平衡
- 生态兼容:与主流分析工具和计算框架兼容
3.2 主流数据仓库对比
特性 | Apache Hive | Google BigQuery | Snowflake |
|---|---|---|---|
部署方式 | 自建/ EMR | 云服务 | 云服务 |
存储格式 | HDFS | Colossus | S3/Azure Blob |
计算模型 | MapReduce/Spark | Dremel | 虚拟仓库 |
定价方式 | 基础设施成本 | 按查询量计费 | 按存储+计算计费 |
扩展性 | 中等 | 极强 | 强 |
延迟 | 高 | 低 | 低 |
SQL支持 | 完整 | 完整 | 完整 |
生态 | Hadoop生态 | GCP生态 | 多云 |
适用场景 | 大规模离线分析 | 大数据实时分析 | 企业级数据仓库 |
3.3 Hive数据仓库设计与实现
CREATE DATABASE IF NOT EXISTS user_analytics;
USE user_analytics;
CREATE TABLE raw_events (
event_id STRING COMMENT '事件唯一标识',
event_name STRING COMMENT '事件名称',
user_id STRING COMMENT '用户ID',
anonymous_id STRING COMMENT '匿名ID',
timestamp BIGINT COMMENT '事件时间戳(毫秒)',
dt STRING COMMENT '分区字段:日期 YYYY-MM-DD',
hr STRING COMMENT '分区字段:小时',
context STRUCT<
ip: STRING,
user_agent: STRING,
device: STRING,
os: STRING,
browser: STRING,
screen_width: INT,
screen_height: INT,
country: STRING,
province: STRING,
city: STRING,
language: STRING,
platform: STRING
> COMMENT '事件上下文',
properties STRING COMMENT '事件属性JSON'
)
COMMENT '原始事件表'
PARTITIONED BY (app_id STRING, env STRING)
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='SNAPPY');
CREATE TABLE users (
user_id STRING COMMENT '用户ID',
anonymous_id STRING COMMENT '匿名ID',
first_seen_timestamp BIGINT COMMENT '首次访问时间戳',
first_seen_date STRING COMMENT '首次访问日期',
last_seen_timestamp BIGINT COMMENT '最后访问时间戳',
last_seen_date STRING COMMENT '最后访问日期',
total_events INT COMMENT '总事件数',
user_type STRING COMMENT '用户类型:new/returning/loyal',
device_info STRUCT<
primary_device: STRING,
device_count: INT,
devices: ARRAY<STRING>
> COMMENT '设备信息',
user_properties MAP<STRING, STRING> COMMENT '用户属性'
)
COMMENT '用户表'
STORED AS PARQUET;
CREATE TABLE sessions (
session_id STRING COMMENT '会话ID',
user_id STRING COMMENT '用户ID',
anonymous_id STRING COMMENT '匿名ID',
start_timestamp BIGINT COMMENT '会话开始时间戳',
start_date STRING COMMENT '会话开始日期',
end_timestamp BIGINT COMMENT '会话结束时间戳',
duration_seconds INT COMMENT '会话时长(秒)',
page_views INT COMMENT '页面浏览数',
events INT COMMENT '事件总数',
bounce BOOLEAN COMMENT '是否跳出',
entry_page STRING COMMENT '入口页面',
exit_page STRING COMMENT '出口页面',
referrer STRING COMMENT '来源'
)
COMMENT '会话表'
PARTITIONED BY (app_id STRING)
STORED AS PARQUET;
CREATE TABLE page_views (
event_id STRING COMMENT '事件ID',
user_id STRING COMMENT '用户ID',
session_id STRING COMMENT '会话ID',
timestamp BIGINT COMMENT '访问时间戳',
dt STRING COMMENT '日期分区',
page_url STRING COMMENT '页面URL',
page_title STRING COMMENT '页面标题',
page_category STRING COMMENT '页面分类',
referrer STRING COMMENT '来源页面',
scroll_depth INT COMMENT '滚动深度(百分比)',
view_duration INT COMMENT '页面停留时长(秒)',
is_entry BOOLEAN COMMENT '是否入口页',
is_exit BOOLEAN COMMENT '是否出口页'
)
COMMENT '页面浏览表'
PARTITIONED BY (app_id STRING, env STRING)
STORED AS PARQUET;
CREATE VIEW v_daily_active_users AS
SELECT
dt,
COUNT(DISTINCT user_id) as dau,
COUNT(DISTINCT anonymous_id) as dau_anonymous
FROM raw_events
WHERE user_id IS NOT NULL OR anonymous_id IS NOT NULL
GROUP BY dt;3.4 BigQuery数据仓库设计
CREATE SCHEMA IF NOT EXISTS `user_analytics`
OPTIONS (
description = 'User Behavior Analytics Dataset',
location = 'US',
default_table_expiration_days = 365
);
CREATE TABLE IF NOT EXISTS `user_analytics.raw_events`
(
event_id STRING NOT NULL,
event_name STRING NOT NULL,
user_id STRING,
anonymous_id STRING,
timestamp INT64 NOT NULL,
event_datetime TIMESTAMP,
context STRUCT<
ip STRING,
user_agent STRING,
device STRUCT<type STRING, brand STRING, model STRING, screen_width INT64, screen_height INT64>,
os STRUCT<name STRING, version STRING>,
geo STRUCT<country STRING, region STRING, city STRING, latitude FLOAT64, longitude FLOAT64>,
platform STRING,
app_version STRING
>,
page STRUCT<url STRING, title STRING, referrer STRING, utm_source STRING, utm_medium STRING, utm_campaign STRING>,
properties JSON,
insert_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP()
)
PARTITION BY DATE(event_datetime)
CLUSTER BY user_id, event_name
OPTIONS (require_partition_filter = TRUE);
CREATE TABLE IF NOT EXISTS `user_analytics.users`
(
user_id STRING NOT NULL,
anonymous_id STRING,
first_seen_timestamp INT64,
first_seen_datetime DATETIME,
first_seen_date DATE,
last_seen_timestamp INT64,
last_seen_datetime DATETIME,
last_seen_date DATE,
total_sessions INT64,
total_events INT64,
total_page_views INT64,
user_type STRING,
primary_device STRING,
device_count INT64,
country STRING,
region STRING,
city STRING,
attributes JSON,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP(),
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP()
)
PARTITION BY first_seen_date
CLUSTER BY user_type, country;
CREATE TABLE IF NOT EXISTS `user_analytics.sessions`
(
session_id STRING NOT NULL,
user_id STRING,
anonymous_id STRING,
start_timestamp INT64,
start_datetime DATETIME,
start_date DATE,
end_timestamp INT64,
duration_seconds INT64,
page_views INT64,
events INT64,
is_bounce BOOL,
is_new_user BOOL,
entry_page_url STRING,
entry_page_title STRING,
exit_page_url STRING,
exit_page_title STRING,
referrer STRING,
referrer_domain STRING,
utm_source STRING,
utm_medium STRING,
utm_campaign STRING,
device_type STRING,
device_brand STRING,
os_name STRING,
country STRING,
region STRING,
city STRING
)
PARTITION BY start_date
CLUSTER BY user_id, is_bounce;3.5 Snowflake数据仓库设计
CREATE DATABASE IF NOT EXISTS USER_ANALYTICS;
CREATE SCHEMA IF NOT EXISTS USER_ANALYTICS.EVENTS;
CREATE SCHEMA IF NOT EXISTS USER_ANALYTICS.USERS;
CREATE SCHEMA IF NOT EXISTS USER_ANALYTICS.ANALYSIS;
CREATE TABLE IF NOT EXISTS USER_ANALYTICS.EVENTS.RAW_EVENTS (
event_id VARCHAR(64) NOT NULL,
event_name VARCHAR(128) NOT NULL,
user_id VARCHAR(64),
anonymous_id VARCHAR(64),
timestamp NUMBER(18, 0) NOT COMMENT 'Unix timestamp in milliseconds',
context VARIANT,
page VARIANT,
properties VARIANT,
created_at TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP(),
event_date DATE
)
COMMENT = 'Raw user behavior events'
CLUSTER BY (event_date, event_name, user_id);
CREATE TABLE IF NOT EXISTS USER_ANALYTICS.USERS.USER_PROFILES (
user_id VARCHAR(64) NOT NULL,
anonymous_id VARCHAR(64),
first_seen_at TIMESTAMP_NTZ,
first_seen_date DATE,
last_seen_at TIMESTAMP_NTZ,
last_seen_date DATE,
total_sessions NUMBER(10, 0),
total_events NUMBER(10, 0),
total_page_views NUMBER(10, 0),
user_type VARCHAR(32),
attributes VARIANT,
created_at TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP(),
updated_at TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
)
COMMENT = 'User profiles'
CLUSTER BY (user_id, first_seen_date);
CREATE TABLE IF NOT EXISTS USER_ANALYTICS.EVENTS.SESSIONS (
session_id VARCHAR(64) NOT NULL,
user_id VARCHAR(64),
anonymous_id VARCHAR(64),
start_at TIMESTAMP_NTZ,
start_date DATE,
end_at TIMESTAMP_NTZ,
duration_seconds NUMBER(10, 0),
page_views NUMBER(10, 0),
events NUMBER(10, 0),
is_bounce BOOLEAN,
is_new_user BOOLEAN,
entry_page VARIANT,
exit_page VARIANT,
referrer VARIANT,
utm VARCHAR(256),
device_info VARIANT,
geo_info VARIANT
)
COMMENT = 'User sessions'
CLUSTER BY (start_date, user_id);第四章 漏斗分析:转化率与流失点识别
4.1 漏斗分析的核心概念
本节为你提供的核心技术价值:掌握漏斗分析的理论基础,学会识别用户转化过程中的关键节点和流失点,并通过SQL实现漏斗分析。
漏斗分析(Funnel Analysis)是用户行为分析中最核心的分析方法之一。它通过分析用户在完成特定目标过程中各个阶段的转化和流失情况,帮助产品团队量化用户行为路径的有效性,发现转化瓶颈,指导产品优化方向。
漏斗分析的核心价值在于:
- 量化转化效率:将用户行为路径分解为多个阶段,计算每阶段的转化率
- 识别流失节点:准确定位用户流失最严重的环节
- 评估优化效果:比较优化前后的漏斗数据,验证优化措施的有效性
- 预测转化潜力:基于漏斗数据预测潜在的业务增长空间
4.2 漏斗分析的理论模型
4.2.1 漏斗模型的形式化定义
设用户行为路径包含
个阶段
,每个阶段
的用户集合记为
,则:
- 阶段到达率:
,表示到达第
阶段的用户占第一阶段用户的比例
- 阶段转化率:
,表示从第
阶段转化到第
阶段的比例
- 总体转化率:
,表示整个漏斗的最终转化率
- 流失率:
,表示在第
阶段的用户流失比例
4.2.2 漏斗分析的关键指标
指标名称 | 定义 | 计算公式 | 分析意义 |
|---|---|---|---|
到达人数 | 到达该阶段的用户数 | ∣ U i ∣ |U_i| ∣Ui∣ | 衡量阶段曝光量 |
阶段转化率 | 该阶段的转化比例 | ∣ U i + 1 ∣ ∣ U i ∣ \frac{|U_{i+1}|}{|U_i|} ∣Ui∣∣Ui+1∣ | 衡量阶段转化效率 |
总体转化率 | 整体转化比例 | ∣ U n ∣ ∣ U 1 ∣ \frac{|U_n|}{|U_1|} ∣U1∣∣Un∣ | 衡量整体路径效果 |
流失人数 | 在该阶段流失的用户数 | ∣ U i ∣ − ∣ U i + 1 ∣ |U_i| - |U_{i+1}| ∣Ui∣−∣Ui+1∣ | 量化流失规模 |
流失率 | 该阶段的流失比例 | 1 − C i 1 - C_i 1−Ci | 衡量流失严重程度 |
平均转化时间 | 完成转化的平均时长 | $\frac{\sum_{u \in U_n} (t_n - t_1)}{ | U_n |
衡量阶段曝光量阶段转化率该阶段的转化比例
衡量阶段转化效率总体转化率整体转化比例
衡量整体路径效果流失人数在该阶段流失的用户数
量化流失规模流失率该阶段的流失比例
衡量流失严重程度平均转化时间完成转化的平均时长$\frac{\sum_{u \in U_n} (t_n - t_1)}{U_n
4.3 漏斗分析的系统实现
from typing import List, Dict, Any, Optional, Tuple
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from enum import Enum
import json
class FunnelWindowType(Enum):
FIXED = "fixed"
RELATIVE = "relative"
@dataclass
class FunnelStep:
name: str
event_name: str
conditions: Dict[str, Any] = field(default_factory=dict)
window_start: Optional[int] = None
window_end: Optional[int] = None
@dataclass
class FunnelResult:
funnel_name: str
date_range: Tuple[str, str]
steps: List[str]
step_users: List[int]
step_rates: List[float]
cumulative_rates: List[float]
drop_users: List[int]
drop_rates: List[float]
avg_conversion_time: Optional[float]
def to_dict(self) -> Dict[str, Any]:
return {
"funnel_name": self.funnel_name,
"date_range": {"start": self.date_range[0], "end": self.date_range[1]},
"steps": self.steps,
"step_users": self.step_users,
"step_rates": [round(r, 4) for r in self.step_rates],
"cumulative_rates": [round(r, 4) for r in self.cumulative_rates],
"drop_users": self.drop_users,
"drop_rates": [round(r, 4) for r in self.drop_rates],
"avg_conversion_time": self.avg_conversion_time
}
class FunnelAnalyzer:
def __init__(self, data_source, default_window_seconds: int = 86400 * 7):
self.data_source = data_source
self.default_window_seconds = default_window_seconds
def define_funnel(self, funnel_id: str, funnel_name: str, steps: List[FunnelStep]) -> Dict[str, Any]:
return {
"funnel_id": funnel_id,
"funnel_name": funnel_name,
"steps": steps,
"created_at": datetime.now().isoformat()
}
def analyze(self, funnel: Dict[str, Any], start_date: str, end_date: str) -> FunnelResult:
steps = funnel["steps"]
step_users = [0] * len(steps)
conversion_times = []
for i, step in enumerate(steps):
query = f"""
SELECT COUNT(DISTINCT user_id) as users
FROM events
WHERE event_datetime BETWEEN '{start_date}' AND '{end_date}'
AND event_name = '{step.event_name}'
"""
if i > 0:
prev_step = steps[i-1]
window_start = step.get("window_start", 0)
window_end = step.get("window_end", self.default_window_seconds)
query += f"""
AND timestamp >= (
SELECT MIN(timestamp) FROM events
WHERE event_name = '{prev_step.event_name}'
AND timestamp >= (
SELECT MIN(timestamp) FROM events
WHERE event_name = '{steps[0].event_name}'
)
+ {window_start}
)
AND timestamp <= (
SELECT MIN(timestamp) FROM events
WHERE event_name = '{prev_step.event_name}'
AND timestamp >= (
SELECT MIN(timestamp) FROM events
WHERE event_name = '{steps[0].event_name}'
)
) + {window_end}
"""
result = self.data_source.execute_query(query)
if result:
step_users[i] = result[0].get('users', 0)
step_rates = []
cumulative_rates = []
drop_users = []
drop_rates = []
total_users = step_users[0] if step_users else 0
for i, users in enumerate(step_users):
if i > 0 and step_users[i-1] > 0:
rate = users / step_users[i-1]
else:
rate = 1.0 if i == 0 else 0.0
step_rates.append(rate)
cumulative_rates.append(users / total_users if total_users > 0 else 0.0)
drop = step_users[i-1] - users if i > 0 else 0
drop_users.append(drop)
drop_rates.append(drop / step_users[i-1] if i > 0 and step_users[i-1] > 0 else 0.0)
avg_conversion_time = None
if conversion_times:
valid_times = [t for t in conversion_times if t is not None]
if valid_times:
avg_conversion_time = sum(valid_times) / len(valid_times)
return FunnelResult(
funnel_name=funnel["funnel_name"],
date_range=(start_date, end_date),
steps=[s["name"] for s in steps],
step_users=step_users,
step_rates=step_rates,
cumulative_rates=cumulative_rates,
drop_users=drop_users,
drop_rates=drop_rates,
avg_conversion_time=avg_conversion_time
)
def identify_drop_off_points(self, funnel_result: FunnelResult, threshold: float = 0.1) -> List[Dict[str, Any]]:
critical_points = []
for i, drop_rate in enumerate(funnel_result.drop_rates):
if i == 0:
continue
if drop_rate >= threshold:
critical_points.append({
"step": funnel_result.steps[i],
"previous_step": funnel_result.steps[i-1],
"drop_users": funnel_result.drop_users[i],
"drop_rate": drop_rate,
"priority": "high" if drop_rate >= 0.3 else "medium"
})
return sorted(critical_points, key=lambda x: x["drop_rate"], reverse=True)
analyzer = FunnelAnalyzer(data_source=None)
purchase_funnel = analyzer.define_funnel(
funnel_id="purchase_funnel",
funnel_name="电商购买漏斗",
steps=[
FunnelStep(name="浏览商品", event_name="page_view", conditions={"page_type": "product"}),
FunnelStep(name="加入购物车", event_name="add_to_cart"),
FunnelStep(name="查看购物车", event_name="page_view", conditions={"page_type": "cart"}),
FunnelStep(name="点击结算", event_name="click_button", conditions={"button_id": "checkout"}),
FunnelStep(name="完成支付", event_name="purchase")
]
)
result = analyzer.analyze(purchase_funnel, "2024-01-01", "2024-01-31")
print(json.dumps(result.to_dict(), indent=2, ensure_ascii=False))
critical_points = analyzer.identify_drop_off_points(result, threshold=0.2)
print("Critical Drop-off Points:")
for point in critical_points:
print(f" - {point['step']}: {point['drop_rate']:.2%} drop rate ({point['drop_users']} users)")4.4 漏斗分析的可视化
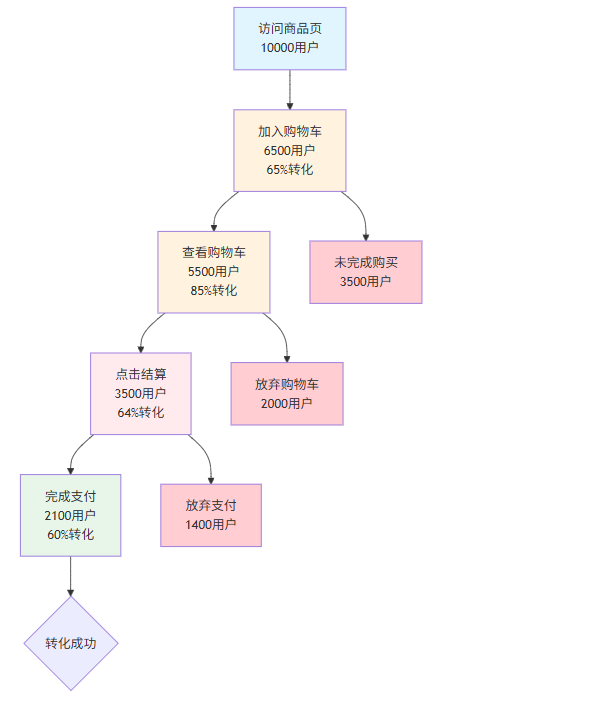
4.5 漏斗分析SQL示例
-- 漏斗分析SQL
WITH funnel_events AS (
SELECT
user_id,
session_id,
event_name,
event_datetime,
CASE
WHEN event_name = 'page_view' AND page.url LIKE '%/products%' THEN 1
WHEN event_name = 'add_to_cart' THEN 2
WHEN event_name = 'page_view' AND page.url LIKE '%/cart%' THEN 3
WHEN event_name = 'click_button' AND properties.button_id = 'checkout' THEN 4
WHEN event_name = 'purchase' THEN 5
ELSE NULL
END AS funnel_step
FROM raw_events
WHERE DATE(event_datetime) = '2024-01-15'
AND event_name IN ('page_view', 'click_button', 'purchase')
),
funnel_users AS (
SELECT
user_id,
MIN(funnel_step) AS first_step,
MAX(funnel_step) AS max_step
FROM funnel_events
WHERE funnel_step IS NOT NULL
GROUP BY user_id
HAVING MIN(funnel_step) = 1
),
step_counts AS (
SELECT step_num, COUNT(DISTINCT user_id) AS users
FROM (
SELECT user_id, 1 AS step_num FROM funnel_users WHERE first_step <= 1
UNION ALL
SELECT user_id, 2 AS step_num FROM funnel_users WHERE max_step >= 2
UNION ALL
SELECT user_id, 3 AS step_num FROM funnel_users WHERE max_step >= 3
UNION ALL
SELECT user_id, 4 AS step_num FROM funnel_users WHERE max_step >= 4
UNION ALL
SELECT user_id, 5 AS step_num FROM funnel_users WHERE max_step >= 5
)
GROUP BY step_num
)
SELECT
step_num,
users,
LAG(users) OVER (ORDER BY step_num) AS prev_users,
ROUND(users / LAG(users) OVER (ORDER BY step_num) * 100, 2) AS conversion_rate
FROM step_counts
ORDER BY step_num;第五章 留存分析:Cohort分析与留存曲线
5.1 留存分析的核心概念
本节为你提供的核心技术价值:掌握留存分析的理论基础,理解Cohort分析的原理,学会计算和分析留存曲线,发现用户留存的规律和问题。
留存分析(Retention Analysis)是用户行为分析中衡量产品健康度的核心指标之一。它关注用户在使用产品一段时间后是否会继续使用,帮助产品团队评估产品价值、识别用户流失原因、指导产品迭代方向。
留存分析的核心概念:
- 留存用户:在某个时间段后仍然活跃的用户
- 流失用户:在一段时间后不再活跃的用户
- 留存率:在某时间点留存的用户占初始用户的比例
- Cohort:具有相同初始行为的一组用户
5.2 留存率的形式化定义
设
为一个Cohort,
为 Cohort 的初始日期,
为 Cohort 在第
天的留存用户集合,则:
- Cohort规模:
,Cohort中的初始用户数
- 第
天留存用户数:
,在第
天仍然活跃的用户数
- 第
天留存率:
留存曲线描述了留存率随时间变化的趋势,是评估产品用户粘性的重要工具。
5.3 Cohort分析的实现
from typing import List, Dict, Any, Optional
from dataclasses import dataclass
from datetime import datetime, timedelta
from collections import defaultdict
import pandas as pd
import numpy as np
@dataclass
class CohortConfig:
cohort_type: str = "daily"
retention_periods: int = 30
date_format: str = "%Y-%m-%d"
@dataclass
class CohortResult:
cohort_type: str
cohort_dates: List[str]
retention_matrix: List[List[float]]
cohort_sizes: List[int]
def to_dataframe(self) -> pd.DataFrame:
columns = [f"Day {i}" for i in range(len(self.retention_matrix[0]))]
return pd.DataFrame(self.retention_matrix, index=self.cohort_dates, columns=columns)
def get_avg_retention(self, day: int) -> float:
if day >= len(self.retention_matrix[0]):
return 0.0
total = sum(row[day] for row in self.retention_matrix)
count = len(self.retention_matrix)
return total / count if count > 0 else 0.0
class RetentionAnalyzer:
def __init__(self, config: Optional[CohortConfig] = None):
self.config = config or CohortConfig()
def analyze_cohort(self, user_activity: List[Dict[str, Any]], start_date: str, end_date: str) -> CohortResult:
cohorts = defaultdict(lambda: defaultdict(set))
for record in user_activity:
user_id = record["user_id"]
activity_date = record["activity_date"]
cohort_date = self._get_cohort_date(activity_date)
day_diff = self._calculate_day_diff(cohort_date, activity_date)
if day_diff >= 0 and day_diff <= self.config.retention_periods:
cohorts[cohort_date][day_diff].add(user_id)
cohort_dates = sorted(cohorts.keys())
retention_matrix = []
cohort_sizes = []
for cohort_date in cohort_dates:
cohort_data = cohorts[cohort_date]
cohort_size = len(cohort_data.get(0, set()))
if cohort_size == 0:
continue
cohort_sizes.append(cohort_size)
retention_row = []
for day in range(self.config.retention_periods + 1):
retained_users = len(cohort_data.get(day, set()))
retention_rate = retained_users / cohort_size
retention_row.append(round(retention_rate, 4))
retention_matrix.append(retention_row)
return CohortResult(
cohort_type=self.config.cohort_type,
cohort_dates=cohort_dates,
retention_matrix=retention_matrix,
cohort_sizes=cohort_sizes
)
def _get_cohort_date(self, date_str: str) -> str:
dt = datetime.strptime(date_str, self.config.date_format)
if self.config.cohort_type == "daily":
return dt.strftime(self.config.date_format)
elif self.config.cohort_type == "weekly":
monday = dt - timedelta(days=dt.weekday())
return monday.strftime(self.config.date_format)
elif self.config.cohort_type == "monthly":
return dt.strftime("%Y-%m-01")
else:
return date_str
def _calculate_day_diff(self, cohort_date: str, activity_date: str) -> int:
dt1 = datetime.strptime(cohort_date, self.config.date_format)
dt2 = datetime.strptime(activity_date, self.config.date_format)
return (dt2 - dt1).days
def calculate_retention_curve(self, cohort_result: CohortResult) -> Dict[int, float]:
curve = {}
for day in range(len(cohort_result.retention_matrix[0])):
curve[day] = cohort_result.get_avg_retention(day)
return curve
def identify_retention_issues(self, cohort_result: CohortResult, thresholds: Optional[Dict[int, float]] = None) -> List[Dict[str, Any]]:
default_thresholds = {1: 0.40, 7: 0.20, 14: 0.15, 30: 0.10}
thresholds = thresholds or default_thresholds
issues = []
for i, cohort_date in enumerate(cohort_result.cohort_dates):
cohort_retention = cohort_result.retention_matrix[i]
for day, threshold in thresholds.items():
if day < len(cohort_retention):
if cohort_retention[day] < threshold:
issues.append({
"cohort_date": cohort_date,
"day": day,
"actual_rate": cohort_retention[day],
"threshold": threshold,
"gap": cohort_retention[day] - threshold
})
return sorted(issues, key=lambda x: x["gap"])
def predict_retention(self, cohort_result: CohortResult, future_days: int = 7) -> Dict[int, float]:
curve = self.calculate_retention_curve(cohort_result)
valid_points = [(d, r) for d, r in curve.items() if d > 0 and r > 0]
if len(valid_points) < 2:
return {}
log_d = np.log([d for d, r in valid_points])
log_r = np.log([r for d, r in valid_points])
n = len(log_d)
sum_x = sum(log_d)
sum_y = sum(log_r)
sum_xy = sum(x * y for x, y in zip(log_d, log_r))
sum_x2 = sum(x ** 2 for x in log_d)
alpha = (n * sum_xy - sum_x * sum_y) / (n * sum_x2 - sum_x ** 2)
r1 = np.exp((sum_y - alpha * sum_x) / n)
predictions = {}
base_retention = curve.get(1, 0.1)
for day in range(1, future_days + 1):
predicted = base_retention * (day ** alpha)
predictions[day] = max(0.0, min(1.0, predicted))
return predictions
config = CohortConfig(cohort_type="daily", retention_periods=30)
analyzer = RetentionAnalyzer(config)
np.random.seed(42)
user_activity = []
base_date = datetime(2024, 1, 1)
for user_id in range(1000):
first_day = np.random.randint(0, 30)
cohort_date = (base_date + timedelta(days=first_day)).strftime("%Y-%m-%d")
is_active = True
day = 0
while is_active and day <= 30:
retention_prob = 0.5 * (day + 1) ** (-0.5)
if np.random.random() < retention_prob:
activity_date = (base_date + timedelta(days=first_day + day)).strftime("%Y-%m-%d")
user_activity.append({"user_id": f"user_{user_id}", "activity_date": activity_date})
day += 1
else:
is_active = False
result = analyzer.analyze_cohort(user_activity, "2024-01-01", "2024-01-31")
print("=== Cohort Retention Matrix ===")
df = result.to_dataframe()
print(df.head(10))
print("\n=== Average Retention Curve ===")
curve = analyzer.calculate_retention_curve(result)
for day, rate in list(curve.items())[:8]:
print(f"Day {day}: {rate:.2%}")5.4 留存分析的可视化
渲染错误: Mermaid 渲染失败: Parse error on line 3: ...B --> C[绘制留存曲线 R(t) = f(time)] C -----------------------^ Expecting 'SQE', 'DOUBLECIRCLEEND', 'PE', '-)', 'STADIUMEND', 'SUBROUTINEEND', 'PIPE', 'CYLINDEREND', 'DIAMOND_STOP', 'TAGEND', 'TRAPEND', 'INVTRAPEND', 'UNICODE_TEXT', 'TEXT', 'TAGSTART', got 'PS'
5.5 核心留存指标体系
指标名称 | 定义 | 计算公式 | 业务意义 |
|---|---|---|---|
D0留存率 | 首日留存 | D a y 1 _ A c t i v e T o t a l _ U s e r s × 100 % \frac{Day1\_Active}{Total\_Users} \times 100\% Total_UsersDay1_Active×100% | 衡量新用户激活效果 |
D1留存率 | 次日留存 | D a y 2 _ A c t i v e D a y 1 _ A c t i v e × 100 % \frac{Day2\_Active}{Day1\_Active} \times 100\% Day1_ActiveDay2_Active×100% | 衡量首日体验 |
D7留存率 | 周留存 | D a y 7 _ A c t i v e D a y 1 _ A c t i v e × 100 % \frac{Day7\_Active}{Day1\_Active} \times 100\% Day1_ActiveDay7_Active×100% | 衡量用户习惯形成 |
D30留存率 | 月留存 | D a y 30 _ A c t i v e D a y 1 _ A c t i v e × 100 % \frac{Day30\_Active}{Day1\_Active} \times 100\% Day1_ActiveDay30_Active×100% | 衡量产品核心价值 |
Rolling Retention | 滚动留存 | 第N天+之后任意一天回访 | 更准确的留存定义 |
Bracket Retention | 区间留存 | N天内至少回访K次 | 衡量用户粘性 |
衡量新用户激活效果D1留存率次日留存
衡量首日体验D7留存率周留存
衡量用户习惯形成D30留存率月留存
衡量产品核心价值Rolling Retention滚动留存第N天+之后任意一天回访更准确的留存定义Bracket Retention区间留存N天内至少回访K次衡量用户粘性
5.6 留存分析SQL示例
-- 留存分析SQL
WITH user_cohorts AS (
SELECT
user_id,
MIN(DATE(event_datetime)) AS cohort_date
FROM raw_events
WHERE DATE(event_datetime) BETWEEN '2024-01-01' AND '2024-01-31'
AND user_id IS NOT NULL
GROUP BY user_id
),
user_activity AS (
SELECT
e.user_id,
c.cohort_date,
DATE(e.event_datetime) AS activity_date,
DATEDIFF(DAY, c.cohort_date, DATE(e.event_datetime)) AS days_since_cohort
FROM raw_events e
JOIN user_cohorts c ON e.user_id = c.user_id
WHERE DATE(e.event_datetime) BETWEEN '2024-01-01' AND '2024-02-28'
AND e.user_id IS NOT NULL
),
cohort_sizes AS (
SELECT cohort_date, COUNT(DISTINCT user_id) AS cohort_size
FROM user_cohorts
GROUP BY cohort_date
),
retention_data AS (
SELECT
c.cohort_date,
a.days_since_cohort,
COUNT(DISTINCT a.user_id) AS retained_users,
cs.cohort_size
FROM user_activity a
JOIN cohort_sizes cs ON a.cohort_date = cs.cohort_date
WHERE a.days_since_cohort BETWEEN 0 AND 30
GROUP BY c.cohort_date, a.days_since_cohort, cs.cohort_size
)
SELECT
cohort_date,
cohort_size,
MAX(CASE WHEN days_since_cohort = 0 THEN retained_users END) AS day_0,
MAX(CASE WHEN days_since_cohort = 1 THEN retained_users END) AS day_1,
MAX(CASE WHEN days_since_cohort = 3 THEN retained_users END) AS day_3,
MAX(CASE WHEN days_since_cohort = 7 THEN retained_users END) AS day_7,
MAX(CASE WHEN days_since_cohort = 14 THEN retained_users END) AS day_14,
MAX(CASE WHEN days_since_cohort = 30 THEN retained_users END) AS day_30,
ROUND(MAX(CASE WHEN days_since_cohort = 1 THEN retained_users END) / cohort_size * 100, 2) AS d1_rate,
ROUND(MAX(CASE WHEN days_since_cohort = 7 THEN retained_users END) / cohort_size * 100, 2) AS d7_rate,
ROUND(MAX(CASE WHEN days_since_cohort = 30 THEN retained_users END) / cohort_size * 100, 2) AS d30_rate
FROM retention_data
GROUP BY cohort_date, cohort_size
ORDER BY cohort_date;第六章 实践:构建完整的用户行为分析系统
6.1 系统架构设计
本节为你提供的核心技术价值:通过一个完整的端到端实例,学会如何将事件采集、数据存储、数据分析串联起来,构建一个实用的用户行为分析系统。
一个完整的用户行为分析系统通常包含以下组件:
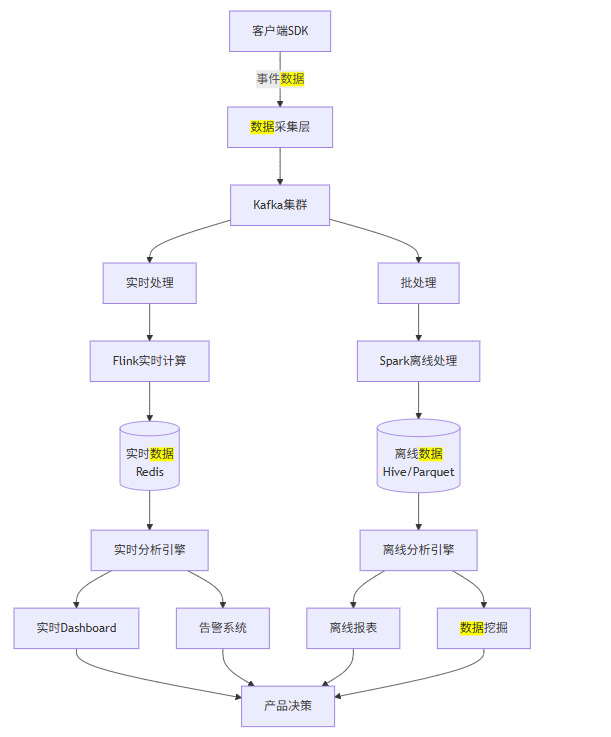
6.2 完整代码实现
"""
完整的用户行为分析系统实现
"""
import json
import time
import uuid
import logging
from datetime import datetime, timezone
from typing import Dict, List, Any, Optional
from dataclasses import dataclass, field, asdict
from enum import Enum
import threading
import queue
from collections import defaultdict
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class EventBatchMode(Enum):
SYNC = "sync"
BATCH = "batch"
ASYNC = "async"
@dataclass
class EventContext:
ip: Optional[str] = None
user_agent: Optional[str] = None
device: Optional[str] = None
os: Optional[str] = None
browser: Optional[str] = None
screen_width: Optional[int] = None
screen_height: Optional[int] = None
country: Optional[str] = None
province: Optional[str] = None
city: Optional[str] = None
platform: str = "web"
app_version: str = "1.0.0"
def to_dict(self) -> Dict[str, Any]:
return {k: v for k, v in asdict(self).items() if v is not None}
@dataclass
class Event:
event_id: str = field(default_factory=lambda: str(uuid.uuid4()))
event_name: str = ""
user_id: Optional[str] = None
anonymous_id: Optional[str] = None
session_id: Optional[str] = None
timestamp: int = field(default_factory=lambda: int(time.time() * 1000))
datetime: str = field(default_factory=lambda: datetime.fromtimestamp(time.time(), tz=timezone.utc).isoformat())
context: EventContext = field(default_factory=EventContext)
properties: Dict[str, Any] = field(default_factory=dict)
def to_dict(self) -> Dict[str, Any]:
return {
"event_id": self.event_id,
"event_name": self.event_name,
"user_id": self.user_id,
"anonymous_id": self.anonymous_id,
"session_id": self.session_id,
"timestamp": self.timestamp,
"datetime": self.datetime,
"context": self.context.to_dict(),
"properties": self.properties
}
class UserBehaviorAnalytics:
"""
用户行为分析系统 - 核心类
功能:
1. 事件采集与管理
2. 用户身份管理
3. 会话管理
4. 数据存储
5. 漏斗分析
6. 留存分析
7. 实时统计
"""
def __init__(
self,
server_url: str = "https://analytics.example.com",
batch_size: int = 100,
flush_interval: int = 5
):
self.server_url = server_url
self.batch_size = batch_size
self.flush_interval = flush_interval
# 事件队列
self._event_queue: queue.Queue = queue.Queue(maxsize=10000)
# 用户数据存储(内存)
self._users: Dict[str, Dict] = {}
self._sessions: Dict[str, List[Event]] = defaultdict(list)
# 统计数据
self._stats = {
"total_events": 0,
"total_users": 0,
"total_sessions": 0,
"daily_active_users": defaultdict(set),
"hourly_events": defaultdict(int)
}
# 锁
self._lock = threading.Lock()
# 运行状态
self._running = False
# 启动后台线程
self._start_background_workers()
def _start_background_workers(self):
"""启动后台工作线程"""
self._running = True
# 事件处理线程
self._processor_thread = threading.Thread(target=self._process_events, daemon=True)
self._processor_thread.start()
# 定时刷新线程
self._timer_thread = threading.Thread(target=self._periodic_flush, daemon=True)
self._timer_thread.start()
# 统计更新线程
self._stats_thread = threading.Thread(target=self._update_stats, daemon=True)
self._stats_thread.start()
def track(
self,
event_name: str,
user_id: Optional[str] = None,
anonymous_id: Optional[str] = None,
session_id: Optional[str] = None,
properties: Optional[Dict[str, Any]] = None,
context: Optional[EventContext] = None
) -> str:
"""
记录用户行为事件
Args:
event_name: 事件名称
user_id: 用户ID
anonymous_id: 匿名ID
session_id: 会话ID
properties: 事件属性
context: 事件上下文
Returns:
事件ID
"""
event = Event(
event_name=event_name,
user_id=user_id,
anonymous_id=anonymous_id,
session_id=session_id or self._get_or_create_session_id(user_id, anonymous_id),
properties=properties or {},
context=context or EventContext()
)
try:
self._event_queue.put_nowait(event)
except queue.Full:
logger.warning("Event queue is full, dropping event")
return event.event_id
def track_page_view(
self,
page_url: str,
page_title: Optional[str] = None,
user_id: Optional[str] = None,
anonymous_id: Optional[str] = None,
referrer: Optional[str] = None,
properties: Optional[Dict[str, Any]] = None
) -> str:
"""记录页面浏览事件"""
props = properties or {}
props.update({
"url": page_url,
"title": page_title,
"referrer": referrer
})
return self.track("page_view", user_id, anonymous_id, properties=props)
def track_click(
self,
element_id: str,
element_text: Optional[str] = None,
element_type: str = "button",
user_id: Optional[str] = None,
anonymous_id: Optional[str] = None,
properties: Optional[Dict[str, Any]] = None
) -> str:
"""记录点击事件"""
props = properties or {}
props.update({
"element_id": element_id,
"element_text": element_text,
"element_type": element_type
})
return self.track("click", user_id, anonymous_id, properties=props)
def identify_user(
self,
user_id: str,
anonymous_id: Optional[str] = None,
properties: Optional[Dict[str, Any]] = None
):
"""
识别用户并设置用户属性
Args:
user_id: 用户ID
anonymous_id: 关联的匿名ID
properties: 用户属性
"""
with self._lock:
if user_id not in self._users:
self._users[user_id] = {
"user_id": user_id,
"anonymous_id": anonymous_id,
"first_seen": datetime.now().isoformat(),
"properties": properties or {}
}
self._stats["total_users"] += 1
else:
if properties:
self._users[user_id]["properties"].update(properties)
def _get_or_create_session_id(self, user_id: Optional[str], anonymous_id: Optional[str]) -> str:
"""获取或创建会话ID"""
key = user_id or anonymous_id or "anonymous"
# 检查是否有活跃会话(30分钟超时)
# 简化实现,实际应检查时间戳
return f"sess_{key}_{int(time.time() // 1800)}"
def _process_events(self):
"""事件处理线程"""
while self._running:
try:
events = []
for _ in range(self.batch_size):
try:
event = self._event_queue.get(timeout=1)
events.append(event.to_dict())
self._event_queue.task_done()
except queue.Empty:
break
if events:
self._send_to_server(events)
self._update_in_memory_data(events)
except Exception as e:
logger.error(f"Error processing events: {e}")
def _send_to_server(self, events: List[Dict[str, Any]]):
"""发送事件到服务器"""
# 实际实现中应发送到服务器
# 这里仅记录日志
logger.info(f"Sending {len(events)} events to {self.server_url}")
def _update_in_memory_data(self, events: List[Dict[str, Any]]):
"""更新内存中的数据"""
with self._lock:
for event in events:
# 更新用户会话
session_id = event.get("session_id")
if session_id:
self._sessions[session_id].append(event)
# 更新DAU统计
user_id = event.get("user_id")
if user_id:
today = datetime.now().strftime("%Y-%m-%d")
self._stats["daily_active_users"][today].add(user_id)
# 更新小时统计
hour = datetime.now().strftime("%Y-%m-%d %H:00")
self._stats["hourly_events"][hour] += 1
self._stats["total_events"] += 1
def _periodic_flush(self):
"""定时刷新"""
while self._running:
time.sleep(self.flush_interval)
self.flush()
def flush(self):
"""立即刷新队列"""
events = []
while True:
try:
event = self._event_queue.get_nowait()
events.append(event.to_dict())
self._event_queue.task_done()
except queue.Empty:
break
if events:
self._send_to_server(events)
self._update_in_memory_data(events)
def _update_stats(self):
"""更新统计"""
while self._running:
time.sleep(60) # 每分钟更新一次统计
with self._lock:
stats = {
"total_events": self._stats["total_events"],
"total_users": self._stats["total_users"],
"total_sessions": len(self._sessions),
"queue_size": self._event_queue.qsize(),
"daily_active_users": {
date: len(users)
for date, users in self._stats["daily_active_users"].items()
}
}
logger.info(f"Stats: {json.dumps(stats)}")
def get_stats(self) -> Dict[str, Any]:
"""获取统计信息"""
with self._lock:
return {
"total_events": self._stats["total_events"],
"total_users": self._stats["total_users"],
"total_sessions": len(self._sessions),
"queue_size": self._event_queue.qsize()
}
def get_dau(self, days: int = 7) -> Dict[str, int]:
"""获取最近N天的DAU"""
result = {}
today = datetime.now()
with self._lock:
for i in range(days):
date = (today - datetime.timedelta(days=i)).strftime("%Y-%m-%d")
result[date] = len(self._stats["daily_active_users"].get(date, set()))
return result
def funnel_analysis(self, funnel_steps: List[str], start_date: str, end_date: str) -> Dict[str, Any]:
"""
漏斗分析
Args:
funnel_steps: 漏斗步骤列表
start_date: 开始日期
end_date: 结束日期
Returns:
漏斗分析结果
"""
step_counts = {step: 0 for step in funnel_steps}
with self._lock:
for session_events in self._sessions.values():
reached_steps = set()
for event in session_events:
event_name = event.get("event_name")
event_date = event.get("datetime", "")[:10]
if start_date <= event_date <= end_date:
if event_name in funnel_steps:
reached_steps.add(event_name)
for step in reached_steps:
step_counts[step] += 1
# 计算转化率
results = []
prev_count = None
for i, step in enumerate(funnel_steps):
count = step_counts[step]
rate = 1.0 if i == 0 else (count / prev_count if prev_count > 0 else 0.0)
results.append({
"step": step,
"users": count,
"conversion_rate": round(rate, 4)
})
prev_count = count
return {"funnel": funnel_steps, "results": results}
def retention_analysis(self, cohort_type: str = "daily", periods: int = 30) -> Dict[str, Any]:
"""
留存分析
Args:
cohort_type: Cohort类型 (daily/weekly/monthly)
periods: 分析周期
Returns:
留存分析结果
"""
# 按Cohort分组用户
cohorts = defaultdict(lambda: defaultdict(set))
with self._lock:
# 收集所有用户和其活跃日期
user_activities = defaultdict(set)
for session_events in self._sessions.values():
for event in session_events:
user_id = event.get("user_id")
if user_id:
date = event.get("datetime", "")[:10]
user_activities[user_id].add(date)
# 确定每个用户的首次活跃日期(Cohort)
for user_id, activity_dates in user_activities.items():
if activity_dates:
first_date = min(activity_dates)
cohorts[first_date]["day_0"].add(user_id)
# 计算留存
for date in activity_dates:
day_diff = (datetime.strptime(date, "%Y-%m-%d") -
datetime.strptime(first_date, "%Y-%m-%d")).days
if day_diff <= periods:
cohorts[first_date][f"day_{day_diff}"].add(user_id)
# 计算留存率
retention_matrix = []
for cohort_date in sorted(cohorts.keys())[:10]: # 最近10个Cohort
cohort_data = cohorts[cohort_date]
cohort_size = len(cohort_data.get("day_0", set()))
if cohort_size == 0:
continue
row = {"cohort_date": cohort_date, "cohort_size": cohort_size}
for day in range(min(periods, 30) + 1):
retained = len(cohort_data.get(f"day_{day}", set()))
retention_rate = retained / cohort_size
row[f"day_{day}"] = round(retention_rate, 4)
retention_matrix.append(row)
return {"cohort_type": cohort_type, "retention_matrix": retention_matrix}
def close(self):
"""关闭系统"""
self._running = False
self.flush()
logger.info("UserBehaviorAnalytics closed")
def main():
"""使用示例"""
# 初始化分析系统
analytics = UserBehaviorAnalytics(
server_url="https://analytics.example.com",
batch_size=50,
flush_interval=3
)
# 模拟用户行为
print("=== Tracking User Behavior ===")
# 匿名用户浏览页面
analytics.track_page_view(
page_url="/products/iphone15",
page_title="iPhone 15 商品详情",
anonymous_id="anon_12345",
referrer="https://google.com"
)
# 用户登录后
analytics.identify_user(
user_id="user_10001",
anonymous_id="anon_12345",
properties={"plan": "premium", "registration_date": "2024-01-01"}
)
# 登录用户浏览商品
analytics.track_page_view(
page_url="/products/iphone15",
page_title="iPhone 15 商品详情",
user_id="user_10001",
referrer="https://google.com"
)
# 点击加入购物车
analytics.track_click(
element_id="add_to_cart",
element_text="加入购物车",
element_type="button",
user_id="user_10001"
)
# 加入购物车
analytics.track("add_to_cart", user_id="user_10001", properties={
"product_id": "prod_88888",
"product_name": "iPhone 15 Pro",
"price": 9999.00,
"quantity": 1
})
# 查看购物车
analytics.track_page_view(
page_url="/cart",
page_title="购物车",
user_id="user_10001"
)
# 点击结算
analytics.track_click(
element_id="checkout",
element_text="结算",
element_type="button",
user_id="user_10001"
)
# 提交订单
analytics.track("create_order", user_id="user_10001", properties={
"order_id": "ord_98765",
"amount": 9999.00,
"item_count": 1
})
# 完成支付
analytics.track("purchase", user_id="user_10001", properties={
"order_id": "ord_98765",
"amount": 9999.00,
"payment_method": "wechat_pay"
})
# 等待事件处理
time.sleep(2)
# 获取统计信息
print("\n=== System Stats ===")
stats = analytics.get_stats()
print(json.dumps(stats, indent=2))
# 漏斗分析
print("\n=== Funnel Analysis ===")
funnel_result = analytics.funnel_analysis(
funnel_steps=["page_view", "add_to_cart", "create_order", "purchase"],
start_date="2024-01-01",
end_date="2024-12-31"
)
print(json.dumps(funnel_result, indent=2))
# 留存分析
print("\n=== Retention Analysis ===")
retention_result = analytics.retention_analysis(cohort_type="daily", periods=7)
print(json.dumps(retention_result, indent=2))
# 关闭系统
analytics.close()
if __name__ == "__main__":
main()6.3 系统部署与运维
6.3.1 Docker部署配置
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
EXPOSE 5000
CMD ["python", "server.py"]6.3.2 docker-compose编排
version: '3.8'
services:
analytics-api:
build: .
ports:
- "5000:5000"
environment:
- KAFKA_BROKERS=kafka:9092
- REDIS_URL=redis://redis:6379
- HIVE_METASTORE_URI=thrift://hive:9083
depends_on:
- kafka
- redis
volumes:
- ./data:/data
restart: unless-stopped
kafka:
image: confluentinc/cp-kafka:7.5.0
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
depends_on:
- zookeeper
restart: unless-stopped
zookeeper:
image: confluentinc/cp-zookeeper:7.5.0
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
restart: unless-stopped
redis:
image: redis:7-alpine
ports:
- "6379:6379"
volumes:
- redis-data:/data
restart: unless-stopped
flink-jobmanager:
image: flink:1.17
ports:
- "8081:8081"
command: jobmanager
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: flink-jobmanager
restart: unless-stopped
flink-taskmanager:
image: flink:1.17
depends_on:
- flink-jobmanager
command: taskmanager
scale: 2
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 2
restart: unless-stopped
volumes:
redis-data:参考链接
- Mixpanel Analytics Platform - 行为分析平台参考
- Amplitude Analytics - 产品分析平台参考
- Google Analytics 4 - Google官方分析文档
- Apache Hive Documentation - Hive数据仓库文档
- Google BigQuery Documentation - BigQuery官方文档
- Snowflake Documentation - Snowflake数据仓库文档
- Apache Kafka Documentation - Kafka消息队列文档
- Apache Flink Documentation - Flink流处理文档
参考论文:
参考链接:
- 主要来源:Apache Hive - 开源数据仓库系统
- 主要来源:Google BigQuery - 云原生数据仓库服务
- 主要来源:Snowflake Documentation - 企业级数据仓库平台
- 主要来源:Mixpanel - 用户行为分析平台参考
- 主要来源:Amplitude - 产品分析最佳实践
附录(Appendix):
A. 埋点系统完整代码
A.1 Web端SDK完整实现
class TrackerSDK {
constructor(config) {
this.config = {
projectId: config.projectId || '',
serverUrl: config.serverUrl || '',
debug: config.debug || false,
sessionTimeout: config.sessionTimeout || 30 * 60 * 1000, // 30分钟
batchSize: config.batchSize || 100,
flushInterval: config.flushInterval || 5000
};
this.eventQueue = [];
this.sessionId = this._getOrCreateSessionId();
this.userId = this._getUserId();
this.anonymousId = this._getOrCreateAnonymousId();
this.lastActivityTime = Date.now();
this._init();
}
_init() {
// 绑定事件监听
this._bindEventListeners();
// 启动定时刷新
setInterval(() => this.flush(), this.config.flushInterval);
// 监听页面卸载
window.addEventListener('beforeunload', () => this.flush());
this._log('TrackerSDK initialized');
}
_getOrCreateSessionId() {
const key = 'tracker_session_id';
let sessionId = sessionStorage.getItem(key);
if (!sessionId) {
sessionId = `sess_${Date.now()}_${Math.random().toString(36).substr(2, 9)}`;
sessionStorage.setItem(key, sessionId);
}
return sessionId;
}
_getOrCreateAnonymousId() {
const key = 'tracker_anonymous_id';
let anonymousId = localStorage.getItem(key);
if (!anonymousId) {
anonymousId = `anon_${Date.now()}_${Math.random().toString(36).substr(2, 9)}`;
localStorage.setItem(key, anonymousId);
}
return anonymousId;
}
_getUserId() {
// 从Cookie或其他存储获取登录用户ID
const match = document.cookie.match(/user_id=([^;]+)/);
return match ? match[1] : null;
}
_bindEventListeners() {
// 页面浏览
window.addEventListener('load', () => {
this.track('page_view', {
url: window.location.href,
title: document.title,
referrer: document.referrer
});
});
// 点击事件
document.addEventListener('click', (e) => {
const target = e.target.closest('[data-track]');
if (target) {
const eventName = target.dataset.track;
const properties = JSON.parse(target.dataset.trackProps || '{}');
this.track(eventName, properties);
}
});
// 滚动深度
let maxScrollDepth = 0;
window.addEventListener('scroll', this._throttle(() => {
const scrollDepth = Math.round(
(window.scrollY / (document.body.scrollHeight - window.innerHeight)) * 100
);
if (scrollDepth > maxScrollDepth) {
maxScrollDepth = scrollDepth;
const bucket = Math.floor(scrollDepth / 25) * 25;
this.track('scroll_depth', { depth: bucket });
}
}, 1000));
// 页面可见性
document.addEventListener('visibilitychange', () => {
this.track('page_visibility', {
visible: document.visibilityState === 'visible'
});
});
}
track(eventName, properties = {}) {
const event = {
event_id: `evt_${Date.now()}_${Math.random().toString(36).substr(2, 9)}`,
event_name: eventName,
user_id: this.userId,
anonymous_id: this.anonymousId,
session_id: this.sessionId,
timestamp: Date.now(),
context: {
url: window.location.href,
title: document.title,
user_agent: navigator.userAgent,
screen_width: window.screen.width,
screen_height: window.screen.height,
language: navigator.language,
platform: navigator.platform
},
properties
};
this.eventQueue.push(event);
if (this.eventQueue.length >= this.config.batchSize) {
this.flush();
}
}
flush() {
if (this.eventQueue.length === 0) return;
const events = this.eventQueue.splice(0, this.eventQueue.length);
this._send(events).catch(err => {
this._log('Failed to send events', err);
this.eventQueue.unshift(...events);
});
}
async _send(events) {
const payload = {
project_id: this.config.projectId,
events,
batch_timestamp: Date.now()
};
if (this.config.debug) {
console.log('[TrackerSDK]', payload);
}
await fetch(`${this.config.serverUrl}/batch`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(payload),
keepalive: true
});
}
_log(...args) {
if (this.config.debug) {
console.log('[TrackerSDK]', ...args);
}
}
_throttle(fn, limit) {
let inThrottle;
return function(...args) {
if (!inThrottle) {
fn.apply(this, args);
inThrottle = true;
setTimeout(() => inThrottle = false, limit);
}
};
}
}
// 初始化
window.TrackerSDK = TrackerSDK;A.2 数据分析服务完整实现
"""
用户行为分析服务 - 完整实现
"""
from flask import Flask, request, jsonify
from datetime import datetime, timedelta
from collections import defaultdict
from typing import Dict, List, Any
import json
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
app = Flask(__name__)
class EventStore:
"""事件存储器"""
def __init__(self):
self.events: List[Dict] = []
self.users: Dict[str, Dict] = {}
self.sessions: Dict[str, List[Dict]] = defaultdict(list)
def store(self, events: List[Dict]):
"""存储事件"""
for event in events:
self.events.append(event)
# 更新用户数据
user_id = event.get('user_id')
if user_id:
if user_id not in self.users:
self.users[user_id] = {
'user_id': user_id,
'first_seen': event.get('timestamp'),
'last_seen': event.get('timestamp'),
'event_count': 0
}
else:
self.users[user_id]['last_seen'] = event.get('timestamp')
self.users[user_id]['event_count'] += 1
# 更新会话数据
session_id = event.get('session_id')
if session_id:
self.sessions[session_id].append(event)
def get_user_events(self, user_id: str, start_time: int = None, end_time: int = None) -> List[Dict]:
"""获取用户事件"""
events = [e for e in self.events if e.get('user_id') == user_id]
if start_time:
events = [e for e in events if e.get('timestamp', 0) >= start_time]
if end_time:
events = [e for e in events if e.get('timestamp', 0) <= end_time]
return events
def get_session_events(self, session_id: str) -> List[Dict]:
"""获取会话事件"""
return self.sessions.get(session_id, [])
class AnalyticsEngine:
"""分析引擎"""
def __init__(self, event_store: EventStore):
self.event_store = event_store
def calculate_dau(self, date: str) -> int:
"""计算日活用户数"""
start_time = datetime.strptime(date, '%Y-%m-%d').timestamp() * 1000
end_time = start_time + 86400000
users = set()
for event in self.event_store.events:
ts = event.get('timestamp', 0)
if start_time <= ts < end_time:
user_id = event.get('user_id') or event.get('anonymous_id')
if user_id:
users.add(user_id)
return len(users)
def funnel_analysis(self, funnel_steps: List[str], start_date: str, end_date: str) -> Dict:
"""漏斗分析"""
start_time = datetime.strptime(start_date, '%Y-%m-%d').timestamp() * 1000
end_time = datetime.strptime(end_date, '%Y-%m-%d').timestamp() * 1000 + 86400000
step_users = defaultdict(set)
for event in self.event_store.events:
ts = event.get('timestamp', 0)
if start_time <= ts < end_time:
event_name = event.get('event_name')
user_id = event.get('user_id')
if user_id and event_name in funnel_steps:
step_users[event_name].add(user_id)
results = []
prev_count = None
for step in funnel_steps:
users = step_users.get(step, set())
count = len(users)
rate = 1.0 if prev_count is None else (count / prev_count if prev_count > 0 else 0.0)
results.append({
'step': step,
'users': count,
'rate': round(rate, 4)
})
prev_count = count
return {
'funnel': funnel_steps,
'results': results,
'overall_conversion': round(prev_count / len(results[0]['users']) if results else 0, 4)
}
def retention_analysis(self, cohort_type: str = 'daily', periods: int = 30) -> Dict:
"""留存分析"""
cohorts = defaultdict(lambda: defaultdict(set))
# 按Cohort分组
for user_id, user_data in self.event_store.users.items():
first_seen = user_data.get('first_seen')
if not first_seen:
continue
first_date = datetime.fromtimestamp(first_seen / 1000).strftime('%Y-%m-%d')
# 获取用户的所有活跃日期
user_events = self.event_store.get_user_events(user_id)
active_dates = set()
for event in user_events:
ts = event.get('timestamp', 0)
if ts:
date = datetime.fromtimestamp(ts / 1000).strftime('%Y-%m-%d')
active_dates.add(date)
# 记录留存
for date in active_dates:
day_diff = (datetime.strptime(date, '%Y-%m-%d') -
datetime.strptime(first_date, '%Y-%m-%d')).days
if 0 <= day_diff <= periods:
cohorts[first_date][day_diff].add(user_id)
# 构建留存矩阵
retention_matrix = []
for cohort_date in sorted(cohorts.keys())[-10:]:
cohort_data = cohorts[cohort_date]
cohort_size = len(cohort_data.get(0, set()))
if cohort_size == 0:
continue
row = {
'cohort_date': cohort_date,
'cohort_size': cohort_size
}
for day in range(periods + 1):
retained = len(cohort_data.get(day, set()))
row[f'day_{day}'] = round(retained / cohort_size, 4)
retention_matrix.append(row)
return {
'cohort_type': cohort_type,
'periods': periods,
'retention_matrix': retention_matrix
}
# 全局实例
event_store = EventStore()
analytics = AnalyticsEngine(event_store)
@app.route('/batch', methods=['POST'])
def receive_events():
"""接收事件数据"""
data = request.get_json()
if not data or 'events' not in data:
return jsonify({'error': 'Invalid payload'}), 400
events = data['events']
event_store.store(events)
return jsonify({'status': 'ok', 'count': len(events)})
@app.route('/api/dau', methods=['GET'])
def get_dau():
"""获取日活用户数"""
date = request.args.get('date', datetime.now().strftime('%Y-%m-%d'))
dau = analytics.calculate_dau(date)
return jsonify({'date': date, 'dau': dau})
@app.route('/api/funnel', methods=['POST'])
def get_funnel():
"""漏斗分析"""
data = request.get_json()
funnel_steps = data.get('steps', [])
start_date = data.get('start_date')
end_date = data.get('end_date')
if not funnel_steps or not start_date or not end_date:
return jsonify({'error': 'Missing required parameters'}), 400
result = analytics.funnel_analysis(funnel_steps, start_date, end_date)
return jsonify(result)
@app.route('/api/retention', methods=['GET'])
def get_retention():
"""留存分析"""
cohort_type = request.args.get('cohort_type', 'daily')
periods = int(request.args.get('periods', 30))
result = analytics.retention_analysis(cohort_type, periods)
return jsonify(result)
@app.route('/api/users/<user_id>', methods=['GET'])
def get_user(user_id):
"""获取用户信息"""
user_data = event_store.users.get(user_id)
if not user_data:
return jsonify({'error': 'User not found'}), 404
return jsonify(user_data)
@app.route('/api/users/<user_id>/events', methods=['GET'])
def get_user_events(user_id):
"""获取用户事件"""
start_time = request.args.get('start_time', type=int)
end_time = request.args.get('end_time', type=int)
events = event_store.get_user_events(user_id, start_time, end_time)
return jsonify({'user_id': user_id, 'events': events, 'count': len(events)})
@app.route('/health', methods=['GET'])
def health():
"""健康检查"""
return jsonify({
'status': 'healthy',
'total_events': len(event_store.events),
'total_users': len(event_store.users),
'total_sessions': len(event_store.sessions)
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000, debug=True)关键词: 用户行为分析、事件埋点、数据仓库、漏斗分析、留存分析、Cohort分析、数据驱动、产品迭代、Python、SQL

在这里插入图片描述
- Eagle, N., & Pentland, A. (2006). Reality Mining: Sensing Complex Social Systems. Personal and Ubiquitous Computing, 10(4), 255-268. ↩︎
- Kumar, A., et al. (2020). Digital Analytics: An Introduction. Journal of Data Science. ↩︎
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号