不只是 mem0:YC CEO 开源了他的 AI 记忆引擎,正则替代 LLM 撑起一张知识图谱
原创
不只是 mem0:YC CEO 开源了他的 AI 记忆引擎,正则替代 LLM 撑起一张知识图谱
原创
术哥
发布于 2026-06-16 21:37:29
发布于 2026-06-16 21:37:29
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 141 篇,AI 星探「2026」系列第 15 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。

GBrain 记忆引擎架构概览
图 1:GBrain 记忆引擎——五大设计决策与核心数据概览
你在给 AI agent 做记忆层的时候,大概率走过这条路:向量数据库 + embedding + top-K 检索。方案跑起来不难,精度数据往往不太好看。
GBrain 的源码里有一组 benchmark 数据很能说明问题:
策略 | P@5 | R@5 |
|---|---|---|
纯 BM25 关键词 | ~18 | ~75 |
纯向量 RAG | ~18 | ~80 |
混合检索 + RRF,无图谱 | ~18 | ~85 |
全栈(默认配置) | 49.1 | 97.9 |
前三行就是大部分 RAG 系统的水平线。P@5 从 18 跳到 49.1,差距全来自第四层:类型化知识图谱。图谱在这里不是装饰品,是承重墙。
我花了几天时间把 GBrain v0.42.44.0 的源码翻了一遍。项目由 Y Combinator CEO Garry Tan 开发并开源(MIT 协议),package.json 里一句 Postgres-native personal knowledge brain with hybrid RAG search 定位得很清楚:给 AI agent 做基于 Postgres 的持久知识大脑。
这篇文章不复述 README 的功能列表,而是从源码出发,拆解这套记忆引擎的五个设计决策,以及每个决策背后的工程取舍。
说明:本文内容基于 GBrain 源码(garrytan/gbrain v0.42.44.0)和官方架构文档分析整理而成,源码分析基于笔者本地仓库版本,尚未在生产环境中完成全场景验证。文中的配置模板和参数建议仅供参考,实际效果请以你的业务数据和环境测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
1. 契约优先:一个接口管住两个引擎
GBrain 底层有两个数据库引擎实现:
- PGLite 引擎(
src/core/pglite-engine.ts):Postgres 17 via WASM,零配置,单进程嵌入式,适合 50K 页以下的个人 brain - Postgres 引擎(
src/core/postgres-engine.ts):原生 Postgres + pgvector,支持 Supabase 和自托管,适合共享或大型部署
两个引擎的桥梁是 BrainEngine 接口(src/core/engine.ts,2145 行)。接口定义了约 47 个操作,从 put_page 到 traverseGraph,两个引擎必须全部覆盖。
这里有个设计细节值得展开。引擎之间不用 instanceof 判断类型,而是在接口上放了一个判别字段:
readonly kind: 'postgres' | 'pglite'这个字段看起来不起眼,但它避开了两个坑。一是 instanceof 在跨模块动态导入时原型链会断裂,判断结果不可靠。二是 TypeScript 的 discriminated union 能在编译期做穷尽性检查 - 如果你加了一个新引擎但忘了处理某个 kind 分支,编译器会报错。
引擎选择通过工厂函数动态导入(src/core/engine-factory.ts),类型签名的核心就是 'pglite' | 'postgres'。CLI 命令和 MCP server 都从同一个 BrainEngine 接口生成。你跑 gbrain init --pglite 和远程 MCP server 调用走的是同一套代码路径,区别只在 kind 字段的值。
想加第三个引擎,实现 47 个操作就行,不需要动 CLI 和 MCP 层。代价也实在 - 47 个操作的 contract 一旦定型,修改波及面很大,两套实现必须同步改。
2. 零 LLM 知识图谱:正则和动词怎么撑起一张图
大部分知识图谱系统靠 LLM 抽取实体关系。GBrain 不一样:它的知识图谱靠正则表达式 + 上下文动词匹配构建,所有函数都是纯函数,零 LLM 调用。核心逻辑在 src/core/link-extraction.ts(1229 行)。
4 pass 提取链
extractEntityRefs(content) 函数按严格优先级顺序执行 4 个 pass,从 Markdown 文本里提取实体引用。
Pass 1 - Markdown 链接,匹配常见的 [Name](dir/slug) 格式:
ENTITY_REF_RE = /\[([^\]]+)\]\((?:\.\.\/)*(DIR_PATTERN\/[^)\s]+?)(?:\.md)?\)/g同时支持文件系统相对路径(../people/alice.md)和引擎 slug 格式(people/alice)。
Pass 2a - 限定 wikilink(v0.17+),匹配带 source 前缀的跨源引用:
QUALIFIED_WIKILINK_RE = /\[\[([source-id]):(DIR_PATTERN\/...)\]\]/g比如 [[wiki:topics/ai]],source 前缀锁定引用来源。
Pass 2b/2c - 非限定和通用 wikilink,匹配 Obsidian 风格的 [[people/alice|Alice]] 和裸名 [[bare-name]]。裸名 wikilink 标记 needsResolution: true,交给 SlugResolver 在后续阶段解析。
这里有个关键防护值得注意。DIR_PATTERN 是一个白名单正则,只允许 people|companies|meetings|concepts|deal|civic|project 等目录前缀。不在白名单里的路径不会被识别为实体引用。另外 stripCodeBlocks() 会在提取前移除代码块和行内代码,防止代码里的字符串被误匹配为 slug。maskRanges() 做范围遮蔽,防止同一个文本片段被多个 pass 重复匹配。
边的类型从哪来
光提取出引用还不够。GBrain 需要知道每条边是什么类型:works_at、founded、invested_in 还是 advises。
inferLinkType 函数(link-extraction.ts:694)的做法是上下文动词正则匹配,同样零 LLM:
function inferLinkType(pageType, context, globalContext?, targetSlug?): string {
// 页面类型直接映射
if (pageType === 'meeting') return 'attended';
// 上下文动词模式匹配(优先级:founded > invested > advises > works_at)
if (FOUNDED_RE.test(context)) return 'founded';
if (INVESTED_RE.test(context)) return 'invested_in';
if (ADVISES_RE.test(context)) return 'advises';
if (WORKS_AT_RE.test(context)) return 'works_at';
// 页面角色先验(仅 person → company)
if (pageType === 'person' && targetSlug?.startsWith('companies/')) {
if (PARTNER_ROLE_RE.test(globalContext)) return 'invested_in';
if (ADVISOR_ROLE_RE.test(globalContext)) return 'advises';
if (EMPLOYEE_ROLE_RE.test(globalContext)) return 'works_at';
}
return 'mentions';
}动词正则的覆盖面比想象中宽。以 WORKS_AT_RE 为例(源码 627-659 行),它匹配 60 多种工作关系表达:CEO of、works at、engineer at、VP at、stint at、tenure at。INVESTED_RE 覆盖 invested in、led the seed、early investor、portfolio company、board seat at。FOUNDED_RE 覆盖 founded、co-founded、founder of、is a co-founder。
匹配优先级是硬编码的:founded > invested > advises > works_at。如果上下文同时出现 founded 和 works at,边会被判定为 founded。这个优先级对于 VC/创业生态数据(GBrain 的主要场景)覆盖了大部分情况。兜底类型是 mentions - 所有动词正则都不匹配时的默认值。
Frontmatter 也能派生边
除了正文里的链接,YAML frontmatter 字段也能直接映射到类型化边(link-extraction.ts:777):
页面类型 | Frontmatter 字段 | 边类型 | 方向 |
|---|---|---|---|
person | company/companies | works_at | outgoing |
person | founded | founded | outgoing |
company | key_people | works_at | incoming |
deal | investors | invested_in | incoming |
meeting | attendees | attended | incoming |
incoming 这个方向设计得比较巧妙。以 key_people: [Pedro] 写在 company/stripe 上为例,它产生的边是 people/pedro → companies/stripe (works_at),而不是反过来。道理很简单:key_people 描述的是谁在这家公司工作,所以边的源端是人,目标端是公司。
批量写入绕过参数上限
每次 put_page 操作的 auto-link post-hook 通过 addLinksBatch 批量写入边:
INSERT ... SELECT FROM jsonb_to_recordset(($1::jsonb)->'rows')
JOIN pages ON CONFLICT DO NOTHING RETURNING 1用 JSONB 文档批量绑定有两个原因。一是绕过 Postgres 的 65535 参数上限:一次写入几百条边时,逐条参数绑定会撑爆限制。二是解决 array literal 在特定上下文崩溃的问题(issue #1861 中 unnest 在日历/Zoom 上下文上会 crash)。
零 LLM 的代价是什么?覆盖率。正则只能覆盖预定义的动词模式和目录结构。如果有人写了一段复杂的关系描述,没用到任何预设动词,这条边就会退化成 mentions。换来的好处是每次写页自动触发、近零成本、不花 token。README 里提到 17K 页的 brain,全图提取秒级完成。
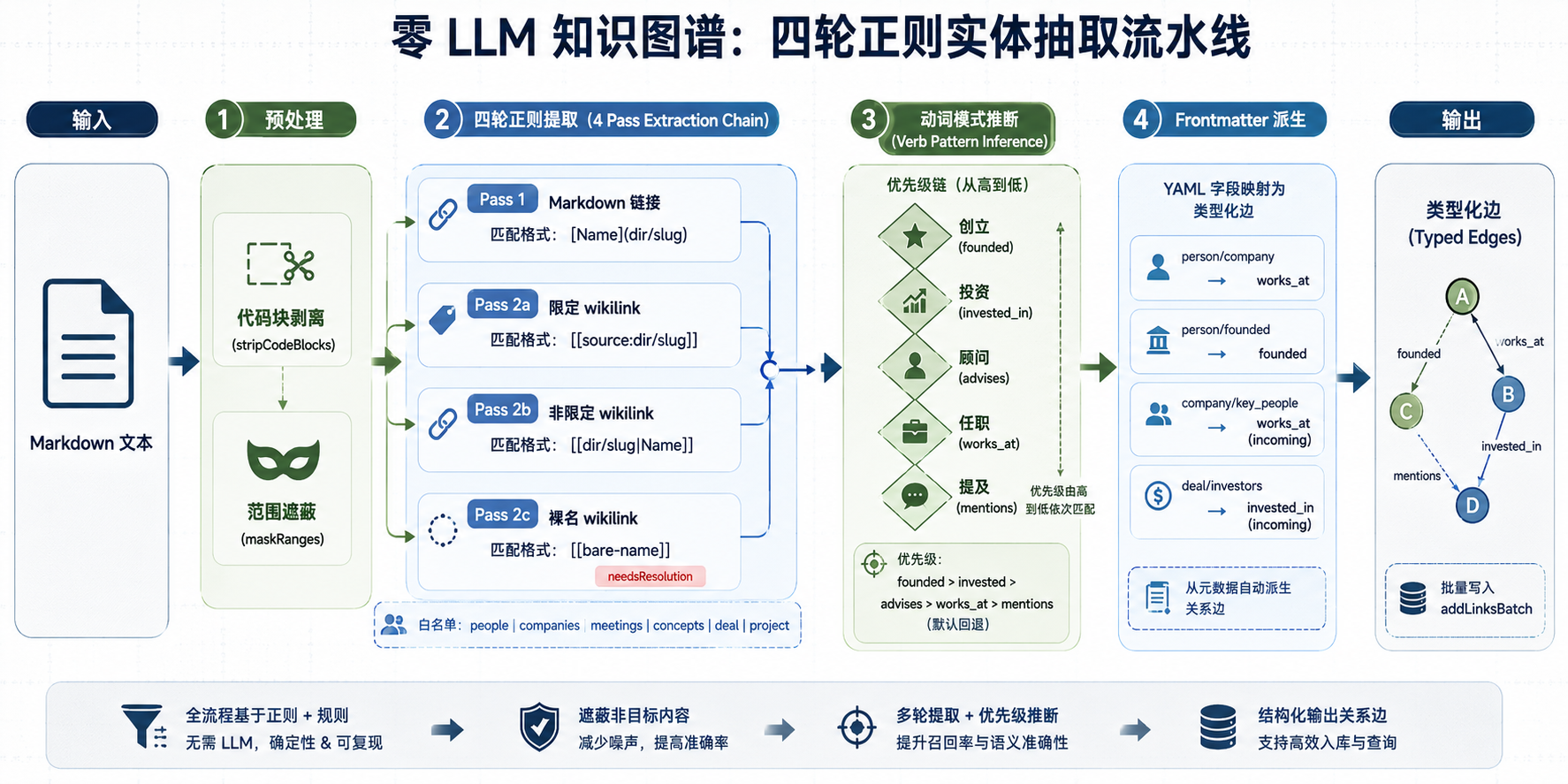
零 LLM 知识图谱 4 pass 提取流程
图 2:从 Markdown 文本到类型化边的 4 pass 正则提取链
3. 四层检索为什么不能少一层
GBrain 的混合检索管线在 src/core/search/hybrid.ts(1968 行)。完整流程是这样的:
intent classify(意图分类)
↓
expansion(查询扩展,可选)
↓
hybrid search(混合搜索)
├── vector(HNSW 向量检索)
├── keyword(BM25 关键词检索)
├── relational(类型化边召回)
├── source-aware re-rank(源权重重排)
└── RRF fusion → top 30
↓
graph augment(类型化边遍历扩展)
↓
reranker(zerank-2 cross-encoder 重排)
↓
token-budget enforcement(按模式预算截断)
↓
deduplication(同 slug 去重,保留得分靠前的 chunk)
↓
results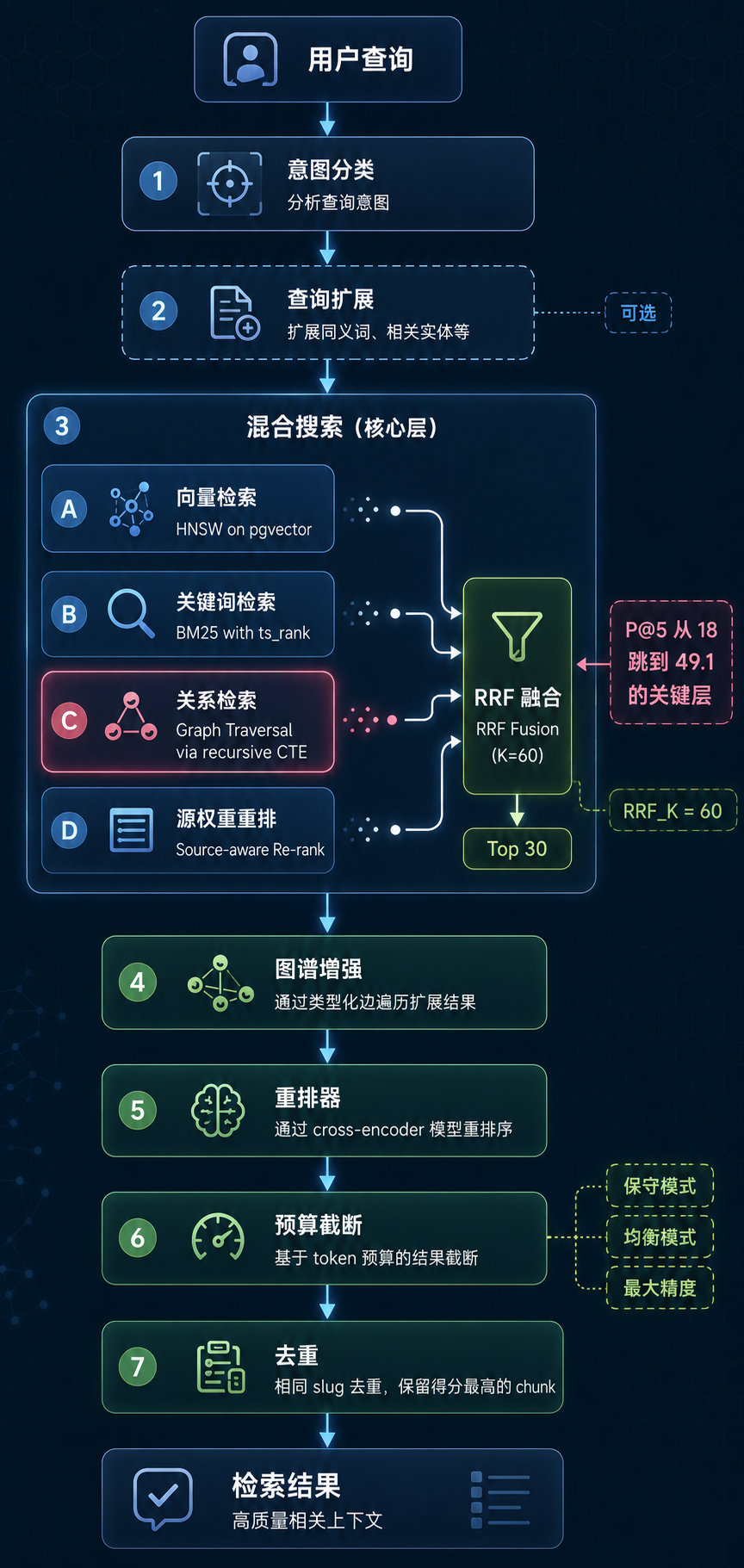
混合检索管线全流程
图 3:8 阶段混合检索管线架构图——关系层是 P@5 从 18 跳到 49.1 的关键
每层解决什么问题
向量层(HNSW on pgvector) 捕捉语义相似。你搜 创业公司融资,它能匹配到写 startup raised Series A 的页面,即使没有一个词重叠。实现上用两阶段 CTE:内层 HNSW ORDER BY 保持索引可用,外层做 source-boost 重排。
BM25 关键词层 捕捉词法精确匹配。向量检索在专有名词上经常翻车:Alice Chen 和 Bob Chen 的 embedding 可能很接近,但它们是不同的人。BM25 用 ts_rank 乘以 source-factor CASE 来兜底。
关系层(类型化边召回) 是真正拉开差距的地方。traverseGraph(slug, depth, opts) 用递归 CTE 做 BFS 遍历。搜一个投资人时,关系层沿着 invested_in 边找到他投过的公司,再沿着 works_at 边找到这些公司的创始人。这种多跳推理是向量和关键词检索都做不到的。
RRF 融合(RRF_K = 60)把三个策略的排名投票合并。RRF 不关心原始分数,只关心排名位置,所以天然解决了不同打分尺度的归一化问题。
几个硬编码加权常量
源码里有几个常量影响着排序结果:
COMPILED_TRUTH_BOOST = 2.0; // 正文 chunk 在 RRF 后 2x 加权
BACKLINK_BOOST_COEF = 0.05; // 反向链接对数加权
ADJACENCY_BOOST = 1.05; // 被多个 top-K 结果链接(局部 hub)
CROSS_SOURCE_BOOST = 1.10; // 被多个 source 链接(跨脑验证)
SESSION_DEMOTE = 0.95; // 同一会话多个结果降权CROSS_SOURCE_BOOST 的设计逻辑值得一提。如果一个实体被多个不同 source 引用,权重会被提升。跨 source 的引用相当于交叉验证:多个独立来源都提到的东西,更可能是重要实体。
Per-page max-pool 机制(文档记录在 RETRIEVAL_MAXPOOL_INCIDENT.md)解决 chunk 级膨胀:同一页面切成多个 chunk 后,searchVector 在用户 LIMIT 之前用 DISTINCT ON (slug) 把 chunk 级候选折叠为每页得分靠前的那个 chunk,防止一个长页面占满结果集。
另外,每个结果携带 evidence 标签(alias_hit、exact_title_match、high_vector_match、keyword_exact、weak_semantic)和 create_safety 标签(exists、probable、unknown)。这两个标签让下游消费者知道每条结果的可信度,而不只是一个分数。
Benchmark 数据说明了什么
回看开头的数据。前三行(纯 BM25 / 纯向量 / 混合无图谱)的 P@5 都在 18 左右,互相差距不大。加上图谱层后直接跳到 49.1。+31 的提升不是来自某个单一优化,而是图谱 + 提取质量 + source-aware ranking 的综合效果。
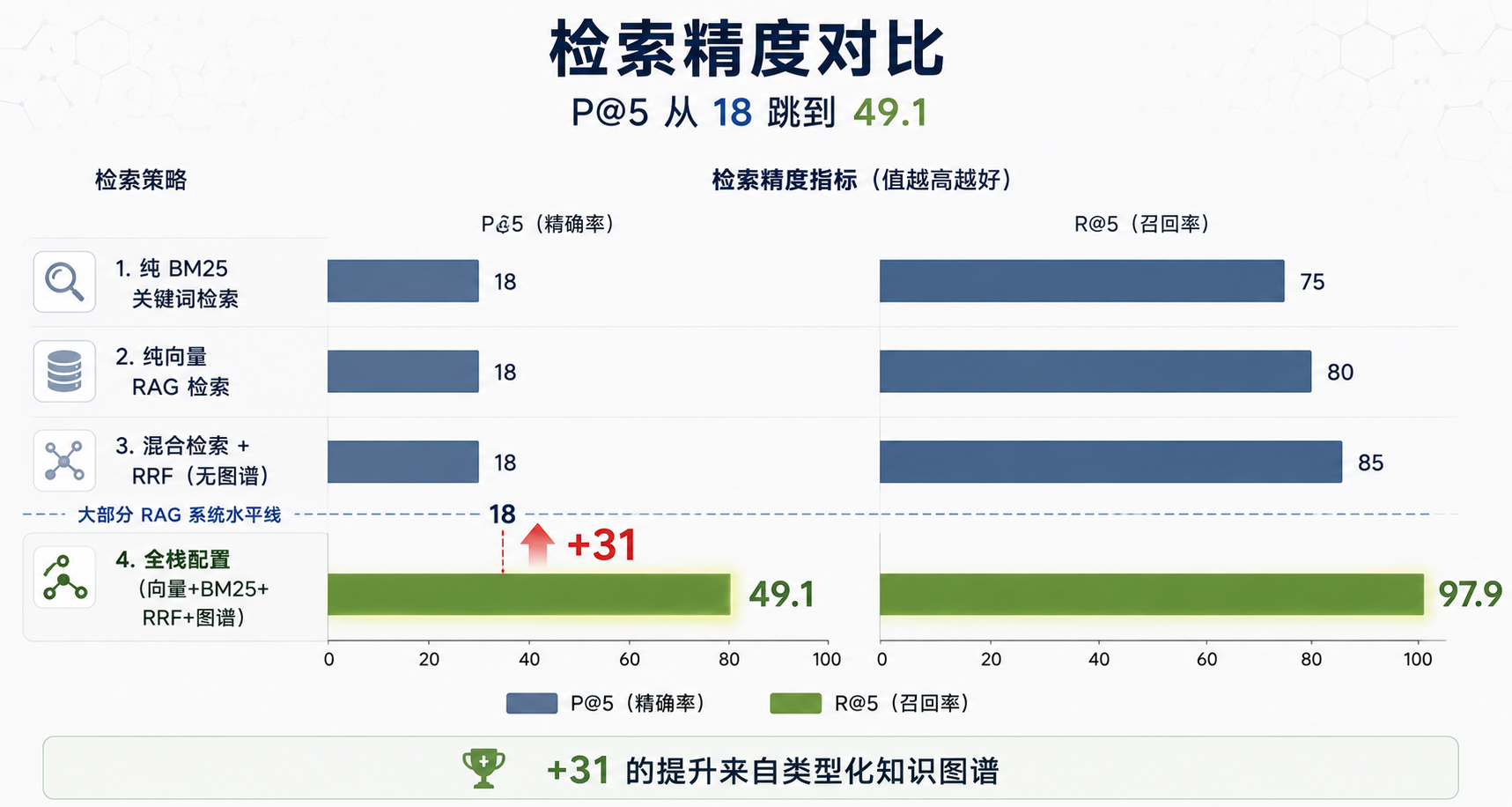
四种检索策略的 P@5/R@5 性能对比
图 4:前三行平台效应 vs 全栈突破——P@5 从 18 跳到 49.1
但也要注意 benchmark 的边界。这组数据来自 GBrain 自己的数据集(VC/创业生态),换到其他领域(比如医疗病历或法律文书),动词正则的覆盖率可能会下降,图谱密度也会不同。GBrain 的方案是在特定数据分布下工程上合理的解法,不是通用解。
三种搜索模式给了不同精度/延迟的折中选择:conservative(无 reranker,无 expansion,无 graph signals)延迟更低;balanced(reranker + graph signals 开,默认)精度和速度均衡;tokenmax(reranker + expansion + per-chunk synopsis)精度更高但延迟也更大。
你在项目里用的是哪种检索方案?纯向量、纯关键词、还是混合?评论区聊聊效果差异。
4. Brain ⊥ Source:两个正交的组织维度
大多数知识库系统只有一个组织维度:要么按数据库分,要么按 namespace 分。GBrain 用了两个正交维度。
Brain(数据库轴):一个 brain 等于一个物理数据库(PGLite 文件 / Postgres 实例 / Supabase 项目)。通过 --brain <id> 参数或 .gbrain-mount dotfile 路由。
Source(仓库轴):一个 brain 内的命名内容仓库。每个 pages 行携带 source_id。
关键设计决策:slug 在 source 范围内不重复,而非全局不重复。这意味着 people/alice 可以同时存在于 work source 和 personal source 中,两条记录互不冲突。
换来的好处是多源联邦查询时不需要 namespace 前缀拼接,每个 source 内部的 slug 是自洽的。代价是跨 source 引用需要显式声明 source 前缀 - 这就是 Pass 2a 限定 wikilink [[wiki:topics/ai]] 存在的原因。
Brain 和 Source 各自有 6 层解析链:
Brain: --brain <id> → GBRAIN_BRAIN_ID → .gbrain-mount → mount path match → fallback 'host'
Source: --source <id> → GBRAIN_SOURCE → .gbrain-source → source path match → fallback 'default'解析链的思路是渐进增强:命令行参数优先于环境变量,环境变量优先于 dotfile,dotfile 优先于路径匹配,末尾兜底 fallback 到默认值。每层都可以缺失,系统总能找到一个合理的默认值。
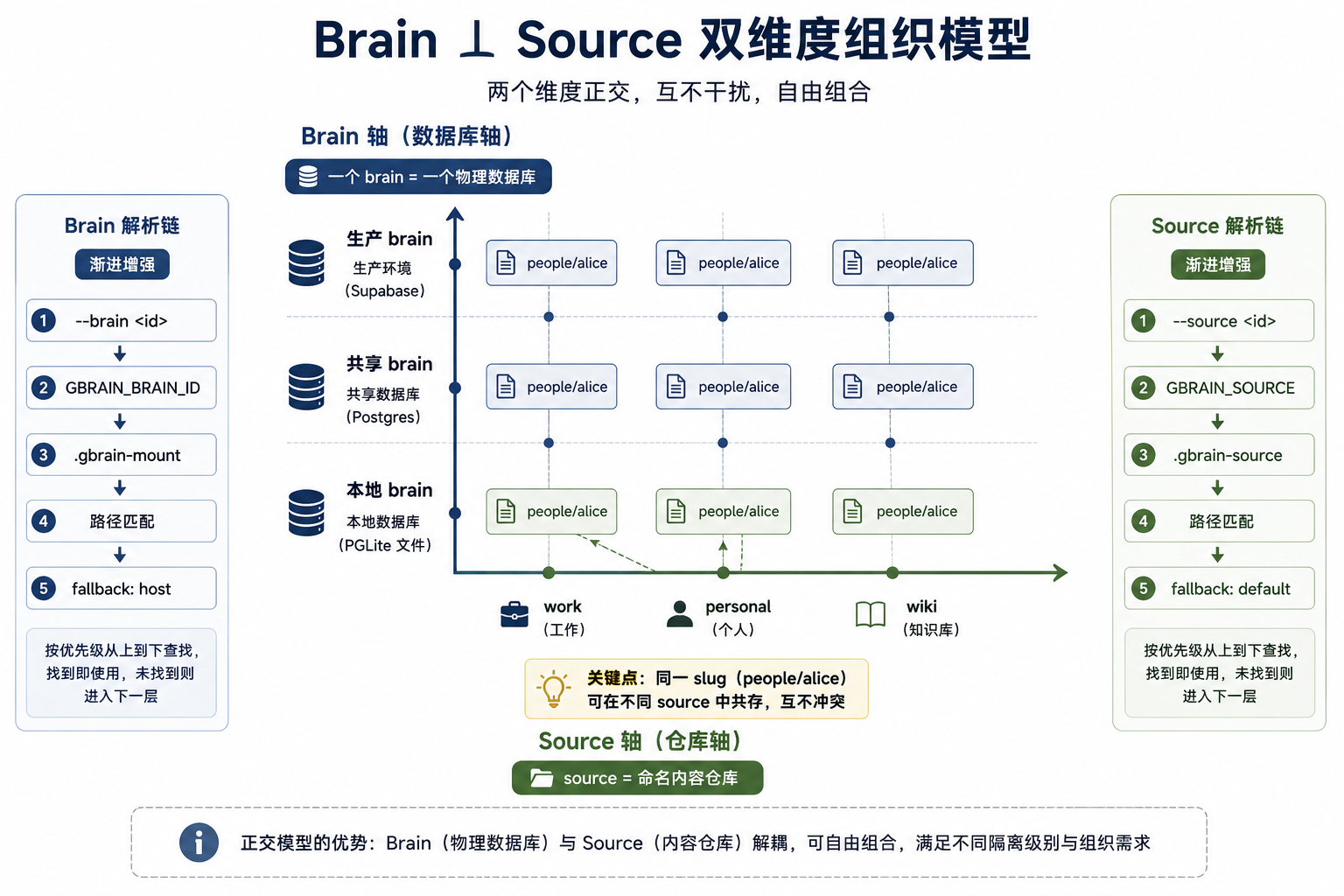
Brain ⊥ Source 双维度正交组织模型
图 5:数据库轴 × 仓库轴的正交组织模型与 6 层渐进增强解析链
数据模型层面,核心实体 Page(src/core/types.ts,1550 行)有几种模态。page_kind 字段支持 markdown、code、image 三种内容类型。PageType 在 v0.38 从闭合 union 改为开放 string,gbrain-base 种子类型含 person、company、deal、meeting、concept 等 26+ 种,Schema Pack 可扩展。软删除用 deleted_at 字段,72 小时后硬删除。
5. 不性感但关键的工程可靠性设计
源码里有一批工程设计,不直接面向用户,但决定了系统能不能在生产环境跑起来。GBrain 的 README 声称生产环境跑了 146,646 pages、24,585 people、5,339 companies、66 个 cron jobs 自主运行。
batchRetry 自愈
src/core/retry.ts 实现了批量写入的重试逻辑。批量操作(addLinksBatch、addTimelineEntriesBatch、upsertChunks)在连接池抖动时会自动重试。默认 3 次重试,使用 decorrelated jitter(去相关抖动)计算退避时间。
decorrelated jitter 比固定退避好在哪?固定退避(比如每次等 1 秒)会导致 thundering herd:所有失败的请求在同一时刻重试,把刚恢复的服务器再次打挂。jitter 通过加入随机性,让重试请求分散到不同时间点。
background-work registry
src/core/background-work.ts 解决的问题是:CLI 进程退出前必须 drain 所有 fire-and-forget 写入。
GBrain 有 5 个后台写入 sink,按顺序注册:
- facts/queue(order 0)
- last-retrieved(order 1)
- search/hybrid cache(order 2)
- eval-capture(order 3)
- volunteer-events(order 4)
通过 finishCliTeardown 统一入口,按 order 依次 drain。如果不做这一步,CLI 退出时未完成的异步写入会丢失:用户执行了 gbrain put,看到成功提示,但数据实际上没写进去。
信任边界 fail-closed
src/core/operations.ts 里有一个 ctx.remote 字段,决定当前调用是否来自远程。
信任边界的语义是 fail-closed(默认拒绝):ctx.remote === false 才是可信本地调用。任何无法确认为本地的调用,都按远程处理,受到 OAuth scope 门控。
这个设计防止了一个攻击面:如果 OAuth token 泄露,攻击者通过 HTTP MCP server 发起的请求会被当作远程调用,write 和 admin scope 的操作会被拒绝。源码中 4 个信任边界调用点全部是 fail-closed 语义 - 宁可拒绝合法请求,也不放过一个可疑调用。
PGLite advisory lock
PGLite 是单进程嵌入式数据库,多进程同时写入会导致 WAL 损坏。src/core/pglite-lock.ts 实现了 advisory lock:用 PID liveness check + heartbeat 两个信号防止两种情况。一是两个进程同时写入导致 WAL 损坏,二是进程崩溃后 PID 被操作系统复用导致误判(以为旧进程还活着,新进程拿不到锁)。
总结
翻完 GBrain 的源码,有几个设计决策让我印象比较深。
零 LLM 知识图谱是核心差异化。用正则 + 动词启发式替代 LLM 抽取,代价是覆盖率受限于预定义模式,收益是每次写页自动触发、近零成本、不花 token。这个取舍在 VC/创业生态的数据分布下合理,换到其他领域需要重新评估动词正则的覆盖面。
混合检索的分层策略解释了 P@5 为什么能从 18 跳到 49.1。前三层(向量 + BM25 + RRF)负责召回,精度提升来自关系层和 source-aware ranking。图谱不是 RAG 的附属功能,在这套架构里是承重墙。
契约优先的双引擎设计让 PGLite 和 Postgres 共存。判别字段 kind 看着简单,但避开了 instanceof 跨模块失效的经典坑。
源码也诚实标注了当前的局限:PGLite 单写者限制导致大规模 sync 需要停 serve;frontmatter tag 没有 provenance 列导致 reindex 只能 add-only(不能安全删除);图遍历的 truncation 检测存在 false positive/negative,方案已推迟处理。这些标注比 README 里的功能列表更有参考价值 - 它们告诉你这套方案的边界在哪。
另外,GBrain 在 search 之上做了一层 think 命令。gbrain search 返回原始页面(和普通 RAG 一样),gbrain think 在检索之上做综合答案 + 显式引用 + 缺口分析(gap analysis):诚实标注 brain 不知道什么,包括页面过期、声明无引用、两页矛盾、知识空洞。这是搜索引擎和大脑的区别 - 搜索找页面,大脑读页面并写出答案,同时承认自己不知道什么。
如果你也在做 AI agent 的记忆层,GBrain 的源码值得花时间读一读。它把零 LLM 图谱 + 混合检索这条路走到了工程可用的程度,benchmark 数据和源码结构都经得起推敲。
关于 AI agent 的记忆架构,你觉得纯向量 RAG 够用,还是需要图谱层加持?欢迎在评论区聊聊你的判断。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号