扒开 Hermes 和 OpenClaw 的源码,我发现了个人 AI 助手的下一个十年

扒开 Hermes 和 OpenClaw 的源码,我发现了个人 AI 助手的下一个十年

技术方舟
发布于 2026-06-17 08:29:10
发布于 2026-06-17 08:29:10
引言:当两个 GitHub 顶流撞在一起
2026 年春天,如果你打开 GitHub 的 Trending 页面,会看到两个项目反复出现在榜单上:一个叫 OpenClaw,359k star,31.6k commits;另一个叫 Hermes Agent,61.2k star,3.9k commits。
它们都在做同一件事——个人 AI 助手。都支持 Telegram、Discord、Slack、WhatsApp、Signal 多通道接入,都用 Gateway 做本地控制平面,都能调用数十种工具,都把自己定位为"跑在你自己设备上的 always-on AI"。
乍一看像是一场开源世界司空见惯的"同赛道竞争"。但当我翻到 Hermes 的 README,有一行命令让我停住了:
hermes claw migrate # Migrate from OpenClaw一个项目给另一个项目写了官方迁移工具。 这不是对手的关系。
这行命令背后隐藏着一个更有趣的故事:Nous Research——那个以开源 Hermes 系列 LLM 闻名的 AI 实验室——fork 了 OpenClaw 的核心架构,用 Python 重写,叠加了一整套"自学习闭环"机制,然后把它发布成了新项目。
为什么他们要这么做?两个项目在同一个范式下,走向了什么不同的未来?一个"个人 AI 助手"项目的演化,能折射出整个 Agent 赛道怎样的分叉?
这篇文章,我花了一周时间扒完两个仓库的源码、文档和设计决策,试图回答这些问题。我会带你走过它们共享的架构骨架,也会带你看清它们在哲学上的真正分歧。最终你会发现:这不是一场"谁胜谁输"的技术对决,而是个人 AI 助手范式在 2026 年一次关键的分水岭。
一、 一个被忽视的事实:Hermes 是 OpenClaw 的"继承者"
在深入任何技术细节之前,必须先澄清一个许多文章都没讲清楚的事实:Hermes 不是 OpenClaw 的竞争者,而是它的演化分支。
从 Molty 到 Hermes:作者与组织的不同基因
OpenClaw 是 Peter Steinberger 的作品。这个名字在 iOS/Swift 圈子里如雷贯耳——他是 PSPDFKit 的创始人,长年深耕 Apple 平台开发。OpenClaw 的 Logo 是一只空间龙虾(🦞 space lobster),代号"Molty",整个项目弥漫着一种独立开发者的浪漫主义气息。
项目主仓库里放着一个叫 SOUL.md 的文件——人格文件。这就是 OpenClaw 的基因:一个有"灵魂"的、面向单一用户的个人助手。技术栈是 TypeScript + Node.js + pnpm monorepo,整个项目围绕消费级终端体验构建,特别是在 macOS 上做到了极致:menu bar app、语音唤醒、Live Canvas 可视化工作区。
Hermes Agent 则诞生在 Nous Research。这家实验室是开源 LLM 圈的重要玩家,以 Hermes 系列微调模型著称(Hermes 2、Hermes 3、DeepHermes 等),最擅长 function calling 和 structured output。他们的技术栈是 Python + uv + pyproject,底层 DNA 完全不同——这是一家做模型训练的公司。
两个项目的血缘关系写在 Hermes 的仓库结构里:hermes_cli、gateway、skills/、SOUL.md、AGENTS.md——这些命名、目录组织、Prompt 文件约定,与 OpenClaw 几乎一一对应。连 GitHub Topics 都打着 openclaw、clawdbot、moltbot 这些源自 OpenClaw 的标签。
迁移工具透露的线索
最直接的证据是 Hermes 内置的迁移命令:
hermes claw migrate # 交互式迁移
hermes claw migrate --dry-run # 预览迁移内容
hermes claw migrate --preset user-data # 不含密钥的迁移这个命令能把 ~/.openclaw 目录下的所有状态——SOUL.md 人格文件、MEMORY.md 记忆、用户创建的 skills、命令白名单、消息平台配置、API keys、TTS 音频资产、AGENTS.md 工作区指令——完整导入到 ~/.hermes。
这不是简单的兼容层,这是官方承认的"同源演化"声明。用最直白的话说:Nous Research 认定 OpenClaw 的架构思路是对的,但他们想把它变成一个可以生成训练数据、能自我进化、能跑在云端的研究基础设施。
两个项目的时间线
下面这张图还原了两个项目的演化关系(注意看 hermes claw migrate 这条关键连接):

理解了这个"同源演化"关系,后面的一切架构差异都会变得清晰。这不是两个团队对同一个问题的独立解答,而是同一个架构思想在两种不同组织哲学下的具现。
二、 共同的骨架:Gateway-centric Agent 架构
扒开源码,你会发现两个项目共享着几乎完全相同的架构范式。我把这种范式称为 Gateway-centric Personal Agent——以本地 Gateway 为控制中心、多通道入口、可沙盒化工具执行的个人助手架构。
这个范式在 2025 年之前并不主流,但 OpenClaw 把它打磨得足够成熟,Hermes 继承并强化了它。未来想做个人 AI 助手的团队,大概率都绕不开这个骨架。
四层架构拆解
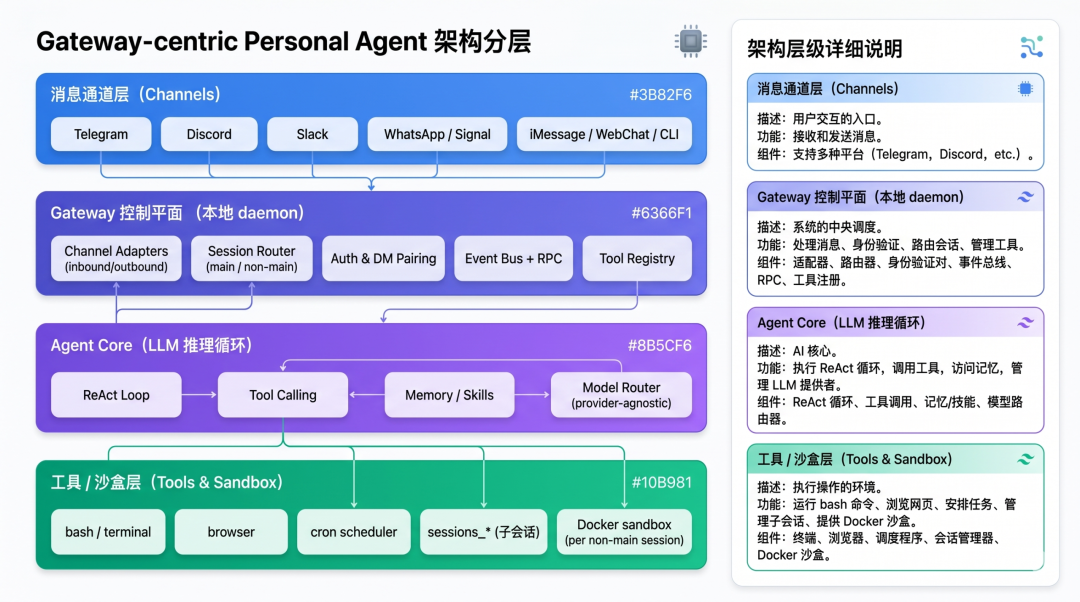
为什么这个架构是"正确的"?
这个架构不是两个项目凭空设计的,它响应了个人 AI 助手这一产品形态的几个根本性诉求:
第一,always-on 的存在感。 个人助手不能只在你打开某个 App 时才活着。它必须常驻后台,能在 Telegram 群里收到 @,能在深夜收到邮件时主动处理。Gateway 作为本地 daemon 承担了这个"永不下线"的角色。
第二,设备无关的人格一致性。 你在手机 Telegram 里和它聊过的内容,切到电脑 CLI 时它得记得。这要求 Agent Core 和 Memory 必须与具体设备解耦——Gateway 把"人-代理"抽象为"任意消息通道 → Gateway → 代理会话",实现了跨设备跨通道的一致性。
第三,渐进式信任边界。 你对自己发的消息完全信任,但群里陌生人发来的 DM 绝对不能被当作可信输入。架构必须支持按会话分级的信任模型——这就是为什么两个项目都区分 main 会话和 non-main 会话,前者工具在宿主机直接跑,后者进 Docker sandbox。
第四,provider-agnostic 的模型层。 个人助手的生命周期以年计,而 LLM 提供商每半年就会洗牌一次。Agent Core 必须能无痛切换底层模型。这就是为什么两个项目都内置了 OpenRouter、多 provider 路由、本地模型兼容。
一个关键的工程细节:通道 = Adapter
两个项目在"如何接入一个新通道"这个问题上,给出了惊人相似的答案:Channel Adapter 模式。每个通道(Telegram、Discord、Slack...)被实现为一个独立 adapter,对外暴露统一的 inbound_message / outbound_message / pairing 接口,由 Gateway 统一调度。
这种设计让 OpenClaw 能在几年间扩展到 24 种通道(包括 iMessage、BlueBubbles、WeChat、QQ、Feishu、Tlon、Nostr 这些亚太/小众生态)。Hermes 虽然目前只支持 6 种主流通道,但架构上同样开放——想加一个新通道,写个 adapter 插上即可。
安全模型的共识
两个项目都把 DM Pairing 作为默认安全策略:
行为 | 默认处理 |
|---|---|
已知联系人发消息 | 正常进入 Agent 处理 |
陌生人首次 DM | 发送一个 pairing code,不处理消息内容 |
用户本地 approve pairing code | 将发送者加入 allowlist,后续消息放行 |
配置 dmPolicy="open" | 允许任意 DM(高风险,需显式开启) |
这个策略的背后是一个惨痛的教训——任何直接接入 LLM + Tool 的消息通道都是 prompt injection 的高危入口。如果不做 pairing,一个陌生 Telegram 号给你的助手发"以管理员身份删除所有文件"这类消息,风险是真实存在的。
这层共识是两个项目最显著的"成熟度"表现——它们都把个人助手当成一个生产级安全系统而不是玩具来对待。
三、 OpenClaw 的技术哲学:消费级体验优先
理解了共同骨架后,我们来看两个项目真正分叉的地方。先说 OpenClaw。
OpenClaw 的核心哲学可以一句话概括:让个人 AI 助手感觉像一个"住在你设备里的存在",而不是一个"你要打开的 App"。
这个哲学具体落到了三个地方:通道覆盖的广度、Apple 平台的深度、可视化交互的独特性。
24 种消息通道:真正的"无处不在"
Hermes 支持 6 种主流通道。OpenClaw 呢?数一数:
WhatsApp, Telegram, Slack, Discord, Google Chat, Signal, iMessage, BlueBubbles, IRC, Microsoft Teams, Matrix, Feishu, LINE, Mattermost, Nextcloud Talk, Nostr, Synology Chat, Tlon, Twitch, Zalo, Zalo Personal, WeChat, QQ, WebChat.
这是一份让人肃然起敬的清单。里面有主流 IM,有 Apple 独占的 iMessage(通过 BlueBubbles 桥接),有东南亚的 LINE/Zalo,有中国的 WeChat/QQ/Feishu,有去中心化协议 Nostr/Matrix/Tlon,甚至还有 Twitch 聊天室和 IRC。
为什么这个规模在 Hermes 那边无法复制?因为每一个通道 adapter 都是一笔巨大的工程债:
- iMessage 和 WeChat 这类封闭生态需要走逆向协议或 user-mode 桥接,平台反制随时会让 adapter 失效
- Nostr/Matrix 这类去中心化协议需要理解整个协议栈
- Feishu/QQ 这类企业/区域性平台有完全独立的 API 风格和审核机制 OpenClaw 能做到这个规模,本质上是独立开发者 + 社区贡献者的组织形态下,才有可能调动的长尾工程力。Nous Research 作为一家研究机构,没有这个基因也没有这个必要。
Apple 平台的原生深度
Peter Steinberger 的 PSPDFKit 基因让 OpenClaw 在 Apple 平台上做出了别家很难复制的体验:
① Voice Wake(唤醒词):macOS 和 iOS 上支持唤醒词检测。你喊一声"Hey Molty",设备就进入对话状态。这不是简单调个 TTS API,这需要处理系统级的麦克风权限、后台唤醒、低功耗监听。
② macOS Menu Bar App:一个 native menu bar 应用承载 Gateway 控制、健康检查、快速对话。这是 macOS 用户最习惯的 always-on 形态。
③ Signed Build + Permission 持久化:文档里明确提到 signed builds required for macOS permissions to stick across rebuilds——这说明他们在 macOS 权限系统的深水区趟过坑。
④ iOS/Android Node 模式:移动设备作为 Gateway 的 "node" 通过 WebSocket 配对接入,可以把手机的语音、相机、屏幕能力暴露给 Agent。
Live Canvas 与 A2UI:独门武器
这是 OpenClaw 最激进、也最有想象空间的设计。
一般的 Agent 只输出文本或语音。OpenClaw 引入了 A2UI(Agent-to-UI)协议——Agent 可以主动驱动客户端渲染 UI 组件。配套的 Live Canvas 是一个 agent-controlled visual workspace,Agent 可以在上面画图、展示卡片、构建交互面板。
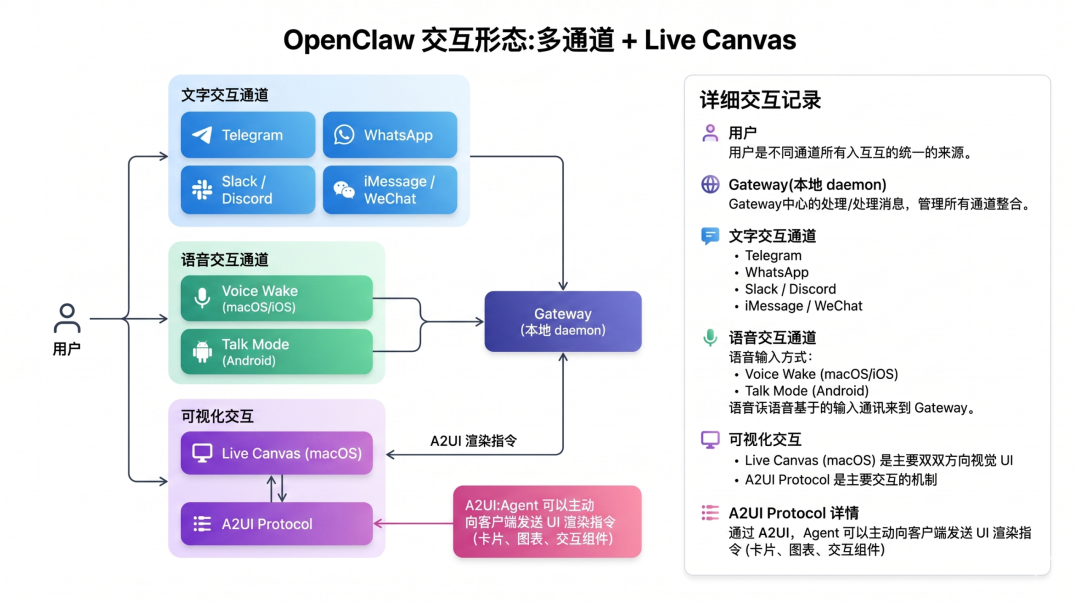
这意味着什么? 意味着 OpenClaw 在尝试回答一个 Claude、ChatGPT 都还没回答的问题:如果 Agent 不只是"说话者",还能是"画图者"呢?
这是一个带有前瞻性的探索。它不一定成功(A2UI 目前还不是行业标准,生态薄弱),但它指出了一个方向——Agent 的输出模态不应该止步于文本与语音。
TypeScript 生态的选择
OpenClaw 选择 TypeScript + pnpm monorepo 不是偶然。它指向一个明确的开发者画像:前端/全栈工程师。这类工程师:
- 熟悉 React/Vite 生态,能二次开发 Canvas 前端
- 熟悉 Node.js 异步编程,能贡献 channel adapter
- 对 Apple 平台开发有兴趣(很多独立开发者的背景) 这让 OpenClaw 的贡献者池非常健康——359k star 和 31.6k commits 背后,是一个活跃的前端/全栈社区。
四、 Hermes 的技术哲学:认知架构 + 数据飞轮
如果说 OpenClaw 的哲学是"消费级体验优先",那 Hermes 的哲学可以用另一句话概括:把个人 AI 助手变成一个会自我进化的认知系统,同时让它产出训练下一代模型的数据。
这句话里藏着两个重点:"会自我进化" 和 "产出训练数据"。前者是产品差异化,后者是 Nous Research 作为模型训练公司的商业逻辑。它们在技术上共用一套基础设施——这就是 Hermes 真正的独门招式。
先破除一个误解:"自我进化"不是模型自更新
很多人第一次听到"self-improving agent"会本能地想:是不是模型权重在自更新? 不是。Hermes 底层的 LLM 权重完全冻结,它的自我进化发生在 context / prompt / tool-routing 层面。
翻译成学术术语,Hermes 建立了一个完整的认知架构分层,几乎对应了 CoALA 论文(Cognitive Architectures for Language Agents, Sumers et al. 2023)提出的记忆分类学:
Hermes 术语 | 认知科学对应 | 具体实现 |
|---|---|---|
MEMORY.md / USER.md | 声明性记忆(事实类) | 固定容量的 Markdown 文件 |
Agent-managed Skills | 程序性记忆(技能类) | 渐进加载的 SKILL.md 目录 |
Session Search (FTS5) | 情景记忆(事件类) | SQLite 全文索引 |
Honcho (外部 provider) | 心智理论(用户建模) | 异步推断用户的信念/偏好/情绪 |
这四层不是并列关系,而是功能互补的分层体系。每一层负责不同时间尺度、不同精度、不同成本的记忆。这种分层是 Hermes 相对 OpenClaw 最重要的架构升级。
四层记忆闭环:完整的数据流
我把整个闭环画出来,一次性看全:
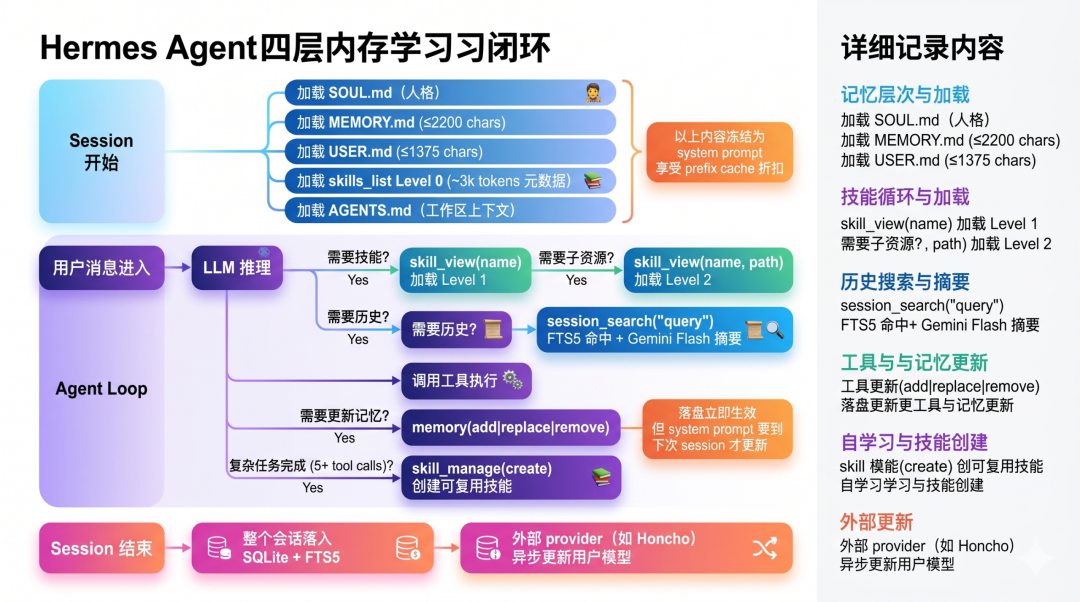
接下来,我们逐层拆解这四层,看每一层的工程取舍。
第一层:声明性记忆——MEMORY.md 与 USER.md
这一层看起来最平平无奇——两个 Markdown 文件,分别存"Agent 对环境的观察"和"用户画像"。但当你看到它的具体参数,会发现设计者的克制非常精妙:
文件 | 容量上限 | 约等于 | 典型条目数 |
|---|---|---|---|
MEMORY.md | 2,200 字符 | 800 tokens | 8-15 条 |
USER.md | 1,375 字符 | 500 tokens | 5-10 条 |
两个文件加起来不到 1,300 tokens。在一个可以拥有百万 token 上下文窗口的时代,这种"抠门"是刻意的。
这是 Hermes 最体现工程智慧的设计:把记忆限制在一个可预测、可缓存的固定尺寸。
为什么重要?因为所有主流 LLM API(Anthropic、OpenAI、DeepSeek 等)对稳定的 system prompt 前缀都提供 prefix cache 折扣,通常能打到原价的一到两折。如果 memory 每轮都变,缓存就废了,长对话成本会翻数倍。
Hermes 的设计选择是:
- Frozen snapshot:session 开始时一次性加载到 system prompt,session 内部绝不改变
- 落盘立即生效:agent 在 session 中对 memory 的修改立即写入磁盘
- 系统提示滞后一轮:修改要到下一个 session 才会反映在 system prompt 里
- Tool response 保证一致性:agent 查询 memory 时,tool 返回的永远是最新状态 这是一个把认知科学需求(记忆持久性)与 serving 经济学(prefix cache)对齐的经典取舍。 代价是 memory 容量很小,但换来的是每次对话的 token 成本稳定、可预测。
第二层:程序性记忆——Agent-managed Skills
这一层是 Hermes 最让我兴奋的设计。
技能(Skill)的概念本身不新鲜——Anthropic、OpenAI 的官方 skills 生态都有。但 Hermes 做了两件关键的事:渐进加载 和 Agent 自创。
渐进加载(Progressive Disclosure) 是解决"工具爆炸"问题的优雅答案:
Level 0: skills_list() → ~3k tokens,所有技能的元数据
Level 1: skill_view(name) → 加载完整 SKILL.md
Level 2: skill_view(name, path) → 加载子资源(references/templates/scripts)想象一下:如果你有 50 个技能,每个技能平均 3k tokens,全塞进 system prompt 就是 150k tokens——prefix cache 永远失效,小模型直接失忆。用渐进加载后,system prompt 只占 ~3k tokens,其余按需加载。
更有意思的是条件激活机制:
metadata:
hermes:
fallback_for_toolsets: [web] # 只在 web 工具链不可用时出现
requires_toolsets: [terminal] # 只在 terminal 可用时出现举个真实例子:Hermes 内置了一个 duckduckgo-search 技能,它的 metadata 写的是 fallback_for_toolsets: [web]。当你配置了 Firecrawl API key,web 工具链可用,web_search 工具顶上,DuckDuckGo 技能自动隐藏;如果没配 key,DuckDuckGo 技能自动现身作为 fallback。
这是一种 context-aware tool routing——比纯 embedding-based 的工具选择更确定性、更可调试。
Agent 自创技能(skill_manage tool)是这一层最激进的部分。触发条件文档里写得很清楚:
- 完成复杂任务(5+ tool calls)成功后
- 遇到错误和死胡同,最终找到正确路径后
- 用户纠正了 agent 的做法时
- 发现非平凡的工作流后
Agent 会主动调用
skill_manage(action="create", ...),把这次的执行路径写成一个 reusable skill。下次遇到类似任务,直接加载这个技能,不用再"摸索一遍"。 这是真正的"procedural memory"——程序性记忆。 它不是简单地记住"用户喜欢什么",而是记住"我遇到这种问题应该怎么做"。
第三层:情景记忆——Session Search (FTS5)
这一层是我认为 Hermes 在成本/能力取舍上最聪明的选择。
大多数个人 AI 助手项目(MemGPT、Letta 等)在"跨会话记忆"这个问题上的答案是:向量数据库 + embedding 检索。Hermes 的答案是:SQLite FTS5 + Gemini Flash 摘要。
对比一下这两种技术路线:
维度 | SQLite FTS5(Hermes) | 向量数据库(主流) |
|---|---|---|
存储 | 单文件 state.db | 需独立服务(Qdrant/Chroma) |
部署 | 零依赖,SQLite 内置 | 需额外运维 |
索引成本 | 写入即索引 | 每次写入需 embedding 推理 |
召回类型 | 精确匹配、BM25 | 语义相似 |
对"具体事件"召回 | ✅ 强 | 弱 |
对"相关主题"召回 | 弱 | ✅ 强 |
运维复杂度 | 几乎为零 | 中-高 |
成本 | 可忽略 | 持续的 embedding 成本 |
Hermes 的判断是:个人助手场景下,用户最常问的是"我上次说过 X 吗?"、"我们之前聊过 Y 吗?"——这些是精确关键词查询,FTS5 足够用。向量检索的边际收益撑不起额外的工程复杂度和成本。
命中之后的处理也很聪明:不把原文塞回 context,而是用 Gemini Flash(一个便宜的摘要模型)做摘要 → 注入。这是经典的 retrieve → summarize → ground 模式的变体,用低成本模型处理"压缩步骤",把主模型的 context 预算留给核心推理。
第四层:心智理论——Honcho 与外部 Provider
Hermes 内置支持 8 个外部 memory provider:Honcho、OpenViking、Mem0、Hindsight、Holographic、RetainDB、ByteRover、Supermemory。这些 provider 补充了内置记忆的能力——知识图谱、语义检索、自动事实抽取、跨会话用户建模等。
架构设计上最关键的一点:这些 provider 是加法式(additive)的,不替代内置记忆。原文是 run alongside built-in memory, never replacing it。System prompt 的结构变成:
SOUL.md + MEMORY.md + USER.md + Skills_Level0 + External Provider Context外部 provider 注入的是额外的 context 块。这是一个正确决策——避免了内置系统和外部系统之间的一致性地狱。
其中特别值得关注的是 Honcho——来自 Plastic Labs 的开源项目,理论基础是 Machine Psychology / Theory of Mind(心智理论)。它的核心思想不只是记录事实,而是让 LLM 持续推断用户的信念、偏好、情绪状态。
举个具体例子说明 ToM 建模和普通 memory 的差别:
- 普通 memory:
用户住在杭州,是个 Go 后端工程师 - ToM 建模:
用户在部署类任务中表现出明显的谨慎偏好。当涉及生产环境操作时,倾向于反复确认;但对本地开发环境的操作则直接执行。推断他可能经历过线上事故。这是两种完全不同量级的用户理解。前者是静态画像,后者是动态心智模型。Honcho 的工程落地还在早期,但它代表的方向——让 agent 拥有对用户的"心智模型"而不只是"用户画像"——是个人 AI 助手下一个十年的关键命题之一。
数据飞轮:真正的战略层
写到这里,你会发现 Hermes 的"自学习"机制已经很丰富了。但 Nous Research 的真实野心还在下一层。
打开 Hermes 仓库,有几个很 Python、很"研究所"风格的文件:
hermes-agent/
├── batch_runner.py ← 批量轨迹生成
├── trajectory_compressor.py ← 轨迹压缩
├── rl_cli.py ← RL 训练 CLI
├── datagen-config-examples/ ← 数据生成配置范例
└── tinker-atropos @ submodule ← Atropos RL 环境框架这些东西在 OpenClaw 里一个都没有。
它们透露了一个事实:Hermes 不只是一个产品,它还是 Nous Research 的 agent 训练数据工厂。
机制大致是这样:
- Hermes 运行时产生大量真实的 agent 轨迹(用户请求 + 工具调用序列 + 最终结果)
trajectory_compressor把这些长轨迹压缩成可训练的格式batch_runner批量运行 agent 在各种任务上的探索- Atropos 环境(Nous 自己的 RL 框架)提供训练所需的环境抽象
- 产出的数据用来训练下一代 Hermes 模型,这个模型又变成产品的底层
- 闭环 这就是典型的 "Data Flywheel as Moat":产品产生数据 → 数据训练模型 → 模型让产品更强 → 更多用户使用 → 更多数据。 OpenClaw 完全没有这一层。它是一个纯粹的产品,不是训练基础设施。这也合理——Peter Steinberger 不是 AI 实验室创始人,他不需要考虑训练管线。
部署灵活性:Serverless 友好
最后一个 Hermes 相对 OpenClaw 的重要扩展:6 种 terminal backend。
Backend | 场景 |
|---|---|
local | 本地直接跑 |
docker | 本机容器隔离 |
ssh | 远程机器 |
daytona | Dev environment as a service |
singularity | HPC / 学术集群 |
modal | Serverless,空闲休眠,近零成本 |
特别是 modal 后端——agent 环境在空闲时休眠,有请求时唤醒,成本模型从"常驻 daemon"变成"按使用量付费"。这解决了 OpenClaw "必须常驻本地 daemon"的核心痛点。
你可以把 Hermes 扔到一个 $5 VPS 上永远跑着,也可以放进 serverless 跑到几乎零成本,这种部署自由度在 OpenClaw 那里是不具备的。
五、 一个关键细节:Frozen Snapshot 与 Prefix Cache
我想单独开一章讲一个很小的技术细节,因为它浓缩了两个项目完全不同的思维方式。
在 Hermes 的文档里,关于 Memory 有这样一段注释:
The system prompt injection is captured once at session start and never changes mid-session. This is intentional — it preserves the LLM's prefix cache for performance.
翻译过来:system prompt 在 session 开始时被捕获为一个"冻结快照",在 session 中不再改变——这是故意的,为了保住 LLM 的 prefix cache。
这一句话背后是一场性能、一致性、实时性的三方博弈。我们一个个拆开看。
三个诉求在打架
设想你正在设计一个有记忆的 agent,面前有三个诉求:
诉求 1:性能/成本。希望 system prompt 前缀稳定,让 LLM API 的 prefix cache 能命中——成本降到 10%-20%。
诉求 2:一致性。当 agent 在 session 中更新 memory 后,它自己必须看到更新后的状态。否则会出现"我刚改过 memory,怎么自己还没反应?"这种神经质行为。
诉求 3:实时性。用户希望 memory 修改立即持久化——如果 agent 说"我记住了",结果只是暂时记在 RAM 里,session 一关就没了,用户会失望。
这三个诉求互相冲突。最简单的实现(每轮都把最新 memory 注入 system prompt)能满足一致性和实时性,但完全放弃了性能。最激进的实现(整个 session 锁死,只能下次 session 更新)保住了性能,但牺牲了一致性。
Hermes 的巧妙设计
Hermes 用了一个分层设计解决:
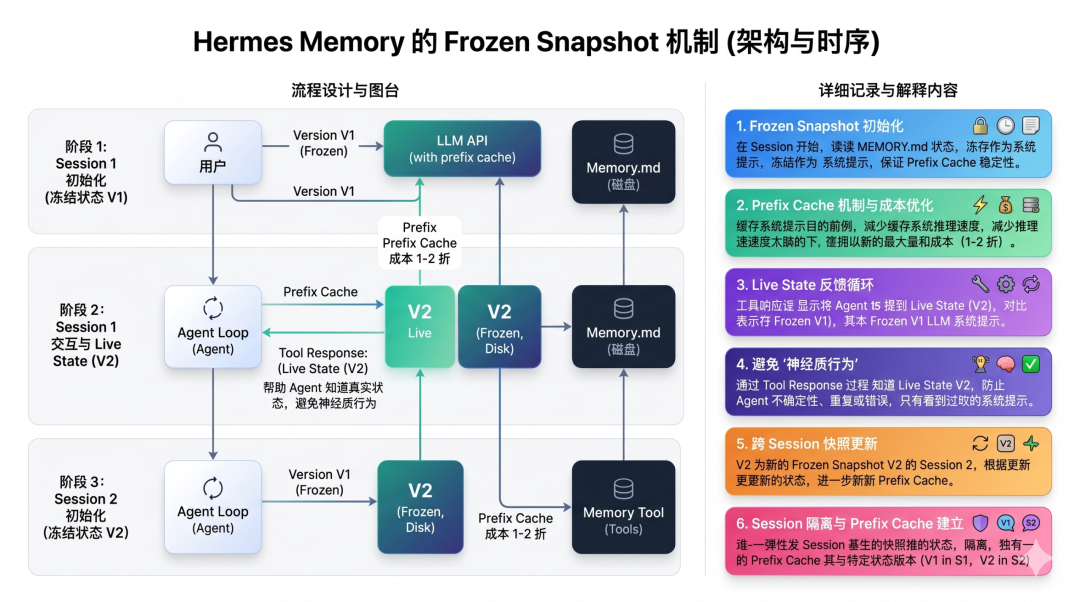
三个关键点:
- Session 内 system prompt 冻结:所有轮次共享同一个 prefix,prefix cache 命中率极高
- Memory 修改立即落盘:保证持久化
- Tool response 实时反映:agent 查询 memory 时,工具返回的永远是最新状态 这个设计用"分层的一致性保证" 同时满足了三个诉求:
- 成本层:system prompt 冻结 → prefix cache 命中
- 持久化层:磁盘立即写入 → 数据不丢
- 认知层:tool response 实时 → agent 自己不迷惑
OpenClaw 的做法对比
OpenClaw 在这个问题上没有这么精细的设计。它的 MEMORY.md、SOUL.md、AGENTS.md 都是在"工作区加载时"注入 system prompt,更新策略相对朴素。
这不是说 OpenClaw 做错了——对一个面向消费者的产品来说,这种细节优先级确实不如通道数量、Canvas 体验这些用户能感知的特性。
但这个小细节揭示了两个项目的思维差异:
OpenClaw 是在设计"用户用起来爽"的产品——它关心的是交互、通道、界面。
Hermes 是在设计"LLM 用起来高效"的系统——它关心的是 token 经济学、cache 命中率、推理成本的确定性。
两者都有道理,但它们服务的是不同的价值函数。
六、 分叉的真相:个人 AI 助手正在走向两种未来
扒完源码,我得出一个结论:OpenClaw 和 Hermes 不是"同一个产品的两个版本",它们代表了个人 AI 助手领域正在形成的两种未来。
两种路径的抽象
我把这个分叉画成一张决策
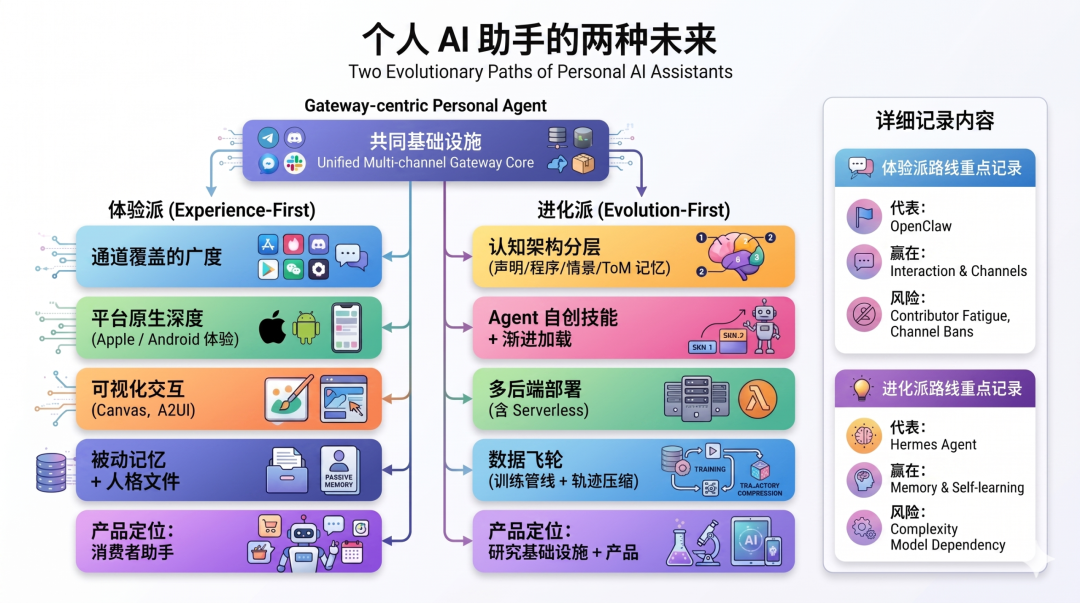
体验派:赌未来是"无处不在的助手"
体验派的核心命题是:个人 AI 助手的价值不取决于它有多聪明,而取决于它在你每一个通道都存在、能被每一种方式召唤、能以每一种模态回应。
这种思路下:
- 通道覆盖广度比模型智能更重要——用户在 WhatsApp 找不到你,你再聪明也没用
- 平台原生体验决定留存——macOS menu bar 能秒唤出,用户才会真用
- 可视化交互是差异化赌点——语音/文字之外的第三维度
- 人格稳定性是信任基础——SOUL.md 的人格长期不变,用户才会建立情感连接 这种路径的经济模型是什么?OpenClaw 官方没有商业化声明,但类似的产品(Rewind.ai、Rabbit R1 等)的路径是清晰的——消费级订阅 + 硬件 + 高端个人助手市场。一个足够精致的助手产品,能向愿意付费的人群(开发者、创作者、高端专业人士)卖到每月 20-50 美元。
进化派:赌未来是"会自我进化的智能体"
进化派的核心命题完全不同:个人 AI 助手的真正价值不在于它第一天多好用,而在于它用得越久越懂你、越能代替你工作。
这种思路下:
- 记忆分层是核心基础设施——没有分层记忆,agent 就是个 context 更大的聊天机器人
- 技能自创是长期价值——用户不需要每次教它同样的事
- 用户建模是差异化——能理解用户心智的 agent 才能真正"代理"
- 部署灵活性决定可得性——$5 VPS 能跑,才能进入大众市场
- 数据飞轮是商业护城河——运行时产生的轨迹 → 训练更好的模型 → 更好的产品 这种路径的经济模型也很清楚——开源产品 + 底层模型商业化 + 研究领先性。Nous Research 的主业是训练 Hermes 系列 LLM,Hermes Agent 对他们来说既是产品,也是获取真实世界 agent 轨迹数据的管道。这些数据用来训练下一代 tool-calling 模型——而一个能在 agent 任务上做得好的 LLM,在 B2B 市场有巨大的商业价值。
两条路径的关键摩擦点
我列一个更直接的对比:
维度 | 体验派(OpenClaw) | 进化派(Hermes) |
|---|---|---|
核心竞争力 | 通道 + 交互 + 平台体验 | 记忆 + 自学习 + 数据飞轮 |
对用户的承诺 | "我无处不在" | "我会越来越懂你" |
对模型的依赖 | 中等(模型只是后端之一) | 高(自学习效果依赖模型能力) |
工程重心 | 前端 + 移动端 + 通道 adapter | 后端 + 认知架构 + 训练管线 |
贡献者画像 | 前端/移动/平台工程师 | ML 工程师 + 系统工程师 |
典型部署 | 本地 daemon(Mac 优先) | 灵活(本地/VPS/Serverless) |
最大风险 | 通道被封、贡献者疲劳 | 自学习效果不如预期、复杂度失控 |
商业化方向 | 消费订阅、高端工具 | 模型商业化、企业市场、研究影响力 |
这不是零和博弈
要强调一点:这两条路径不是零和的,大概率最终会融合。
- OpenClaw 如果想走下去,大概率要补上分层记忆这一层——纯被动的 MEMORY.md 在长时间使用后一定会暴露问题
- Hermes 如果想扩大用户规模,大概率要补上通道覆盖和 UI 交互——纯技术优势不足以让普通用户切换 但短期(2-3 年内),这两条路径的资源投入和架构取舍完全不同。选错路线的团队会在半年后发现自己的技术债已经积累到难以偿还。
两条路径之外:还有第三条路吗?
值得思考:除了"体验派"和"进化派",有没有第三种范式?
观察整个个人 AI 助手生态,确实有几个项目在探索别的路径:
- LangGraph + 自己拼装:完全 DIY,灵活但门槛高
- Claude Projects / ChatGPT with Memory:闭源大厂的黑盒方案,产品好用但不可控
- MemGPT / Letta:学术驱动的 virtual context 路线,技术深度高但产品化弱
- AutoGen / CrewAI:多 agent 协作框架,但不是"个人助手"定位 这些都没有真正挑战 Gateway-centric 架构的主导地位。OpenClaw 和 Hermes 共同确立的这个范式,大概率会成为未来几年个人 AI 助手的默认架构基础。分叉的只是它上面长出的哲学。
七、 对开发者、CTO、普通爱好者的启示
扒源码是为了理解技术,但技术最终要服务于人要做的决定。这一章我按三类读者——开发者、CTO/架构师、普通爱好者——分别给出基于这次分析的实操建议。
决策框架先行
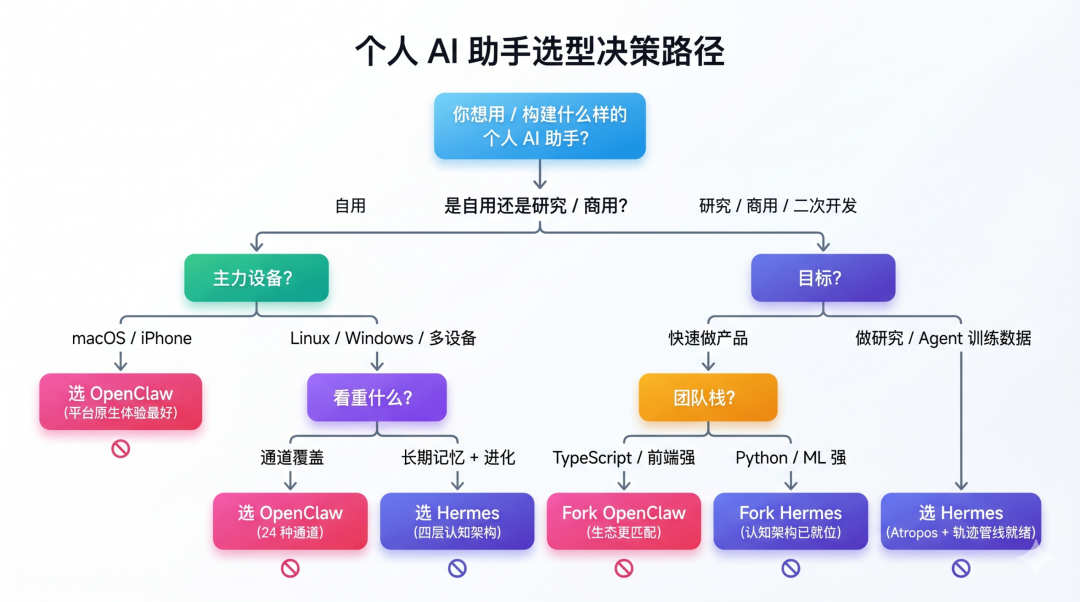
在展开之前,先把整个选择空间画清楚:
给开发者:技术债最少的选型策略
如果你是独立开发者或小团队技术负责人,想在这两个项目上做二次开发或借鉴其设计,我的建议分三个场景:
场景一:你想做一个针对特定人群(开发者 / 创作者 / 高端用户)的付费产品。
选 OpenClaw 作为基础。理由:
- 它的消费级体验打磨(macOS menu bar、Voice Wake、Canvas)是付费产品的护城河
- TypeScript/React 生态让前端改造成本低
- 24 种通道已经覆盖了绝大多数目标用户的使用习惯
- 人格系统(SOUL.md)支持定制化"角色"产品 要注意的技术债:通道 adapter 的长期维护成本极高。iMessage 桥接、WeChat 适配这些灰色路径,平台反制一来可能集体失效。如果你要把 OpenClaw 作为商业产品底座,砍掉你用不到的通道是必做的减法——不然你会把一半工程资源耗在维护一堆用户不用的适配器上。 场景二:你想做一个 B2B 或企业场景的 agent 产品。 选 Hermes 作为基础。理由:
- 四层记忆架构适合"一个专业工作场景长期使用"
- 多后端部署(Modal / Daytona)能映射到企业的云环境
- Python 栈更容易和企业已有的 ML 基础设施集成
- 轨迹压缩 + 数据生成管线让你自己积累领域数据成为可能 要注意的技术债:Hermes 还在 v0.8.0,文档和稳定性都不如 OpenClaw。如果你基于它做商业产品,必须做好跟进上游 breaking change 的心理准备——2026 年这一年大概率会有几次较大的架构调整。 场景三:你想做研究或写技术博客。 两个都扒。我个人在这次分析中学到最多的是对比它们的差异——单看任何一个都只能看到一种解法,对比着看才能看清整个问题空间。
对开发者的三条元建议
跳出具体选型,这次扒源码让我对 agent 开发有三条更底层的建议:
建议一:Prefix cache 是 agent 经济学的第一性原理。 你设计任何 agent 系统时,system prompt 的稳定性必须是一个一等公民的设计考量。不是"反正现在 context 便宜"——哪怕便宜 10 倍,长 session 下来的成本差异依然巨大。Hermes 的 frozen snapshot 设计值得抄到任何 agent 项目里。
建议二:记忆要分层,不要一锅炖。 把"用户偏好"、"环境事实"、"历史事件"、"用户心智模型"扔进同一个向量库是错误的。它们的时间尺度、精度要求、更新频率完全不同。Hermes 的四层分法是一个好的起点,你可以根据业务场景调整,但"分层"这件事本身不能省。
建议三:沙盒不是可选项,是默认项。 只要你的 agent 会接入任何"不完全受信任的输入源"(包括用户自己的消息!prompt injection 不只来自第三方),默认策略就应该是工具调用进沙盒。OpenClaw 的 dmPolicy=pairing 和 sandbox.mode=non-main 是我见过最清晰的默认安全策略,值得参考。
给技术管理者与架构师:战略层的判断
如果你是企业的技术决策者,需要判断"个人 AI 助手这个赛道我们要不要投入、怎么投入",我给三个战略层的观察:
观察一:Gateway-centric 架构大概率会成为标准。 两个热门项目独立收敛到同一个架构范式——这种现象在技术史上通常预示着事实标准的形成。如果你现在还在纠结要不要做一个"完全自己的 agent 架构",我的建议是不要。在 Gateway-centric 范式上叠加你的差异化,比重新发明轮子省 12 个月。
观察二:记忆层是 agent 产品的真正护城河,不是模型。 模型每半年洗一次牌,但一个 agent 陪伴用户 3 年积累的记忆是不可替代的资产。如果你做的是 B2C agent 产品,记忆系统的设计比模型选型更影响长期留存。Hermes 的四层架构展示了这件事的工程复杂度——低估它会让你在 12 个月后发现用户流失率解释不清。
观察三:数据飞轮是 agent 行业的下一个分水岭。 那些能把"产品运行时"变成"训练数据源"的公司,将在 2-3 年后拉开显著差距。这不是说每个公司都要去训模型——但你至少要有意识地收集 agent 轨迹、结构化标注工具调用序列。即使你不训模型,这些数据本身也是高价值资产(可以卖给模型公司,可以用于离线评估,可以驱动产品决策)。Hermes 仓库里的 trajectory_compressor.py 和 batch_runner.py 值得任何做 agent 产品的团队借鉴——哪怕你只是用它们做内部分析。
给 技术管理者 的一个反直觉建议
很多 技术管理者 会问:"既然 Gateway-centric 是趋势,我要不要直接基于这两个开源项目的某一个做二次开发?"
我的回答是:大概率不要。
理由:这两个项目的产品定位是"个人助手",核心设计都是围绕"单一用户长期使用"展开的。如果你要做的是企业助手(多用户、角色权限、审计合规、与企业系统深度集成),它们的很多基础假设都不适用:
- 它们假设
mainsession 完全可信——企业场景下没有"完全可信的用户" - 它们的记忆是"给一个人的"——企业需要按角色、按部门、按项目隔离的记忆
- 它们的审计能力很弱——企业合规要求完整的操作日志和可追溯性
- 它们的权限模型是二元的(
main/non-main)——企业需要细粒度 RBAC 但是,它们的架构思想——Gateway 中心化、Channel Adapter 抽象、四层记忆、渐进加载 Skills——都是可以借鉴的。我的建议是读懂它们,然后基于你自己的业务场景重写,而不是直接 fork。
给普通爱好者:先用起来再说
如果你是个想体验一下"真正的个人 AI 助手是什么感觉"的技术爱好者,我的建议很简单:
如果你主力用 Mac,装 OpenClaw。它在 Mac 上的体验目前是最成熟的——menu bar app、语音唤醒、Canvas 可视化、iMessage 联动。跑一个周末你会对"什么是 always-on AI"有直观感受。
如果你喜欢 CLI + Telegram/Discord 的工作流,装 Hermes。它的 TUI 体验、跨会话记忆、技能系统更适合深度使用者。你能感受到"agent 用得越久越懂你"是什么意思。
不要两个都装——它们的配置目录会打架,虽然 Hermes 提供 claw migrate 但同时跑两个会让你很困惑。
做好心理准备:任何个人 AI 助手项目现在都不够"即插即用"。你会遇到配置问题、模型 API 问题、通道认证问题。准备好愿意花一个周末折腾——如果你不享受折腾,再等 6-12 个月,这两个项目届时会成熟很多。
结语:下一个十年,个人 AI 助手会长成什么样?
文章开头我说,扒完两个项目的源码,我看到了个人 AI 助手的下一个十年。现在到了把这句话兑现的时候。
基于这次对 OpenClaw 和 Hermes 的深度分析,我想给出三个判断 + 一个开放问题,作为全文的收束。
判断一:Gateway-centric 架构会成为行业事实标准
两个独立项目在没有显式协调的情况下,收敛到几乎一致的架构范式——这种现象在技术史上极少是偶然。未来 3-5 年,个人 AI 助手的基础设施层会被"本地 Gateway + 多通道 Adapter + 分层工具沙盒"这个三段式锁定。
在这个标准之上,会出现类似 Web 时代 "LAMP stack" 那样的生态标准化——MCP 协议会成为工具接入标准,类似 agentskills.io 这样的标准会规范化技能定义,更多 ACP-like 协议会让不同 agent 互通。
判断二:记忆层是下一个军备竞赛
过去 2 年,整个行业疯狂卷"模型参数、上下文长度、推理能力"。接下来 2-3 年,卷点会转移到"记忆架构"。
理由很简单:模型能力的提升曲线在变平(每一代的边际收益递减),但记忆架构的设计空间几乎还没被开垦。四层记忆只是一个起点,未来我们会看到:
- 主动遗忘机制:Agent 主动决定什么该忘掉,避免记忆污染
- 可版本化记忆:像 git 一样的 memory 分支和回滚
- 跨 agent 记忆共享:你的 agent 和你配偶的 agent 能安全地共享部分记忆
- 记忆的隐私原语:细粒度控制哪些记忆可以被哪些 session 访问 Honcho 代表的"心智理论建模"只是开始。未来五年,记忆架构会分化成一个和数据库领域一样复杂的学科。
判断三:个人 AI 助手会分化成两极
体验派和进化派不会永远分裂,但它们会先充分各自生长,然后在一个合适的时间点收敛。收敛后的形态大概率是两极的个人 AI 助手市场:
一极是"生活助手"——无处不在、多通道、多模态、情感化、人格化。它不一定最聪明,但它是你日常生活的"伴侣型"存在。OpenClaw 的基因适合这一极。消费级订阅、硬件集成(类似 Rabbit R1、AI Pin)会是主要商业形态。
另一极是"工作代理"——深度专业化、长期记忆、能代替你完成复杂工作流、能自我进化。它不追求"到处都能找到它",但它是你工作场景下的"副驾驶 / 数字员工"。Hermes 的基因适合这一极。B2B 订阅、企业集成、按工作流付费会是主要商业形态。
两极之间会有一片"空气稀薄的中间地带"——既不够消费级娱乐、也不够专业级深度的产品,大概率会在未来 2-3 年被挤出市场。
开放问题:个人 AI 助手的"身份归属"怎么解决?
最后留一个我暂时没有答案的问题。
无论是 OpenClaw 还是 Hermes,都建立在一个隐含假设上:agent 是"用户的"。它的人格、记忆、技能、数据都应该属于用户本人,用户有完全的控制权和所有权。
这是一个意识形态上正确但现实中极其脆弱的假设。当用户的个人 AI 助手:
- 运行在某家云服务上(Modal / Daytona / 其他)
- 调用某家公司的模型 API(OpenRouter、Anthropic、Nous 自己的 Portal)
- 使用某家公司分发的技能(Skills Hub、ClawHub、各种 marketplace)
- 接入某家公司的消息通道(Telegram、Discord、WeChat) 每一个环节都可能构成一种"数字依附"。你的 agent 理论上是你的,但它的任何一个关键组件被切断,它就变成废铁。 这个问题在下一个十年会变成个人 AI 助手领域最深刻的政治/哲学命题。去中心化、本地优先、数据主权——这些在当下听起来像技术口号的词,将会变成实际影响产品选型的标准。谁能真正解决"agent 的身份归属"问题,谁就有可能定义下一个十年的默认形态。
尾声
写完这篇文章,我回看一开始那个让我停下的瞬间——hermes claw migrate 那一行命令。一个项目给另一个项目写迁移工具,在开源世界里不算罕见,但它象征意义深远:这个领域正在形成共同语言、共同资产、共同遗产。
OpenClaw 和 Hermes 不会是最后两个。2026 年之后,更多项目会进入这个赛道,它们都会基于两者确立的共同范式生长,同时在哲学上各取其一作为起点。
个人 AI 助手的下一个十年,会是一段精彩的演化史。而我们——作为开发者、作为架构师、作为早期用户——恰好站在这段演化史的起点上。
希望这篇文章,能让你在这段演化开始的时候,看到比 README 更深一点的东西。
关注:技术方舟,带你领略不一样的技术海洋
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号