分布式数据库中分布键该怎么选?一张表只有一次机会

分布式数据库中分布键该怎么选?一张表只有一次机会

PawSQL
发布于 2026-06-17 20:46:02
发布于 2026-06-17 20:46:02
Co-located Join 不是万能解药,但用对了能让核心查询快 40 倍。
一个必须先承认的前提
上一篇分析跨分片JOIN的三大性能杀手时,留下了一个问题:有没有办法从根源上消除跨分片JOIN?
答案是:没有。但可以做到"消除你最在乎的那条路径上的跨分片JOIN"。
原因很简单:一张表只能有一个分布键,但业务查询的JOIN字段往往不止一种。
-- 按 user_id 查询订单历史(最高频)
SELECT * FROM orders WHERE user_id = 123;
-- 按 order_id 查询订单详情(次高频)
SELECT * FROM orders o JOIN order_items oi ON o.order_id = oi.order_id;
-- 按 merchant_id 查询商家订单(运营报表)
SELECT * FROM orders WHERE merchant_id = 456;同一张 orders 表,三种查询模式,三个候选分布键。你只能选一个——选了 user_id,前两种查询的本地JOIN问题就解决了,但商家维度的查询依然要跨分片。这不是技术缺陷,而是分布式系统的根本性约束。真正的问题不是"如何根治跨分片JOIN",而是"如何为最重要的查询路径做出最优的分布决策,同时接受其他路径的代价"。
理解了这个前提,我们才能正确看待本篇的核心——分片内关联(Co-located Join)。
分片内关联:为主路径消除数据搬迁
原理
核心思想只有一句话:让经常一起JOIN的表,按照相同字段、相同规则分布到相同节点,JOIN在本地完成,不产生任何数据移动。
三种架构的实现方式略有不同,但目标一致。
- 架构一(分片中间件,TDSQL分布式为例)
通过相同的分片键,保证关联数据落在同一分片:
orders(按 user_id 分片) users(按 user_id 分片)
分片1:user_id 1-10000 分片1:user_id 1-10000
分片2:user_id 10001-20000 分片2:user_id 10001-20000
分片3:user_id 20001-30000 分片3:user_id 20001-30000
→ 中间件将 SQL 下发到各分片,分片内本地完成 JOIN,零跨节点传输架构二(存算分离 MPP,以 GaussDB DWS 为例)建表时指定相同的分布列,优化器识别到分布列与 JOIN 条件一致,自动选择 Local Hash Join:
CREATE TABLE orders (...) DISTRIBUTE BY HASH(user_id);
CREATE TABLE users (...) DISTRIBUTE BY HASH(user_id);架构三(经典 MPP,以 Teradata 为例)通过主索引(Primary Index)控制数据落点,相同 PI 值的数据在同一 AMP,JOIN 在本地完成:
CREATE TABLE orders (...) PRIMARY INDEX (user_id);
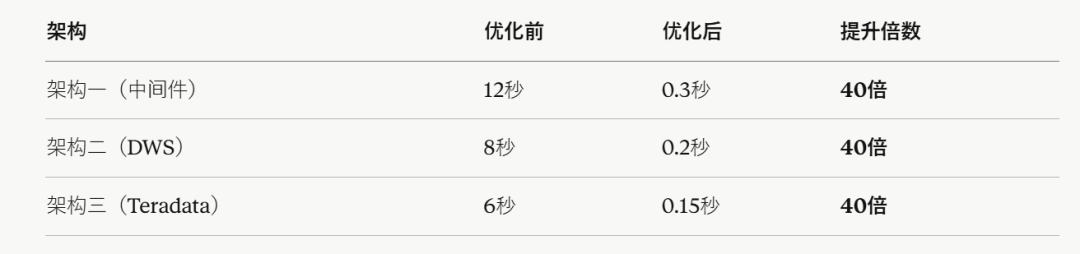
CREATE TABLE users (...) PRIMARY INDEX (user_id);性能差距以下是基于 TPC-H 基准(1TB 数据规模)的实测数据:
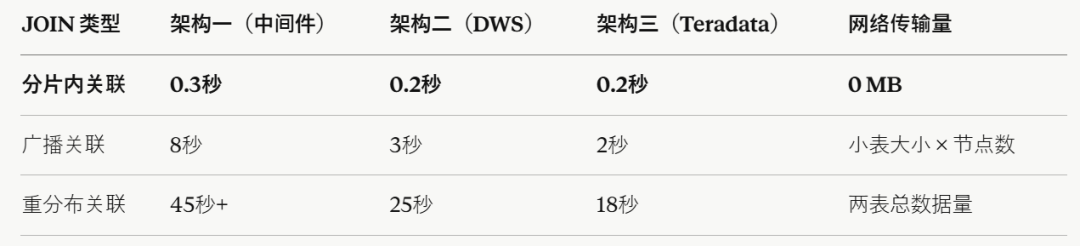
主路径上,分片内关联比重分布关联快两个数量级。网络状况越差、数据规模越大,差距越悬殊。
分布键选择:一张表只有一次机会
正因为只能选一个,分布键的决策就必须严肃对待。改错了代价极高——轻则停服迁移,重则影响线上核心业务。
决策框架
- 第一步:摸清查询全貌
在做任何决定之前,先把近 30 天的慢查询日志拉出来,统计 JOIN 字段的出现频率:
SELECT join_field, COUNT(*) AS frequency
FROM slow_query_log
WHERE query_type = 'JOIN'
GROUP BY join_field
ORDER BY frequency DESC;
不要凭感觉,数据说话。
- 第二步:识别主路径
频率最高的 JOIN 字段,通常就是分布键的首选。但还需要叠加以下三个约束来验证:

- 第三步:量化评分,辅助决策
当候选字段不止一个时,用这张评分表来对比:
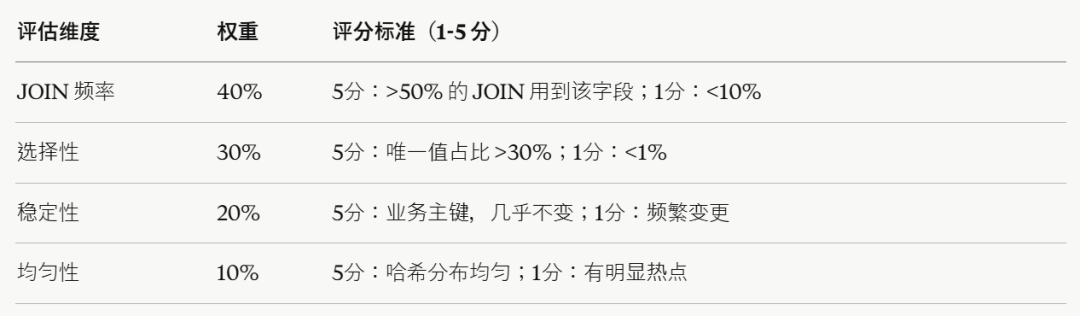
综合得分 = Σ(权重 × 得分),超过 4 分的字段可以作为最终候选。
- 多张表关联时,如何取舍?
当涉及 3 张以上表时,往往无法让所有表同时实现本地 JOIN。这是另一个必须正视的现实。
SELECT ...
FROM users u
JOIN orders o ON u.user_id = o.user_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id;四张表,两条 JOIN 路径(user_id 链路和 order_id 链路),只能选其一优先: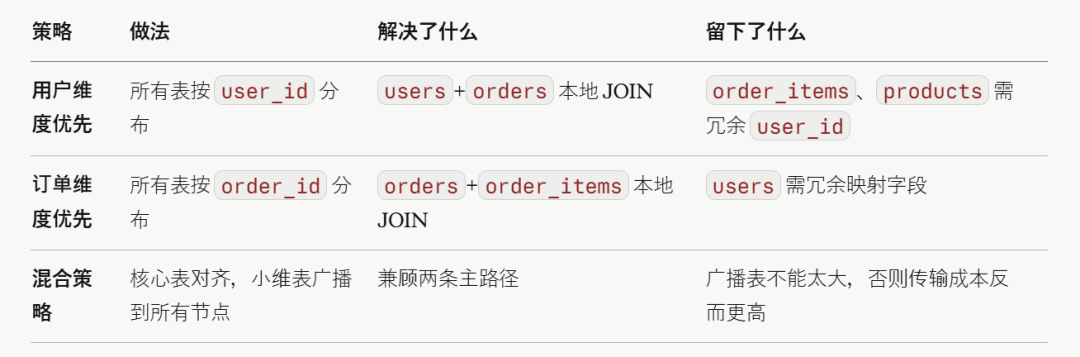
没有完美答案,只有最优取舍。 推荐的原则是:选择业务最核心、用户最感知的那条查询路径优先保障,其余路径通过冗余字段、广播表或物化视图来弥补。
各架构的设计要点
- 架构一(分片中间件)

- 架构二(存算分离 MPP)
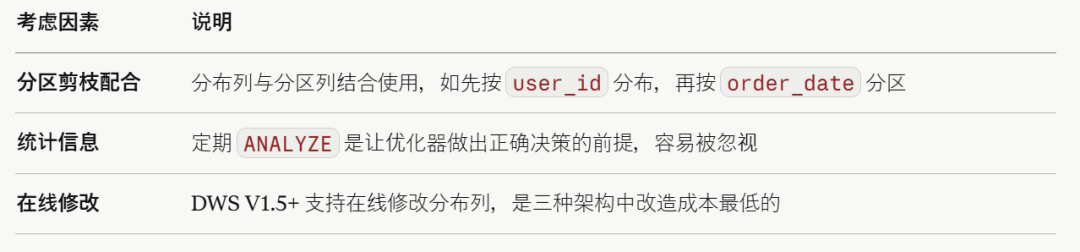
- 架构三(经典 MPP)

实战案例:40 倍提升背后的取舍
改造背景
某电商平台早期为了快速上线,所有表按主键随机分片,随着业务增长查询性能持续恶化。
- 数据规模:
表 | 行数 | 当前分布键 |
|---|---|---|
orders | 5 亿行 | order_id |
order_items | 15 亿行 | order_item_id |
users | 2000 万行 | user_id |
- 核心痛点 SQL:
SELECT o.order_id, o.order_time, oi.product_name, oi.quantity, oi.price
FROM orders o
JOIN order_items oi ON o.order_id = oi.order_id
WHERE o.user_id = 12345
ORDER BY o.order_time DESC
LIMIT 10;根因:orders 按 order_id 分片,过滤和 JOIN 条件都用 user_id,必然全量重分布。
决策过程
统计近 30 天慢查询日志后发现:
- 85% 的慢查询涉及
orders和order_items的 JOIN - 按
user_id查询占 60%,按order_id点查占 30%,按merchant_id的运营查询占 10%
决策:选 user_id 作为分布键,覆盖最高频的用户维度查询。
接受的代价:商家维度的运营查询(10%)在改造后依然会触发跨分片扫描。针对这部分查询,后续通过物化视图预计算来弥补,不纳入本次改造范围。
改造执行
- 架构一(分片中间件)
-- 1. 创建新表,指定分片键并配置 ER 分片绑定
CREATE TABLE orders_new (
order_id BIGINT,
user_id INT,
order_time DATETIME,
...
) SHARDKEY = user_id
BINDING_TABLES = order_items_new;
CREATE TABLE order_items_new (
order_item_id BIGINT,
order_id BIGINT,
user_id INT, -- 新增冗余字段,支持路由
product_name VARCHAR(200),
quantity INT,
price DECIMAL(10,2)
) SHARDKEY = user_id
BINDING_TABLES = orders_new;
-- 2. 分批迁移数据
INSERT INTO orders_new SELECT * FROM orders;
-- 3. 原子切换表名
RENAME TABLE orders TO orders_old, orders_new TO orders;
-- 4. 验证一致性后清理旧表架构二(GaussDB DWS)-- 在线修改分布列(V1.5+ 支持零停服)
ALTER TABLE orders SET DISTRIBUTE BY HASH(user_id);
-- order_items 需重建,同时补充 user_id 冗余列
CREATE TABLE order_items_new (
order_item_id BIGINT,
order_id BIGINT,
user_id BIGINT, -- 冗余列
...
) DISTRIBUTE BY HASH(user_id)
AS SELECT oi.*, o.user_id
FROM order_items oi
JOIN orders o ON oi.order_id = o.order_id;
DROP TABLE order_items;
ALTER TABLE order_items_new RENAME TO order_items;
-- 刷新统计信息,让优化器感知新分布
ANALYZE VERBOSE orders;
ANALYZE VERBOSE order_items;架构三(Teradata)-- 修改主索引必须重建表
CREATE TABLE orders_new AS orders
WITH DATA AND STATS
PRIMARY INDEX (user_id);
CREATE TABLE order_items_new AS order_items
WITH DATA AND STATS
PRIMARY INDEX (user_id);
RENAME TABLE orders TO orders_old;
RENAME TABLE orders_new TO orders;
RENAME TABLE order_items TO order_items_old;
RENAME TABLE order_items_new TO order_items;
-- 收集统计信息
COLLECT STATISTICS COLUMN(user_id) ON orders;
COLLECT STATISTICS COLUMN(user_id) ON order_items;改造效果
架构二优化后的执行计划:
Streaming (type: LOCAL) ← 本地 JOIN,无重分布
-> Hash Join
-> Index Scan on orders (user_id = 12345) ← 走索引,精准定位
-> Index Scan on order_items ← 同节点本地扫描
Total runtime: 0.35 ms (per node)Streaming type: LOCAL 是我们最想看到的结果。
五、当分布键无法满足某条查询路径时
即便做了最优的分布键设计,总有一些查询路径无法享受本地 JOIN。这时不是"放弃优化",而是换工具:

有时候,一个冗余字段就能省掉一次 JOIN:
-- 原做法:需要关联 orders 才能过滤 user_id
SELECT * FROM order_items oi
JOIN orders o ON oi.order_id = o.order_id
WHERE o.user_id = 123;
-- order_items 补充 user_id 冗余列,写入时同步维护
ALTER TABLE order_items ADD COLUMN user_id INT;
-- 查询退化为单表扫描
SELECT * FROM order_items WHERE user_id = 123;总结

分片内关联的本质,是把查询优化的决策提前到数据建模阶段。分布键选对了,核心查询的性能天花板能提升两个数量级;选错了,后续再怎么调 SQL 都是在有限的空间里打转。
好的分布键设计,不是追求消灭所有跨分片操作,而是让最重要的数据流动变为零,让不可避免的数据移动代价最小。
下一步
你现在已经可以:
- ✅ 理解分布键的根本约束,建立正确的优化预期
- ✅ 用量化框架为高频查询路径选择最优分布键
- ✅ 在三种架构下落地改造,并制定平滑迁移方案
但有些场景下,改动分布键根本不可行——遗留系统动不了、多业务共用表改不起、窗口期申请不下来。下一篇,我们讲不改表也能快的方法。
📌 下期预告:《不用改表也能快——查询改写与条件下推实战》。利用过滤条件下推和值传递,在不变更数据分布的前提下,实现数量级的性能提升。
🌐关于PawSQL
PawSQL专注于SQL质量管理和数据库性能优化自动化和智能化,提供的解决方案覆盖SQL开发、测试、运维的整个流程,广泛支持多种主流商用、国产和开源数据库,为开发者和企业提供一站式的创新SQL质量审核和优化解决方案。
图片
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号