软件设计中的数字:3

软件设计中的数字:3
黑猫Lien
发布于 2026-06-17 21:23:59
发布于 2026-06-17 21:23:59
“ 抽取方法的时机:出现相似的3个方法”
为什么是3这个数字呢?今天就来聊一聊这个数字三。
这里我们来分别看看在第一次,第二次,第三次,第四次出现类似方法时抽取方法的场景。
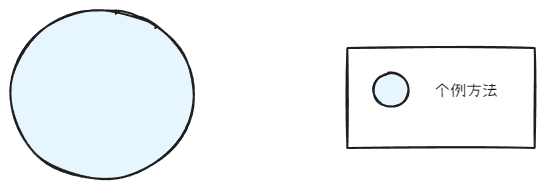
功能第一次出现时,没有公共信息
首先当方法第一次编写时,方法本身完全没有提供给我们公共信息(也就是抽取出的公共方法是如何定义的?)。关于公共方法的信息很少。抽取准确度可能很低。
如果这时强行抽取公共方法基本只有两条路。一条就是以当前方法的所有内容作为公共信息来定义公共方法,但这样以所有当前方法作为公共方法的做法,显然已经叫做过度设计。另一条路则是根据经验来判断:哪部分是公共信息,以及什么是公共方法。这显然又陷入了经验主义陷阱。
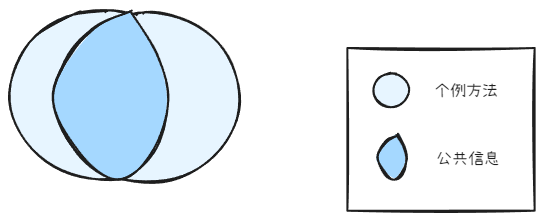
相似功能第二次出现时,有了公共信息
当出现第二个类似的方法时,感觉有了一些公共信息,可以做一部分抽象。有了公共信息。但准确度有待提高。
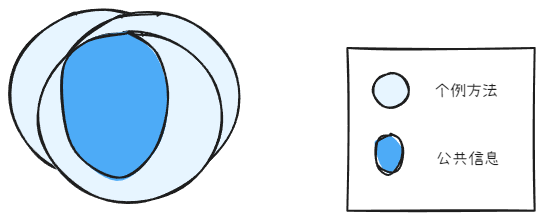
相似功能第三次出现时,公共信息准确度变高
当出现第三个类似的方法时,公共信息更多了。而且出现了公共信息的叠加。三者共通的部分,是真正的公共部分的可能性大大提高了。抽象准确度较高。
相似功能第四次出现时,公共信息准确度变更高
当出现第四个类似方法时,公共信息比第三个更多了。但相比来说收益略微降低。我第三次已经做好抽象的情况下,第四次已经可以直接使用它了。这样就节约了这次的开发成本,把这第四次变成了这次设计工作(抽象动作)的收益。
通常来说类似方法出现的次数越多。就越难给我们提供有效的公共信息。边际效应递减。比如:类似的功能出现十次,可能就提供不了一点有效的公共信息了。
总结
软件设计中的数字3(出现三次则抽取方法),本质上是为了防止过度设计,平衡收益和成本。
软件设计是一个大成本的工作。能少就尽量少。
且软件设计是一个影响很大的工作。能准确就尽量准确。
总结一下本篇文章中的信息点:
- • 在相同能力的情况下,公共信息越多,设计质量越高。
- • 类似方法出现越多,边际效应递减,公共信息的收益降低。
- • 越早进行抽象和设计,越早获得收益。
所以:基于成本和收益平衡的角度来讲,以三这个次数标准来抽取方法(或者说设计)是工作成本和收益平衡点。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号