AI 编程总失控?Comet + OpenSpec + Superpowers 用文件系统管住 AI
原创
AI 编程总失控?Comet + OpenSpec + Superpowers 用文件系统管住 AI
原创
术哥
发布于 2026-06-17 22:07:21
发布于 2026-06-17 22:07:21
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 142 篇,AI 编程最佳实战「2026」系列第 42 篇 大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。 我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者! Talk is cheap, let's explore。无界探索,有术而行。

信息图封面:三个项目分工 + 五阶段流水线 + 关键数据
你在用 Claude Code 或 Cursor 做项目时,可能踩过这些坑:
- 需求只存在于聊天记录里,关掉窗口就找不到了
- 换个终端打开,AI 不知道上次做到哪一步
- 该写测试的时候,AI 已经跳到写文档了
- 代码改完忘了归档,下次迭代又从头来过
翻了一圈社区讨论,这类吐槽出奇一致。问题的根源不是模型不够聪明,而是 AI 编程缺少工程纪律:没有规格管理,没有状态追踪,没有阶段校验。
GitHub 上有三个开源项目正在尝试解决这个问题:Superpowers、OpenSpec 和 Comet。它们不依赖数据库或云服务,只用 Markdown 文件、YAML 配置和 Shell 脚本,就把 AI 编程从即兴对话改造成了可追踪的工程流水线。
这篇文章基于三个项目的源码分析,拆解它们的分工逻辑、核心机制和工程取舍。
说明:本文内容基于 Superpowers、OpenSpec、Comet 三个开源项目的源码(GitHub 仓库)和官方文档分析整理而成,源码分析基于笔者本地仓库版本,尚未在生产环境中完成全场景验证。文中的架构分析和机制描述仅供参考,实际行为请以官方源码和文档为准。如果有实际使用经验,欢迎在评论区分享交流。
1. 三个项目各管什么
先说结论:这三个项目不是同类竞品,而是一条流水线的三层。
OpenSpec 管 WHAT(做什么)。它维护的是需求的规格生命周期:提案 → 规格 → 设计 → 任务清单 → 归档。核心要解决的问题是,需求不能只活在聊天记录里,得变成可追踪的文件。
Superpowers 管 HOW(怎么做)。它是一套方法论技能库,包含 TDD、系统化调试、子代理协作、代码审查等十几个 Skill。每个 Skill 就是一个 Markdown 文件,告诉 AI 在特定场景下应该遵循什么纪律。
Comet 管 WHEN 和 NEXT(什么时候做什么)。它是架在 OpenSpec 和 Superpowers 之上的编排层,用一个 YAML 状态机管理五阶段流水线:open → design → build → verify → archive。每次进入一个新阶段,Comet 会自动分发到对应的子技能。
这个分工有一层关键的工程考量:Comet 不修改 OpenSpec 和 Superpowers 的原始 Skill 文件。这一点在 Comet 的 CLAUDE.md 中写得明确,它是纯粹的编排层,不侵入底层项目。
好处是 Superpowers 和 OpenSpec 各自迭代时,Comet 不受影响,用户也可以单独用任何一个,不需要装全家桶。代价也明显:Comet 没法深度定制底层行为,只能靠编排规则来约束。
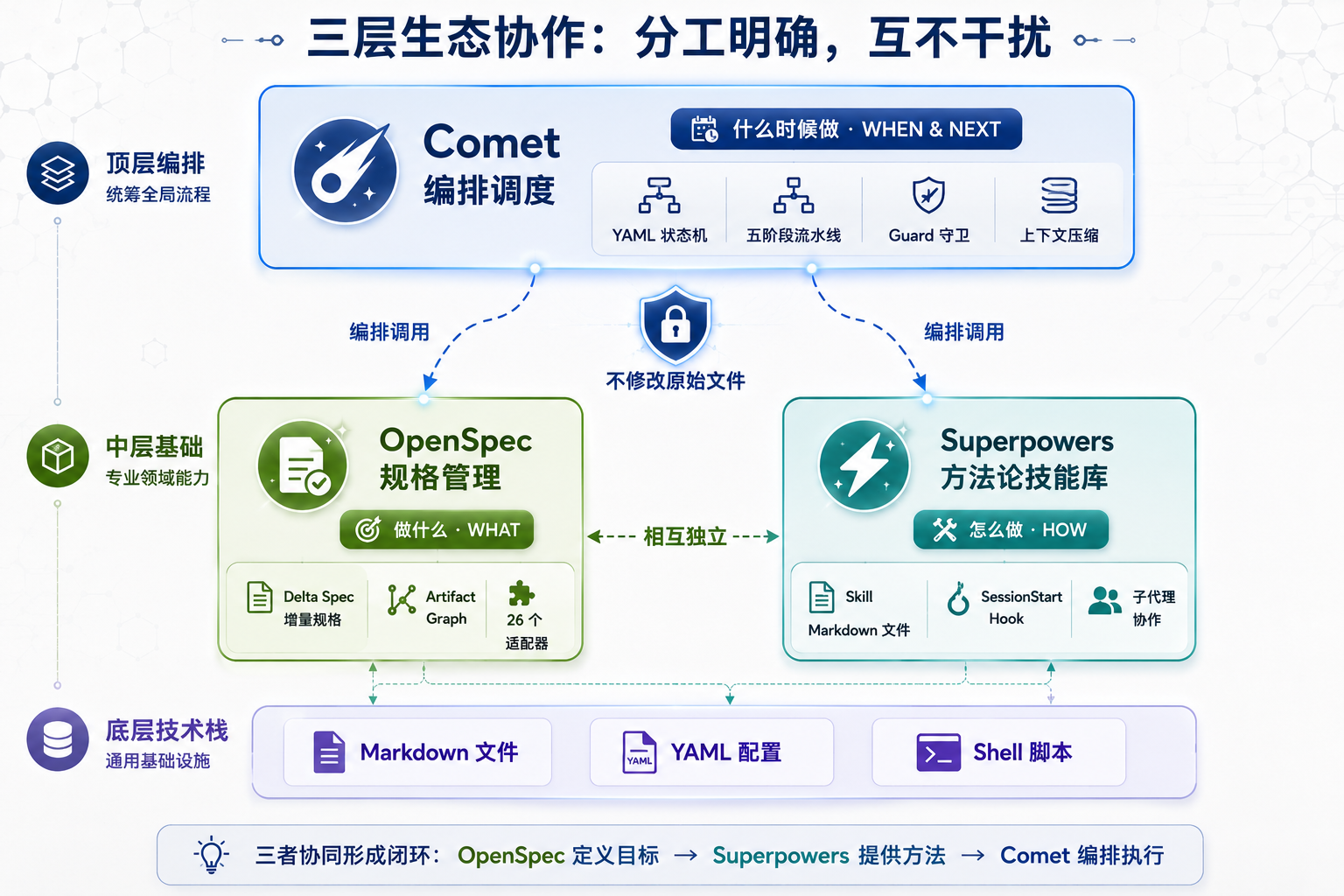
三层分工生态图:OpenSpec/Superpowers/Comet 三层编排关系
图 1:三层分工生态图
2. Superpowers:用 Markdown 给 AI 加纪律
Superpowers 的源码结构很反直觉:核心是十几个 SKILL.md 文件,几乎没有可执行代码。真正能算代码的只有 hooks/session-start 这个 57 行的 Shell 脚本。
这 57 行脚本是整个系统的自举(bootstrap)入口。
# session-start 脚本的核心逻辑(简化版)
using_superpowers_content=$(cat "${PLUGIN_ROOT}/skills/using-superpowers/SKILL.md")
# JSON 转义后注入为会话上下文
session_context="<EXTREMELY_IMPORTANT>\nYou have superpowers.\n\n${using_superpowers_escaped}\n</EXTREMELY_IMPORTANT>"
# 根据宿主平台输出不同格式的 JSON
printf '{\n "hookSpecificOutput": {\n "hookEventName": "SessionStart",\n "additionalContext": "%s"\n }\n}\n' "$session_context"具体的触发链路是这样的:hooks.json 注册了 SessionStart 事件监听,matcher 是 startup|clear|compact。也就是说,会话启动、清空上下文、上下文压缩这三种情况都会触发。
脚本执行后,using-superpowers/SKILL.md 的完整内容被注入为 additionalContext(Claude Code 格式)或 additional_context(Cursor 格式)。AI 在第一轮对话时就自动获得了检查和使用 Skill 的指令。
这个设计要解决的问题其实很直接:AI 不需要自己记住该用什么 Skill。很多 AI 编程方案失败在这里——它们依赖 AI 自己判断什么时候该用什么方法论。但 AI 的注意力是有限的,聊着聊着就忘了。Superpowers 把这个指令在会话开始时就注入了上下文,相当于每次对话开始前先给 AI 贴一张备忘录。
有意思的是脚本里的平台适配逻辑。同一个脚本,会根据环境变量判断当前运行在哪个平台:
- 如果
CURSOR_PLUGIN_ROOT存在 → 输出additional_context(Cursor 的 snake_case 格式) - 如果
CLAUDE_PLUGIN_ROOT存在且没有COPILOT_CLI→ 输出hookSpecificOutput.additionalContext(Claude Code 的嵌套格式) - 其他情况 → 输出
additionalContext(SDK 标准格式)
这说明 Superpowers 设计时就考虑了多平台兼容,不是只为 Claude Code 服务。
Skill 之间也有明确的依赖链路。从 SKILL.md 文件的内容可以还原出这条链:
brainstorming → using-git-worktrees → writing-plans → subagent-driven-development
↓ (内部调用)
test-driven-development
requesting-code-review
receiving-code-review
→ finishing-a-development-branch
→ verification-before-completion设计探索(brainstorming)是入口,不可跳过。Git Worktree 隔离是第二步,确保工作空间独立。然后是写计划、执行计划,中间穿插 TDD 和代码审查,最后是分支完成和验证。这条链路本质上是一套标准的软件工程流程,只不过用 Skill 文件固化成了 AI 能执行的指令。
3. OpenSpec:增量规格与制品依赖图
OpenSpec 的定位是规格驱动开发(Spec-Driven Development)。核心要解决的问题是:需求只存在于聊天记录中。
它用 TypeScript CLI + Markdown 模板系统,把需求规格变成了可版本控制的文件。但真正有意思的不是这个,而是它的两个核心机制。
Delta Spec:增量规格
OpenSpec 的 Delta Spec 机制是针对存量项目(brownfield)设计的。不重写整个规格,只描述变更部分:
# Delta for Auth
## ADDED Requirements
### Requirement: Two-Factor Authentication
(新增需求)
## MODIFIED Requirements
### Requirement: Session Expiration
(修改需求,替换原有)
## REMOVED Requirements
### Requirement: Remember Me
(废弃需求)归档时,delta spec 的三个部分被分别应用到主 spec:ADDED 追加、MODIFIED 替换、REMOVED 删除。这样做的好处是,你不需要为了加一个功能而重写整个认证模块的规格。
从 schemas/spec-driven/schema.yaml 源码可以看到,MODIFIED 的处理规则很严格:必须复制整个需求块(从 ### Requirement: 到所有 scenarios),在副本上修改。如果用 MODIFIED 但只写了部分内容,归档时会丢失细节。这个坑在 schema 的 instruction 字段里有明确提醒。
Artifact Graph:制品依赖图
OpenSpec 的 Schema 系统定义了制品之间的依赖关系。默认的 spec-driven schema 长这样:
artifacts:
- id: proposal
generates: proposal.md
requires: [] # 无依赖,首先创建
- id: specs
generates: specs/**/*.md
requires: [proposal] # 需要 proposal
- id: design
generates: design.md
requires: [proposal] # 可与 specs 并行
- id: tasks
generates: tasks.md
requires: [specs, design] # 需要 specs 和 design关键在于,依赖是使能器(enabler)而非门控(gate)。它们表示可以创建什么,而不是必须创建什么。你可以跳过 design,也可以先创建 specs 再回头补 design。
这种设计背后的理念,用 OpenSpec 官方文档自己的话说就是四个词:fluid not rigid, iterative not waterfall, easy not complex, brownfield-first。规格应该跟着开发节奏走,而不是反过来。
命令生成:26 个平台适配器
OpenSpec 的 src/core/command-generation/adapters/ 目录下有 26 个适配器文件,从 claude.ts 到 cursor.ts、codex.ts、gemini.ts、opencode.ts,覆盖了主流的 AI 编程工具。
每个适配器的作用是,把同一套工作流逻辑转换为不同平台的 Skill/Command 格式。比如 Claude Code 生成 .claude/skills/openspec-*/SKILL.md,Cursor 生成 .cursor/skills/openspec-*/SKILL.md,OpenCode 生成 .opencode/commands/openspec-*.md。
这意味着 OpenSpec 的工作流逻辑只写一次,通过适配器分发到各个平台。新增平台只需要加一个适配器文件。
4. Comet:一个 YAML 文件驱动的状态机
Comet 是三个项目中工程量最重的一个。CLI 用 TypeScript 写,但核心逻辑全在 Shell 脚本里:comet-state.sh 1245 行,comet-guard.sh 752 行,comet-handoff.sh 390 行。
Comet 的核心创新是用 .comet.yaml 这么一个简单文件,充当 AI Agent 的外部记忆。
状态字段与转换
从 comet-state.sh 的 cmd_set 白名单可以提取出完整字段清单。这些字段分三类:
# 阶段控制
workflow: full # 工作流类型:full/hotfix/tweak
phase: build # 当前阶段:open/design/build/verify/archive
archived: false # 归档终态
# 构建决策
build_mode: subagent-driven-development # 构建执行模式
build_pause: null # 构建暂停点:null/plan-ready
isolation: worktree # 隔离方式:branch/worktree
tdd_mode: tdd # TDD 模式:tdd/direct
subagent_dispatch: confirmed # 子代理派发确认
# 验证与交接
verify_mode: full # 验证模式:light/full
verify_result: pending # 验证结果:pending/pass/fail
handoff_context: docs/superpowers/handoff-rate-limit.md
handoff_hash: a1b2c3... # 交接上下文 SHA256 指纹状态转换不是随便改个字段值就行的。comet-state.sh 的 cmd_transition 子命令定义了合法的转换事件:
open-complete : open → design(full)或 open → build(hotfix/tweak)
design-complete : design → build
build-complete : build → verify(需校验构建决策)
verify-pass : verify → archive(需校验验证证据)
verify-fail : verify → build(保留分支状态)每次转换前,comet-guard.sh 都会检查前置条件是否满足。不满足就阻断,退出码 1。
阶段检测优先级
Comet 的 SKILL.md 定义了一个 first-match-wins 的阶段检测链路,写得很直接:
archived: true→ 工作流完成verify_result: pass→ 进入归档verify_result: fail→ 验证失败决策阻塞点phase: verify或 tasks.md 全勾选 → 进入验证phase: build→ 按工作流路由phase: design→ 进入设计phase: open→ 进入提案- 无活跃变更 → 创建新变更
这个检测链路的关键细节是:每次恢复上下文时都要重新执行 Step 0 和 Step 1,不能信任对话历史。因为对话历史可能被压缩或截断,只有文件系统的状态是可靠的。
Guard 守卫机制
comet-guard.sh 的设计体现了 Comet 的核心哲学:用脚本强制执行工程纪律,而不是寄希望于 AI 自觉。
从源码可以看到两个核心约束:
构建决策强制(require_build_decisions):离开 build 阶段之前,isolation 必须已设置(branch 或 worktree),build_mode 必须已选择。如果用的是 full workflow,还必须选 tdd_mode。如果 build_mode 是 subagent-driven-development,subagent_dispatch 必须是 confirmed。
# guard.sh 中的 tasks_all_done 函数
if ! grep -q '\- \[x\]' "$tasks"; then
echo "tasks.md has no completed tasks." >&2
return 1
fi
if grep -q '\- \[ \]' "$tasks"; then
echo "Unfinished tasks:" >&2
grep -n '\- \[ \]' "$tasks" >&2 || true
return 1
fi上面这段代码检查 tasks.md 里的任务勾选状态:没有已完成任务就阻断,有未完成任务也阻断。AI 没法跳过测试直接宣称完成。
验证证据强制(require_verification_evidence):进入 archive 之前,verification_report 必须指向实际存在的报告文件,branch_status 必须是 handled。没有验证报告就不能归档。
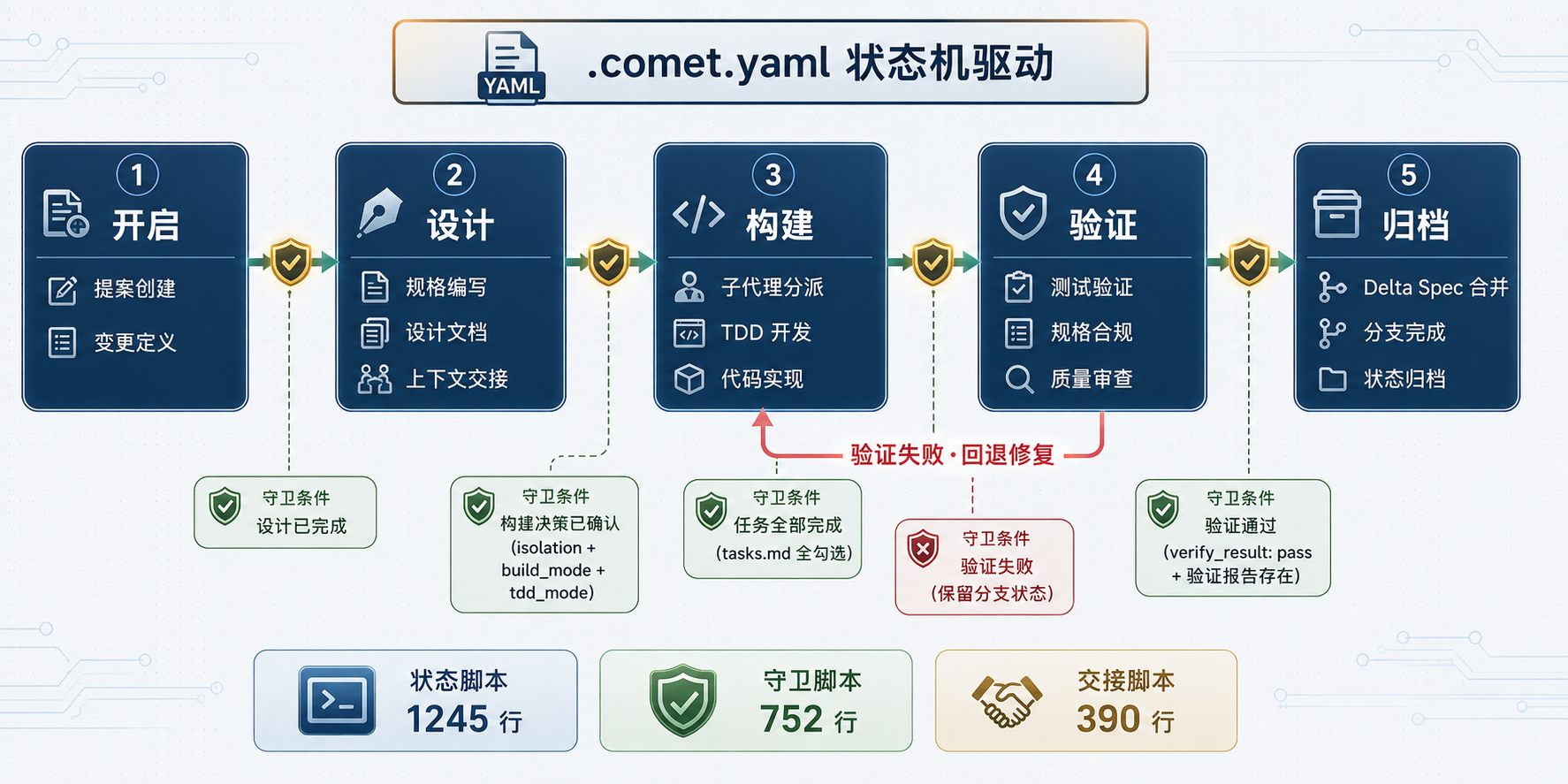
五阶段状态机流程图:open→design→build→verify→archive + Guard 守卫
图 2:五阶段状态机与 Guard 守卫关系图
规模评估机制
Comet 还有一个自动决策机制:根据变更规模选择验证模式。comet-state.sh 的 cmd_scale 子命令从三个维度评估:
task_count=$(grep -c '^\- \[' "$tasks_file")
delta_spec_count=$(find "$change_dir/specs" -name "spec.md" | wc -l)
changed_files=$(git diff --name-only "$base_ref"...HEAD | wc -l)
if [ "$task_count" -gt 3 ] || [ "$delta_spec_count" -gt 1 ] || [ "$changed_files" -gt 4 ]; then
verify_mode="full"
else
verify_mode="light"
fi任务超过 3 个、delta spec 超过 1 个、或变更文件超过 4 个,就自动切换到 full 验证模式。小改动走 light 模式,不浪费时间。
5. 嵌套 Skill 触发:让 AI 真正执行而非模仿
Comet 面临的一个核心技术挑战是:如何让 AI 真正触发底层 Skill,而不是看着文档描述来模仿行为。
这两者有本质区别。模仿行为是 AI 读了 Skill 的描述后,自己尝试执行类似操作,但可能遗漏关键步骤。真正触发是通过宿主平台的 Skill 工具加载 Skill 的完整内容,确保所有指令都被执行。
Comet 在 CLAUDE.md 中定义了统一的触发表述规范:
中文统一使用:
**立即执行:** 使用 Skill 工具加载 <skill-name> 技能。禁止跳过此步骤。
英文统一使用:
**Immediately execute:** Use the Skill tool to load the <skill-name> skill.
Skipping this step is prohibited.这个规范不是建议,是强制要求。每个子技能在进入和退出时都有明确的 Skill 加载指令。
配合触发表述的还有一个写保护机制:comet-hook-guard.sh。这是一个 PreToolUse Hook,注册在宿主平台的 hooks 配置中。
当 Comet 处于 open、design 或 archive 阶段时,如果 AI 试图写入代码文件(非文档和配置),hook 直接拦截并拒绝。设计意图很明确:AI 在需求未确认、设计未完成或归档进行中时,不能偷偷写代码。
从 platforms.ts 源码可以看到,支持 hooks 的平台包括 9 种,每种平台有不同的 hookFormat:
// Claude Code / Codex / Amazon Q
hookFormat: 'claude-code'
// Gemini CLI
hookFormat: 'gemini'
// Windsurf
hookFormat: 'windsurf'
// GitHub Copilot
hookFormat: 'copilot'
// Qwen Code
hookFormat: 'qwen'
// Kiro
hookFormat: 'kiro'
// Qoder
hookFormat: 'qoder'这说明 PreToolUse Hook 不是所有平台都支持的。不支持 hooks 的平台(如 Cursor),就只能依赖 SKILL.md 中的文字指令来约束行为,可靠性会打折扣。
你在项目中用过类似的 Skill 触发机制吗?欢迎在评论区聊聊实际体验。
6. 设计交接与上下文压缩
AI 编程工具的一个实际限制是上下文窗口。复杂项目的设计文档、规格文件、任务清单加起来可能几万字,全塞进 build 阶段的上下文会挤占代码生成的空间。
Comet 用 comet-handoff.sh 解决了这个问题。在 Design → Build 过渡时,这个脚本会生成一个结构化的上下文包。
两种压缩模式
# .comet.yaml 中的配置
context_compression: off # 或 betaoff 模式:完整 Spec 内容嵌入交接包,不做压缩。适合上下文窗口充裕的场景。
beta 模式:只保留 Design Doc 和源文件的 SHA256 哈希引用,不嵌入完整内容。AI 需要某个文件的细节时,根据哈希引用去读原文件。
交接包的结构长这样:
# Comet Design Handoff
- Change: rate-limit
- Phase: design
- Mode: beta
- Context hash: a1b2c3...
OpenSpec remains the canonical capability spec.
This handoff is a deterministic, source-traceable context pack,
not an agent-authored summary.
## openspec/changes/rate-limit/proposal.md
- Source: openspec/changes/rate-limit/proposal.md
- Lines: 1-42
- SHA256: d4e5f6...这里有一个值得注意的设计决策:交接包不是 AI 写的摘要,而是脚本确定性生成的。每一行都标注了源文件路径、行号范围和 SHA256 哈希。这意味着上下文是可追溯的,如果 build 阶段的 AI 对某个规格有疑问,可以直接打开源文件验证。
SHA256 追踪
每个源文件都计算 SHA256 哈希,整个上下文包也有一个聚合哈希。Guard 在进入 build 阶段前验证 handoff_hash 格式正确。
根据 Comet README 和 CONTEXT-COMPRESSION.md 的基准测试数据:
- beta 模式比 off 模式减少 25-30% 的 Build 阶段输入 token
- 测试通过率不受影响
- Spec 覆盖率从 100%(off)降到 95%(beta),仅在边缘案例细节有少量丢失
25-30% 的 token 节省对于长任务来说很可观。更重要的是,这个机制让跨会话恢复变得可靠:上下文压缩后,AI 不需要依赖对话历史,只需要读 .comet.yaml 和交接包就能恢复全部状态。

上下文压缩对比图:off vs beta 模式 + SHA256 追踪 + 数据对比
图 3:上下文压缩对比流程图
7. 多 Agent 协作模式
Superpowers 的 subagent-driven-development Skill 定义了一种多 Agent 协作模式。主 Agent 只做协调,实际编码由子 Agent 完成:
主 Agent(协调者)
├── 分派任务 → Implementer Subagent(写代码)
├── 审查结果 → Spec Compliance Reviewer(规格合规性)
├── 审查结果 → Quality Reviewer(代码质量)
└── 继续下一个任务或回退修复每个子代理获得全新的上下文,只接收当前任务所需的信息。这样做的好处是避免上下文污染:一个任务的细节不会干扰另一个任务的判断。
Comet 对这个模式有额外的约束。在 .comet.yaml 中引入了 subagent_dispatch 字段,要求在 build_mode: subagent-driven-development 时必须确认为 confirmed。
从 SKILL.md 的恢复逻辑可以看到具体的约束规则:
如果 subagent_dispatch 已确认,主窗口只协调不执行,检查第一个未完成任务,如已实现则勾选,否则派遣后台子代理。
如果 subagent_dispatch 未确认,恢复时会提示:确认子代理派发,或切换到 executing-plans 模式。
这条规则堵了一个常见的漏洞:AI 声称使用子代理模式,但实际上在主窗口直接执行了所有任务。子代理模式的价值在于上下文隔离,如果在主窗口执行,这个价值就丧失了。
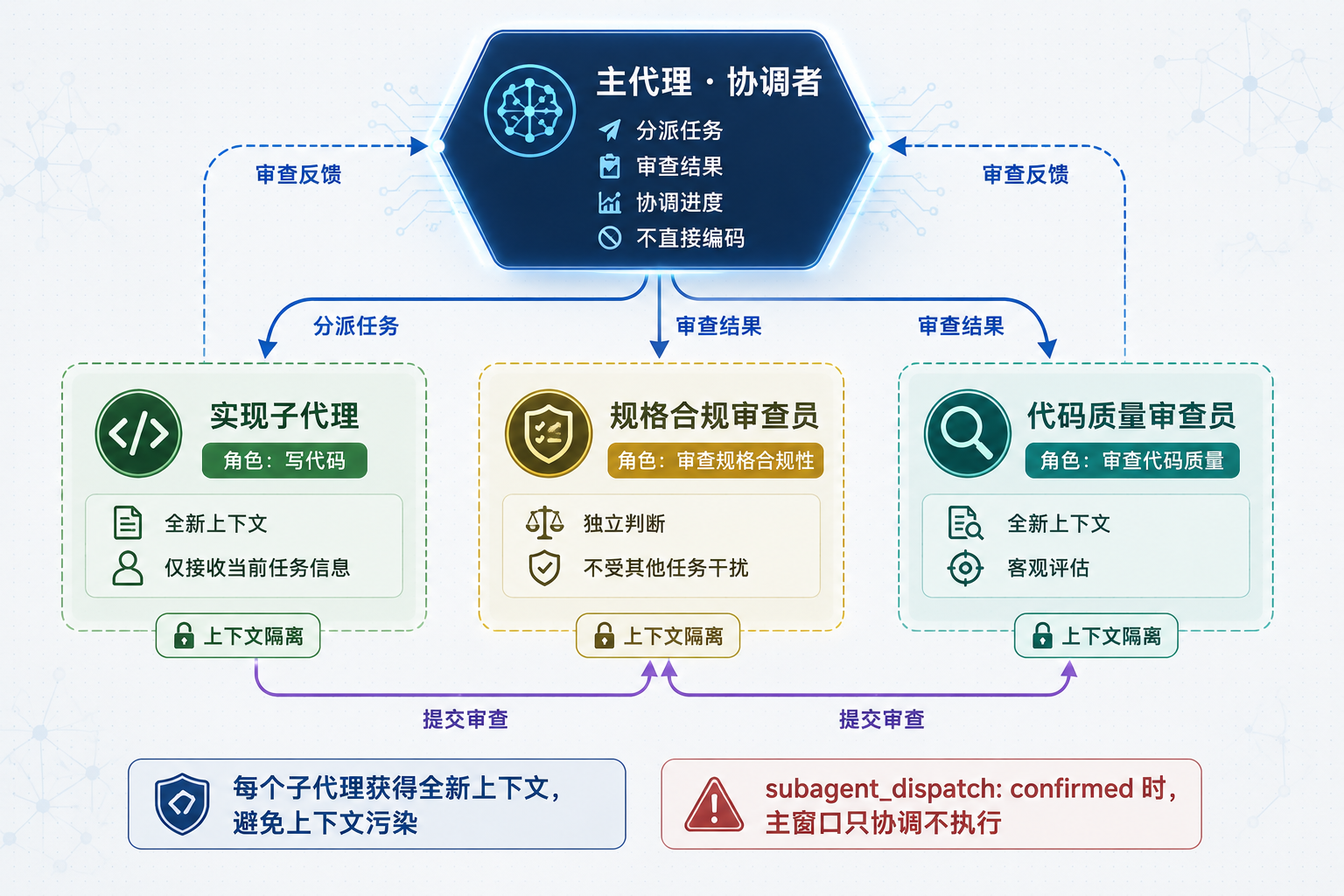
多代理协作架构图:主代理协调 + 子代理上下文隔离
图 4:多代理协作架构图
8. 工程取舍:为什么用 Shell + YAML
看完上面的分析,你可能会问:为什么不直接用 Node.js 写一个完整的后端?为什么要用 Shell 脚本和 YAML 文件?
为什么用 YAML 而非数据库
.comet.yaml 选择简单 YAML 文件而不是数据库,有利有弊。
好处是零运行时依赖——不需要安装数据库,不需要启动服务,一个纯文本文件就是全部状态。Git 可以追踪它的每一次变更历史,AI 可以直接读取内容,不需要额外的查询接口。
代价是并发写入无保护。如果两个 Agent 同时写 .comet.yaml,后写的会覆盖先写的。不过在 AI 编程的场景下,并发写入的情况很少,通常一个时刻只有一个活跃的 Agent 在操作。
为什么用 Shell 脚本而非纯 Node.js
这个问题更有意思。Comet 的 CLI 是 TypeScript 写的,但核心逻辑全在 Shell 脚本里。
原因是 Shell 脚本可以直接调用 git、grep、awk、sha256sum 等系统工具,不需要 Node.js 运行时。AI 在执行 Shell 脚本时,可以理解每一行做什么,出了问题可以调试。
但代价是跨平台兼容性。GNU 和 BSD 的工具行为不一致,这是 Shell 脚本的经典陷阱。Comet 的 CLAUDE.md 记录了几个明确的约束:
- 禁止 sed -i(GNU/BSD 不兼容),用 awk 替代
- 必须兼容 sha256sum(GNU)和 shasum -a 256(BSD/macOS)
- 所有可选 grep 结果加 || true从 comet-state.sh 的 strip_inline_comment 函数可以看到,为了处理 YAML 行内注释(# 后面的内容),作者没有用 sed,而是写了一个 20 多行的 awk 程序逐字符解析。这就是跨平台兼容的代价。
为什么不修改底层 Skill
Comet 的 CLAUDE.md 写了一条硬规则:不能够直接修改 Superpowers 和 OpenSpec 的原始 Skill。
这是一个关注点分离的决策。好处是底层项目更新时 Comet 不受影响,用户可以单独使用任何一个项目。代价是 Comet 无法深度定制底层行为,只能通过编排规则来约束。
换句话说,Comet 能做的是决定什么时候调用哪个 Skill,在调用前后加什么校验,但不能改变 Skill 本身的内容。如果 Superpowers 的 TDD Skill 需要调整,你得去 Superpowers 的仓库改,而不是在 Comet 里改。
9. 可扩展性与演进方向
三个项目的平台覆盖范围差异明显:
项目 | 平台数 | 扩展方式 |
|---|---|---|
Superpowers | 8+ | 插件清单文件( |
OpenSpec | 26 |
|
Comet | 29 |
|
Comet 的 platforms.ts 是三个项目中最完善的平台抽象。每个 Platform 对象包含技能目录、检测路径、OpenSpec 工具 ID、规则文件配置、Hook 支持等十几个字段。新增一个平台只需要在数组里加一个对象。
OpenSpec 的 Schema 也支持自定义扩展。除了默认的 spec-driven schema,你可以定义自己的制品依赖图:
# openspec/schemas/research-first/schema.yaml
name: research-first
artifacts:
- id: research
generates: research.md
requires: []
- id: proposal
generates: proposal.md
requires: [research]这个示例在 proposal 之前加了一个 research 阶段,适合需要前期调研的项目。
从版本迭代来看,几个明显的演进趋势:
Comet 0.3.7+ 引入了 CodeGraph 语义索引,据 README 数据,成本降低 16%,工具调用减少 58%。上下文压缩处于 Beta 阶段。auto_transition 配置项让阶段过渡可以自动执行而不需要手动触发。hotfix 和 tweak 预设工作流为小改动提供了快捷路径,跳过完整的设计阶段。
这些变化指向同一个方向:减少手动操作,增加自动化,同时保持工程纪律不被绕过。
总结
拆完三个项目的源码,有一个感受比较深:AI 编程的核心瓶颈不在模型能力,而在工程纪律。
Superpowers 用 Markdown Skill 给 AI 加方法论纪律,OpenSpec 用文件系统给需求加规格纪律,Comet 用 YAML 状态机给流程加阶段纪律。三个项目都没有依赖复杂的基础设施,核心载体就是 Markdown 文件、YAML 配置和 Shell 脚本。
如果你正在用 AI 编程工具做项目级开发(而不是写个脚本就完事),这套工具链值得研究。不是说非得全装上,而是它的设计思路(把工程纪律固化成文件系统中的约束)对任何 AI 编程工作流都有参考价值。
建议从 OpenSpec 单独试用开始,感受规格驱动开发和 Delta Spec 的工作方式。如果你已经在用 Superpowers,可以直接叠加 Comet 看看五阶段流水线的效果。
如果你对 AI 编程的工程化有其他思路或实践,欢迎在评论区聊聊。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号