DeepSeek V3.1 到底更新了什么?我用完忍不住想说几句……

DeepSeek V3.1 到底更新了什么?我用完忍不住想说几句……

小机学AI大模型
发布于 2026-06-19 10:30:25
发布于 2026-06-19 10:30:25

图片
你好呀,我是小机,AIGC探索者,我是小机学AI,一个专注于输出 AI+ 提示词和AI大模型内容的学者,关注我一起进步。
大家好,小机又来分享AI了。
相信最近的DS更新的消息大家应该很多人也看过了。
前几天,DeepSeek 静悄悄地来了一次大版本更新,甚至我最近在小某书刷到很多的也都是在说这事的,不过大多都是在问:R1什么时候回来?

作为本身就常用DS的人,我也去问了一下DS,然后DS给了我如下回答:
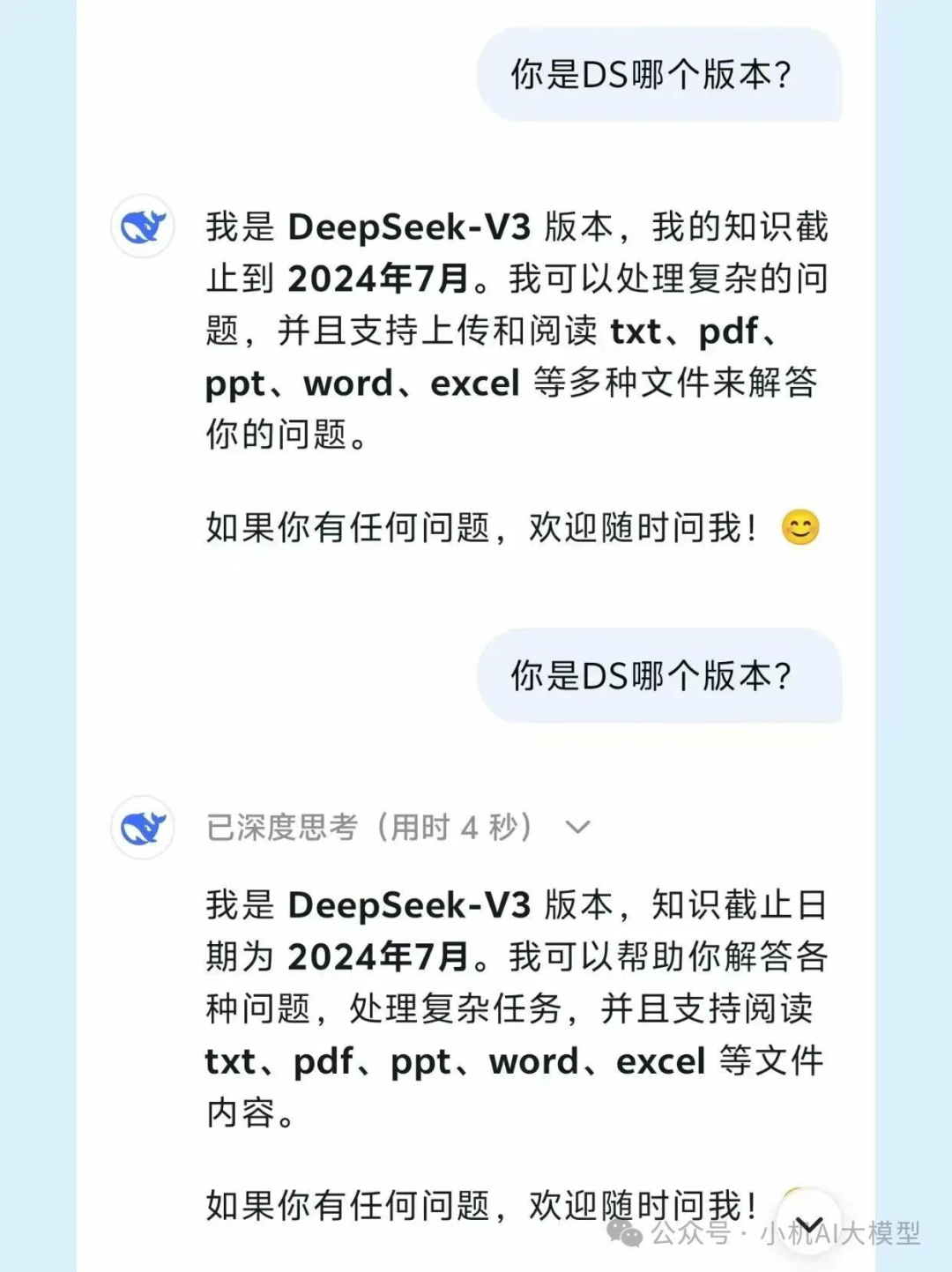
甚至当我问它是R1的时候,它还回复,不知道R1是谁?
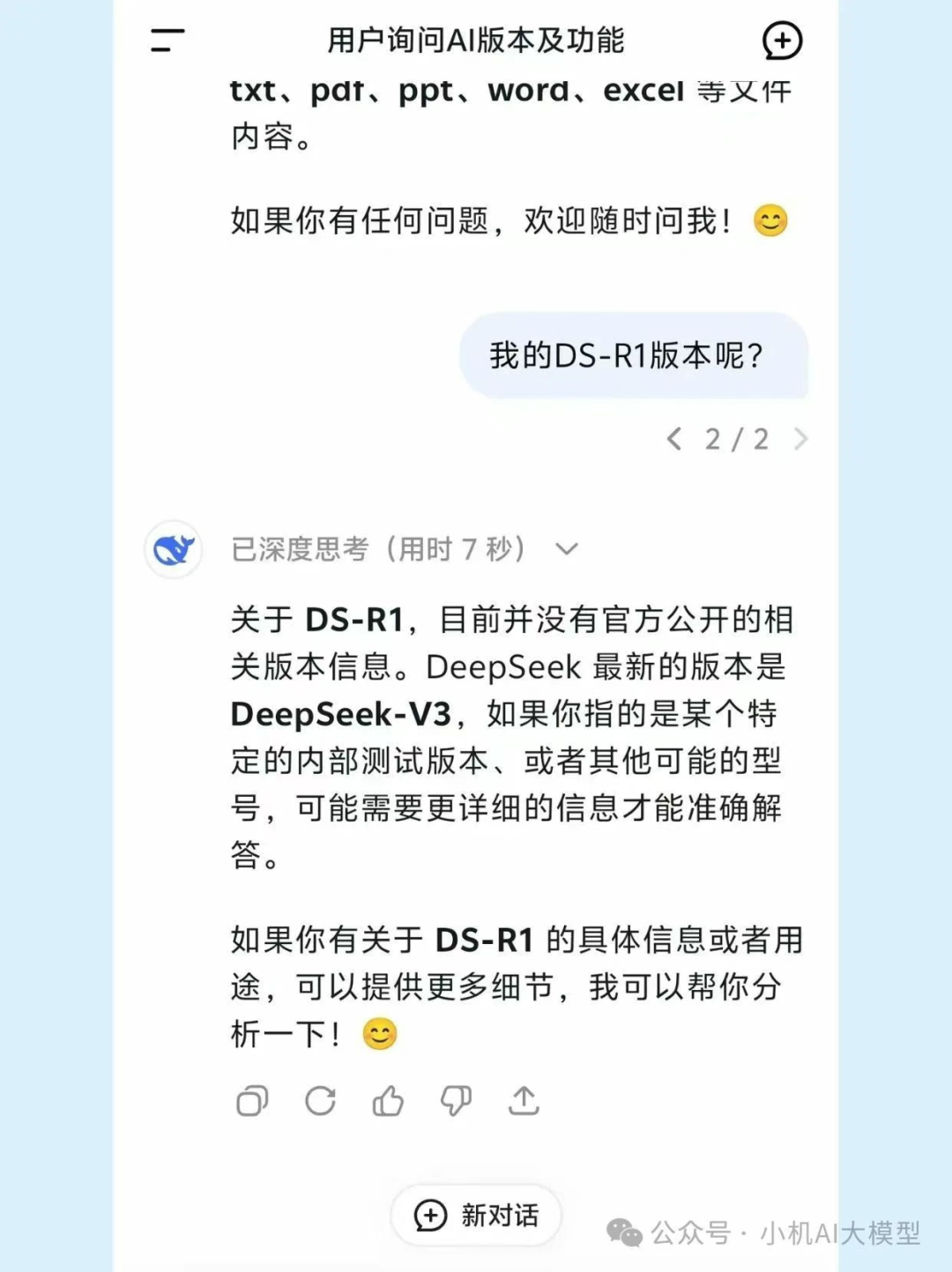
当我分享这个消息到群里的时候,一位uu,直接锐评:
“有的AI活着,但是他却已经死了”。
颇有一种GPT5之前的行为,强制下线GPT4o,也不管用户愿不愿意。
当然,虽然说R1不见了,让我很懵逼,但是知道DS更新了什么还是很有必要的,于是我直接就开始了测评之路。
诶,你还真别说,这一趟下来,我还真发现点很多普通用户根本没注意到的"隐藏玩法"。
一、首先就是128的上下文长度

当然,V3.1 其实之前就开放了128K上下文长度。但如果你是从 V3 就开始用的老用户,应该早就知道:DeepSeek 的模型底层本来就支持128K。
之前官网和API只开放64K,主要是出于成本控制。包括火山引擎、SiliconFlow 这些第三方平台,其实早就能调用128K了。
至于为什么放出来,我猜测可能和最近梁文锋得到了最加论文奖那篇文章有关:

当然,这次官方全面开放128K,更像是一次“功能解锁”,算不上技术突破。
那真正的更新亮点是啥?
是 模型融合。
二、什么是模型融合?
简单来说,DeepSeek 这次把之前的对话模型(V3)和推理模型(R1)合二为一了。你现在用的 V3.1,是“一个身体,两个灵魂”——既能聊天,也能深度推理。
最明显的信号是: 不管你是在网页端开“深度思考”模式,还是调用原本 deepseek-reasoner 的API,模型都会坚定地说:“我是 DeepSeek-V3”。
也就是我最开始前面和DS的对话。
听说有技术大佬对比了 V3.1 和 V3 的配置文件,发现 V3.1 新增了几个特殊 token:
<think>:推理开始</think>:推理结束<|search_begin|>:搜索开始<|search_end|>:搜索结束
这意味着,V3.1 从模型结构层面就支持了“思维链”推理。不再需要单独调用一个“推理大脑”,一个模型就能完成对话、思考、搜索、调用工具等一系列操作。
是不是听起来很耳熟?没错,这路线很像之前Qwen想做的“全能模型”,也符合GPT-5提出的融合方向。
大厂们都在试图解决同一个问题:维护多套模型太贵太麻烦。如果能合一,省资源又提效率。
此外,还有一点很重要的是,如何To Agent?
众所周知,Agent很重要的一个特点就是能直接调用不同的工具,而众多模型由于他们擅长的点不同,导致擅长的方向不同,而混合模型就解决了这个问题,可以直接根据不同场景使用不同的模型。
二、实测效果:有惊喜,也有老毛病
我第一时间拿 V3.1 跑了一些测试。说几个直观感受:
✅ 做得好的地方:
比如我让它: “生成一个骑自行车的鹦鹉的SVG图像”
它不仅生成了SVG代码,还主动包了一个完整HTML页面,甚至加上了标题和样式——看得出来,是想让输出更“完整可用”。
这种“多走一步”的细节,其实对普通用户更友好。
❌ 依然存在的问题:
但老问题也没完全解决:
- 幻觉仍在:尤其在生成长文本或复杂逻辑内容时,还是会出现“一本正经胡说八道”;
- 中英文混杂:比如回答中突然插入英文术语,虽然技术人员能看懂,但对小白不太友好;
- 稳定性波动:有时候回答极好,有时候又退回“普通助理”水平,发挥不稳定。
三、吐槽最多的是:更新方式太“硬核”
如果说技术上的尝试还可以理解,那DeepSeek的更新策略真是让很多开发者和企业用户头疼。
他们采用覆盖式更新——只要发新版本,旧版API就直接停用,不保留任何历史版本。
对比一下,OpenAI 到现在还维护着 GPT-4o 多个版本(如0513、0806),就是为了保证线上业务稳定。
而 DeepSeek 这种“一刀切”的做法,相当于告诉企业用户:“你别依赖我,我随时变。”
果然,HuggingFace、Reddit、HN 上已经炸锅了:
“我是API用户,昨天还用得好好的,今天生成质量突然下降,一看才知道是被强制升级了!” “为什么不能像其他公司那样让用户自己选版本?” “V3.1在写作方面退步明显,我只想用回 V3-0324……”
像极了之前的GPT:
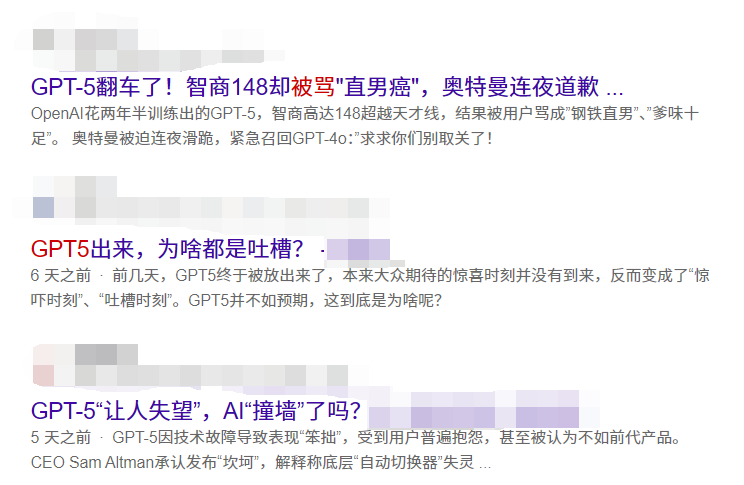
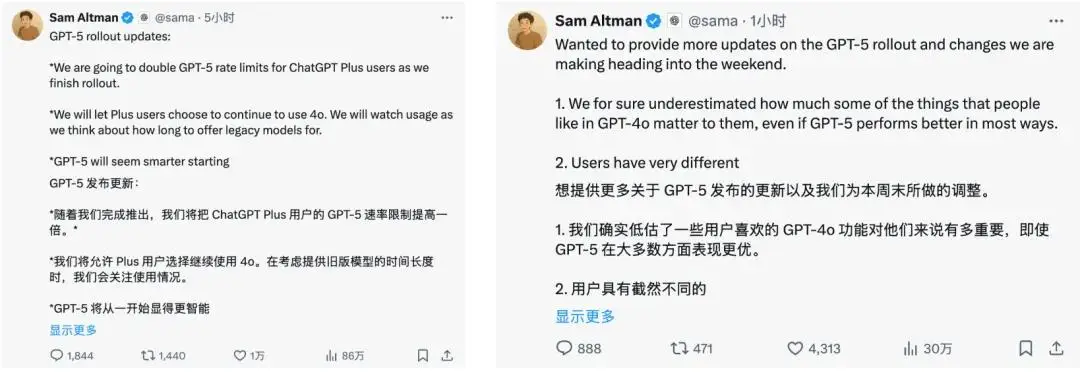
至于会不会回退R1,不好说。
四、总结:V3.1 值得一试,但别盲目上生产
如果你是个普通用户,或者刚接触AI,DeepSeek V3.1 依然是一个免费、强大且值得尝试的工具。128K上下文能处理更长的文档,融合模型也更方便你进行多轮复杂任务。
但如果你是企业用户,或者正在开发AI应用,建议:
- 先充分测试,别急着替换线上流程;
- 做好版本兼容和心理准备——DeepSeek 更迭很激进;
- 如果有稳定需求,可以考虑同时接入多个模型API做备选。
五、写在最后
AI世界变化太快,几乎每个月都有大模型更新。我们既要保持好奇去尝试新东西,也要脚踏实地做好备份和预案。
DeepSeek 这次融合尝试,不管成败,都是一次有价值的探索。也许未来的AI模型真的就是“一个模型,全能搞定”。
你怎么看 V3.1?欢迎在评论区聊聊你的使用体验~
图片
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号