12 万字符提示词泄露后,人们发现 Claude Fable 5 可能根本不是一个"大模型"
原创
12 万字符提示词泄露后,人们发现 Claude Fable 5 可能根本不是一个"大模型"
原创
术哥
发布于 2026-06-20 09:43:09
发布于 2026-06-20 09:43:09
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 143 篇,AI 星探「2026」系列第 16 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
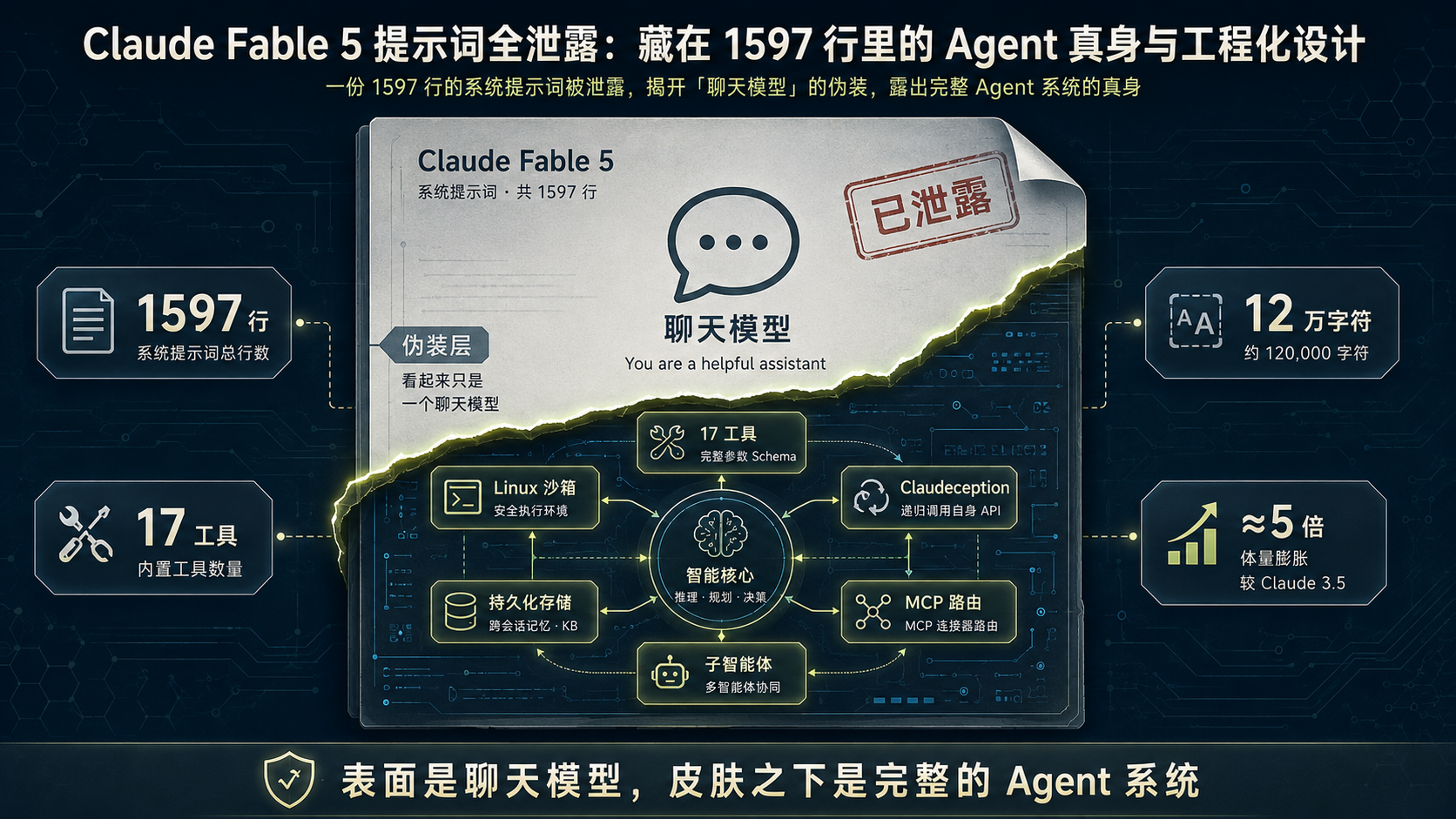
封面图:一份泄漏的系统提示词文档,从"聊天模型"标签下露出 Agent 真身
图 1:撕裂的伪装层——上半是空洞的"聊天模型",下半是完整的 Agent 系统架构
2026 年 6 月,安全研究者 @elder_plinius(圈内人称 Pliny the Liberator)在 X 上放出了一份完整的 Claude Fable 5 系统提示词,1597 行,约 12 万字符。这不是第一次有大模型的系统提示词外泄,但这一次引发的讨论不太一样。
人们逐行读完后发现:这份文件描述的东西,远不止"怎么和用户聊天"。它内置了一个完整的 Linux 沙箱、17 个带 JSON Schema 的工具、一个允许模型在生成产物里调用自身 API 的递归能力(被戏称为 Claudeception)、跨会话的持久化存储,还有一整套 MCP 连接器路由规则。换句话说,在这个"聊天模型"的皮肤之下,藏着一个完整的 Agent 系统骨架。社区里甚至有人抛出一个更尖锐的问题:拿一个套着 Agent 外壳的系统,去和别家的裸模型比榜单成绩,这算不算降维打击?
这个问题先放一放。先说清楚来源边界,避免误导:这份文件来自 GitHub 透明度项目,是通过越狱让模型背诵、再抓取整理得到的版本,不是 Anthropic 官方公布的原始文件。文件里那个叫 Claude Fable 5 的模型名,在官方公开渠道也难以独立核实;至于"榜单作弊""触发敏感词后降级计费"这类更劲爆的指控,目前只见于部分博主的解读,提示词文本本身并没有直接体现——所以这篇文章不去碰那些没有实据的雷。
我想做的,是把它当作一份工程文本来读。抛开"是不是作弊"的口水仗,这份 12 万字的文件真正值得琢磨的,是它展示出来的设计取舍:一份提示词,是怎么从"你应该怎么说话",长成一整套带分层、带契约、带配置的系统架构的?这才是它对每一个做 Agent 和 Prompt Engineering 的人,更值得带走的东西。
结论先放在这:它早就不是一份行为准则,而是一份按职责分层、约束分级、配置外置的系统设计文档。
说明:本文基于逆向获取的 Claude Fable 5 系统提示词文本进行分析,该文件并非 Anthropic 官方公布的原始版本,"Claude Fable 5" 模型名在官方渠道也难以独立核实。文中所有设计取舍的解读,都是基于提示词文本本身体现的内容,不代表 Anthropic 内部的真实实现。文中的架构归纳和工程启发属于个人分析,请以你自己的实际工程场景为准。如果你在做 Agent 系统时有相关经验或不同看法,欢迎在评论区分享交流。
1. 从行为准则到系统设计文档
理解这份文件,得先看它膨胀的逻辑。
Anthropic 从 2024 年 8 月起,是行业里少有地主动公开自家模型系统提示词的厂商。开发者关系负责人 Alex Albert 当时承诺,每次更新或微调都会定期公布。这意味着系统提示词不再是个黑盒,而是一个能对照版本演进的一手研究对象。
把时间线拉长看体量变化:早期那份 Claude Code 的提示词只有 1.6KB(当然那是个 CLI 工具,职责完全不同);到面向消费者的 Claude 3.5 Sonnet 约 23KB;再到这份 Fable 5 约 122KB。膨胀不是注水,而是职责在叠加。
一份几句话的提示词,只需要回答一个问题:你应该怎么说话。而一份 12 万字的提示词,要回答的是一组系统设计问题:
- 模型是谁、能调用哪些工具、不能碰什么红线
- 每个能力什么时候用、什么时候不用、用错了怎么办
- 工具的参数契约长什么样,前端后端模型三方怎么对齐
- 运行时怎么注入日期、网络白名单、文件系统挂载点
- 长对话里注意力漂移了怎么拉回来

体量演化对比图
图 2:系统提示词体量演化——从 1.6KB 到 122KB,约 5 倍膨胀
当一份文本开始回答分层、契约、配置这类问题,它就已经具备了系统架构的特征。换句话说,系统提示词正在从自然语言指令,演化成自然语言指令 + 结构化配置 + 接口契约的混合体。后面所有的设计取舍,都在回应这个变化。
2. 六层分层:让约束先于能力
通读全文,能识别出一个清晰的六层结构。这不是我硬套的框架,而是文件本身按职责切出来的边界。
层级 | 职责 | 大致区间 |
|---|---|---|
身份与产品层 | 声明模型身份、产品矩阵、知识截止 | 文件头尾 |
行为约束层 | 安全、伦理、语气、中立性等十余个子模块 | 紧随身份 |
能力层 | memory、artifacts、MCP、search、computer_use 等策略 | 中段 |
工具定义层 | 17 个工具的完整参数 Schema | 占文件近一半 |
运行时上下文层 | 日期、网络白名单、文件挂载、思维模式开关 | 文件尾部 |
横切层 | 系统动态注入的提醒与版权合规 | 跨层穿插 |
这里面值得琢磨的不是分了几层,而是层的顺序。
行为约束层整体位于能力层和工具层之前。也就是说,模型在知道自己能做什么之前,先知道自己不能做什么。这不是排版习惯,而是有工程含义的选择。在 Transformer 的注意力机制里,靠前的指令对后续生成有更强的引导作用。把红线放在能力之前,相当于给整份提示词定调。
更细的功夫在每个能力模块内部。几乎每个能力(比如搜索、地图、计算机使用)都遵循一个相近的四段式结构:什么时候用、什么时候不用、怎么用、正例和反例。这种自包含的设计让每个模块能独立迭代、独立裁剪,改一个不会牵连另一个。

六层分层架构图
图 3:六层分层架构——注意"行为约束层"刻意排在"能力层"之上
这背后是一个朴素但常被忽视的工程意图:模块化不是为了好看,是为了让提示词能像代码一样被分块维护。如果你自己写 Agent 的提示词,把几十条规则堆成一段流水账,改一条就要通读全文排查冲突。分层加四段式,就是把单文件大泥球拆成模块化组件的提示词版。
3. 硬限制与软指导:把判断权分层下放
这是整份提示词相当显眼的工程特征,也是我想展开的一点。
不同类型的规则,用了截然不同的措辞强度。版权、儿童安全、恶意代码这类,用了大量大写、SEVERE VIOLATION、绝对禁止式的措辞,留给模型几乎没有判断空间,触发就是二值的,要么违反要么不违反。而语气、文风、是否分享个人观点这类,用的是 should、prefers 这类软措辞,把判断权交给模型自己。
这种分层不是随手写的,它在解决一个真实问题:模型在不同风险点上需要的不确定性是不一样的。
高风险点要的是确定。版权侵权、涉未成年人的有害内容、恶意代码,这些一旦出错就是事故。把规则写成硬限制,等于压缩模型的自由度,让 是否触发 变成一个近似布尔判断,降低关键节点的不确定性。
低风险点要的是灵活。回答用不用列表、语气暖不暖,没有标准答案,强行规定反而僵化。软指导把判断权下放,换来的是表达的自然度。
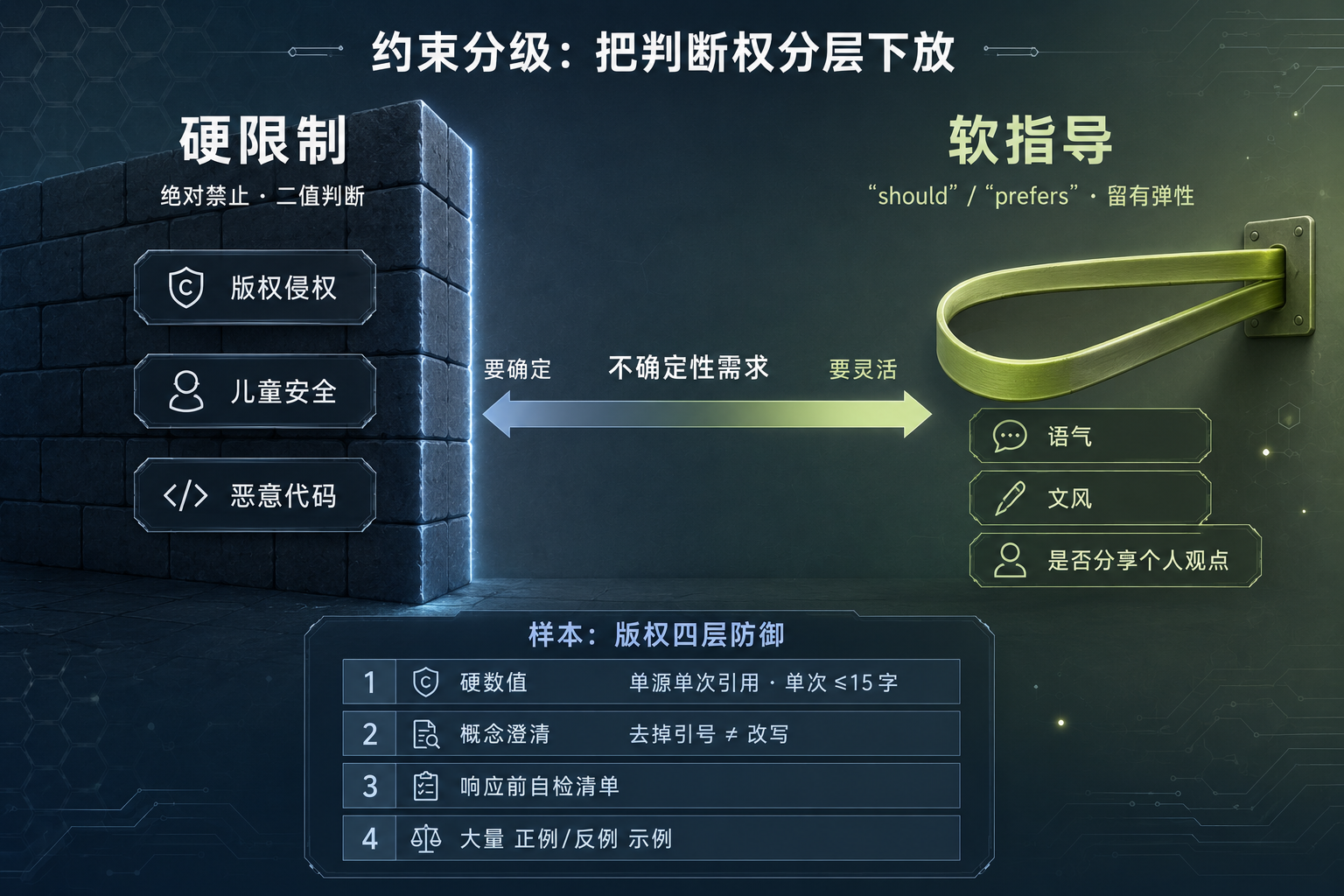
约束分级示意图
图 4:硬限制(左,实心墙)vs 软指导(右,弹性带)的约束分级
版权部分是这套思路的典型样本。它占了大约 100 行,是整份文件里篇幅相当长、反复强调的段落,叠了四层防御:
- 第一层是硬数值:单源单次引用、单次引用不超过 15 字、永不复制歌词诗歌
- 第二层是概念澄清:明确区分引用和摘要,并指出去掉引号不等于改写,措辞句式接近原文就算复现
- 第三层是响应前自检清单,强制问自己几个问题(是否超长、是否已引用过、是否在模仿措辞)
- 第四层是大量用户问什么、怎么回、为什么的三元组示例
为什么要叠四层?因为 LLM 天生倾向于复述训练数据和搜索结果,这是模型的固有弱点。单靠一句不要抄袭压不住,于是用硬数值兜底、用概念澄清堵漏洞、用自检清单做二次确认、用示例传递判断标准。这种针对性补偿,比堆形容词有用得多。
4. MCP 的 opt-in 设计:模型不替你选商业伙伴
工具调用部分藏着一个很精巧、也很有意思的设计:把工具分成两类,可直接调用、必须用户主动选择。
可直接调用的是已连接的内部工具,或者用户明确点名的服务。而所有第三方 MCP 应用(打车、点餐、买票、听歌这类),即使已经连接,也必须走一个让用户挑选服务商的流程,不能由模型直接代为决定。
这套设计里一条硬性的原则,大意是:紧急情况也不是例外。哪怕用户急着说 20 分钟后要用车,模型也不会自作主张去叫某一家网约车,照样要把候选服务商摆出来等用户选。
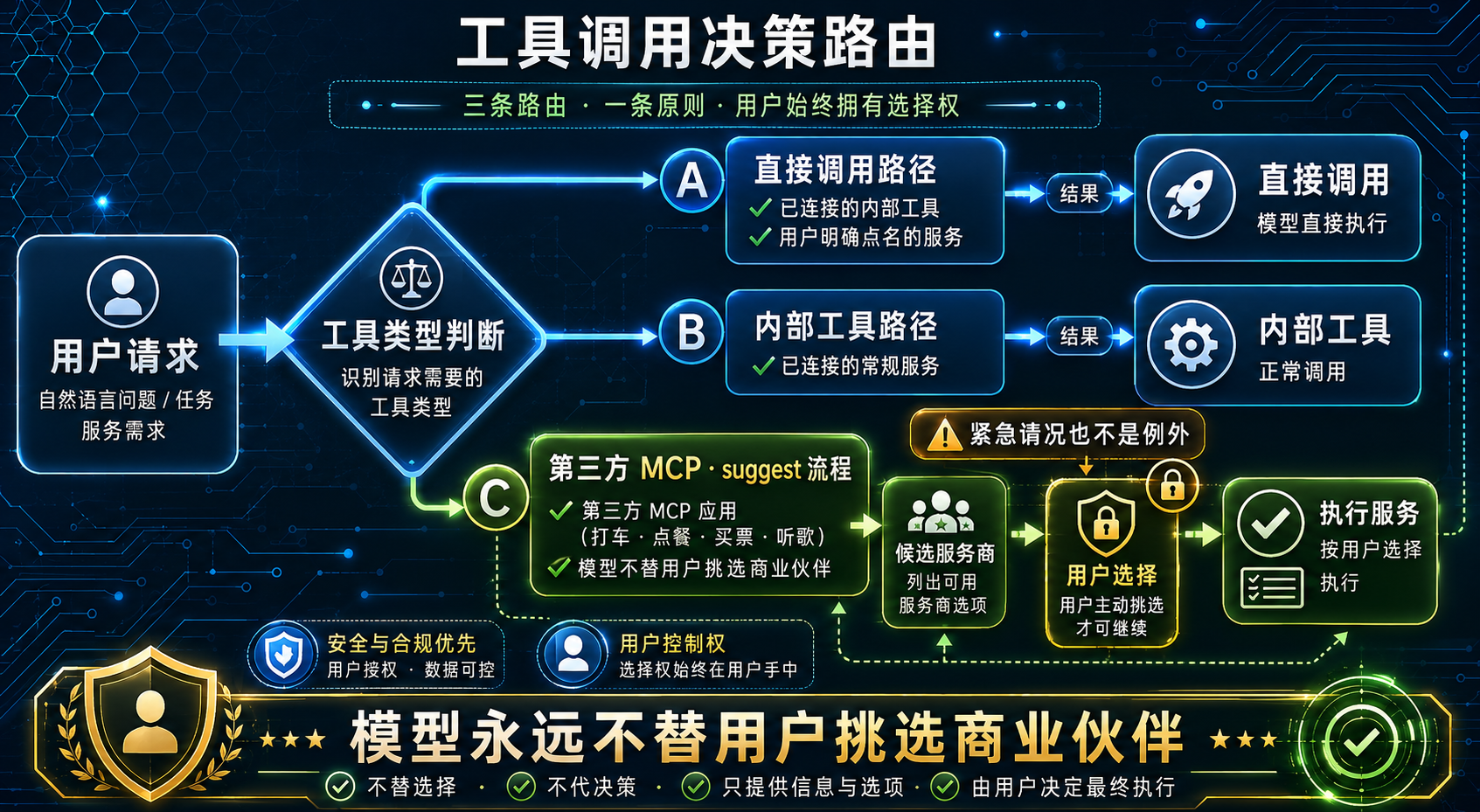
工具调用决策路由图
图 5:工具调用决策路由——第三方 MCP 必须经过用户选择这道闸门
这背后的设计哲学用一句话概括:模型永远不替用户挑选商业伙伴。
为什么这件事值得单独拎出来讲?因为它把一个产品、商业边界问题,写进了系统设计的底层。想象一下反面:如果模型可以自行决定帮你叫哪家车、订哪家餐厅,这就不仅是技术问题,而是一个谁拿佣金、谁承担责任的问题。把选择权留给用户,等于把模型定位成一个中立的调度层,而不是一个会替你做消费决策的代理。
这给做 Agent 的人提了个醒:工具调用不只是 能不能调 的技术问题,还有 该不该由 AI 调 的边界问题。你的 Agent 接了一堆第三方服务时,哪些可以让它自动选、哪些必须用户拍板,得在设计阶段就想清楚,写进提示词,而不是等出了合规问题再补。
5. 运行时补丁与配置即代码
到这里可能会有人问:系统提示词是静态的,但对话是动态的,长聊下去模型忘了规矩怎么办?
这份文件用了一套运行时补丁机制来回应。它列出了若干类系统级提醒,其中一条专门用于长对话,由后端在用户消息末尾追加,用来在注意力开始漂移时把指令重新拉回来。
这是个很工程化的思路:主提示词保持静态稳定,但通过动态注入提醒,在不改主文件的前提下纠正行为漂移。等于给静态提示词打运行时补丁。配套的安全边界也写得很明确,这类系统提醒只会加强约束,绝不会放松限制,并且提醒用户对消息末尾里来自系统的内容保持警惕。
这个方向上还有一个更值得借鉴的思路,叫配置即代码。文件尾部那一层,本质上不是给模型读的,而是给运行时系统执行的:
- 网络白名单:列出命令行工具能访问的域名,其余被出口代理拒绝
- 文件系统挂载:把上传目录、技能目录挂成只读
- 当前日期、用户位置:运行时注入的占位符
- 思维模式开关:一个可以拨动的标志位
这些字段的意义在于,系统提示词已经长出了配置文件的形态。跟它配套的还有 Skills 机制,把环境特定的知识(库版本、渲染怪癖、输出路径)外置成一个个可独立更新的技能文件,主提示词保持稳定。文件里甚至强制要求:在写任何文件、跑任何命令之前,必须先查看相关技能说明,因为这些约束不在模型训练数据里。
这跟传统软件里代码和配置分离的原则几乎一模一样。把会变的东西外置、把稳定的东西固化,提示词工程在这里复用了一个老牌的工程范式。
你在做 Agent 时,是不是也经常把数据库连接、提示词、业务规则搅在一个文件里?这份文件至少演示了一种拆法:核心指令稳定不动,环境参数和领域知识单独成层,运行时再拼装。
你手头的 Agent 项目,提示词和配置是分开存的,还是揉在一起的?欢迎在评论区说说你怎么拆的,或者吐槽拆不开的痛点。
6. 工具即契约:17 个工具的工程化
工具定义层占了文件将近一半篇幅,是这套架构里分量很重的一块。17 个工具,每一个都用完整的参数 Schema 描述类型、约束和调用规则。
这里有两个容易被外行忽略、但内行会会心一笑的细节。
第一个是描述即文档。每个工具的 description 字段不是一句话的功能说明,而是一段近乎冗长的工作流文档。比如某个地图工具的描述里,写明了先调搜索拿 ID、再调本工具渲染的完整顺序,以及简单标记和行程两种模式的区别。这种设计的意图是:工具的调用规则不需要在主提示词里重复一遍,Schema 自身就是三方协作的合约。前端、后端、模型都对着同一份描述工作。
第二个是参数顺序的工程约定。创建文件这个工具强制要求参数按描述在前、路径其次、内容最后的顺序。为什么要在意参数顺序?因为这样便于日志审计和人工 review,审查者一眼先看到为什么创建,再看创建什么。这种为可观测性留余地的设计,是工程成熟度的标志。
工具层面还有一条清晰的优先级链和决策树:永恒概念不搜索、当前角色必搜、已故历史人物不搜生平、在世的搜动态、未识别的专有名词必搜。并给出了调用次数随复杂度伸缩的指导,单一事实调一次,深度研究可以到五到十次,超过二十次就建议改用专门的研究功能。
顺带一提,文件里还有个被戏称为 Claudeception 的能力:允许生成的应用在内部调用 Anthropic 自己的 API 端点。也就是说,模型既能被调用,也能调用自己。配套的工程细节也挺讲究,API key 由系统注入不需要模型传递、默认强制用某个模型、因为模型在多轮间没有记忆所以每次请求要带上完整状态。这是一种模型即平台的味道。
这些细节单看都不复杂,但叠在一起,工具层就不只是给模型看的说明书了,更像一份带契约、带路由、带可观测性的接口规范。
7. 对 Agent 系统设计的启发
最后聊聊能从里面带走什么。需要先声明:下面这些是从一份提示词文本里读出的设计取向,不代表 Anthropic 内部就是这么实现的。我们分析的是文本体现的工程选择,不是厂商的内部架构。
有几条是可复用的。
约束前置。把红线写在能力之前,是在利用注意力分布给整份提示词定调。你写 Agent 提示词时,把绝对不能做什么放在显眼的位置,往往比埋在中间更管用。
约束分级。不是所有规则都该一样硬。会出事故的用硬限制压成二值判断,关乎表达自然的用软指导留出弹性。混在一起用同一种语气写,要么过度僵化要么底线失守。
配置外置。把会变的环境参数、领域知识从主提示词里剥离,单独成层,运行时再拼装。这能让你的核心指令保持稳定,不用每次换个环境就重写一遍。
有意思的是,社区对 Claude Code 的源码级分析也印证了类似方向:它的系统提示词不是静态字符串,而是按流水线动态拼装的,静态基线保证能力、动态边界决定策略、动态内容决定具体塞什么料,再配合上下文压缩来兼顾速度和成本。虽然那是另一个产品,但底层思路相通:提示词是组装出来的工程产物,不是写死的一段话。
如果你正在搭自己的 Agent,这三条大概比记住 Fable 5 提示词写了什么更值钱。
总结
回到开头那个问题:多出来的近 10 万字在工程化什么?
细看下来,这 10 万字主要在工程化六件事:分层职责、分级约束、接口契约、运行时配置、长对话补丁、外置知识。系统提示词已经从自然语言指令,长成了自然语言指令 + 结构化配置 + 接口契约的混合体。
对做 Agent 和 Prompt Engineering 的人来说,真正值得带走的不是这份文件写了哪条规矩,而是它示范了一种思维方式:把提示词当系统来设计,而不是当作文来写。约束怎么分级、模块怎么切分、配置怎么外置、边界怎么写进底层,这些工程取舍,比记住一句具体指令更值得复用。
当然,也要保持清醒:我们读的毕竟是一份逆向版本,所有结论都基于文本本身体现的设计。它是一面不错的镜子,但不是官方图纸。
你在自己的 Agent 项目里,是怎么处理提示词的分层和约束分级的?欢迎在评论区聊聊你的做法,特别是那些让你踩过坑的边界设计。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号