决策树分类模型对葡萄酒数据的训练及预测

决策树分类模型对葡萄酒数据的训练及预测

Wangzy
发布于 2026-06-22 18:18:02
发布于 2026-06-22 18:18:02
一、决策树模型训练
1、选择训练数据集,这里选择直接用sklearn自带的葡萄酒数据
导入需要用到的python包
import pandas as pd
from sklearn import tree
from sklearn .tree import DecisionTreeClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import graphviz加载并查看sklearen自带的葡萄酒数据
wine = load_wine()加载后可以看到葡萄酒数据具体内容,一共有178条数据,13种特征类型 ,3种目标值。

查看具体数据:
pd.concat([pd.DataFrame(wine.data,columns=wine.feature_names),pd.DataFrame(wine.target)],axis=1)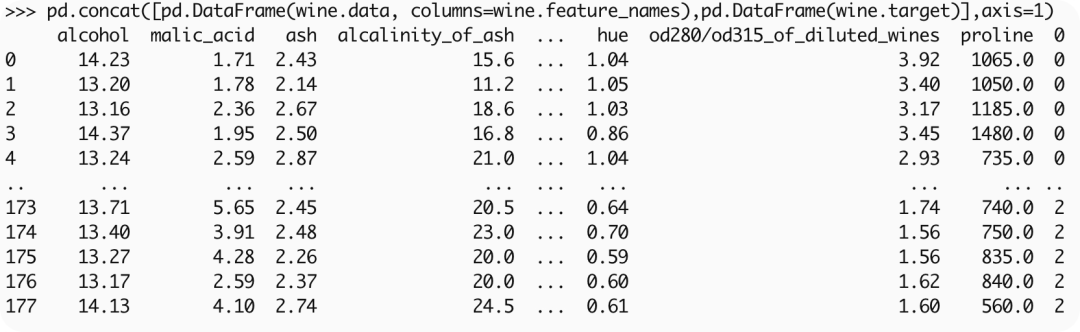
2、把数据集区分训练数据集和测试数据集,如下定义测试集占比30%,训练集占比70%。
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)3、建立决策分类树模型及训练模型
# 选择信息熵模式即ID3算法建立决策分类树模型
clf = DecisionTreeClassifier(criterion="entropy")# 用训练数据建立决策树
clf = clf.fit(Xtrain, Ytrain)# 用以上训练的决策树,给测试数据返回打分
score = clf.score(Xtest, Ytest)
4、通过graphviz工具把以上训练创建的决策树给画出来
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜 色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
dot_data = tree.export_graphviz(clf,out_file = None
,feature_names= feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True,rounded=True)
graph = graphviz.Source(dot_data)
graph.view()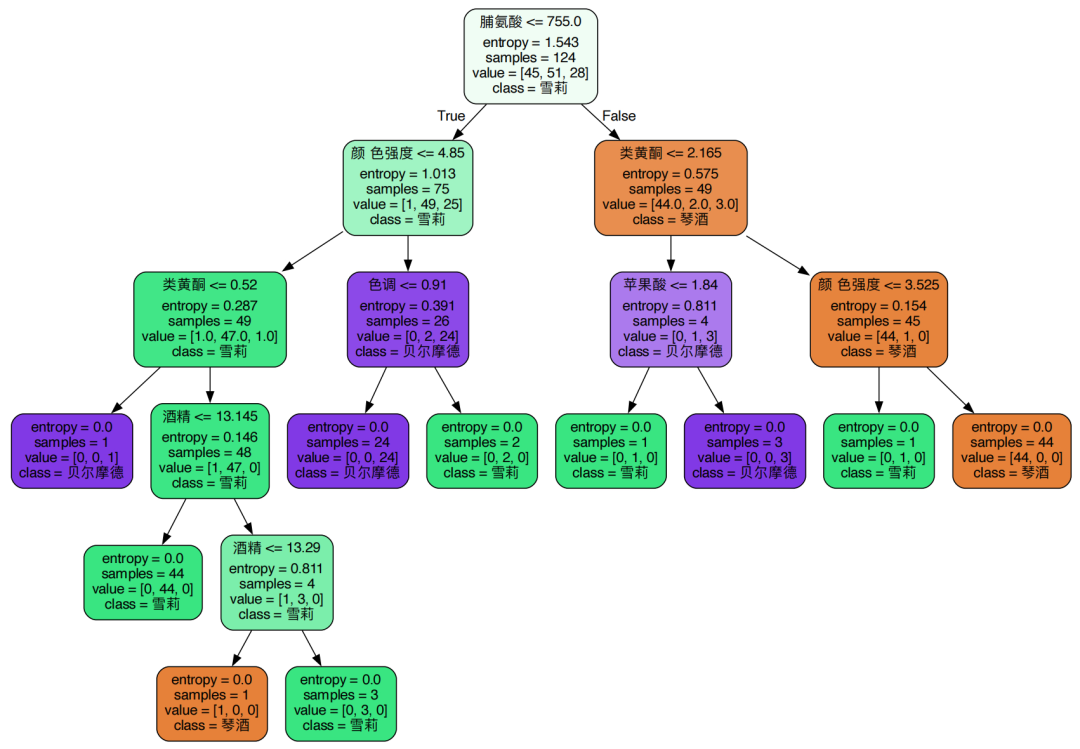
二、决策树模型微调
1、决策树分类树重要参数介绍(详见官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn.tree.DecisionTreeClassifier.fit)
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0, monotonic_cst=None)
2、splitter & random_state & max_features 随机相关参数调整
这三个参数deepseek推荐的组合参数如下,可能需要根据实际的数据集训练结果来微调最佳组合

3、剪枝相关参数调整
决策树模型是一个天生过拟合的模型,即它会在训练集上表现很好,在测试集上却表现糟糕。剪枝策略对决策树的影响巨大,正确的剪枝策略是优化决策树算法的核心。
剪枝参数有max_depth、min_samples_leaf、min_samples_split、max_features、min_impurity_decrease 等
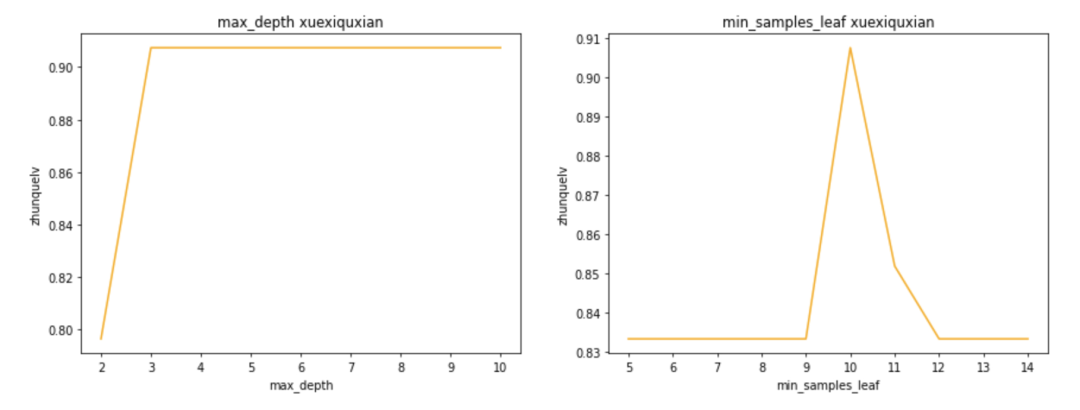
可以通过学习曲线的方式选择最佳剪枝参数。
超参数的学习曲线,是一条以超参数的取值为横坐标,模型的度量指标为纵坐标的曲 线,它是用来衡量不同超参数取值下模型的表现的线。
`` L = []
`` L1 = []
`` # 调节决策树最大深度
`` for i in range(2, 11):
`` dct = DecisionTreeClassifier(criterion='entropy'
`` , random_state=10
`` , splitter='random'
`` , max_depth=i
`` , min_samples_leaf=10
`` , min_samples_split=10)
`` dct.fit(Xtrain, Ytrain)
`` L.append([i, dct.score(Xtest, Ytest)])
`` # 调节一个节点在分枝后的每个子节点都必须包含的训练样本个数
`` for j in range(5,15):
`` dct1 = DecisionTreeClassifier(criterion='entropy'
`` , random_state=10
`` , splitter='random'
`` , max_depth=3
`` , min_samples_leaf=j
`` , min_samples_split=10)
`` dct1.fit(Xtrain, Ytrain)
`` L1.append([j, dct1.score(Xtest, Ytest)])
`` a = pd.DataFrame(L, columns = ['max_depth', 'zhunquelv'])
`` b = pd.DataFrame(L1, columns = ['min_samples_leaf', 'zhunquelv'])
`` A = [a, b]
`` plt.figure(figsize=(15, 5), dpi=70)
`` for k,v in enumerate(A):
`` plt.subplot(1,2,k+1)
`` plt.plot(v.iloc[:,0], v.zhunquelv, color='orange')
`` plt.xticks(v.iloc[:,0])
`` plt.xlabel(v.columns[0])
`` plt.ylabel('zhunquelv')
`` plt.title(f'{v.columns[0]}exuexiquxian');
`` plt.savefig('learning_curve.png', bbox_inches='tight')
如上代码输出学习曲线如下图,可见当max_depth=3时准确率最高,而min_samples_leaf=10时准确率最高。
再来看看当max_depth=3和min_samples_leaf=10时的决策树结构。
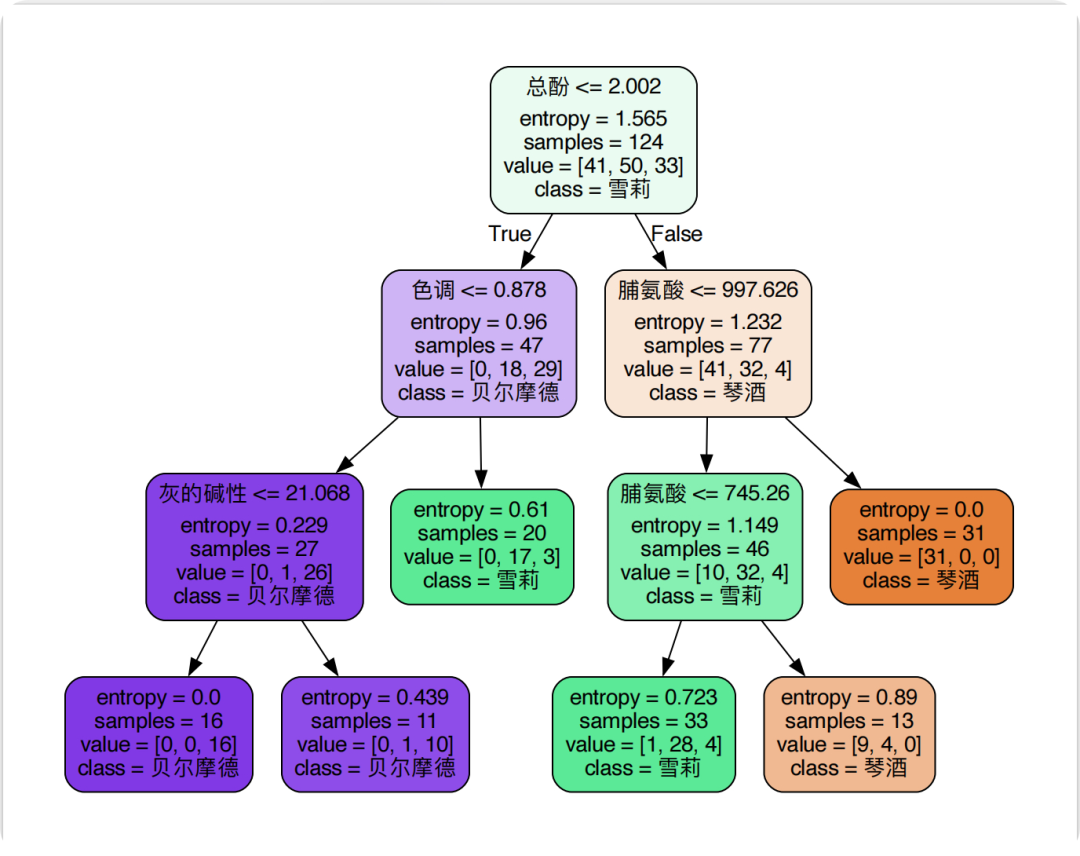
其余剪枝参数的调节同样可以使用学习曲线。可以先从max_depth开始调节,确定最佳参数后,再去调节其余参数,直至模型达到一个最佳状态停止。这样每次确定一个最佳参数是一种局部最优思想。
4、网格搜索选取最佳参数
一般而言,使用局部最优达到全局最优即能满足一般情况。如果更加严格的要求,可使用网格搜索选取最佳参数,但由于网格一样全局搜索最佳参数,计算量极大,较耗时。在求最佳参数而不关注训练时间的情况下,可选用网格搜索选取最佳参数。
网格搜索是一种通过穷举遍历所有预定义参数组合,并利用交叉验证评估每种组合性能,从而选取最佳超参数的方法。它的核心优势在于其全面性和确定性,能够在定义的网格上找到最优解。然而,其最大的代价是高昂的计算成本,尤其当参数空间维度高或取值密时。因此,它最适合计算资源充足、参数空间不大、且对找到网格内最优解有强烈需求的场景
三、训练后的决策树模型文件保存
`` # 通过pickle来保存训练后的模型文件
`` import pickle
`` with open('decision_tree_model.pkl', 'wb') as file:
`` pickle.dump(clf, file)四、加载训练的决策树模型文件,以及对新数据的预测
`` with open('decision_tree_model.pkl', 'rb') as file:
`` clf_loaded = pickle.load(file)
``
`` new_data = [[13.17,2.59,2.37,20,120,1.65,0.68,0.53,1.46,9.3,0.6,1.62,840]]
``
`` prediction = clf_loaded.predict(new_data)
`` print(f'预测类别:{prediction[0]}')
五、小结
如上文章是用决策树模型对葡萄酒数据进行分类的训练及预测的简单介绍,具体参数调优还需要根据具体数据集来详细测试,后续会根据实际的故障总结的特征及标签数据集,继续来做决策树分类模型训练及调优实战,敬请期待。
决策树的应用场景出了分类外,还有其他类型的应用,总结了下包括以下场景:
- 分类问题:决策树可以用于对数据进行分类,如判断一封邮件是垃圾邮件还是非垃圾邮件。
- 回归问题:决策树可以用于对数据进行回归分析,如根据房屋的特征预测房价。
- 特征选择:决策树可以用于选择最重要的特征,帮助我们了解数据的特征重要性。
- 异常检测:决策树可以用于检测异常数据,如判断信用卡交易是否存在欺诈行为。
- 决策分析:决策树可以用于辅助决策制定,如制定营销策略时根据不同特征预测不同用户的购买概率。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号