短剧出海译制一部要多久?四阶段并行把交付从几天压到小时级
原创
短剧出海译制一部要多久?四阶段并行把交付从几天压到小时级
原创
用户11938007
发布于 2026-06-22 18:28:20
发布于 2026-06-22 18:28:20
交付为什么慢?根本原因不是任何单一环节太慢,而是串行流水线——字幕提取完才开始翻译,翻译完才开始配音,配音完才开始擦除,每步等上一步,时间黑洞就这样形成的。
把长视频切片并行、各Agent异步协同,才能把"天"压到"小时"。
一、串行流水线的时间黑洞
传统短剧译制的流程结构如下:
字幕提取 → 翻译 → 配音 → 字幕擦除 → 导出
(逐步串行,每步完成后人工触发下一步)
串行结构的问题:
· 每步之间有等待时间(人工检查、文件传输、触发任务)
· 单视频处理完才能处理下一条
· 多语种需要多轮,不能并发
· 返工一步,后续全部重排
以100集剧为例,串行处理每集约需数十分钟,仅处理时间就超过一天,加上等待和传输,2-3天是起步价。
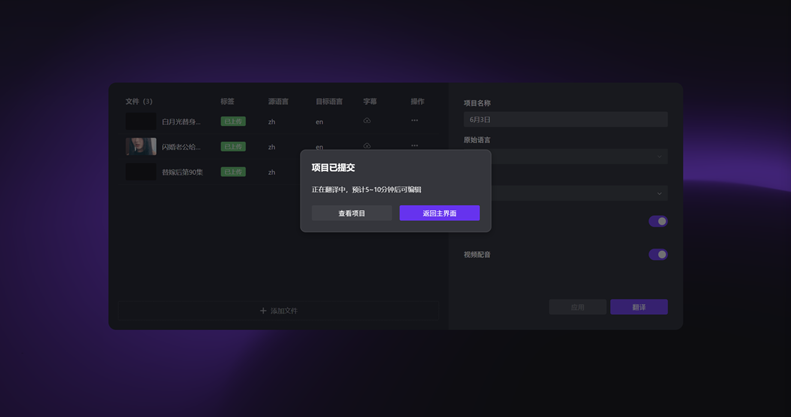
图1:翻译任务提交成功——分钟级进入可编辑状态,四阶段并行架构下字幕提取、翻译、配音同步推进,串行等待消失
二、四阶段并行架构
解耦异步协同的核心思路,是把四个独立阶段拆开并行执行:
阶段 | 功能 | 技术实现 |
|---|---|---|
阶段一:字幕提取 | 非OCR自动提取,1毫秒精度 | 独立ASR引擎,不依赖OCR |
阶段二:多语种翻译 | 翻译+翻译压缩,适配语言信息密度差 | 大模型翻译+语义压缩算法 |
阶段三:情绪配音 | 频谱情绪提取→大模型TTS | 端到端情绪识别+声音克隆 |
阶段四:字幕擦除 | AIGC视频修复,4K原画质重建 | 帧级修复算法,并行处理 |
这四个阶段在技术上是可解耦的:翻译不依赖配音的完成,擦除不依赖翻译的完成——这就为异步并行提供了基础条件。
三、关键技术:切片并行与分布式调度
长视频切片并行
一部100集的剧,单集分别进入处理队列,互不等待。系统维护任务调度队列,已完成集数自动推进到下一阶段,未完成的继续处理,不阻塞整体流程。
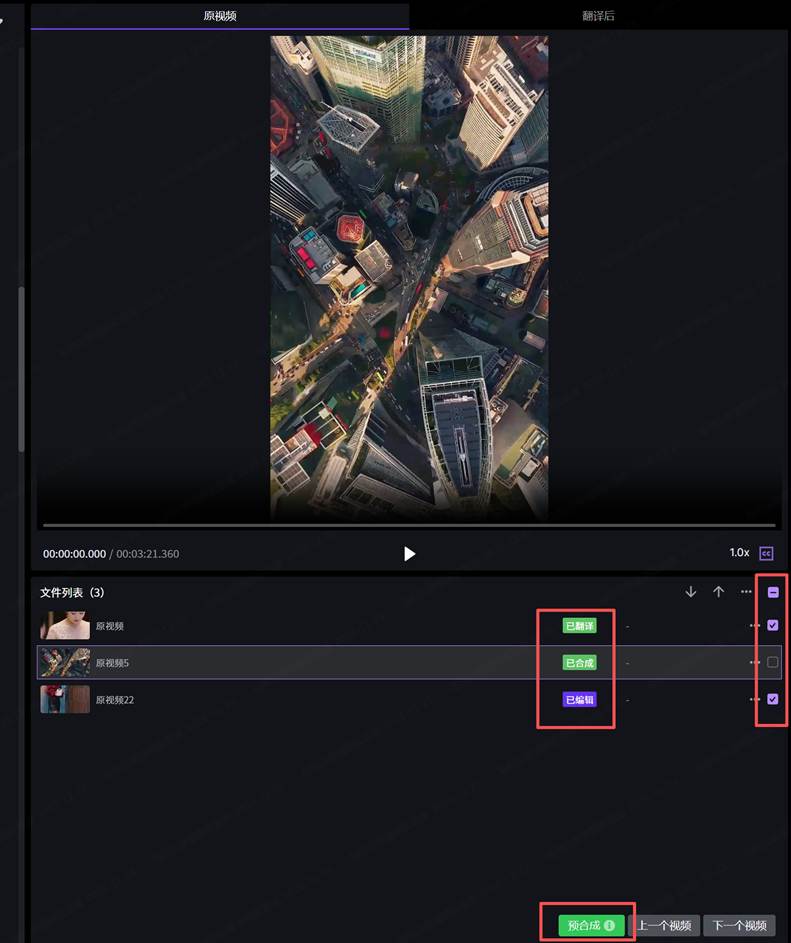
图2:文件列表「已翻译/已合成/已编辑」三色状态追踪——并行处理中每集独立进度可视化,100集同时运行互不阻塞
云原生分布式系统
基于云原生分布式架构,解耦异步协同,保证大规模并发任务稳定执行。并发处理能力仅受算力限制,可按需扩展。智马翻译实测日处理能力达100部短剧,且支持任意规模扩展。
多语种并发
单项目可支持最大200个文件的批量上传,多语种同步输出不需要逐语种单独跑,一次提交可同时产出25种目标语言版本。
四、效果验证:关键性能指标
以下为智马翻译实测性能数据:
指标 | 数值 |
|---|---|
全流程处理速度 | 约3分钟/分钟视频 |
字幕擦除速度 | 2分钟/分钟视频 |
单部剧最快完成 | 1小时(全流程) |
日处理能力 | 100部短剧(可扩展) |
单项目最大文件数 | 200个 |
系统可用性 | 99.999%(7×24小时) |
字幕识别率 | 99%(短剧场景) |
时间戳精度 | 1毫秒 |
对比传统串行人工方案,全流程交付时间可从2-3周压缩到小时级,核心变量是并行架构和分布式调度能力。

图3:时间轴多角色彩色分轨——毫秒级拖拽调整,音画同步的精度保障,四阶段并行中配音与字幕对齐的最终呈现
五、总结
短剧译制的交付速度本质上是架构问题。
· 串行等待是时间黑洞的根源,解法是任务解耦
· 切片并行是批量处理的前提,解法是云原生分布式
· 多语种并发是规模化出海的基础,解法是一次提交多语言输出
当这三个问题都被解决,从"几天"到"小时"不是目标,而是技术指标
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号