Java服务在K8s 中部署内存问题排查实战|Java Heap Dump(堆转储)

Java服务在K8s 中部署内存问题排查实战|Java Heap Dump(堆转储)

用户5741377
发布于 2026-06-22 21:51:36
发布于 2026-06-22 21:51:36
📌持续分享:云原生·Kubernetes·DevOps·AIOps·AI智能体等
欢迎查看更多历史文章👇👇
🔥一起学习云原生、AI等技术体系,持续提升架构与运维实战能力。
点击如下名片,即可关注公众号↓↓↓正文如下👇👇
Java 应用因其稳定性和企业级特性,被广泛部署在 Kubernetes(K8s)环境中。但这种组合也带来了独特的内存管理和排障挑战。
在 Kubernetes 中,由于容器内存限制与传统 JVM 堆内存计算方式存在差异,Java 内存问题的排查比物理机或虚拟机时代更加复杂。
虽然 Java 自带垃圾回收(GC)机制,但在容器化环境中,内存问题依然频繁发生。Java Heap Dump(堆转储)是 JVM 在某一时刻的内存快照,记录了堆中所有对象及其引用关系,是排查以下问题的关键手段:
- Pod 因 OOMKilled 被杀死
- 应用性能持续下降
- Java 内存泄漏
当 Pod 因内存限制被终止,或出现明显性能劣化时,开发和运维人员需要可靠的方式来采集并分析 Heap Dump。
本文将系统介绍 Kubernetes 环境下 Java Heap Dump 的多种采集方式、分析方法以及生产环境最佳实践。
K8s Pod Java Heap Dump 技术方式总览:
在运行中的 Pod 内执行 jmap -dump 命令,实时生成堆转储文件,适合现场排查问题Kubernetes 容器中的 Java 内存问题原理:
在 Kubernetes 中,Java 应用经常在启动后几分钟内以 exit code 137(OOMKilled) 退出,即使业务逻辑实际并不需要那么多内存。
还有一些场景中,应用并不会被杀死,但会出现:
- Full GC 频繁
- 响应时间明显变慢
- 内存持续处于高压状态
这些问题通常说明:
- JVM 堆配置不合理
- 存在内存泄漏
- 尚未触发容器内存上限,但已接近极限
核心矛盾:容器内存 vs JVM 堆计算方式
- 容器内存限制:由 Linux cgroups 控制,限制容器内所有进程可用的总内存
- JVM 传统行为:根据“宿主机总内存”来计算堆大小
如果 JVM 没有感知容器限制,就会发生严重问题。
典型错误示例(Legacy Java 场景):
Pod 内存限制:2GB Node 物理内存:32GB
如果 JVM 未开启容器感知:
- JVM 认为自己有 32GB
- 默认分配 25% 作为堆 → 8GB
- 启动即触发 OOMKilled
正确的容器化 JVM 配置(推荐)
java -XX:+UseContainerSupport \
-XX:MaxRAMPercentage=75.0 \
-XX:InitialRAMPercentage=50.0 \
-jar myapp.jar效果说明:
- 最大堆:1.5GB(2GB × 75%)
- 初始堆:1GB
- 剩余 500MB 用于:
- Metaspace
- Direct Memory
- JVM 自身
- OS 进程和缓冲区
⚠️ 除非排查兼容性问题,不要关闭
UseContainerSupport,否则会重新引入内存误判问题。
Java Heap Dump 采集方式详解:
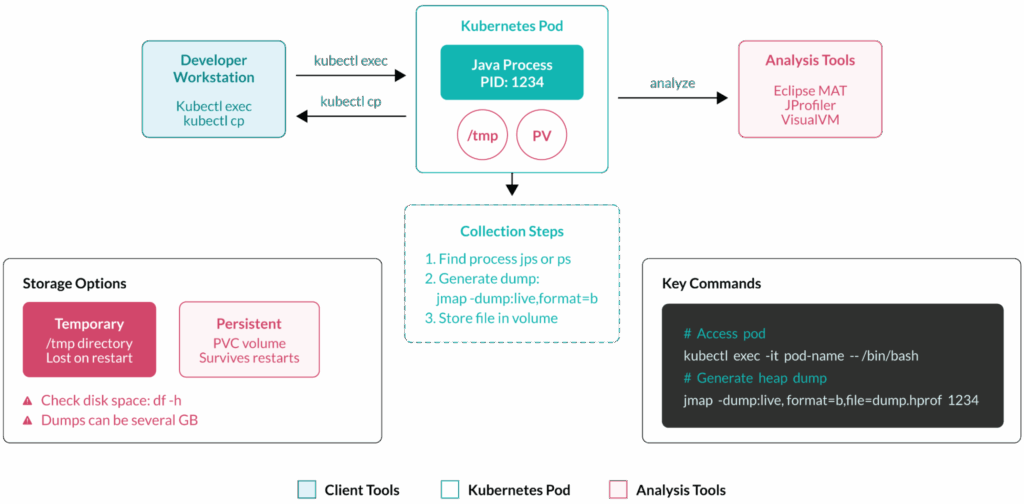
一、手动方式:jmap / jcmd
1️⃣ 进入 Pod
kubectl exec -it my-web-app-xxx -- /bin/bash2️⃣ 查找 Java 进程
jps -v
# 通常 PID 为 13️⃣ 生成 Heap Dump
jmap -dump:live,format=b,file=/tmp/heap.hprof 1live:只保留可达对象,Dump 体积减少 30%~50%- 1GB 堆 ≈ 400~600MB Dump 文件
jcmd 补充诊断:
jcmd 1 GC.class_histogram > /tmp/histogram.txt适合快速评估对象分布,避免直接生成大文件。
二、OOM 自动 Dump(生产推荐)
在 Deployment 中加入 JVM 参数:
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/heapdumps/
-XX:+ExitOnOutOfMemoryError结合 PVC 持久化 Dump 文件,避免 Pod 重启后丢失数据。
三、使用 CronJob 自动清理 Dump 文件
apiVersion: batch/v1
kind: CronJob
metadata:
name: heapdump-cleanup
spec:
schedule: "0 3 * * *"每天凌晨自动清理 30 天前的 .hprof 文件,防止磁盘被打爆。
四、代码级 Heap Dump(高级用法)
通过 JMX 暴露接口,支持远程触发:
hotspotMBean.dumpHeap(filename, true);⚠️ 生产环境必须限流,否则可能被误触发导致雪崩。
Heap Dump 分析思路:
常用工具
- Eclipse MAT(强烈推荐)
- JProfiler
- VisualVM
- jhat(命令行,能力有限)
重点关注指标
- Dominator Tree 中 Retained Heap > 10%
- GC Roots 引用链
- Full GC 频率与回收效果
Kubernetes 中的常见问题模式:
问题模式 | 原因 |
|---|---|
固定 -Xmx 大于容器限制 | 启动即 OOMKilled |
String 重复过多 | 环境变量、配置解析 |
Spring / Hibernate 对象未释放 | 框架使用不当 |
HashMap 扩容频繁 | 初始容量配置不合理 |
生产环境最佳实践总结:
- Heap Dump 会 STW(暂停所有线程)5~15 秒
- 建议:
- 低峰期采集
- 自动 + 手动组合
- 与 Readiness / 熔断机制配合
- 在 CI/CD 中验证 Dump 能力
- 配合资源自动调优(Rightsizing)
总结:
在 Kubernetes 中进行 Java Heap Dump 排查,既是 JVM 技术问题,也是云原生运维问题。
合理组合以下能力,才能真正解决问题:
- JVM 内存模型理解
- Kubernetes 资源限制设计
- Heap Dump 采集与分析
- 自动化与成本控制意识
Heap Dump 不只是排错工具,更是 Java 应用内存治理的重要数据来源。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-12,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 DevOps和k8s全栈技术 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号