OpenAI单个PostgreSQL支撑8亿用户,是神作还是妥协?

OpenAI单个PostgreSQL支撑8亿用户,是神作还是妥协?

用户11563501
发布于 2026-06-23 11:43:46
发布于 2026-06-23 11:43:46
OpenAI在官方博客里公布了一个数字:单个PostgreSQL主节点加上近50个副本,撑起了ChatGPT的8亿用户。

过去一年,OpenAI的PostgreSQL负载增长了超过10倍,但他们选择继续使用单主架构,而不是传统的分片方案。这个决策背后的细节,比表面看起来更复杂。
架构的真实边界
官方博客澄清了一个关键细节:并非所有数据都在PostgreSQL中。OpenAI明确表示,新功能需要的额外表必须放在Azure CosmosDB等分片系统中,而不是PostgreSQL。
他们已经将可分片的写密集型工作负载迁移到了分片系统,剩下那些难以分片但写入量大的工作负载正在逐步迁移中。这意味着PostgreSQL主要处理的是核心读写负载,而不是全部业务数据。
更重要的是,OpenAI承认他们不再允许在当前PostgreSQL部署中添加新表。新工作负载默认使用分片系统。这个限制说明单主架构确实有其边界。
工程优化的具体细节
OpenAI公开了他们如何将PostgreSQL推向极限的具体方法:
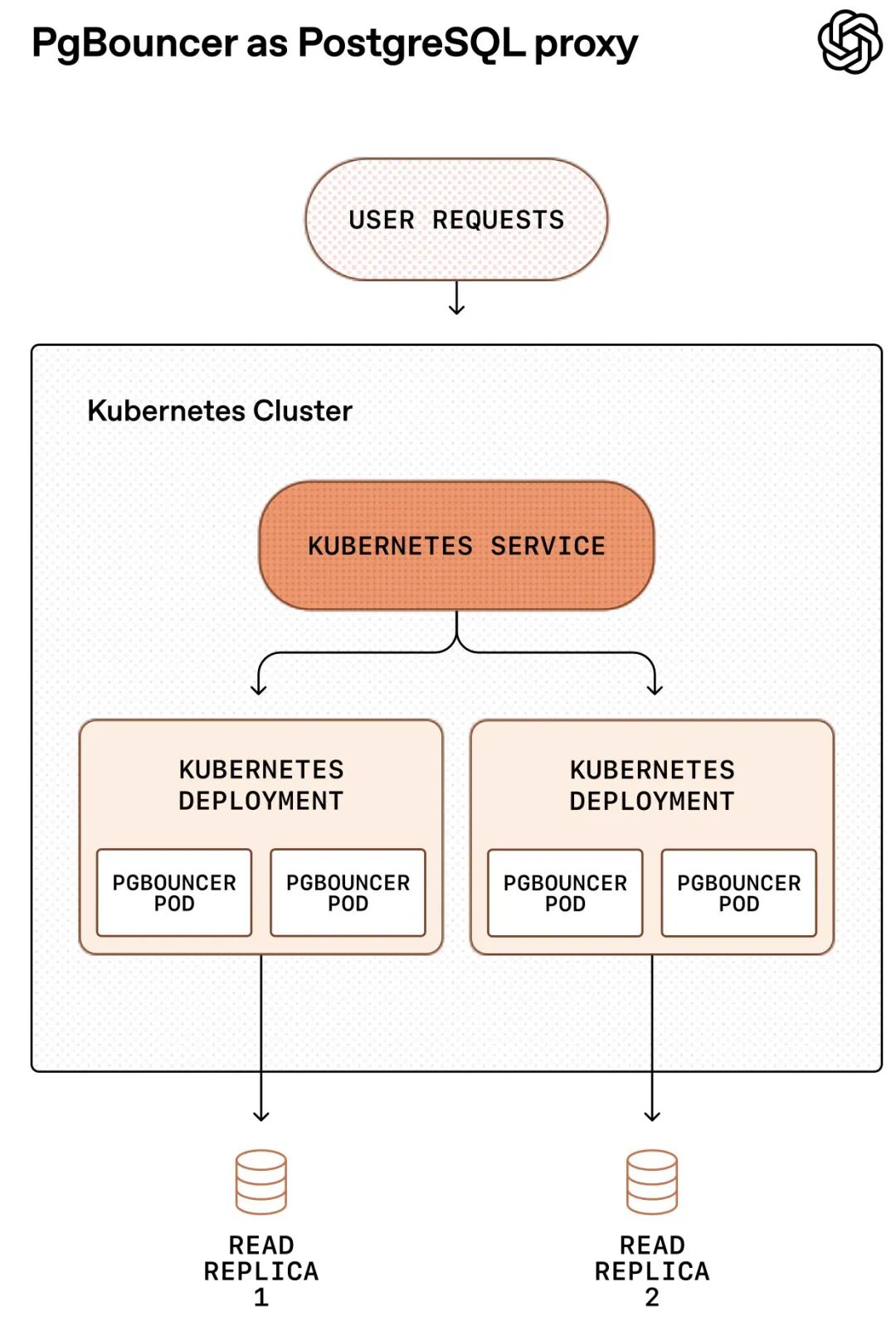
连接池优化:部署PgBouncer代理层,将平均连接时间从50毫秒降至5毫秒。Azure PostgreSQL的连接上限是5000,在语句或事务池化模式下,PgBouncer能高效复用连接,大幅减少活跃连接数。跨区域连接和请求开销很大,所以他们将代理、客户端和副本都部署在同一区域,最小化网络开销。PgBouncer的配置需要谨慎,特别是空闲超时设置,这对防止连接耗尽至关重要。
缓存锁定机制:当多个请求同时遇到缓存未命中时,只有一个请求获得锁去PostgreSQL获取数据,其他请求等待缓存更新。这个机制防止了缓存未命中风暴直接冲击数据库。当缓存命中率意外下降时,大量请求会同时打到PostgreSQL,消耗大量资源并拖慢服务。通过锁机制,只有一个请求去数据库取数据并更新缓存,其他请求等待缓存刷新,显著减少了冗余的数据库读取。
查询优化教训:他们发现了一个极其昂贵的12表连接查询,这个查询的流量峰值曾导致严重的SEV故障。现在他们避免复杂的多表连接,必要时将连接逻辑移到应用层。许多问题查询都是ORM框架生成的,所以仔细审查ORM产生的SQL并确保其行为符合预期很重要。他们还发现PostgreSQL中经常出现长时间运行的空闲查询,配置idle_in_transaction_session_timeout等超时参数对防止这些查询阻塞autovacuum至关重要。
工作负载隔离:为了解决"吵闹邻居"问题,他们将工作负载隔离到专用实例上。某些请求会消耗PostgreSQL实例上不成比例的资源,导致同一实例上其他工作负载性能下降。他们将请求分为低优先级和高优先级层级,路由到不同的实例。这样即使低优先级工作负载变得资源密集,也不会影响高优先级请求的性能。同样的策略也应用于不同产品和服务之间,确保一个产品的活动不会影响另一个产品的性能或可靠性。
多层限流策略:他们在应用层、连接池、代理和查询层实施了多层限流,防止突发流量压垮数据库实例并触发级联故障。避免过短的重试间隔很关键,这会触发重试风暴。他们还增强了ORM层以支持限流,必要时完全阻止特定的查询摘要。这种针对性的负载削减能够快速从昂贵查询的突发中恢复。
模式变更限制:即使是小的模式变更,比如修改列类型,也可能触发整表重写。因此他们对模式变更非常谨慎,只允许轻量级操作,避免任何会重写整表的变更。只允许轻量级模式变更,比如添加或删除不会触发整表重写的特定列。对模式变更强制执行严格的5秒超时。允许并发创建和删除索引。模式变更仅限于现有表,如果新功能需要额外表,必须放在Azure CosmosDB等替代分片系统中。回填表字段时,他们应用严格的速率限制防止写入峰值,虽然这个过程有时需要超过一周,但确保了稳定性,避免了生产影响。
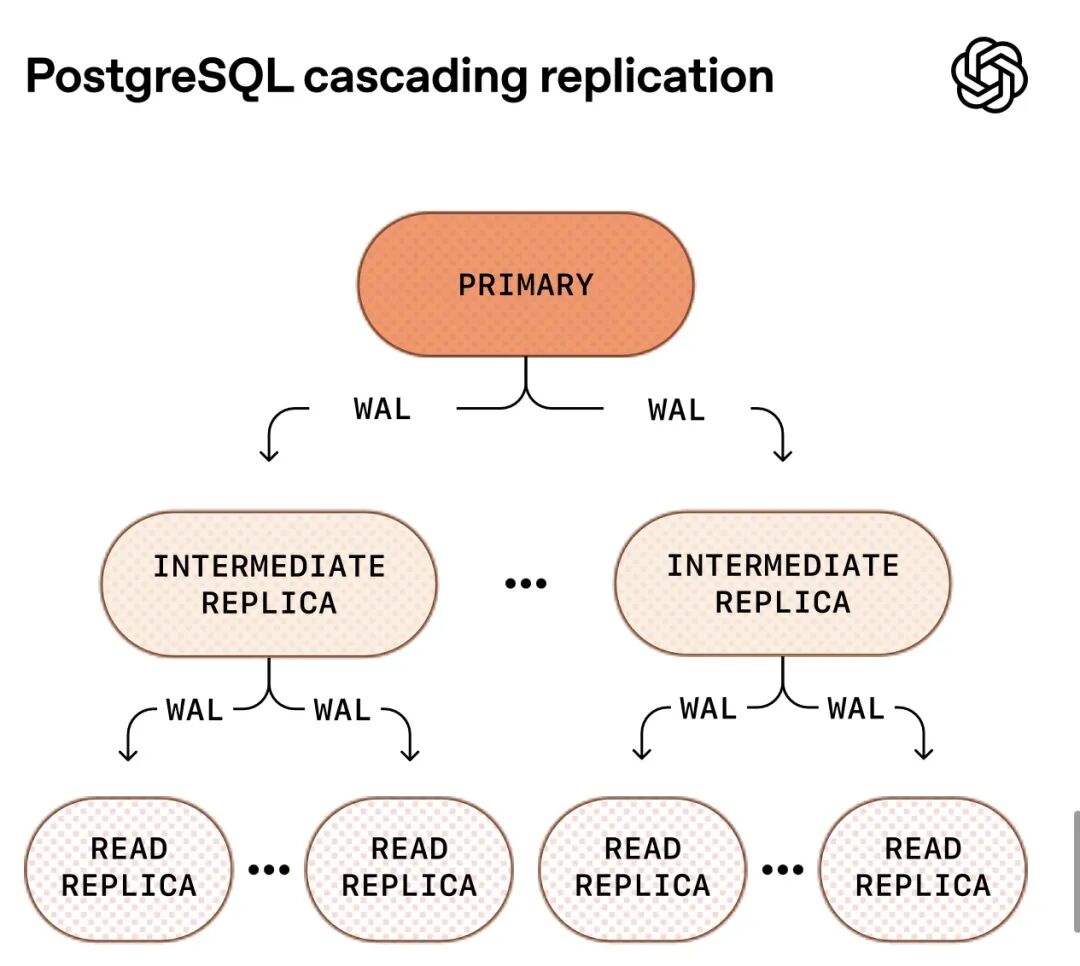
级联复制方案:正在与Azure PostgreSQL团队合作开发级联复制,让中间副本转发WAL日志给下游副本。虽然目前的架构在超大实例类型和高网络带宽下扩展良好,但不能无限制地添加副本而不最终压垮主节点。级联复制允许扩展到可能超过100个副本而不压垮主节点,但也引入了额外的运营复杂性,特别是故障转移管理。这个功能还在测试中,他们会确保其稳健性并能安全故障转移后才投入生产。
性能数据vs现实体验
OpenAI公布了具体的性能指标:处理数百万QPS的读密集型工作负载,客户端P99延迟保持在低两位数毫秒,生产环境达到五个九的可用性。
过去12个月,他们只遇到一次SEV-0 PostgreSQL故障,发生在ChatGPT ImageGen病毒式传播期间。当时一周内有1亿新用户注册,写入流量突然激增超过10倍,系统无法承受。
但用户的实际体验仍然存在问题。ChatGPT侧边栏加载时间较长,iOS用户经常需要重启应用才能看到回复。
技术债务的现实选择
OpenAI的案例证明,精心优化的传统关系型数据库仍能胜任大规模应用,同时也是不得已而为之的选择。
他们承认分片现有应用工作负载"会非常复杂和耗时,需要修改数百个应用端点,可能需要数月甚至数年时间"。由于工作负载主要是读密集型的,当前架构仍有足够增长空间。
OpenAI选择继续优化单主架构,而不是重构整个应用层。同时,他们并没有排除未来分片PostgreSQL的可能性,一切还是从场景需要出发。开发者们也没必要盲目跟风,从来没有绝对正确的架构,都是一种妥协的艺术。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号