Loop Engineering 如何降低大模型幻觉?三角色闭环讲清楚

Loop Engineering 如何降低大模型幻觉?三角色闭环讲清楚

AI 生命克劳德
发布于 2026-06-23 20:02:25
发布于 2026-06-23 20:02:25
Loop Engineering 从入门到进阶手册 · 第 4 篇 上一篇讲了 5 种 Loop 模式怎么选。 这一篇讲 Planner / Generator / Evaluator 三角色方法论,解决 Loop 的核心难题:Agent 写出来的东西,谁来审?Loop Engineering 不能让模型不出错,但可以降低幻觉进入最终交付结果的概率。
第三篇发出后,群里有人问了一个很好的问题:
Loop Engineering 能不能有效降低大模型幻觉?
我的回答是:可以降低。它降低的是幻觉进入最终交付结果的概率;模型本身仍然可能出错。
Agent 自审为什么不可靠
你有没有让 ChatGPT 或 Claude 检查过它自己写的代码?
结果通常是:
代码很好,逻辑清晰,没有明显问题。
但你自己看一遍,发现三个 bug、两个边界情况没处理、还有一个变量名拼错了。
这不是 Agent 在骗你。这是 LLM 的固有缺陷:确认偏误(Confirmation Bias)。
同一个模型,很难可靠地评估自己的输出。
它在生成时沿着一个思路走,在评估时又会沿着同一个思路回放。即使有错误,它也倾向于认为"这个方向是对的"。
这个问题在 Loop Engineering 中不是"偶尔发生"——它是系统性的质量天花板。
如果你的 Loop 里没有独立的评判者,那 Loop 跑得越快,错误扩散得越快。
Anthropic 的长周期 Agent Harness 和多 Agent 工程实践,也反复指向这个问题。
它能给这套方法论提供一个重要背书:把"干活的"和"评判的"分开。
两类会放大错误的失败模式
在讲三角色方法论之前,先看两个长任务里反复出现的失败模式。理解它们,你会更容易看到:独立评估是质量控制的基础。
失败模式一:上下文焦虑(Context Anxiety)
当模型在长任务中接近上下文窗口上限时,它会提前收工。
它并没有真的做完,只是"感觉"上下文快满了,于是选择在一个"看起来还行"的地方停下来。
有人可能会说:那用 Compaction(上下文压缩)不就行了?
Anthropic 的结论是:不够。
Compaction 做的是原位摘要——把历史信息压缩一下,腾出空间。但模型仍然背着"历史包袱"。它知道之前写过什么、犯过什么错,这些残留会影响它后续的判断。
更稳的处理方式是:Context Reset(上下文重置)。
清空当前上下文,通过结构化的交接 artifact(比如一份完整的进度报告)把必要信息传递给下一个实例。代价是编排复杂度和 token 开销增加,但质量显著提升。
失败模式二:自我评估偏误(Self-Evaluation Bias)
这个更隐蔽。
Agent 给自己的作品打高分——即使质量平庸。
在客观任务中(比如"测试通过了吗?"),这个问题不太明显,因为有二进制的 pass/fail 标准。
但在主观任务中(比如"这个 UI 设计好不好?"),问题极其严重。同一个 Agent 生成的设计,它自己评估时几乎总会给出"还不错"的结论。
这不是道德问题。是结构问题。
同一个模型,无法同时当好"创作者"和"批判者"。
就像让自己批改自己的考试,答题时形成的思维路径会影响判卷。
三角色闭环怎么跑
基于这两个失败模式,一个可靠的 Loop 可以拆成三类角色。Anthropic 的相关实践提供背书,但这篇重点讲可复用的工程分工。
三类角色分别负责定义目标、生成产出、独立验收。每个角色都有明确边界。
角色 | 职责 | 类比 |
|---|---|---|
Planner(规划器) | 把一句话需求展开成完整 product spec | 产品经理 / 架构师 |
Generator(生成器) | 基于 spec 形成执行 contract,并产出代码 | 工程师 |
Evaluator(评估器) | 对照 spec 和 contract,独立验证 Generator 的输出 | 质检员 |
这三者放在一起,流程大概是这样:
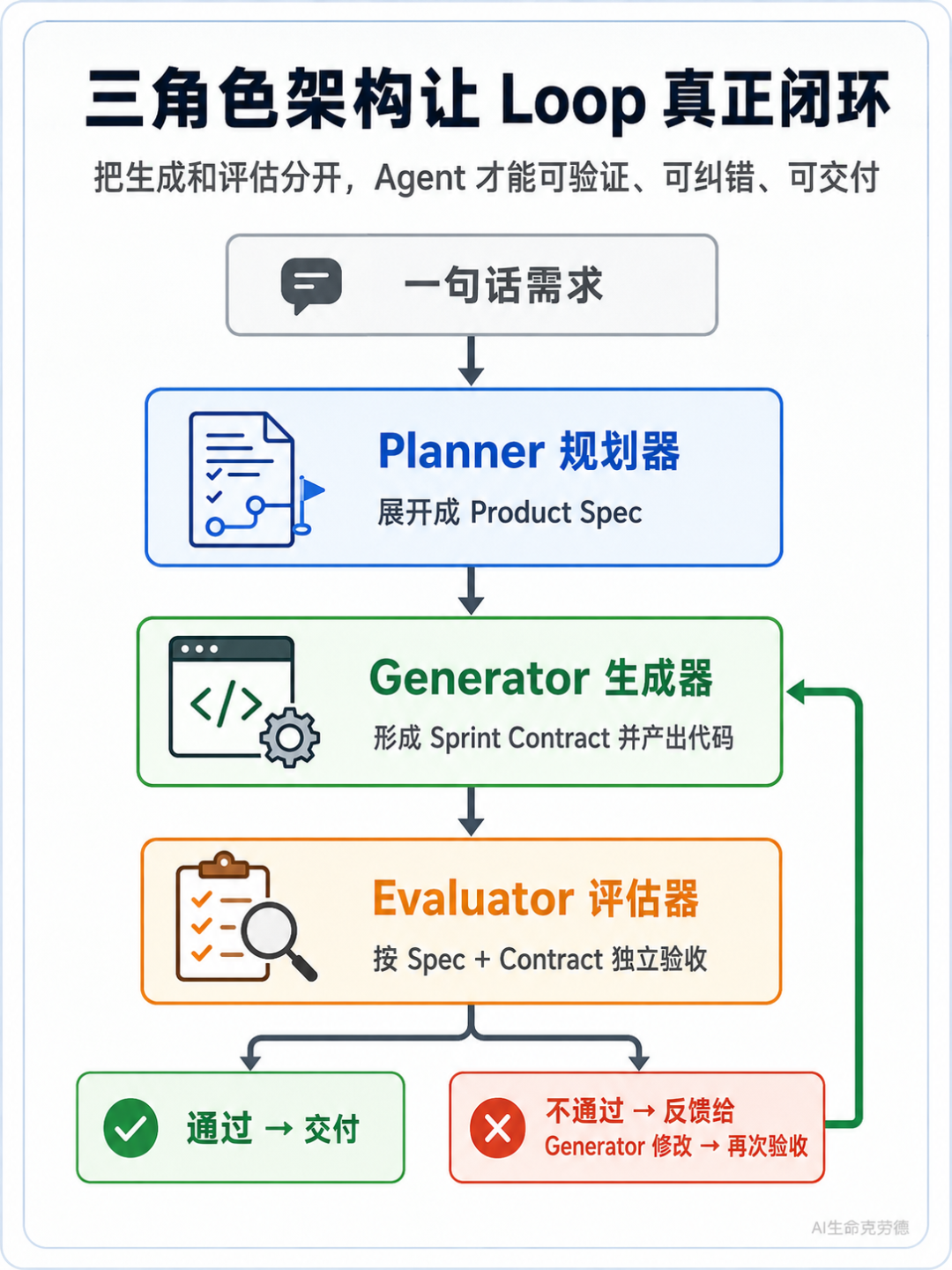
三角色架构闭环图
三角色架构闭环图
这套架构的核心原则只有一条:
Evaluator 必须与 Generator 分离。结构化分离是质量跃迁的前提。
Planner:把一句话需求展开成完整 spec
Planner 不写代码。它的工作是把一句话需求(比如"做一个用户登录页面")展开成完整 product spec:
- 用户目标和核心场景是什么
- 功能范围和边界是什么
- 关键交互、状态和异常情况是什么
- 验收标准和约束是什么
好的 product spec 是可执行、可验收的。它不会只写"让登录页面好看一点",而会写清:登录页面包含邮箱输入框、密码输入框、提交按钮;提交后调用 /api/login 接口;失败时显示红色错误信息。
Planner 输出的是 spec。它定义"要什么"、"边界在哪里"、"什么情况算完成"。
Generator:专注实现,不做评判
Generator 拿到 product spec 后,先形成 sprint contract,再开始写代码。
这个 contract 由 Generator 和 Evaluator 围绕 spec 对齐形成:Generator 承诺怎么实现,Evaluator 明确按哪些标准检查。
Generator 不重新定义需求。它要做的是把 spec 里的每一条要求落实到方案和代码中。
Generator 的注意力应该全在实现质量上:代码是否正确、是否高效、是否遵循项目约定。
它不应该在写完之后说"我觉得挺好的"。那是 Evaluator 的工作。
Evaluator:独立的批判者
这是整个架构的灵魂。
Evaluator 拿到三样东西:
- Planner 的 product spec
- Generator 和 Evaluator 对齐出来的 sprint contract
- Generator 的代码产出
它的任务只有一个:对照 spec 和 contract,逐条验证 Generator 是否达标。
Evaluator 不能参与 Generator 的创作过程。它只在产出完成后介入,像质检员检查产品一样,逐项打勾或打叉。
如果某项不达标,Evaluator 给出具体反馈,Generator 基于反馈修改,然后 Evaluator 再次验证。
这个循环持续到所有项通过,或者达到最大迭代次数。
为什么必须拆出 Evaluator?
你可能会问:让同一个模型先当 Generator、再当 Evaluator,不就行了吗?
Anthropic 的答案是:不行。
原因有三个。
第一,思维路径污染。
Generator 在写代码时已经建立了一套思维路径:"我为什么选这个方案"、"我为什么忽略那个边界"。当它切换成 Evaluator 角色时,这些思维残留会让它对自己更宽容。
第二,单独调教 Evaluator 更容易。
让一个模型同时擅长"创造"和"批判"很难。但让一个模型专门变"狠"——专门挑毛病——相对容易得多。
你只需要用详细的评分 breakdown 做 few-shot 校准,告诉它"什么样的输出算好、什么样的算差"。几次之后,它就会变成一个可靠的批判者。
第三,GAN 的启示。
这套架构的灵感来自 Generative Adversarial Networks(生成对抗网络)。
GAN 的核心思想:一个 Generator 负责生产,一个 Discriminator 负责鉴别。两者对抗训练,Generator 越做越好,Discriminator 越判越准。
Agent 系统也一样。Generator 和 Evaluator 分离后,两者可以独立优化。Generator 专注于"写得更好",Evaluator 专注于"判得更准"。
同一个 Agent 同时做两件事,两件事都做不好。
Evaluator 按什么标准打分
Evaluator 怎么判?不能凭感觉。
Anthropic 在前端设计场景中定义了四条可量化的评判标准:
标准 | 定义 | 默认表现 |
|---|---|---|
Design Quality(设计质量) | 设计是否有凝聚力的整体 | AI 容易出"slop"(拼凑感) |
Originality(原创性) | 是否有定制化决策 | AI 容易出"slop"(模板感) |
Craft(工艺) | 技术执行(字体、间距、色彩) | 默认就好 |
Functionality(功能性) | 可用性独立于审美 | 默认就好 |
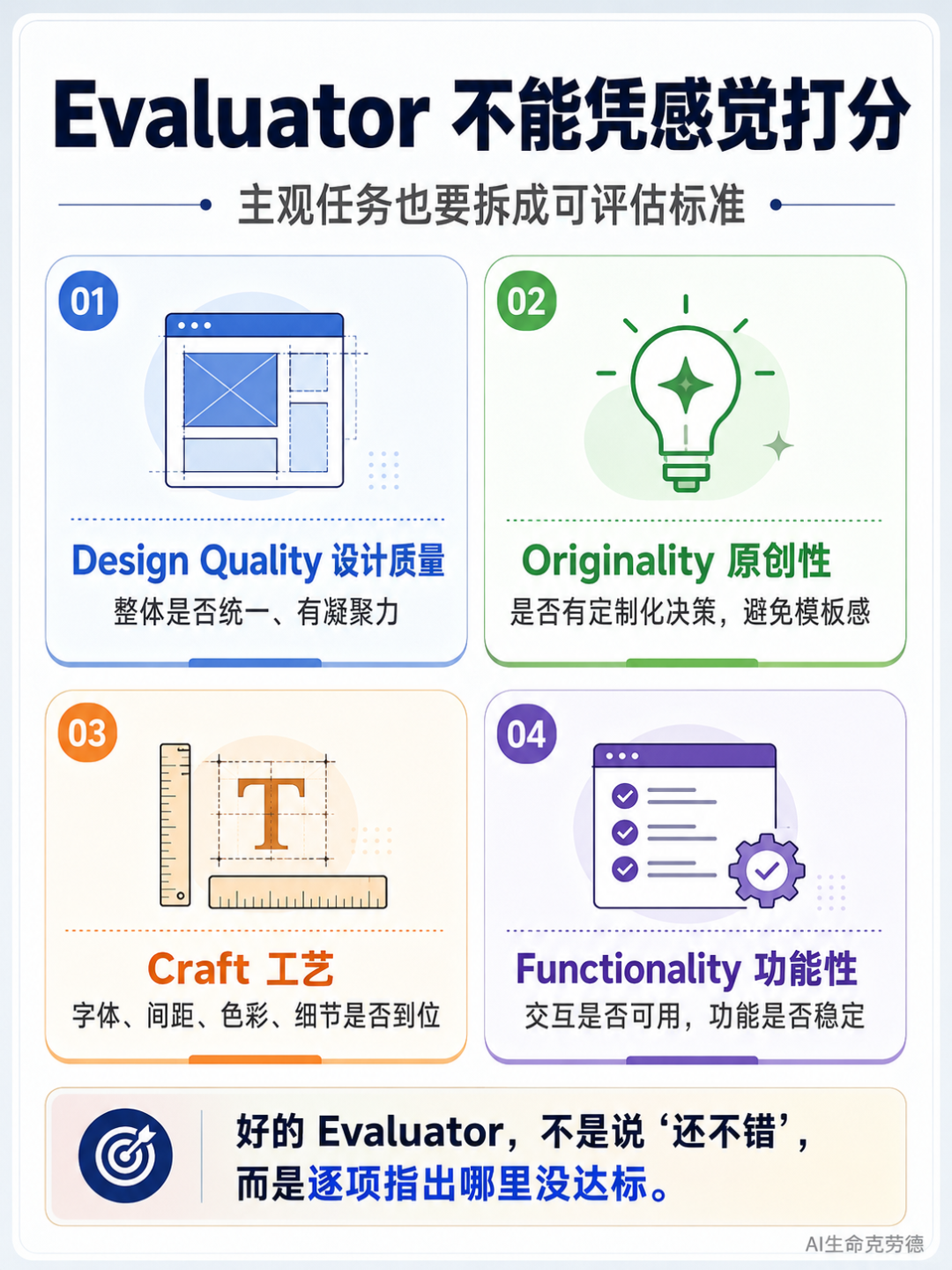
Evaluator 四项评分标准图
Evaluator 四项评分标准图
关键发现:Design Quality + Originality 是 AI 的弱项。
AI 生成代码时,Craft 和 Functionality 通常没问题——它能写出语法正确的代码、实现基本功能。但整体设计往往缺乏凝聚力,容易变成"AI 拼凑感"。
所以 Anthropic 的权重策略是:把评判重心放在 Design Quality 和 Originality 上。
同时,用 few-shot 示例校准 Evaluator。给它几个详细的评分 breakdown,让它知道"人类觉得好的设计长什么样"。这能显著减少评分漂移——否则 Evaluator 的标准会随着时间慢慢变松。
这套分工怎么迁移到开发
这套架构最初是在前端设计场景中验证的。但 Generator-Evaluator Loop 可以自然映射到整个软件开发生命周期。
Anthropic 给出了两个实际案例:
- 2D 复古游戏:6 小时全自主完成,从规划到实现到验证
- DAW(数字音频工作站):在 Opus 4.6 上近 4 小时完成
这不是玩具项目。DAW 是一个复杂的音频处理应用,涉及信号处理、UI 渲染、实时交互等多个技术层面。
全栈开发的映射:
- Code Review = 设计评估的同等结构角色。你需要有人(或 Agent)独立检查 Generator 的代码,重点看架构是否合理、是否有隐藏 bug,而不只停留在语法层面。
- QA 测试 = 功能性评估。自动化测试就是 Evaluator 的一种形式——它有明确的 pass/fail 标准。
- Product Review = 原创性评估。这个功能是否真正解决了用户需求?还是只是"看起来像"解决了?
Anthropic 实践带来的启发
在 2026 年 5 月的 AI Engineer Workshop 上,Anthropic 的 Ash Prabaker 和 Andrew Wilson 进一步提炼了这套方法论。
他们的核心观点:
第一,对抗性 Evaluator 优于自我评估。
做法从"让 Agent 检查自己的代码",改成"让另一个 Agent 来检查"。对抗性越强,质量越高。
第二,上下文压缩不等于治愈连贯性漂移。
Compaction 不能解决长任务中的连贯性问题。真正有效的是结构化交接——用明确的 artifact(进度报告、决策记录、待办列表)把信息传递给下一个实例。
第三,围绕 product spec 形成可测试的 sprint contract。
先把"把这个模块做好"展开成明确 spec,再让 Generator 和 Evaluator 对齐可验证的 contract。每一条都要能被 Evaluator 逐条打勾。
第四,用 rubric 评分主观输出。
对于无法用 pass/fail 判断的主观任务(设计、文案、架构选择),用评分量表替代二元判断。
第五,看 trace 作为首要调试手段。
当 Loop 出问题时,不要猜。看完整的执行 trace,找到 Agent 在哪一步走偏了。
第六,模型进化时,哪些 harness 组件该删掉。
随着模型本身变强,一些原本需要的 harness 组件(比如某些检查点)可能变得多余。定期审视你的 Loop 架构,去掉不必要的约束。
最小落地:先做 Maker + Checker
如果你现在想在自己的项目中用这套架构,怎么做?
第一步:至少做到 Maker + Checker 分工。
不需要三个独立的 Agent 实例。最简版本:
- 一个 Agent 负责起草代码(Maker)
- 另一个 Agent(最好用不同模型)负责审查(Checker)
- Checker 对照测试用例、项目约定、lint 规则逐项验证
第二步:给 Checker 写一个 Skill。
把你们的代码审查标准沉淀成 SKILL.md:
- 什么算"好代码"
- 什么算"不能接受"
- 必须检查的项(安全性、性能、可维护性)
- 可以参考的项(风格偏好)
这样 Checker 每次审查时都有统一标准,不会凭感觉。
第三步:设置最大迭代次数。
Generator 修改 → Checker 验证 → 不通过 → Generator 再修改。这个循环不能无限跑。
建议设置 2-3 次上限。超过上限还没通过?停下来,交给人处理。
第四步:保留 trace。
每次循环的输入、输出、评分、决策都记录下来。这是你调试 Loop 的唯一可靠手段。
如果要落到自己的项目里,可以先从这个最小模板开始:

可控 Loop 的最小模板
可控 Loop 的最小模板
目标:
Product Spec:
Sprint Contract:
Evaluator 检查清单:
最大迭代次数:
这个模板看起来很短,但已经包含了一个可控 Loop 最重要的五件事:目标、规格、执行约定、评估标准和停止边界。
最后先问:谁来审?
Loop Engineering 最容易被忽视的一环,不是 Automations 怎么配、Worktree 怎么开、Skill 怎么写。
是谁来评判 Loop 的产出。
如果你不解决这个问题,Loop 跑得越快,错误扩散得越快。
这也是 Anthropic 相关实践给这篇文章提供的关键背书:
干活的不是判的。判的不是干活的。结构化分离是质量跃迁的前提。
你的下一个 Loop,应该从这个问题开始:
"谁来审?"
下一篇:CI 自动修复实战
《从零搭建你的第一个 Loop:CI 自动修复实战》
理论够了。这篇动手。
从零到一个每日 CI 自动修复 Loop:
- 怎么写一个可验证的 goal(不是"让项目更好"这种废话)
- 怎么配调度器和断路器(不烧 token)
- 怎么用 Worktree 隔离、Skill 沉淀、Maker/Checker 分工
- 端到端跑通:触发 → 排查 → 修复 → 验证 → 开 PR
跑通一个,比看十篇都管用。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号