K8s 中 Exit Code 137 是什么?我用一次真实 OOM 实验讲明白了

K8s 中 Exit Code 137 是什么?我用一次真实 OOM 实验讲明白了

一根头发丝的宽度
发布于 2026-06-24 12:15:41
发布于 2026-06-24 12:15:41
在上一篇文章《CPU 打满之后会发生什么?》中,我模拟了容器 CPU 被持续占满的场景,并观察了 Kubernetes 的处理过程。
结果发现:
CPU 打满通常只是让应用变慢,并不会直接导致 Pod 退出。
而内存问题则完全不同。
当容器内存持续增长并超过 Memory Limit 后,Linux Kernel 会直接终止进程,Pod 随之退出,并可能进入:
OOMKilled
Exit Code 137
CrashLoopBackOff
这些状态在 Kubernetes 生产环境中十分常见,却也经常让人感到困惑。
本文将通过一次真实实验,完整了解 Pod 从内存溢出到 OOMKilled,再到 CrashLoopBackOff 的全过程。
大家在使用 Kubernetes 时,应该都见过下面这种状态:
kubectl get pod
-----------------
NAME READY STATUS
memory-test 0/1 CrashLoopBackOff
Pod 一直重启。
日志也看不出什么明显错误。
很多人第一反应是:
- 应用程序崩了?
- 镜像有问题?
- Kubernetes 出 Bug 了?
实际上,这类问题在生产环境中最常见的原因之一就是:
OOM(Out Of Memory,内存溢出)
最近在我的环境中专门模拟了一次 Pod OOM 故障,并完整记录了从 OOM 到 CrashLoopBackOff 的整个过程。
先制造一个 OOM
实验 Pod 配置如下:
resources:
requests:
memory: 100Mi
limits:
memory: 200Mi
然后让容器持续申请:
300MB
内存。
也就是说:
容器限制:200Mi
实际申请:300MB
理论上一定会触发 OOM。
创建 Pod 后:
kubectl get pod -w
很快就看到状态开始变化:
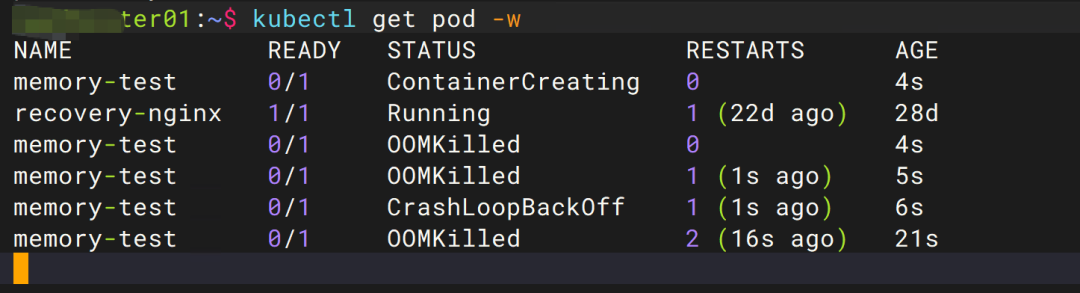
OOM 后发生了什么?
很多人以为:
Kubernetes 发现内存超了,然后主动把 Pod 干掉。
其实并不是。
真正执行 Kill 动作的是 Linux Kernel。
整个链路如下:

Kubernetes 在这里更像是:
“善后人员”。
真正下手的是 Linux Kernel。
第一现场:Pod 状态
执行:
kubectl describe pod memory-test
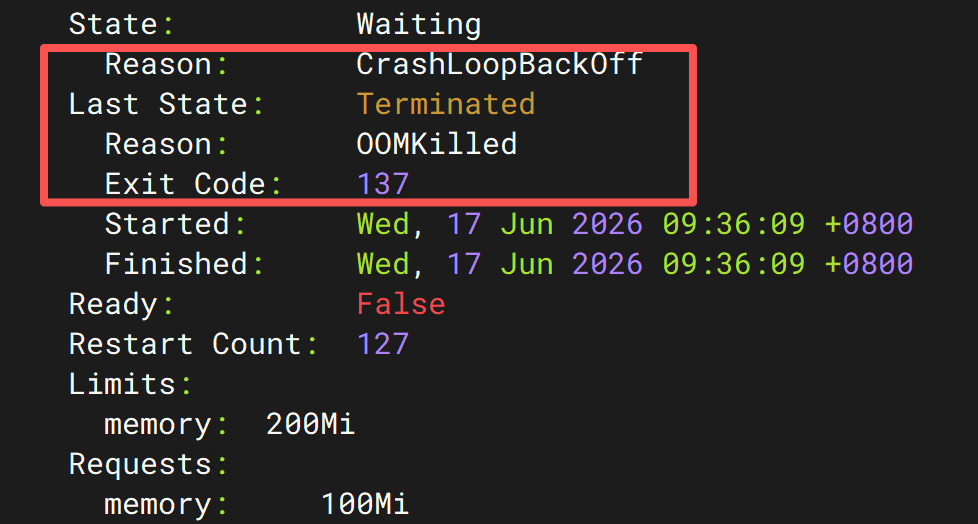
看到:
Last State:
Reason: OOMKilled
Exit Code: 137
这里有两个关键点。
OOMKilled
直接说明:
容器因为内存不足被杀死
Exit Code 137
很多面试都会问。
实际上:
137 = 128 + 9
而:
9 = SIGKILL
也就是说:
Linux Kernel 强制终止了进程。
并不是应用自己退出。
第二现场:Events
继续往下看:
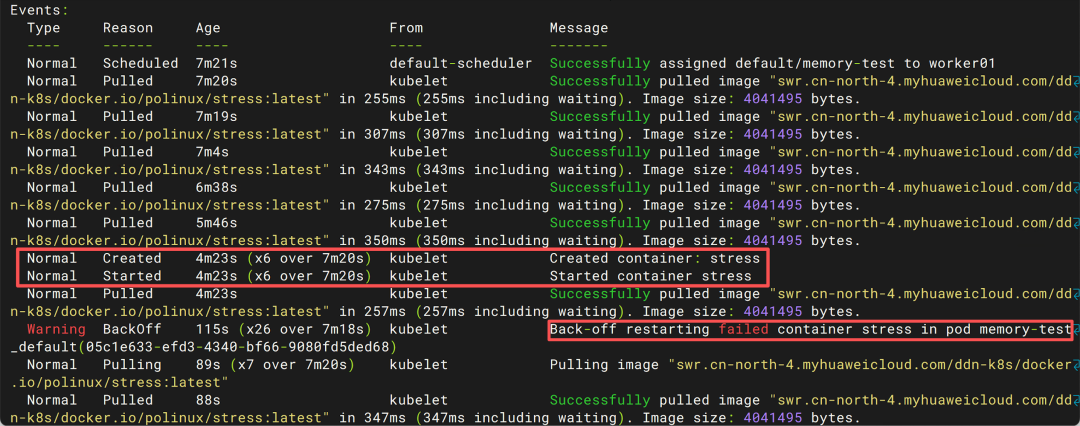
Warning BackOff
Back-off restarting failed container
很多人看到这里就认为:
BackOff = OOM
其实不对。
BackOff 的意思是:
容器连续失败太多次
Kubelet开始降低重启频率
换句话说:
OOM 是原因
BackOff 是结果
这也是 Kubernetes 中非常容易混淆的一个知识点。
第三现场:Node 内核日志
真正让我确认问题的,是登录节点后看到的日志。
sudo dmesg -T | grep -i oom
输出:
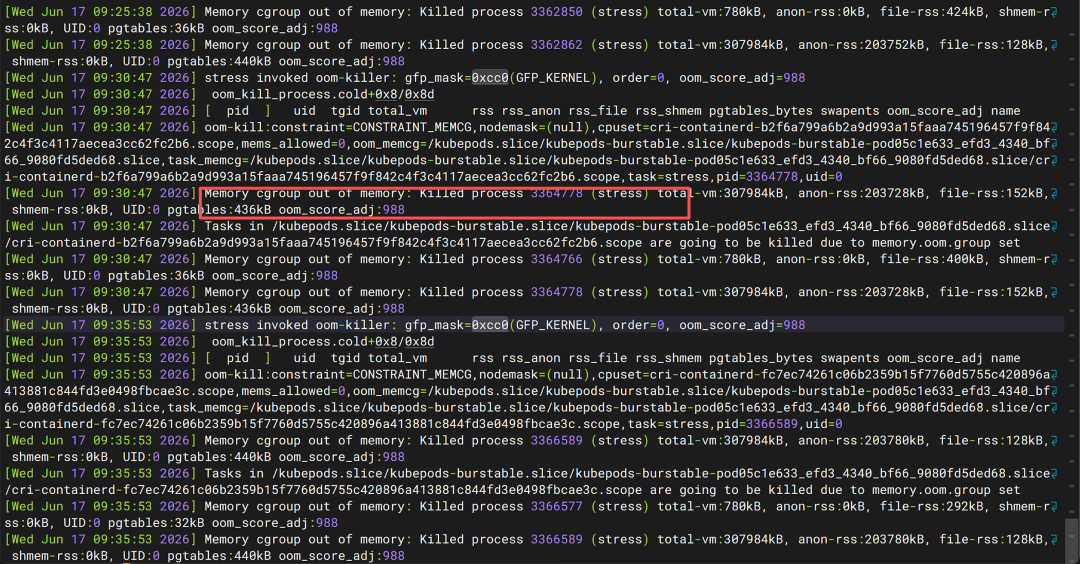
Memory cgroup out of memory:
Killed process 3364778 (stress)
看到这里基本就可以结案了。
这句话翻译成人话就是:
Linux 发现这个容器已经超出内存限制,于是直接把 stress 进程杀掉了。
继续往下看:
oom_score_adj=988
这个数字也很有意思。
它表示:
这个进程在发生 OOM 时
属于优先被清理对象
因此 Linux 优先干掉了它。
为什么 Pod 一直重启?
因为 Kubernetes 默认会帮你恢复业务。
当容器退出后:
OOM
↓
Container Exit
↓
Kubelet Restart
↓
再次启动
↓
再次OOM
↓
再次重启
不断循环。
最终:
CrashLoopBackOff
形成我们最开始看到的状态。
一个容易忽略的细节
在我的实验中:
QoS Class: Burstable
这是因为:
requests:
memory: 100Mi
limits:
memory: 200Mi
Request 和 Limit 不相等。
因此 Kubernetes 把它归类为:
Burstable
这类 Pod 在资源紧张时,更容易成为 OOM 的目标。
很多线上故障其实都和 QoS 配置有关。
生产环境如何避免 OOM?
我个人的经验是:
1. 必须设置 Request
不要让调度器瞎猜。
requests:
memory: 512Mi
2. 必须设置 Limit
避免单个 Pod 吃光节点内存。
limits:
memory: 1Gi
3. 提前监控
不要等 OOM 再处理。
建议 Prometheus 告警:
内存使用率 > 80%
直接通知。
4. 关注 Restart Count
很多线上 OOM 最早暴露的信号不是告警。
而是:
Restart Count
持续增长。
这是非常值得关注的指标。
总结
这次实验完整还原了一次 Kubernetes OOM 故障:
申请300MB内存
↓
超过200Mi Limit
↓
Memory Cgroup OOM
↓
Linux OOM Killer
↓
OOMKilled(137)
↓
Kubelet重启
↓
CrashLoopBackOff
记住一句话:
CPU 打满通常只是变慢,而内存耗尽会直接“杀进程”。
这也是为什么 OOM 一直是 Kubernetes 生产环境中最值得关注的故障之一。
如果你最近也遇到过:
OOMKilled
Exit Code 137
CrashLoopBackOff
希望这篇文章能帮你少走一些弯路。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号