缓存技术:从CPU Cache到AI KV Cache (五)KV Cache

缓存技术:从CPU Cache到AI KV Cache (五)KV Cache

霞姐聊IT
发布于 2026-06-24 13:30:35
发布于 2026-06-24 13:30:35
五、AI时代:KV Cache
KV Cache是 Transformer 大语言模型在推理阶段的一种优化技术。
它的核心作用是:通过缓存历史Token 在每一层 Transformer 中计算得到的 Key 和 Value,避免 Decode 阶段重复计算历史 Token 的 Attention,从而显著降低 LLM 推理延迟。
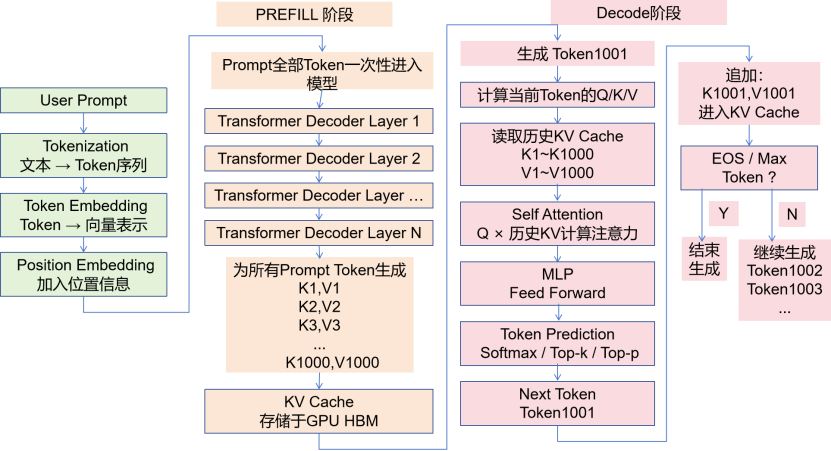
我们来简要的看一下LLM的推理流程:
假设用户输入Prompt:“今天天气怎么样?”
模型生成:“今天的天气很好。”
整个推理过程是可以分成Prefill和Decode两个阶段的。
在Prefill阶段,模型会理解用户输入,建立KV Cache;
而在Decode阶段,模型会逐Token生成答案。
下面,我们把这两个阶段打开详细看一下:
1.Prefill阶段:Prompt 处理阶段
此阶段,用户的整个Prompt一次性输入模型,经过所有Transformer Decoder Layer,计算每个Token的隐藏状态以及 Attention 所需要的 K/V,并缓存起来。
“今天天气怎么样?”
↓
经过Tokenization 后,变成token序列:
↓
Token1 Token2 Token3 Token4,
↓
再经过 Embedding 和位置编码后,每个 Token 都会得到一个向量:
↓
X1 X2 X3 X4 (比如X1是今天的向量表示,X2是天气的向量表示……)
↓
进入 Transformer 的每一层后,会通过三个不同的线性变换生成:
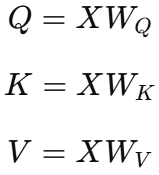
X1 X2 X3 X4这样向量会得到:

每一层Transformer计算后,都会得到KV,这些KV会被缓存到GPU HBM显存中。
Prefill阶段,完成了两件事情:
(1)经过多层 Transformer 后,模型获得了对整个上下文的理解。
(2)生成Decode 所需的 KV Cache,为后续逐Token 生成提供基础。
Prefill阶段需要处理整个 Prompt、所有 Token 都要经过所有 Transformer 层、每个 Token 都要计算 Q(Query)/K(Key)/V(Value)。
2.Decode阶段:逐Token生成答案阶段
模型先生成第一个回答Token:“今天”。
↓
计算当前 Token 的 Q/K/V Q5 K5 V5
↓
从显存中读取历史KV Cache
Layer1:
K1 K2 K3 K4
V1 V2 V3 V4
...
Layer N:
K1 K2 K3 K4
V1 V2 V3 V4
↓
执行Attention:
当前的Token的Q5和历史Key:K1 K2 K3 K4 K5计算注意力,获得当前 Token 对整个上下文的理解。
↓
预测下一个Token,得到“的”
MLP Feed Forward→Linear + Softmax→采样(Top-k / Top-p)
↓
不断循环,生成Token→计算新 K/V→追加 KV Cache→
下一Token,直到输出 EOS
或者达到Max Token。
那么,KV Cache在其中起了什么样的作用呢?
3.有没有KV Cache的区别
大语言模型采用的自回归(Auto-Regressive)生成的特点,从逻辑上看,自回归生成会不断把新Token 追加到上下文中;如果没有 KV Cache,工程实现上就需要反复重新计算历史上下文。
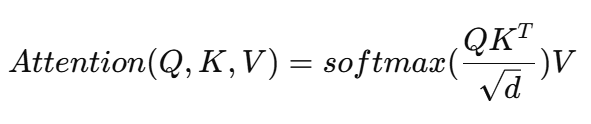
其中:
Q(Query):当前 token 想关注什么
K(Key):历史 token 提供什么信息
V(Value):历史 token 具体内容
(1)没有 KV Cache:
举例来说,生成第 11 个 Token 时,则需要重新计算:Q1~Q10 K1~K10 V1~V10,之前的历史 Token:“今天”“天气”“怎么样”...会被反复计算。
生成 N 个 Token:1 + 2 + 3 + ... + N,需要的计算复杂度是O(N2)。
随着上下文增长,推理会越来越慢。
(2)有KV Cache
因为模型参数固定、历史token 不变、位置编码确定,所以历史 Token 的 K/V是不变的,所以可以将它们缓存起来,后续计算直接用即可。
比如,K1 V1、K2 V2...K10 V10可以直接缓存成KV Cache。在生成第 11 个 Token 时,只需要计算:Q11 K11 V11,然后结合之前缓存的KV Cache完成Attention计算即可。所以每一步只增加当前 Token 的计算。
KV Cache 避免了历史 Token 的重复投影和前向计算,使每一步只需计算当前 Token 的 Q/K/V,并复用历史 K/V。虽然 Attention 仍需访问历史 KV,但整体推理开销相比无缓存大幅下降。这样用户看到的模型生成速度会大幅提升。
KV Cache 用显存换计算,避免了历史 Token 的重复计算,可显著降低推理延迟,是大模型支持低延迟生成、高并发和长上下文推理的核心技术。
4. KV Cache的代价
KV Cache使用显存空间降低计算复杂度,那么这个显存的代价有多大呢?
KV Cache 显存大小约为:层数× 序列长度 × KV 维度 × K/V两份 × 数据类型字节数 × Batch Size
其中:
Batch Size:同时处理的请求数量。
序列长度:当前生成的上下文总长度(Prompt 长度 + 已生成 Token 数量)。
层数:Transformer 的解码器总层数。
KV 维度:KV 注意力头数 × 每个头的维。
数据类型字节数:FP16/BF16 2 字节,FP32 4 字节,INT8 1 字节。
以FP16 精度为例:
场景A:LLaMA 2 7B 传统MHA
模型配置:层数L=32,Dimension_KV = 4096
推理配置:Batch = 1,生成到 Sequence Length = 2048
KV显存 Size约为: 2×1×2048×32×4096×2÷(1024×1024×1024)≈1.0 GB
场景B:LLaMA 3 70B GQA
模型配置:层数L=80,总隐藏维度 8192,但 KV 头数只有 8 个,每个头128 维,所以 Dimension_KV = 8 × 128 = 1024。
推理配置:Batch = 1,长上下文 Sequence Length = 128,000计算: 2×1×128000×80×1024×2÷(1024×3)≈39.1 GB
即使用了GQA,处理 128k 长文本时,KV Cache 也要吃掉近 40GB 显存。我们可以由此看出来,长上下文推理非常依赖高显存GPU。
5.KV Cache的优化方法
KV Cache 优化可分为以下几类:
(1)架构层优化
通过直接修改模型结构,减少Dimension_KV维度。
MHA(标准多头注意力):每个Q头配一对独立的 K/V 头,缓存量最大,已被前沿模型逐步弃用。
MQA(多查询注意力):所有 Q 头共享同一对 K/V 头。KV Cache 直接缩减为原来的 1/N,但代价是小模型或复杂任务精度可能下降明显,大模型经过重新训练后可以保持不错性能。
GQA(分组查询注意力):MHA 和 MQA 的折中方案,将 Q 头分组,每组共享一对 K/V。这是工业界目前主流的精度-效率折中方案,可在显存节省和模型质量间取得好的平衡。
MLA(多头潜在注意力):不直接缓存 K/V,而是缓存压缩后的潜在向量,在推理时再动态解压出 K/V。这能大幅降低KV Cache 体积。
(2)精度层优化
KV Cache可以单独降精度存储:可将FP16/BF16的 K/V 压缩为 INT8 或 INT4,这样显存占用可直接减掉一半以上。
量化时对K 和 V可采用不同的分组策略以避免异常值破坏精度。
(3)系统层优化
即使总容量够,显存碎片也会导致OOM的问题。针对这块,有一下工程优化方法:
Paged Attention:借鉴OS的虚拟内存和分页机制,将每个请求的KV Cache 分割成固定大小的页,存储在非连续的物理显存块中。
这样可消除了外部碎片,允许按需分配。
当Batch 中有请求提前结束时,其占用的页可以立即释放给新请求,可极大提升GPU 利用率。
Prefix Caching:如果多个用户的Prompt 有公共前缀,系统会复用这部分 Prompt 对应的 KV Cache,而不是为每个用户重复计算和存储。
这个优化可以在处理大量相似请求(如RAG 检索式问答)等场景时,获得巨大收益。
(4)算法层优化
当上下文极长时,需要对历史信息做取舍,方法有:
滑动窗口注意力:限制每个Token 只能注意到前 W 个 Token,超出窗口的 K/V 直接被丢弃,将显存占用锁定在固定值O(W),不再随序列长度无限增长。
KV 驱逐策略(KV Eviction):在生成过程中,根据注意力分数动态判断哪些历史Token 的 K/V 是重要的,保留重要的,驱逐掉冗余的,用有限的缓存容纳无限长的上下文。
(5)分布式与异构计算
多卡分布式存储:在张量并行中,将KV Cache 按注意力头维度切分到多张 GPU 上。例如,用 8 张 GPU 存 KV Cache,单卡承担的缓存量仅为原来的 1/8。
CPU/DRAM 卸载:对于极长序列,将冷门的KV Cache 从 GPU 显存卸载到 CPU 内存或 NVMe 硬盘上,在需要计算时再异步预取回来。
六、总结
计算的速度在不断提升,但不同层级的存储的数据访问速度始终存在巨大的鸿沟。缓存是对速度鸿沟的持续对抗。
从CPU 与内存之间差距,到分布式系统中网络与磁盘的延迟,再到今天 AI推理的新矛盾,每一次硬件或软件的突破,都会制造新的速度差。缓存也是与时俱进,以新的形式出现在工程中。
不过在这个过程中,有几条规律始终没有改变:
局部性原理始终有效,只是表现形式不断变化。
早期CPU 利用程序的时间和空间局部性缓存指令和数据;
互联网系统根据用户访问热点缓存网页和对象;
今天的AI则利用自回归生成中的上下文依赖,使用KV Cache缓存历史Token 的 K/V。
每增加一层缓存,就引入一组新的系统复杂性。
CPU Cache 需要解决缓存一致性问题;
分布式缓存需要面对数据失效、穿透、击穿问题;
AI 推理中的 KV Cache 则带来了显存容量、内存碎片、调度效率、隔离与共享等新的工程挑战。
我们无法让所有数据都处在最快的地方,所以只能想办法把最重要、最可能再次被访问的数据提前放到离计算最近的位置。
从CPU 中的 SRAM,到 GPU HBM 显存中的 KV Cache,缓存从来都不是一个可有可无的性能优化技巧,它是现代计算系统对抗物理限制的基本方法。
计算机世界中的不公平客观存在:计算比存储快,芯片内部比外部快,局部数据比全局数据更容易获取;但缓存又试图通过预测、复用和靠近,把这种不公平带来的代价降到最低。
新的速度鸿沟仍会出现,缓存的形式也会不断改变,但它解决的问题不会消失:当无法让一切都变快时,总要找到那些最重要的东西,让它先快起来。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号