2026-06-21:统计结果等于 K 的序列数目。用go语言,给定整数数组 nums 和整数 k。 从左到右遍历 nums,维护一个初始值 val = 1。到达

2026-06-21:统计结果等于 K 的序列数目。用go语言,给定整数数组 nums 和整数 k。 从左到右遍历 nums,维护一个初始值 val = 1。到达

福大大架构师每日一题
发布于 2026-06-24 15:55:57
发布于 2026-06-24 15:55:57
2026-06-21:统计结果等于 K 的序列数目。用go语言,给定整数数组 nums 和整数 k。 从左到右遍历 nums,维护一个初始值 val = 1。到达每个位置 i 时,你必须从三种更新方式中选一种作用到 val:
- • 把 val 乘以 nums[i]
- • 把 val 精确地除以 nums[i](按有理数计算,允许 val 变成分数,要求除法结果是精确的)
- • 什么也不做,val 保持不变
当所有元素都处理完后,只有当 val 的最终有理数结果恰好等于 k 时,该选择序列才算成功。
问有多少种不同的选择序列能够使最终 val = k。
返回该计数结果。
1 <= nums.length <= 19。
1 <= nums[i] <= 6。
1 <= k <= 1000000000000000。
输入: nums = [2,3,2], k = 6。
输出: 2。
解释:
以下 2 个不同的选择序列导致 val == k:
序列 | 对 nums[0] 的操作 | 对 nums[1] 的操作 | 对 nums[2] 的操作 | 最终 val |
|---|---|---|---|---|
1 | 乘法:val = 1 * 2 = 2 | 乘法:val = 2 * 3 = 6 | 保持 val 不变 | 6 |
2 | 保持 val 不变 | 乘法:val = 1 * 3 = 3 | 乘法:val = 3 * 2 = 6 | 6 |
题目来自力扣3850。
一、题目数学模型转化(核心前置逻辑)
1. 数值拆解原理
所有参与运算的数:数组元素 nums[i] ∈ [1,6]、目标值 k,质因子仅包含 2、3、5:
- • 1:无任何质因子,指数
(0,0,0) - • 2:仅因子2,指数
(1,0,0) - • 3:仅因子3,指数
(0,1,0) - • 4=2²:指数
(2,0,0) - • 5:仅因子5,指数
(0,0,1) - • 6=2×3:指数
(1,1,0)
任意有理数 val 都可以唯一表示为:
其中 为整数(正数代表乘,负数代表除)。
题目要求最终 val = k,可以完全转化为三元指数约束问题,彻底避开浮点数、分数精度问题。
2. 操作对应的指数变化
初始 val=1,对应初始指数三元组 (0,0,0)。
设当前数字 nums[i] 分解为指数 (e2,e3,e5),三种操作对指数三元组 的修改规则:
- 1. 乘 nums[i]:指数相加 →
- 2. 除 nums[i]:指数相减 →
- 3. 不操作:指数不变 →
3. 目标等式转换
设遍历完所有数组后,最终指数为 ;
目标值 k 分解为指数 。
val = k 等价于:
二、算法整体分步流程(完全对应代码逻辑,无代码)
步骤1:预处理目标值 k,校验合法性
- 1. 对
k做质因子分解,统计因子2、3、5的指数 ; - 2. 分解结束后如果剩余数字≠1,说明
k包含2/3/5以外的质因子(如7、11等):- • 不存在任何合法操作序列,直接返回答案 0。
步骤2:预处理数组 nums 每一个元素的指数三元组
遍历数组每一个数字 x = nums[i]:
- 1. 对
x分解质因子,得到该数字对应的指数三元组 ; - 2. 全部存入数组
es,后续DFS直接取用,不用重复分解。 由于nums[i]≤6,所有数字都只有2、3、5因子,不存在非法元素。
步骤3:带记忆化的深度优先搜索 DFS 定义
DFS状态定义
状态四元组 (i, curE2, curE3, curE5):
- •
i:当前正在处理数组第i个元素(数组从0开始,倒序遍历,i初始为数组最后一位下标); - •
curE2,curE3,curE5:处理完前i+1个元素后,当前val对应的2、3、5指数。
返回值含义:从当前状态出发,处理完剩下所有元素后,能满足最终指数等于 (K2,K3,K5) 的合法操作序列总数。
记忆化缓存 memo
用哈希表存储已经计算过的状态 (i,curE2,curE3,curE3),key为四元组,value为该状态对应的合法方案数;
避免重复递归计算同一状态,大幅减少重复运算。
步骤4:DFS递归终止条件(i < 0,所有数字全部处理完毕)
数组全部遍历完成,此时判断当前指数是否等于目标k的指数:
- 1. 若
curE2=K2、curE3=K3、curE5=K5:找到1条合法序列,返回1; - 2. 指数不匹配:无合法序列,返回0。
步骤5:递归分支计算(三种操作分别递归)
取出当前数字 nums[i] 的指数三元组 (e2,e3,e5),分三路递归:
- 1. 分支1:执行除法
新指数 = 当前指数 - 数字指数 → 递归
dfs(i-1, curE2-e2, curE3-e3, curE5-e5) - 2. 分支2:执行乘法
新指数 = 当前指数 + 数字指数 → 递归
dfs(i-1, curE2+e2, curE3+e3, curE5+e5) - 3. 分支3:不操作
指数保持不变 → 递归
dfs(i-1, curE2, curE3, curE5)
将三个分支返回的方案数相加,得到当前状态总合法方案数。
步骤6:缓存状态结果,返回上层
将当前状态 (i,curE2,curE3,curE5) 和计算出的总方案数存入memo哈希表;
向上层递归返回总方案数。
步骤7:启动递归,输出结果
初始调用 dfs(n-1, K2, K3, K5),含义:
- • 从数组最后一个元素开始倒序遍历;
- • 初始传入目标指数,递归逻辑等价于反向推导: 逆向视角:把“最终要等于k”转化为“从k的指数出发,倒推每一步操作抵消指数,全部处理完数字后指数归零”,和正向遍历数学等价。
示例 nums=[2,3,2],k=6 完整推演
- 1. k=6=2¹×3¹,目标指数
K2=1,K3=1,K5=0; - 2. 数组元素分解:
- • nums[0]=2 → (1,0,0)
- • nums[1]=3 → (0,1,0)
- • nums[2]=2 → (1,0,0)
- 3. 启动
dfs(2,1,1,0),倒序处理第2位、第1位、第0位; - 4. 递归遍历所有3³=27种操作组合,筛选出2组满足终止条件的序列,最终输出2。
三、时间复杂度分析
1. 基础规模
数组长度 ,每一步3种操作,暴力枚举总状态 ,直接暴力会超时;依靠记忆化只计算可达指数状态。
2. 指数范围约束(决定实际有效状态数量)
每个数字最多贡献指数:
- • 2:最多指数+1;3:最多+1;5:最多+1 n=19时,单类指数最大偏移区间:,总区间长度39。 三元指数组合理论上限:; 再叠加数组下标 ~,全局总状态上限:。
3. 总时间复杂度
- • 预处理分解:,可忽略;
- • DFS记忆化:每个状态仅计算1次,单次状态内仅3次递归加法; 总时间复杂度:, 为三元指数组合最大数量(),远小于暴力 。
四、额外空间复杂度分析
额外空间分为两部分:
- 1. 数组存储
es:; - 2. 记忆哈希表memo:存储全部访问过的
(i,e2,e3,e5)状态,最坏存储 个键值对; - 3. 递归调用栈:深度等于数组长度n,。
总额外空间复杂度:, 为指数三元组组合上限。
补充关键说明(代码逆向逻辑解释)
常规正向思路:初始指数(0,0,0),遍历所有操作,最后判断等于k指数; 本代码采用逆向DFS:初始传入k的指数,每一步操作反向抵消(乘变减、除变加、不变仍不变),全部处理完后判断指数归零。两种思路数学等价,仅递归入参方向相反,时间、空间复杂度完全一致。
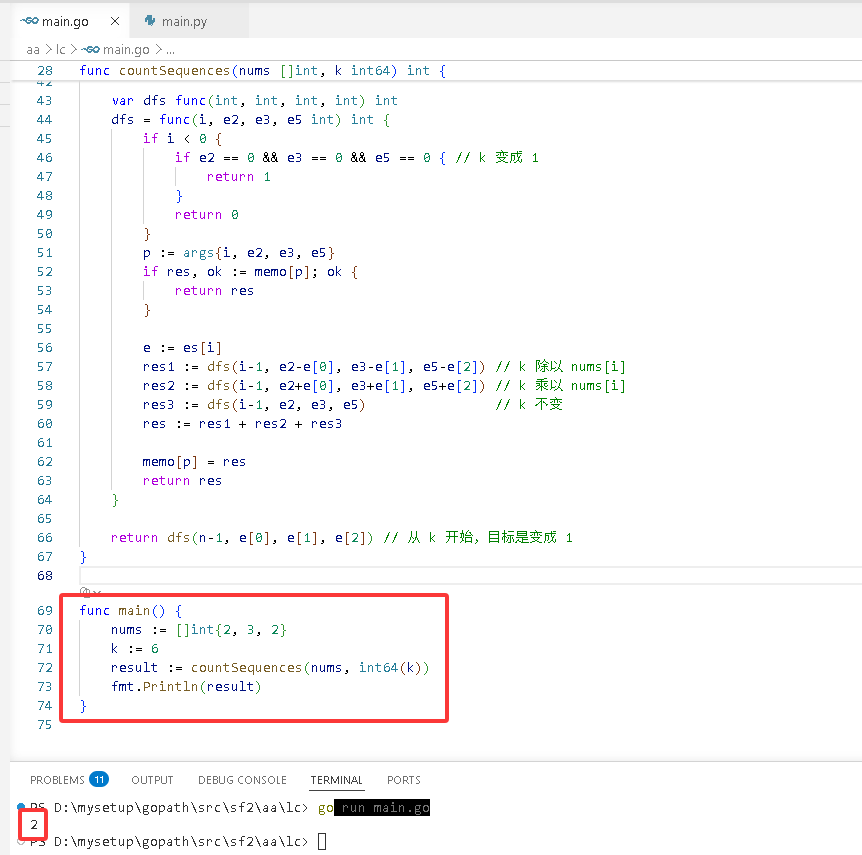
Go完整代码如下:
.
package main
import (
"fmt"
"math/bits"
)
// 返回 k 中的质因子 2,3,5 的个数,以及 k 是否只包含 <= 5 的质因子
func primeFactorization(k int) ([3]int, bool) {
e2 := bits.TrailingZeros(uint(k))
k >>= e2
e3 := 0
for k%3 == 0 {
e3++
k /= 3
}
e5 := 0
for k%5 == 0 {
e5++
k /= 5
}
return [3]int{e2, e3, e5}, k == 1
}
func countSequences(nums []int, k int64)int {
e, ok := primeFactorization(int(k))
if !ok { // k 有大于 5 的质因子
return0
}
n := len(nums)
es := make([][3]int, n)
for i, x := range nums {
es[i], _ = primeFactorization(x)
}
type args struct{ i, e2, e3, e5 int }
memo := map[args]int{}
var dfs func(int, int, int, int)int
dfs = func(i, e2, e3, e5 int)int {
if i < 0 {
if e2 == 0 && e3 == 0 && e5 == 0 { // k 变成 1
return1
}
return0
}
p := args{i, e2, e3, e5}
if res, ok := memo[p]; ok {
return res
}
e := es[i]
res1 := dfs(i-1, e2-e[0], e3-e[1], e5-e[2]) // k 除以 nums[i]
res2 := dfs(i-1, e2+e[0], e3+e[1], e5+e[2]) // k 乘以 nums[i]
res3 := dfs(i-1, e2, e3, e5) // k 不变
res := res1 + res2 + res3
memo[p] = res
return res
}
return dfs(n-1, e[0], e[1], e[2]) // 从 k 开始,目标是变成 1
}
func main() {
nums := []int{2, 3, 2}
k := 6
result := countSequences(nums, int64(k))
fmt.Println(result)
}
在这里插入图片描述
Python完整代码如下:
.
# -*-coding:utf-8-*-
from typing import List, Tuple
from functools import lru_cache
def prime_factorization(k: int) -> Tuple[Tuple[int, int, int], bool]:
"""
返回 k 中的质因子 2,3,5 的个数,以及 k 是否只包含 <= 5 的质因子
"""
e2 = 0
while k % 2 == 0:
e2 += 1
k //= 2
e3 = 0
while k % 3 == 0:
e3 += 1
k //= 3
e5 = 0
while k % 5 == 0:
e5 += 1
k //= 5
return (e2, e3, e5), k == 1
def count_sequences(nums: List[int], k: int) -> int:
"""
计算满足条件的序列数量
"""
# 获取 k 的质因子分解
k_factors, ok = prime_factorization(k)
if not ok: # k 有大于 5 的质因子
return0
n = len(nums)
# 预先计算每个 nums[i] 的质因子分解
factors = []
for x in nums:
f, _ = prime_factorization(x)
factors.append(f)
# 使用 lru_cache 实现记忆化搜索
@lru_cache(None)
def dfs(i: int, e2: int, e3: int, e5: int) -> int:
"""
i: 当前处理的索引
e2, e3, e5: 当前 k 中质因子 2,3,5 的指数
"""
if i < 0:
# 当所有数都处理完,如果 k 变为 1,则找到一种方案
return1if e2 == 0 and e3 == 0 and e5 == 0else0
# 获取当前数的质因子指数
f2, f3, f5 = factors[i]
# 三种操作:
# 1. k 除以 nums[i](需要 k 能被整除)
# 2. k 乘以 nums[i]
# 3. k 不变
res = 0
# 操作1: k 除以 nums[i]
res += dfs(i - 1, e2 - f2, e3 - f3, e5 - f5)
# 操作2: k 乘以 nums[i]
res += dfs(i - 1, e2 + f2, e3 + f3, e5 + f5)
# 操作3: k 不变
res += dfs(i - 1, e2, e3, e5)
return res
# 从最后一个元素开始,初始状态为 k 的质因子指数
return dfs(n - 1, k_factors[0], k_factors[1], k_factors[2])
def main():
nums = [2, 3, 2]
k = 6
result = count_sequences(nums, k)
print(result)
if __name__ == "__main__":
main()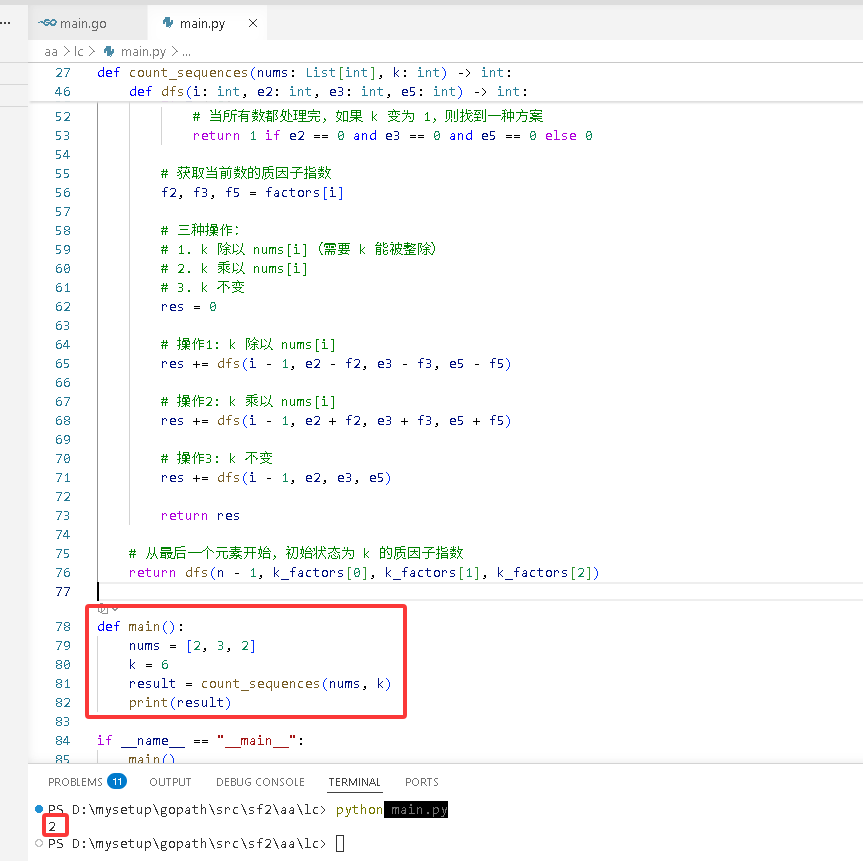
在这里插入图片描述
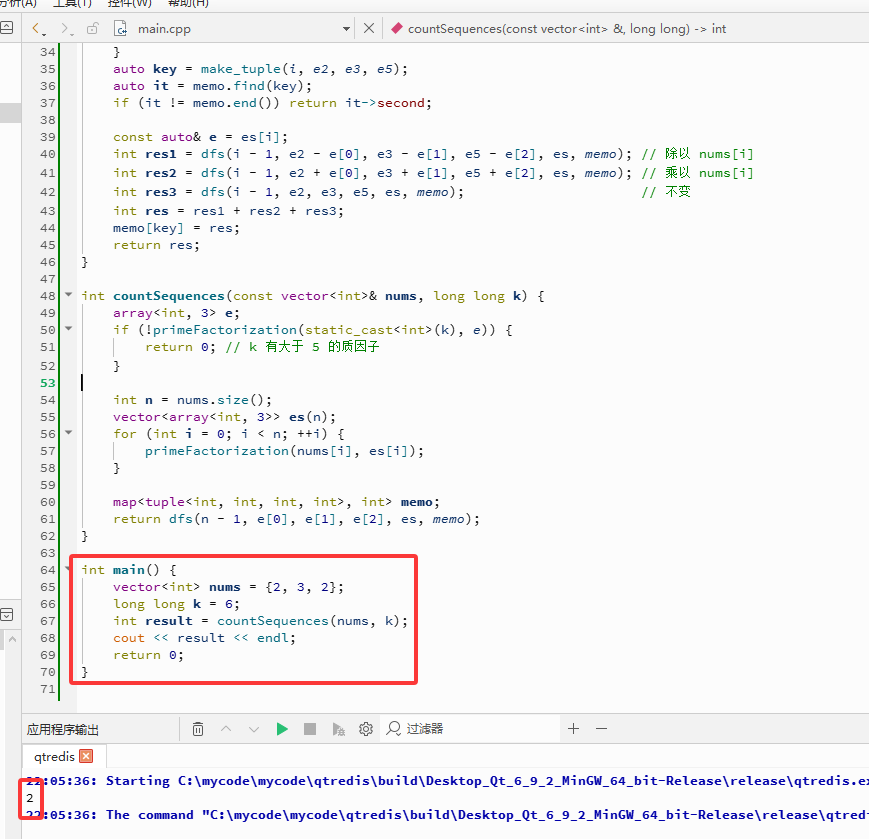
C++完整代码如下:
.
#include <iostream>
#include <vector>
#include <map>
#include <tuple>
#include <array>
using namespace std;
// 返回 k 中质因子 2,3,5 的个数,以及 k 是否只包含 <= 5 的质因子
bool primeFactorization(int k, array<int, 3>& e) {
e[0] = 0;
while (k % 2 == 0) {
++e[0];
k /= 2;
}
e[1] = 0;
while (k % 3 == 0) {
++e[1];
k /= 3;
}
e[2] = 0;
while (k % 5 == 0) {
++e[2];
k /= 5;
}
return k == 1;
}
int dfs(int i, int e2, int e3, int e5,
const vector<array<int, 3>>& es,
map<tuple<int, int, int, int>, int>& memo) {
if (i < 0) {
return (e2 == 0 && e3 == 0 && e5 == 0) ? 1 : 0;
}
auto key = make_tuple(i, e2, e3, e5);
auto it = memo.find(key);
if (it != memo.end()) return it->second;
const auto& e = es[i];
int res1 = dfs(i - 1, e2 - e[0], e3 - e[1], e5 - e[2], es, memo); // 除以 nums[i]
int res2 = dfs(i - 1, e2 + e[0], e3 + e[1], e5 + e[2], es, memo); // 乘以 nums[i]
int res3 = dfs(i - 1, e2, e3, e5, es, memo); // 不变
int res = res1 + res2 + res3;
memo[key] = res;
return res;
}
int countSequences(const vector<int>& nums, long long k) {
array<int, 3> e;
if (!primeFactorization(static_cast<int>(k), e)) {
return0; // k 有大于 5 的质因子
}
int n = nums.size();
vector<array<int, 3>> es(n);
for (int i = 0; i < n; ++i) {
primeFactorization(nums[i], es[i]);
}
map<tuple<int, int, int, int>, int> memo;
return dfs(n - 1, e[0], e[1], e[2], es, memo);
}
int main() {
vector<int> nums = {2, 3, 2};
long long k = 6;
int result = countSequences(nums, k);
cout << result << endl;
return0;
}
在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号