DINOv3 ViT | 新一代视觉基础模型 架构与应用综述

DINOv3 ViT | 新一代视觉基础模型 架构与应用综述

OpenCV学堂
发布于 2026-06-24 19:56:34
发布于 2026-06-24 19:56:34
DINOv3 ViT 架构
DINOv3 ViT 是一个自监督Transformer模型,可为广泛应用生成稳定、可迁移的密集视觉特征图。
它引入了创新的架构元素,如轴向旋转位置嵌入、寄存器令牌注入和 Gram 锚定,以增强长时间训练中的特征区分性。
其可扩展的配置支持多种任务,包括视频动作识别、医学图像分析、分割、遥感、目标检测、工业小样本缺陷分类与零样本缺陷检测与分割。
DINOv3 ViT 是在自监督学习范式下开发的一系列视觉Transformer模型,旨在为各种下游任务生成鲁棒、可迁移的密集视觉特征。
这些骨干网络提供多种规模和参数预训练模型,DINOv3 的决定性转变在于其专注于高度通用、非任务特定的预训练,使其能够即插即用地集成到众多视觉流程中,且通常无需微调。
架构、骨干网络和配置
DINOv3 提供多种Transformer模型规格,以适应不同的任务规模和资源限制,这些规格由层深度 L、嵌入向量维度 d 和注意力头数 H 定义。核心设计元素包括:
patch大小:
所有主要变体均使用 16×16 的输入patch,在更大的模型中有一些自定义设置(例如,ViT-H+ 中使用 14×14)。
位置编码:
采用带有抖动增强的轴向旋转位置嵌入(RoPE)作为标准配置。
寄存器token注入:
四个寄存器token位于 [CLS] token之前,用于调节全局-局部特征交换并正则化补丁范数。
层归一化/专用归一化:
独立的层归一化使得可以为全局和局部自监督学习目标进行特定于损失的归一化。
特征提取与特定应用适配
视频动作识别:
对帧进行中心裁剪、补丁嵌入,并独立地通过视觉变换器进行处理。特征在时间上进行池化以获得序列级表示。DINOv3 产生较高的轮廓聚类效果(0.31,对比 V-JEPA2 的 0.21),在静态、姿态中心动作上表现出色,但在依赖运动的动作上性能下降,证实了其空间-语义偏向(Kodathala 等人,2025年9月25日)。

医学图像分类:
基于 LoRA 的适配仅微调 DINOv3-H+ 中 0.1% 的参数,在强染色/几何增强和焦点损失下,于非典型有丝分裂图检测中实现了 0.8871 的平衡准确率。尽管与自然图像存在领域差异,骨干网络的不变性仍能稳健迁移(Balezo 等人,2025年8月28日)。
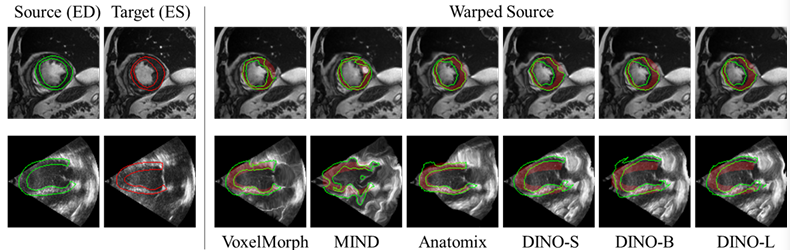
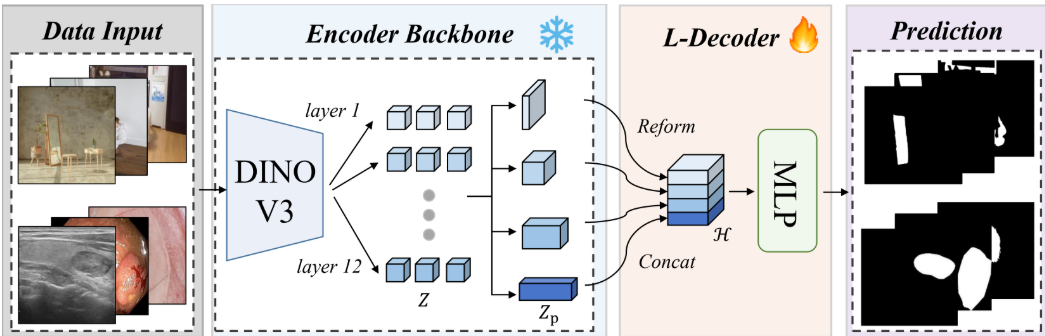
分割:SegDINO
将冻结的 DINOv3-S 与一个四层深度多级特征提取器、通道对齐模块和一个 2-3 层 MLP 解码器相结合,实现了高效的掩码预测。解码器头拥有约 5300 万个可训练参数,在六个分割基准测试中取得了最先进的结果(Yang 等人,2025年8月31日)。
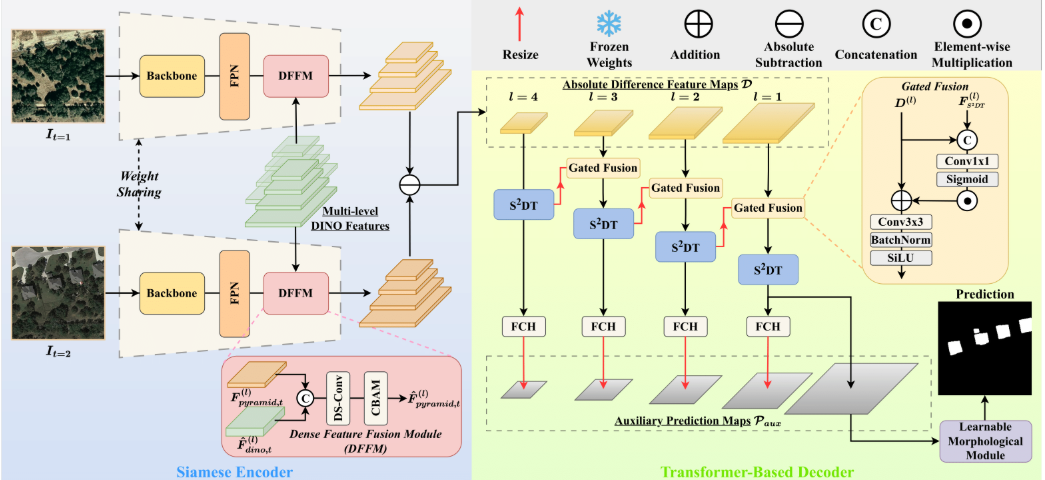
遥感变化检测:
ChangeDINO 将 DINOv3 金字塔特征(通过轻量级适配和融合)与一个空间-光谱差分变换器解码器融合,在四个基准测试中取得了新的最优交并比/ F1 分数。消融研究证实了 DINOv3 特征和差分解码的主要贡献。
目标检测:
DEIMv2 采用空间调谐适配器将单尺度的 DINOv3 输出转换为多尺度金字塔,为 DETR 头部整合了强语义信息和卷积神经网络派生的细节。DEIMv2-X 在 5030 万参数下达到 57.8 AP,是其规模下的最优水平,较小的变体在参数更少的情况下匹配了 YOLO 模型。
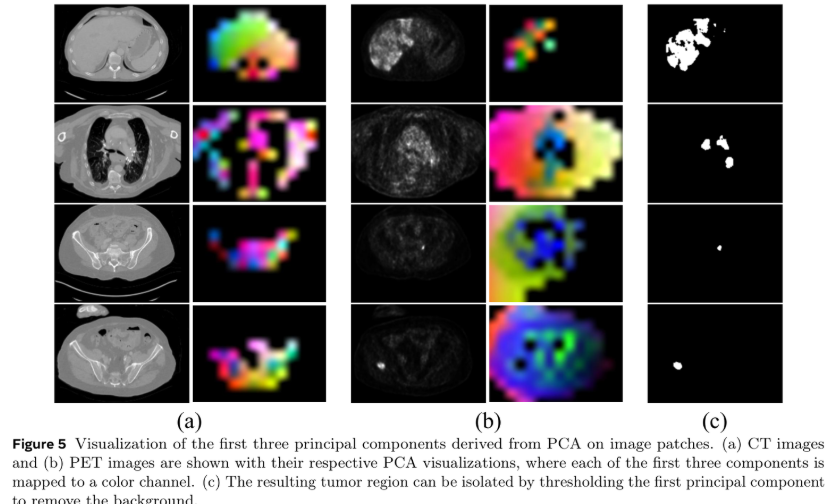
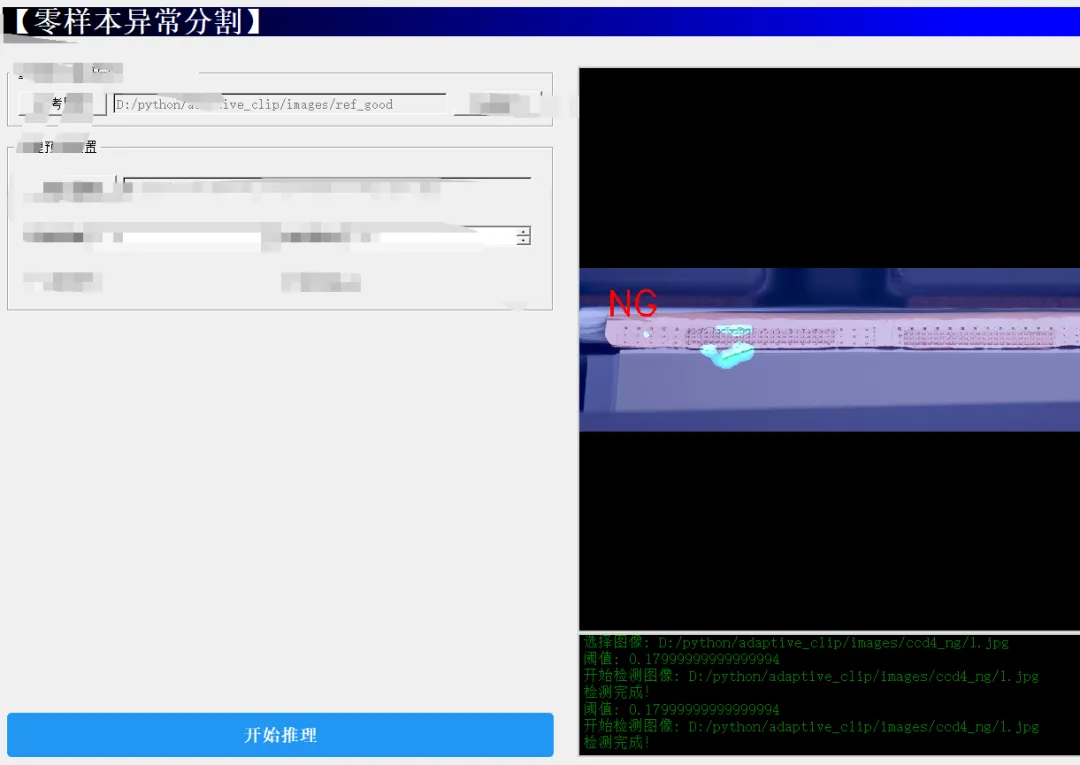
零样本工业缺陷检测
基于DINOv3实现的AVA-DINO 零样本学习异常,泛化能力碾压现有方法。基于DINOv3各层的特征输出采样构建的零样本工业缺陷检测应用已经呈现井喷爆发趋势。

图片
局限性、权衡与未来方向
领域差异:
DINOv3 的迁移效果取决于特征的通用性;在分布外场景中,可能需要进行特定领域的增强或适配(如 LoRA、适配器、数据增强)以获得稳健性能。
解码器极简主义:
包括 SegDINO 和 DEIMv2 在内的应用表明,当骨干网络足够强大时,使用极小权重的解码器即可实现高性能预测。
未来探索:
更大的 DINOv3 变体、特定领域的自监督预训练、更高秩的适配以及进一步的多模态对齐,被认为是扩展其应用前景的有希望的方向
DINOv3 ViT 为视觉基础模型在空间和密集任务上树立了新的参考标准,它桥接了自监督学习、架构扩展和参数高效适配,为广泛的科学和工业应用提供可迁移、高质量的特征向量输出。
2026年 大模型与多模态VLM模型在工业缺陷检测领域的优势在于真正意义上的“零样本”,无需针对特定任务训练,灵活度高,可应对开放词汇描述的新缺陷。工业支持急速五分钟换型、四张参考样本准确率可以达到99%。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号