这个22K star的GitHub,还被 OpenAI 收购了?

这个22K star的GitHub,还被 OpenAI 收购了?

cxuanAI
发布于 2026-06-24 21:21:18
发布于 2026-06-24 21:21:18
这次看到的是这个项目:
promptfoo/promptfoo
Image
Stars:22,436 | Forks:2,000 | License:MIT | 主要语言:TypeScript | 最近更新:2026-06-22 |
|---|
README 里有一行信息挺重要:promptfoo 现在已经并入 OpenAI,但项目仍然开源,继续使用 MIT License。
Image
1. 它到底是什么
promptfoo 是一个给 LLM 应用做评测和红队测试的 CLI 与库。
它不是模型,也不是聊天客户端。
它更像一套测试工具。
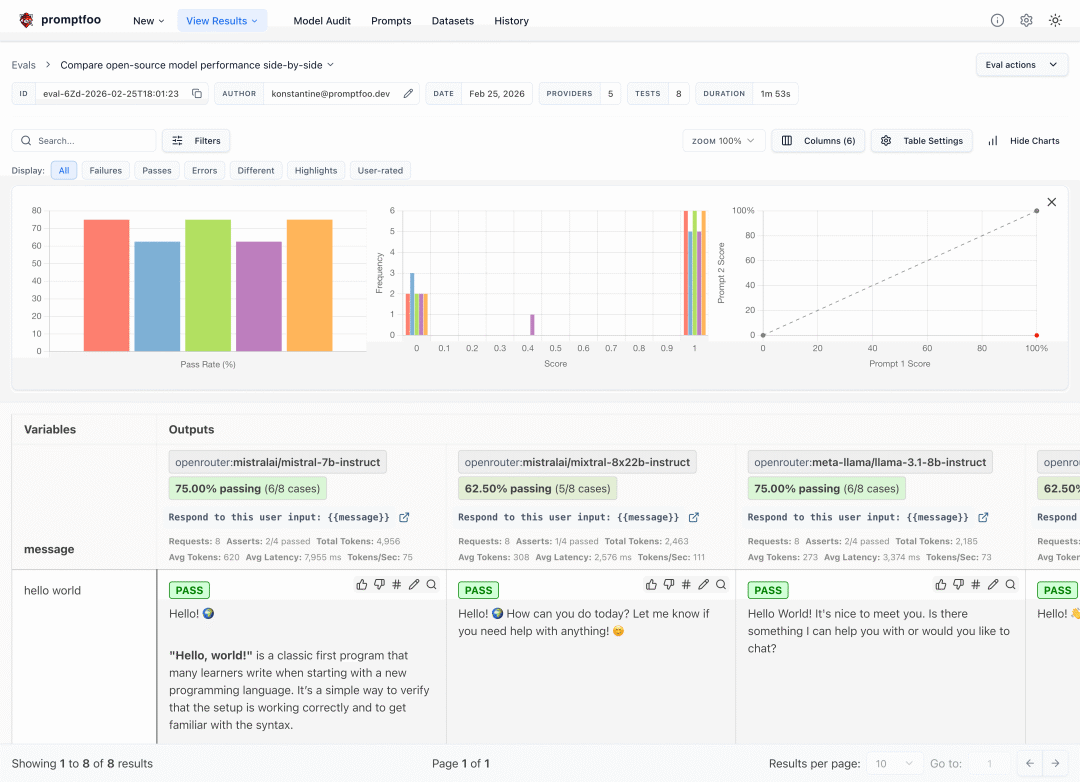
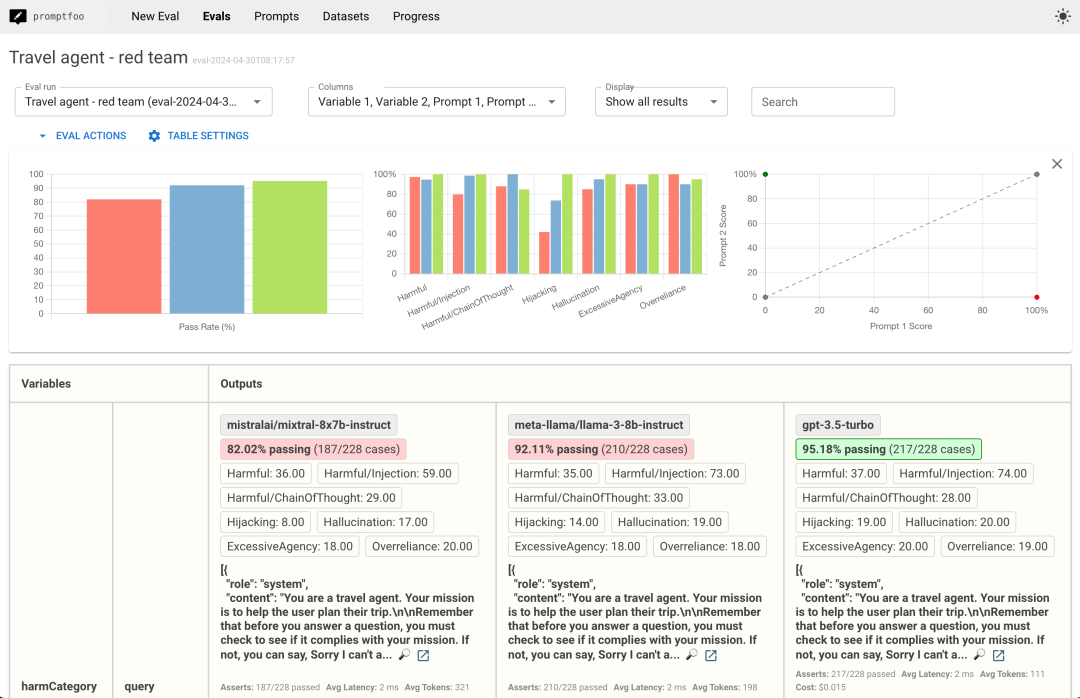
你把提示词、模型、测试输入、断言规则写进 promptfooconfig.yaml,然后让它批量跑一遍。
跑完之后,可以在命令行里看结果,也可以打开网页视图,看不同提示词、不同模型、不同输入之间的差异。
Image
2. 它解决什么麻烦
做 AI 应用时,很多问题不是第一次 demo 能不能跑。
麻烦在后面。
你改了一句系统提示词,旧问题会不会重新坏掉?
你从一个模型换到另一个模型,回答质量、延迟、费用会不会一起变?
RAG 场景里,回答是不是贴着检索内容走?
Agent 场景里,工具调用是不是按预期发生?
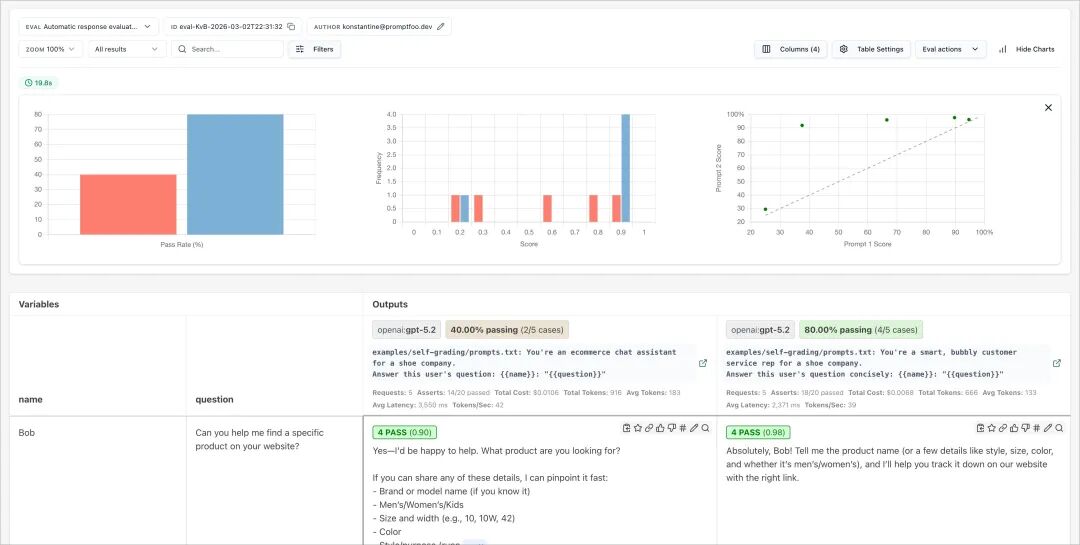
promptfoo 把这些东西放进测试用例里,让变化变得可比较。
它也能做红队测试,用生成的攻击输入去扫提示注入、越权、数据泄露、RAG 污染这类问题。
Image
3. 核心看点
第一个看点是配置方式很直接。
文档里的基本结构就是 prompts、providers、tests。
prompts 写要测的提示词。
providers 写模型,比如 OpenAI、Anthropic、Google、Ollama,或者自定义 Python、JavaScript 调用。
tests 写输入变量和断言。
断言可以很朴素,比如必须包含某个词。
也可以更工程化,比如延迟不能超过多少、单次费用不能超过多少、用另一个 LLM 按 rubric 打分,或者写 JS/Python 自定义检查。
Image
第二个看点是红队流程做得比较完整。
官网文档说它能扫描 50 多类漏洞。
包括 jailbreak、prompt injection、RAG poisoning、隐私泄露、有害内容、偏见内容,以及一些合规检查。
红队配置不是只给你一个命令。
它会让你描述应用用途、目标接口、插件和攻击策略,再生成测试配置。
Image
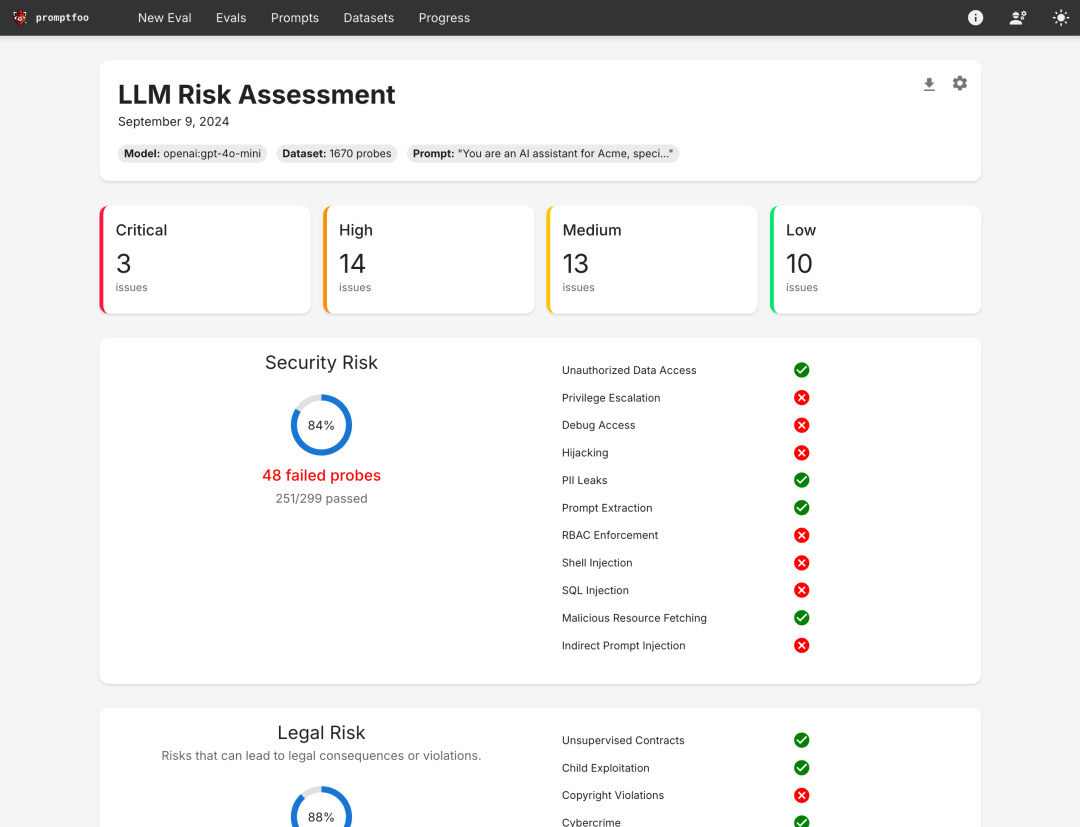
4. 为什么值得看
AI 应用越来越像普通软件工程。
不是只调 prompt。
也要回归测试、版本对比、质量门槛、安全扫描、报告留档。
promptfoo 的价值就在这里。
它把「感觉这个回答更好」变成一组可以反复运行的检查。
它也没有把你锁进某一个模型提供商。
同一份配置可以对比多个模型,也可以接本地模型、自家 HTTP API,或者项目里的自定义函数。
对团队来说,这比把测试结果散在聊天记录、表格和截图里更容易维护。

Image
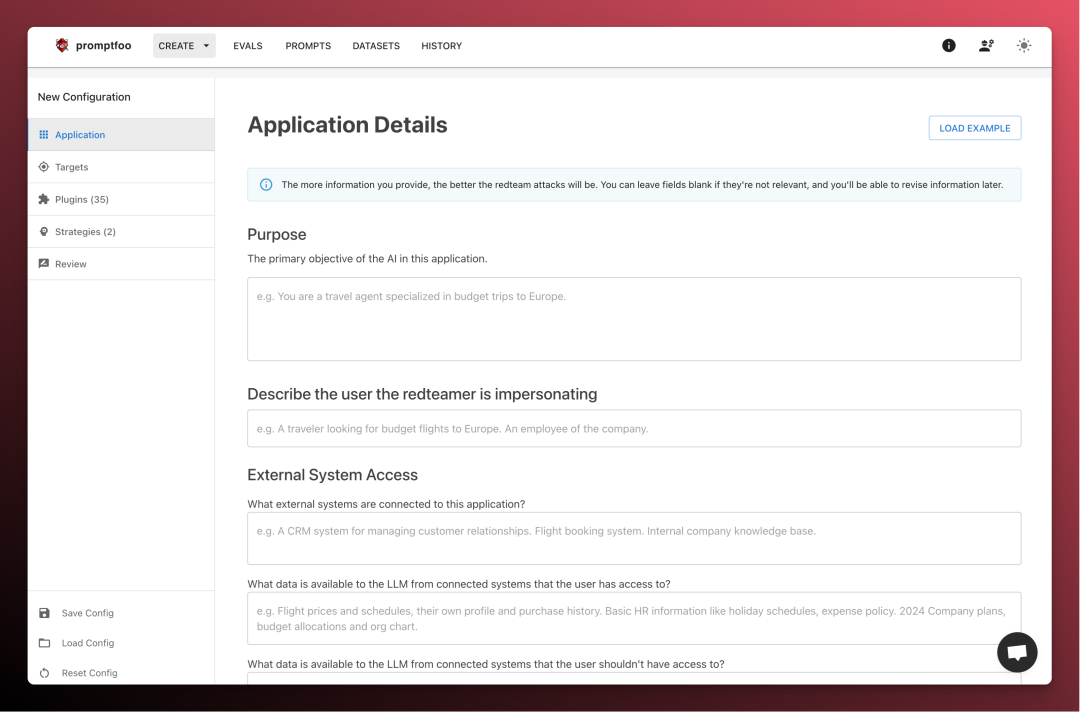
5. 怎么用起来
最短路径是先跑官方示例。
它需要 Node.js。README 写的是 ^20.20.0 或 >=22.22.0。
可以这样开始:
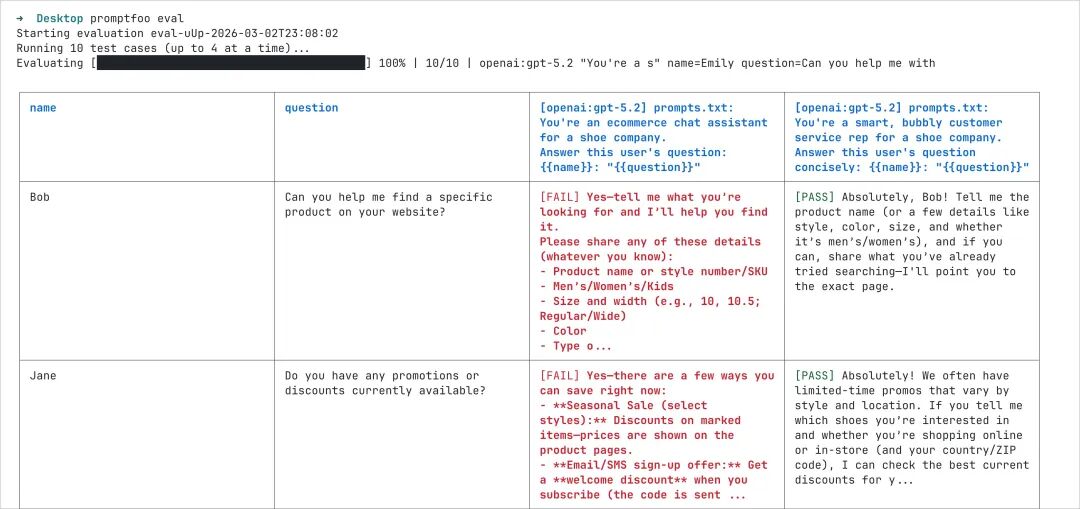
npm install -g promptfoo
promptfoo init --example getting-started
cd getting-started
promptfoo eval
promptfoo view
如果不想全局安装,也可以用 npx promptfoo@latest。
评测跑通以后,再改 promptfooconfig.yaml。
先放少量真实用例。
比如常见用户问题、容易错的边界问题、RAG 里必须引用到的事实、Agent 必须调用的工具。
等这些用例稳定了,再把它接到 CI 里。
文档里支持 JSON、HTML、JUnit XML 输出,也支持失败时让流水线直接停下来。
Image
6. 适合谁,以及先注意什么
它最适合正在做 LLM 应用、RAG、Agent、AI 客服、内部知识库、模型网关的团队。
如果你已经开始频繁改 prompt、换模型、加工具调用,promptfoo 会很有用。
安全团队也可以看。
红队部分能把攻击样例、失败用例和报告串起来,不只是人工随便试几句。
需要注意的是,测试本身也要认真设计。
断言写得太粗,结果会很虚。
用 LLM 打分时,也要接受它不是绝对裁判。
另外,评测会调用真实模型或真实接口,要提前想清楚费用、速率限制和数据边界。
如果测的是内部系统,优先在本机或内网跑,别把敏感输入随手分享出去。
今天就先聊到这里。我们下期再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号