AI大模型逆向工程-将IT业务系统蒸馏为独立的Skills技能包

AI大模型逆向工程-将IT业务系统蒸馏为独立的Skills技能包

人月聊IT
发布于 2026-06-25 11:53:50
发布于 2026-06-25 11:53:50
大家好,我是人月聊IT。今天分享一个对业务系统进行逆向工程和蒸馏的规范参考手册。即把已有业务系统蒸馏为"AI 可理解、可调用的领域能力中心"
本手册是一份可分享的标准与参考。任何人按本手册的流程、目录结构、文件模板与验收方法,都能对一个业务系统产出一套规范一致的蒸馏文档。文末附有完整的参考案例(合同管理系统)与使用方法。
1. 这是什么 / 解决什么问题
目标
把一个面向人使用的业务系统,逆向蒸馏为一个面向 AI 的"领域能力提供中心":
- 业务系统不再只是给人点的界面,而是一组可被 AI 调用的底层能力。
- 这些能力全部通过 API 暴露,AI 不直接访问数据库。
- 产出一套 Markdown 文档,让 AI 完整理解业务语义,从而能用自然语言完成录单、查单、统计等操作。
输入
业务系统已有的部分或全部资料:
- 原始需求文档
- 数据库(Schema / 实例)
- 本体模型 / 领域模型(如有)
- 源代码(尤其是服务层、接口层)
不要求四类资料齐全。多数项目只有其中两三类,手册流程对"资料不全"是兼容的。
输出
一套结构化 Markdown 文档(即 distilled/ 目录),分三层:
- 语义层:让 AI 建立"世界观",可全量加载。
- 能力层:业务用例级 API 说明,AI 据此操作业务。
- 明细层:字段级 Schema、枚举、错误码等,按需检索。
适用读者
- 蒸馏执行者(工程师 / 业务分析师):按本手册产出文档。
- 后续使用者(AI 应用开发者):把产物喂给 AI,构建自然语言业务助手。
2. 核心理念与六条设计原则
这六条是蒸馏成败的关键,贯穿全流程。模板和流程都是为落实这六条服务的。
原则一:语义层 / 明细层分离
产出物不是"一份大文档",而是分层的:
- 语义层(给 AI 推理):精炼的领域模型、关系、规则、每个 API 的"场景/输入/输出/约束"。要短、准、可全量加载。
- 明细层(给 AI 按需检索):完整字段、枚举、错误码等。不常驻上下文。
反例:把需求、Schema、API 全塞进一个上万行文件 → 塞不进上下文,AI 反而更糊涂。
原则二:API 以"业务用例"为粒度,而非 CRUD 原子接口
- ❌ 太细(CRUD 级):
insertOrderItem、updateStatus…… AI 要自己编排多步、极易违反业务时序。 - ❌ 太粗(界面级):照搬前端复合接口,夹带 UI 态字段,语义噪音大。
- ✅ 用例级:一个接口 = 一个完整、自洽的业务动作(如"录入合同""确认收款"),规则封装在服务端。AI 的一次意图 ≈ 一次调用。
蒸馏时从"原始需求里的业务动作"出发定义这层 API,源代码是实现参考,不是 API 设计标准。
原则三:每条规则必须标注"谁来保证"
【服务端强制】:违反会被接口拒绝。AI 只需知道,用于预判并向用户解释。【调用方需预判】:服务端不拦截,AI 调用前需自行判断或与用户确认。
不区分 → AI 要么过度兜底(多此一举),要么以为服务端会拦却没拦。
原则四:事实优先级明确,冲突单独记录
资料常互相矛盾(文档过期、代码才是真相):
- 业务意图 / 为什么 → 以需求 + 本体为准。
- 当前实际行为 / 规则细节 → 以源代码 + 数据库实际约束为准。
- 冲突时记录冲突本身(写入
model-code-conflicts.md),不要悄悄选一个——这往往是宝贵的业务债清单。
原则五:写权限分级,且最终要机制化
- 前期:AI 只开放读(查询/统计);写操作(CUD)需用户显式确认。
- 不要只靠在文档里写"请不要删除"——不可靠。
- 目标态:查询类与写入类接口/凭证物理分离,写操作走"预演 / 确认"模式(dry-run 校验 → 回显 → 确认 → 提交)。
原则六:可验证
蒸馏完成后必须验证:准备一组真实业务问答/操作测试集,让 AI 仅凭蒸馏文档去回答/操作,核对是否正确。把它当作蒸馏质量的回归测试。
3. 蒸馏前置:输入资料盘点与事实优先级
开始前,先填一张"资料盘点表",明确手上有什么、以谁为准。
3.1 资料盘点表(模板)
资料类型 | 是否具备 | 位置/路径 | 可信度 | 用途 |
|---|---|---|---|---|
原始需求文档 | 是/否 | 中 | 业务意图、术语、功能范围 | |
数据库 Schema | 是/否 | 高 | 数据结构、约束、枚举 | |
数据库实例数据 | 是/否 | 高 | 主数据、真实取值、种子数据 | |
本体 / 领域模型 | 是/否 | 中 | 对象关系、约束声明、状态机 | |
源代码(服务层) | 是/否 | 最高 | 实际业务规则、API 行为 | |
源代码(接口层/路由) | 是/否 | 最高 | API 清单、入参出参、鉴权 |
3.2 事实优先级(冲突时的裁决规则)
实际行为 / 规则细节: 源代码 > 数据库约束 > 本体 > 需求文档
业务意图 / 概念含义: 需求文档 > 本体 > 源代码注释
任何"本体/需求说 A,代码做 B"的差异,都记入
reference/model-code-conflicts.md,并在相关对象/接口文档中以 ⚠️ 标注。
3.3 资料不全时的降级策略
- 只有代码、没需求:从代码逆向业务动作和规则,需求章节标注"由代码反推,待业务确认"。
- 只有需求、没代码:能力层按需求定义"应有接口",并标注"接口待实现/未验证"。
- 没有本体:领域对象直接从 Schema + 代码归纳,跳过本体冲突核对。
4. 蒸馏流程(七个阶段)
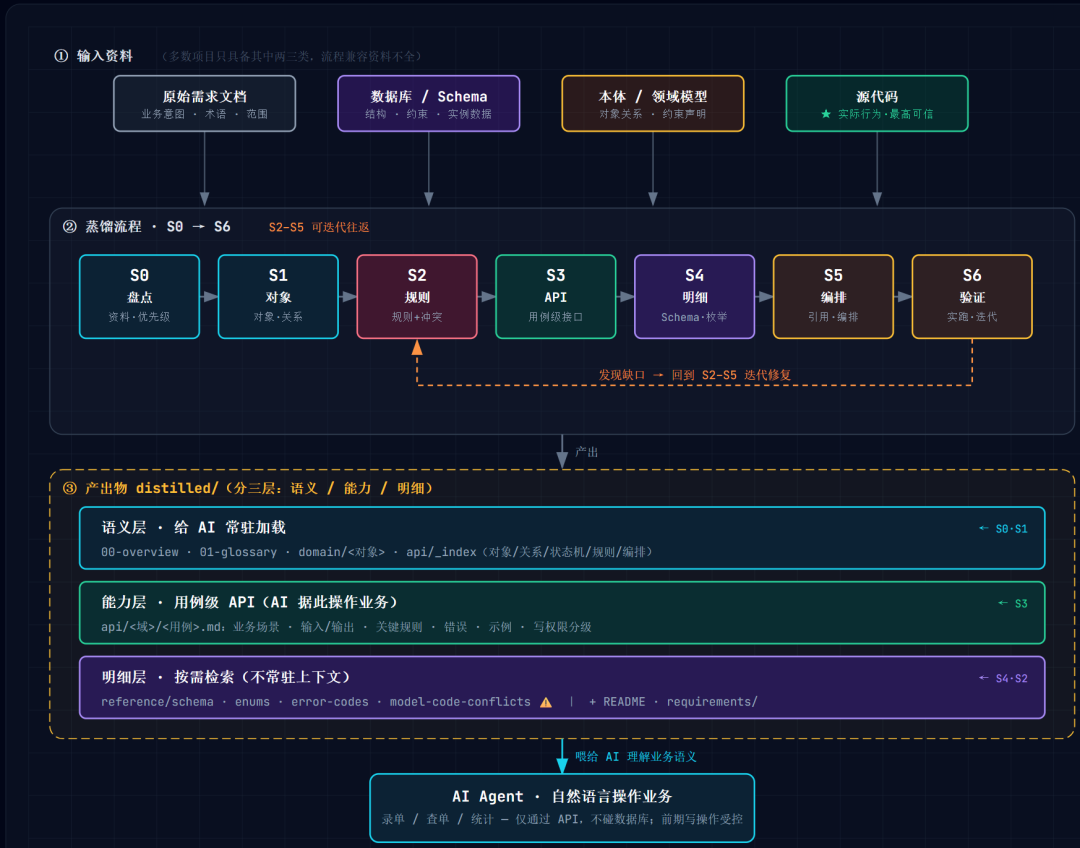
每个阶段有明确产出与检查点。建议顺序执行,但 S3–S5 可迭代往返。
S0. 准备与盘点
- 填写 §3.1 资料盘点表,确定事实优先级。
- 通读原始需求,建立对系统"是什么"的整体印象。
- 产出:资料盘点表;一段话的系统定位。
S1. 识别业务对象与边界(语义骨架)
- 从需求 + 本体 + 数据库表,归纳核心业务对象(聚合根、明细、主数据)。
- 厘清对象间关系(1:N、N:N、引用 vs 组合)、生命周期/状态机。
- 划清系统边界:管什么、不管什么。
- 产出:
00-overview.md初稿、domain/_index.md、各domain/<对象>.md初稿。 - 检查点:每个对象能用一句话定义;关系图自洽。
S2. 抽取业务规则并标注执行方
- 从源代码服务层抽取实际强制的规则(校验、状态流转、自动计算)。
- 与本体声明的约束比对,发现"声明了但代码没强制"的,记入冲突表。
- 给每条规则打
【服务端强制】/【调用方需预判】标签。 - 产出:各对象文档的"核心业务规则"段;
reference/model-code-conflicts.md。 - 检查点:每条规则都有执行方标注;冲突已登记。
S3. 定义能力层 API(用例级)
- 从"需求中的业务动作"出发列出用例(录入、开票、收款、查询、统计…)。
- 对照路由层/服务层,确认每个用例对应的真实接口(方法+路径+入参+出参)。
- 用例级粒度:必要时把多个原子接口合并描述为一个业务动作;剥离 UI 态字段。
- 产出:
api/_index.md、各api/<域>/<用例>.md。 - 检查点:每个用例能回答"什么场景用、输入什么、输出什么、有哪些规则、可能哪些错误"。
S4. 整理明细层(Schema / 枚举 / 错误码)
- 字段级 Schema,逐字段标"对应哪个领域属性/API 字段"。
- 汇总所有枚举/字典值,标注 ✅(代码在用)/ ⚠️(仅模型定义、未实现)。
- 汇总错误码与统一响应信封。
- 产出:
reference/schema/*.md、reference/enums.md、reference/error-codes.md。 - 检查点:API 文档里出现的每个枚举/错误码,明细层都能查到。
S5. 建立交叉引用与编排说明
- 用
[[slug]]把对象↔接口↔Schema 串起来。 - 在
api/_index.md写"自然语言意图 → 接口序列"的典型编排。 - 标注每个写接口的"写权限分级"。
- 产出:完善后的
api/_index.md、README.md、requirements/_index.md。 - 检查点:能顺着链接从"用户想做的事"走到"该调哪些接口、依赖哪些对象"。
S6. 验证(实跑)
- 准备测试集(§8.2),让 AI 仅凭
distilled/推导调用,再真打到接口验证。 - 修复发现的文档缺口,回到 S2–S5 迭代。
- 产出:验证记录 / 结论。
- 检查点:典型读、写、统计、规则反例场景全部通过。
S0 盘点 → S1 对象 → S2 规则 → S3 API → S4 明细 → S5 编排 → S6 验证
▲__________________________________|
(发现缺口则迭代)
5. 标准输出目录结构
distilled/
├── README.md 入口:阅读顺序、加载策略、目录导航、写权限提醒
├── 00-overview.md 系统全景 + 给 AI 的关键约定
├── 01-glossary.md 业务术语表(全局共享语义)
│
├── domain/ 【语义层】领域对象——建议给 AI 常驻加载
│ ├── _index.md 对象关系总览(文字版关系图)
│ ├── <对象A>.md 一个核心业务对象一个文件
│ └── <对象B>.md
│
├── api/ 【能力层】业务用例级接口
│ ├── _index.md 能力清单 + 典型编排
│ ├── <域1>/ 按业务域分子目录
│ │ ├── <用例1>.md 一个用例级接口一个文件
│ │ └── <用例2>.md
│ └── <域2>/
│
├── reference/ 【明细层】按需检索,不常驻上下文
│ ├── schema/ 字段级数据库 Schema
│ │ └── <表>.md
│ ├── enums.md 全部枚举/字典值
│ ├── error-codes.md 错误码与统一响应
│ └── model-code-conflicts.md ⚠️ 本体/需求 与 代码 的差异清单
│
└── requirements/
└── _index.md 原始业务需求(蒸馏来源,保留可追溯)
命名约定
- 文件名用小写 kebab-case(如
create-contract.md)。 - 领域对象文件名 = 对象英文别名(如
contract.md)。 - API 文件名 = 用例动作(如
create-contract.md、query-contracts.md)。
6. 文件模板参考(逐类)
以下每个模板都可直接复制填写。
<尖括号>为占位符。模板后附"填写说明"。
6.1 README.md(入口)
# <系统名> · 蒸馏文档(AI 能力说明书)
本目录把<系统名>蒸馏为一套 AI 可理解、可调用的领域能力说明。
AI 仅通过 API 操作业务,**不直接访问数据库**。
## 阅读顺序 / 加载策略
**语义层(建议常驻加载给 AI):**
1. 00-overview.md — 系统全景与给 AI 的约定
2. 01-glossary.md — 业务术语
3. domain/ — 领域对象
4. api/_index.md — API 能力清单与典型编排
**明细层(按需检索):**
- api/ — 各业务用例接口详情
- reference/schema/ — 字段级 Schema
- reference/enums.md / error-codes.md
- reference/model-code-conflicts.md — ⚠️ 重要:模型与代码差异
**来源:** requirements/_index.md
## 目录结构
<贴出本系统的目录树>
## 关键提醒(写操作权限)
<前期只读/写需确认/不可逆操作说明>
6.2 00-overview.md(系统全景)
# <系统名> · 能力总览
> 本目录是对<系统名>的蒸馏产物:把系统下沉为可被 AI 调用的领域能力中心。
> AI 通过本文档理解业务语义,并**只能通过 API**操作业务。
## 这是什么系统
<2~4 句:系统定位、服务谁、核心价值>
## 业务边界
- 管理什么:<...>
- 不管理什么:<...>(划清边界,避免 AI 越界假设)
## 核心业务链路(一句话)
<用一句话串起主流程,如:录入 → 开票 → 收款>
## 核心业务对象
| 对象 | 说明 | 详见 |
|------|------|------|
| <对象A> | <一句话> | [[对象A-slug]] |
## 能力清单(API 概览)
| 能力 | 类型(读/写) | 详见 |
|------|------------|------|
| <能力> | 写 | [[用例-slug]] |
## 给 AI 的关键约定
1. 永远通过 API 操作,不直接读写数据库。
2. 引用类字段是 ID 不是名称——先调<主数据接口>解析。
3. 金额/状态等由服务端计算或裁决。
4. 写操作权限分级:<前期策略>。
5. 规则标注 【服务端强制】/【调用方需预判】 的含义。
## 技术事实(便于排错,非业务语义)
- 技术栈、数据库、统一响应信封、鉴权方式、错误码入口。
填写说明:这是 AI 最先读的文件,必须短而全。"给 AI 的关键约定"是行为护栏,务必写清 ID 解析、服务端权威、写权限。
6.3 01-glossary.md(术语表)
# 业务术语表(Glossary)
> 全局共享语义。出现歧义时以本表为准。
| 术语 | 英文/别名 | 含义 |
|------|-----------|------|
| <中文术语> | <Alias> | <含义;指明它在业务中的角色与关键约束> |
填写说明:把需求里反复出现的名词、代码里的对象别名、用户口语的叫法对齐到一起。一个术语一行,含义要点到关键约束(如"比例合计必须=1")。
6.4 domain/_index.md(对象关系总览)
# 领域模型总览
> 语义层。描述业务对象、关系、生命周期。字段级细节见 reference/schema/。
## 对象关系(文字版)
```
<用 ASCII 画出对象间引用/组合关系>
```
## 关键关系说明
- <对象A> 1:N <对象B>:<组合还是引用,级联行为>
- <对象A> N:N <对象C>(通过<中间对象>)
## 对象清单
| 对象 | 角色(聚合根/明细/主数据) | 文档 |
|------|--------------------------|------|
| <对象A> | 聚合根 | [[对象A-slug]] |
6.5 domain/<对象>.md(业务对象)— 核心模板
# 业务对象:<中文名> (<Alias>)
## 一句话定义
<它是什么、在业务中扮演什么角色>
## 业务语义
<2~4 句:它代表什么、在流程中的位置、谁创建谁消费>
## 生命周期 / 状态
<状态机:状态A → 状态B → ...;每个状态含义与触发动作>
> ⚠️ 已知差异:<模型定义但代码未实现的状态>,见 [[model-code-conflicts]]
## 关键属性(语义级,非字段级)
| 属性 | 含义 | 约束/来源 |
|------|------|-----------|
| <attr> | <含义> | <必填/唯一/服务端维护/引用 [[xx]]> |
## 组合 / 关系
- 包含 <明细对象>(基数,组合/引用,级联行为)
- 引用 [[主数据]]
- 被 [[其它对象]] 引用
## 核心业务规则
1. 【服务端强制】<规则>,违反报"<错误消息>"。
2. 【服务端维护】<由系统自动计算/更新的字段>。
3. 【调用方需预判】<服务端不拦但业务要求的约束>。
4. 【副作用】<该对象变更触发的连锁动作>。
## 相关能力
- 录入:[[create-xx]] 查询:[[query-xx]] 详情:[[get-xx-detail]]
## 明细索引
- 字段级 Schema → reference/schema/<表>.md
- 枚举值 → [[enums]]
填写说明:属性表是语义级(合并/省略技术字段),字段级放 Schema。规则段是本对象的灵魂,每条必带执行方标签。
6.6 api/_index.md(能力清单 + 编排)
# API 能力清单
> 业务用例级接口。统一响应信封:<贴出信封结构>。"输出"均指 data 部分。
> 鉴权:<说明>。
## 业务能力(AI 主要使用)
| 能力 | 方法 + 路径 | 读/写 | 文档 |
|------|------------|-------|------|
| <能力> | POST /api/... | 写 | [[slug]] |
## 平台/辅助接口(一般不直接暴露给业务对话)
| 接口 | 方法 + 路径 | 用途 |
|------|------------|------|
## 典型编排(自然语言 → 接口序列)
- **"<用户说的话>"** → [[接口1]] 解析… → [[接口2]] 执行。
填写说明:把"业务能力"和"平台/辅助接口"分开列——AI 主要用前者。"典型编排"是把单接口拼成业务流的关键,直接降低 AI 出错率。
6.7 api/<域>/<用例>.md(用例级接口)— 最重要模板
# 接口:<中文动作名> (<接口标识>)
`<HTTP方法> <路径>`
## 业务场景
<什么情况下用;给一句用户自然语言示例;强调它是完整业务动作而非底层 CRUD>
## 能力边界
- 做什么:<...>
- 不做什么:<...>(划清边界,避免 AI 误用)
## 输入(<Body/Query>)
| 参数 | 类型 | 必填 | 说明 | 约束 |
|------|------|------|------|------|
| <param> | <type> | 是/否 | <含义> | <取值/引用 [[xx]]> |
> <不需传入、由服务端生成的字段说明>
## 输出(data)
| 字段 | 说明 |
|------|------|
| <field> | <含义;服务端计算的标注出来> |
## 关键规则
1. 【服务端强制】<规则> → "<错误消息>"。
2. 【调用方需预判】<AI 调用前要保证的事>。
3. 【服务端维护/副作用】<自动更新/触发的连锁>。
## 涉及的数据对象
- 主对象:[[对象]] 关联:[[对象]]
## 可能的错误
| message / errorCode | 含义 | AI 应如何向用户解释 |
|---------------------|------|---------------------|
## 调用示例
```json
<一个真实可用的请求 body>
```
## 写权限分级
- 当前阶段:<只读/受控写/禁用>;<是否需 dry-run+确认;是否不可逆>
填写说明:这是整套文档里 AI 用得最多的文件。"业务场景 + 能力边界 + 关键规则 + 可能的错误"四段决定 AI 用得对不对。示例必须是能直接跑通的真实数据。
6.8 reference/schema/<表>.md(字段级 Schema)
# 表:<表名>(<中文说明>)
> 对应领域对象 [[对象]]。AI 不直接访问,仅供理解语义与排错。
| 字段 | 类型 | 含义 | 约束 | 对应领域属性/API字段 |
|------|------|------|------|----------------------|
| <col> | <type> | <含义> | <PK/FK/UNIQUE/NOT NULL/DEFAULT> | <camelCase 字段> |
## 索引与约束体现的业务规则
- <唯一键/外键 → 对应哪条业务规则>
填写说明:关键价值在最后一列"对应领域属性/API字段"——它把数据库命名(snake_case)和 API 命名(camelCase)对齐,是 AI 排错的桥梁。
6.9 reference/enums.md(枚举)
# 枚举 / 字典值
> ✅ = 代码实际使用;⚠️ = 仅模型定义、代码未实现(见 [[model-code-conflicts]])。
## <对象>.<字段>
| 值 | 状态/含义 | 标记 |
|----|-----------|------|
| <值> | <含义> | ✅ |
| <值> | <含义> | ⚠️ |
## 主数据示例值(以实时<主数据接口>结果为准)
- <类型>:<示例取值>
6.10 reference/error-codes.md(错误码)
# 错误码与错误处理
> 统一信封:<结构>。失败时 <字段约定>。
## errorCode 总览
| errorCode | HTTP | 含义 | 典型来源 |
|-----------|------|------|----------|
## 给 AI 的处理建议
1. <每类错误 AI 该怎么处理/解释/是否重试>
6.11 reference/model-code-conflicts.md(差异清单)
# 本体模型 ↔ 代码实现 差异记录
> 蒸馏时发现的"本体/需求"与"实际代码"不一致之处。
> **实际行为以代码为准**;本表帮助 AI 不做错误假设,也是后续治理清单。
## N. <差异标题>
- 本体/需求:<声明>
- 代码:<实际>
- AI 影响:<AI 应注意什么>
---
维护建议:<如何收敛这些差异>
6.12 requirements/_index.md(原始需求)
# 原始业务需求
> 蒸馏来源之一,保留可追溯。原文见 <路径>。
> 注意:与实际代码的差异见 [[model-code-conflicts]]。
## 业务范围
<原文摘录/整理>
## 关键业务对象(原文)
<原文摘录>
## 需实现的业务功能(原文)
1. <功能> → [[对应接口]]
## 蒸馏时补充识别出的能力(需求未明确,但代码已实现)
- <能力> → [[接口]]
7. 关键规范与约定
7.1 规则执行方标注(强制)
【服务端强制】:违反被接口拒绝。【服务端维护】:由系统自动计算/更新,调用方不可设置。【调用方需预判】:服务端不拦,AI 需自行保证或与用户确认。【副作用】:该动作触发的连锁(事件、重算等)。
7.2 交叉引用
- 一律用
[[slug]],slug= 目标文件名(不含.md)。 - 链接到尚不存在的文件也允许——它标记"待补",不是错误。
- 对象↔接口↔Schema 三者之间要互相链接,形成可追溯网。
7.3 命名
- 文件:小写 kebab-case。
- API 字段:沿用代码实际返回的命名(通常 camelCase),不要自创。
- 枚举值:用业务实际值(含中文),不要翻译。
7.4 粒度
- 一个领域对象一个文件;一个业务用例一个文件。
- 接口粒度按业务动作,不按表的 CRUD。
7.5 "实际为准"
- 入参/出参/错误消息以代码实际行为为准,逐一核对,不臆测。
- 与需求/本体不一致的,照实写代码行为,并登记到冲突表。
8. 质量验收:如何确认蒸馏对了
8.1 静态检查清单
- [ ] 每个领域对象有一句话定义、状态机、规则段。
- [ ] 每条规则有执行方标注。
- [ ] 每个业务用例接口四要素齐全(场景/输入输出/规则/错误)。
- [ ] API 文档出现的枚举、错误码,明细层都能查到。
- [ ] 交叉引用无明显断链。
- [ ] 冲突清单已建立。
8.2 动态验证(实跑)——强烈推荐
准备一组真实场景测试集,让 AI 仅凭 distilled/ 推导出应调用的接口序列,再真打到运行中的系统,核对结果。建议覆盖四类:
类型 | 示例 | 验证什么 |
|---|---|---|
读/查询 | "查 X 部门今年的合同" | 名称→ID 解析、查询参数 |
写/录入 | "给客户 A 录个合同……" | ID 解析、必填、用例编排、服务端维护字段 |
统计 | "未来三个月各部门预计收多少" | 统计接口口径理解 |
规则反例 | 故意违反规则(如比例≠1、重复操作) | "关键规则/可能的错误"是否准确预测 |
判定标准:AI 能正确解析名称、推导前置条件、按正确顺序编排接口、预判并解释规则错误,且字段/枚举/错误消息与真实系统一致 → 文档可用性通过。
参考案例 §9 给出了合同管理系统实跑验证的真实过程与结论。
9. 完整参考案例:合同管理系统
本案例是按本手册产出并已实跑验证通过的真实样例,可作为新蒸馏的对照基准。
9.1 系统简介
一个销售合同管理系统,只管理"已签字盖章生效后"的合同:合同信息维护 → 按付款条款分阶段开票 → 客户付款后确认收款;每次变动自动重算"未来 3 个月分部门收款预算"。
9.2 输入资料
- 原始需求:
合同管理原始需求.txt - 源代码:
code/backend(Flask + SQLite)——API 与规则的真相来源 - 本体模型:
models/contract/m1-object-model.yaml
9.3 产出目录(节选)
distilled/
├── 00-overview.md, 01-glossary.md, README.md
├── domain/ : _index, contract, invoice, master-data
├── api/
│ ├── _index.md
│ ├── contract/ : create-contract, query-contracts, get-contract-detail
│ ├── invoice/ : create-invoice, query-open-invoices
│ ├── payment/ : receive-payment
│ ├── reference/: get-reference-data
│ └── analytics/: receipt-budget
├── reference/ : schema/(contracts,invoices,payment-terms-and-mappings,master-data), enums, error-codes, model-code-conflicts
└── requirements/_index.md
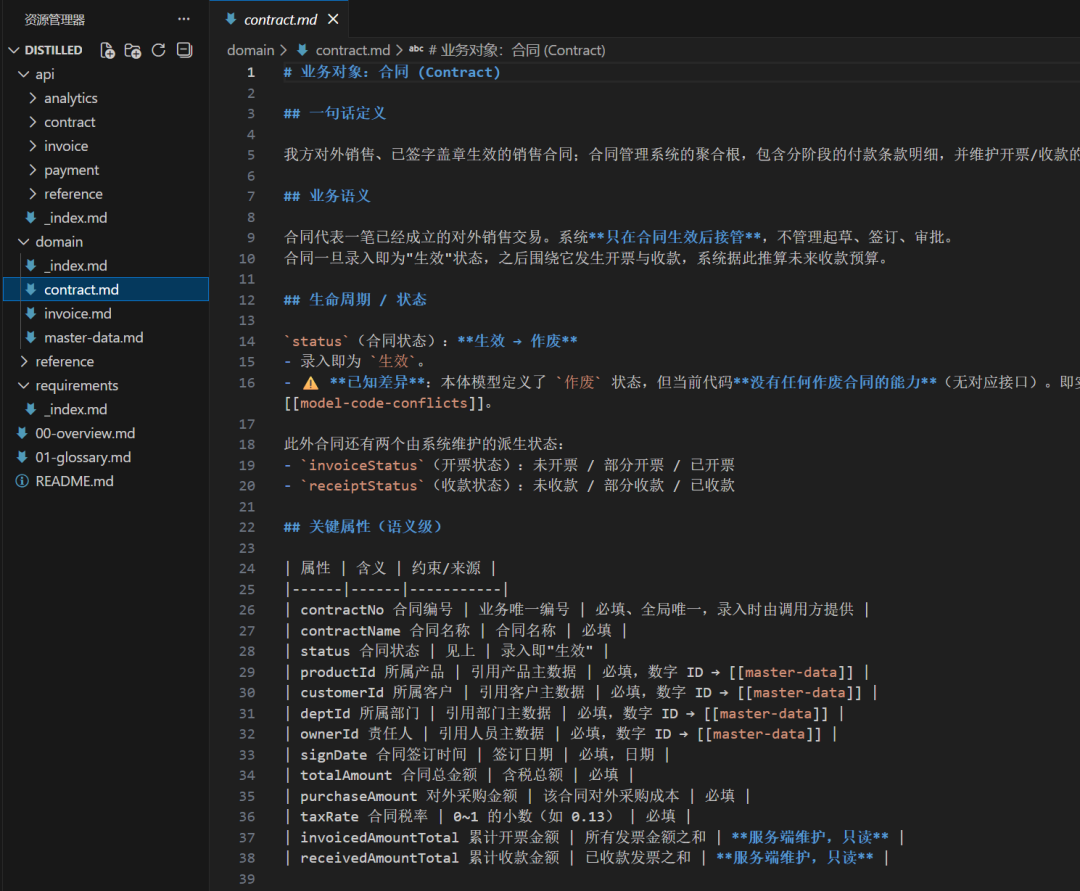
9.4 领域对象样例(合同,节选)
- 一句话定义:我方对外销售、已签字盖章生效的销售合同;聚合根,含分阶段付款条款,并维护开票/收款累计汇总。
- 状态:
生效 → 作废(⚠️ "作废"本体定义但代码未实现)。 - 规则样例:
- 【服务端强制】付款比例合计必须 = 1,否则报"付款比例合计必须等于 1"。
- 【服务端维护】累计开票/收款金额、开票/收款状态由系统在开票/收款时更新。
- 【调用方需预判】采购额≤总额、税率∈[0,1]——本体要求但代码未强制。
9.5 用例级接口样例(录入合同,节选)
POST /api/behaviors/Contract_Create/execute- 场景:"给华东能源录个合同,软件平台产品,销售一部张敏负责,48 万,税率 13%,分预付 30%/验收 40%/尾款 30%"。
- 能力边界:创建"生效"合同+付款条款,触发预算重算;不解析名称(需先取主数据)、不开票收款。
- 输入:contractNo, contractName, productId, customerId, deptId, ownerId, signDate, totalAmount, purchaseAmount, taxRate, paymentTerms[]。
- 关键规则:编号唯一、付款条款≥1、比例合计=1;引用 ID 须来自主数据接口。
- 写权限分级:受控写,先回显(名称→ID 映射、比例合计)给用户确认后再调用。
9.6 差异清单样例(model-code-conflicts,节选)
- 合同"作废"状态:本体定义,代码无作废能力。
- 开票"已冲销"状态:本体定义,代码未实现。
- 采购额/税率边界:本体声明约束,代码未校验 → 标为【调用方需预判】。
- 需求"产品线" = 代码"产品类型"(productType)。
- 收款粒度:需求泛指,代码实为"对单张发票整额确认,不支持部分收款/撤销"。
9.7 实跑验证结论
仅凭 distilled/ 文档,AI 成功完成端到端链路:
- 录合同:自动
GET /meta/reference-data把"星河制造/集成交付服务/销售二部/李强"解析为 ID →POST Contract_Create,返回字段与文档逐字段吻合。 - 开票→收款:先
GET Contract_GetDetail推导出"可开票、剩余可开票额、合法阶段" → 开票 → 确认收款;复查详情显示状态自动流转为"部分开票/部分收款"。 - 查待收款:
POST open-invoices,已收款的发票正确地不在列表中。 - 统计:
GET /events/runs返回分部门收款预算,口径与文档一致。 - 规则反例:比例≠1、对已收款发票重复确认,均按文档预测被拒并返回文档所述错误消息。
结论:文档可用性通过。 字段名、枚举、错误消息、服务端维护逻辑与真实系统完全对得上。
10. 使用方法
10.1 作为蒸馏执行者,如何用这份手册产出文档
- 按 §3 填资料盘点表,定事实优先级。
- 在目标系统仓库新建
distilled/目录。 - 按 §4 的 S0→S6 流程推进;每个文件套用 §6 对应模板。
- 边做边用 §7 规范自检,用 §12 检查清单收尾。
- 按 §8.2 实跑验证,迭代修复缺口。
可借助 AI 加速:把单个源码服务文件 + 对应模板喂给 AI,让它产出初稿,再人工核对"实际为准"。
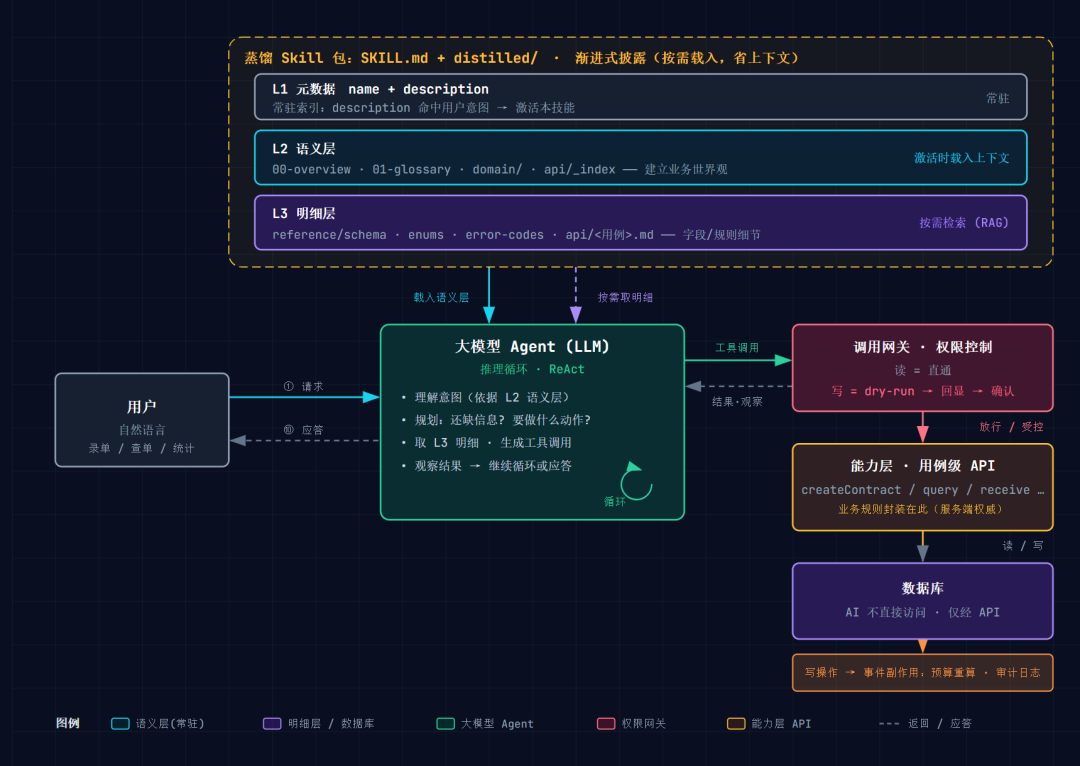
10.2 作为 AI 应用开发者,如何把产物用起来
- 常驻上下文:把语义层(
00、01、domain/、api/_index.md)注入系统提示或检索的高优先级片段。 - 按需检索:把明细层(
reference/、各api/<用例>.md)做成可被 AI 检索的知识库(RAG / 工具),AI 需要时再取。 - 接口对接:按
api/文档把真实 API 注册为 AI 可调用的工具(function calling)。 - 运行时护栏:把
00-overview.md的"给 AI 的关键约定"写进系统提示。
10.3 写权限控制的落地建议(机制化)
- 前期:只把查询类接口注册为 AI 工具;写接口不注册或需人工确认。
- 进阶:加一层调用网关,按路由白名单放行(GET/查询类直接放行,写操作走 dry-run 校验 → 回显 → 用户确认 → 提交)。
- 不可逆操作(如确认收款无撤销)必须强制二次确认。
基于这套蒸馏规范模板,我们对合同管理系统进行蒸馏。输出完整的Skills技能包,具体如下:
基于这套技能包,我们再做一个AI自然语言对话客户端。该客户端可以动态的价值我们刚才输出的完整技能。
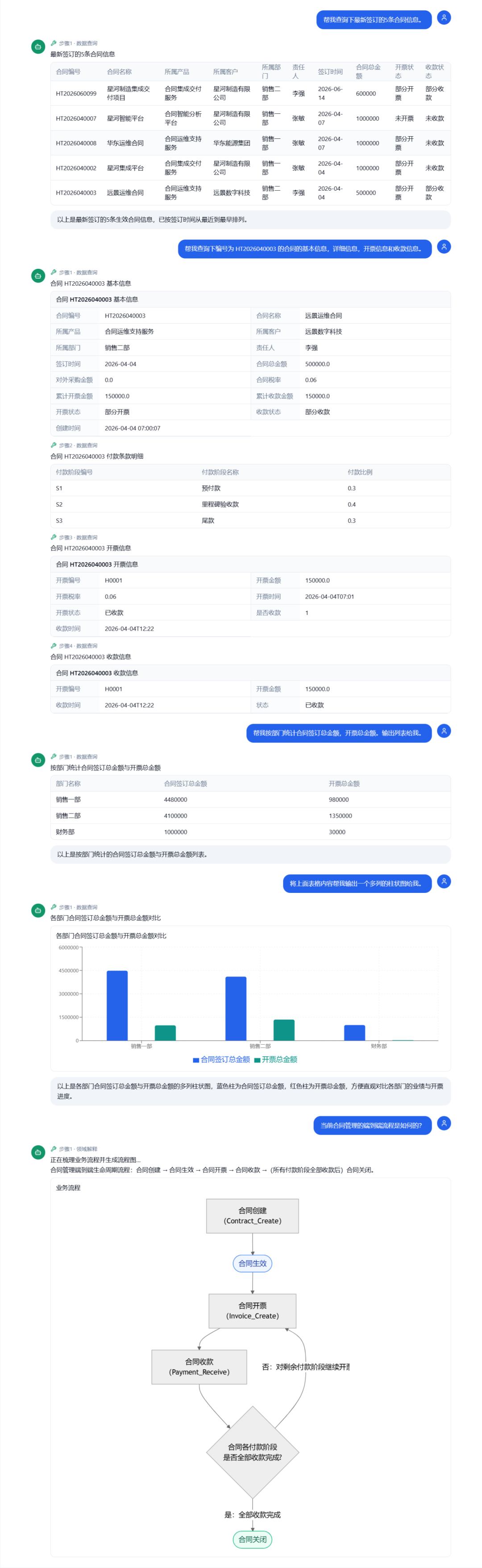
基于该技能包,我们就可以愉快的和合同管理系统进行自然语言对话了,大家可以看下具体参考的对话输出结果。
今天的分享就到这里,希望对大家有所启发。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号