AI驱动的数字化转型-所有的IT系统都应该CLI化,成为AI的底层能力

AI驱动的数字化转型-所有的IT系统都应该CLI化,成为AI的底层能力

人月聊IT
发布于 2026-06-25 11:55:12
发布于 2026-06-25 11:55:12
大家好,我是人月聊IT。
在今年年初的时候,我就强调了在AI赋能方面我今年的一个研究重点是AI辅助下对企业已有的IT资产进行逆向建模。其核心的一个原有就是企业数字化发展多年,实际已经构建了大量的IT系统,如何让这些存量IT系统能够快速的融入到AI赋能这个大框架才是关键。AI时代,从0到1构建一个全新的系统容易,真正难的反而是存量系统的改造优化和融入AI。
我在前面专门发过多篇AI逆向的文章,包括还发布了一篇通过AI辅助对已有的IT系统进行逆向建模和蒸馏,形成一个独立的Skills技能包,然后再作为底层能力接入到通用AI智能体。大家也可以参考。
大家要注意,对于任何一个IT系统实际包括三个方面的关键能力。第一是展现层UI和用户进行人机交互协同的能力;第二是逻辑层处理复杂流程和业务的能力;第三是数据库,实现结果的持久化存储和结构化的能力。
在AI时代,UI界面部分的能力将会变得越来越不重要。核心原有就是原来的所有人机交互UI,核心都是人在和机器打交道。但是AI时代,和IT系统打交道的可能不是人,而是通用的AI智能体或数字人。而看起来对人优化的UI界面,实际上对AI完全不友好。对AI真正优化的就是精确的结构化语义+API接口。
从CLI-Anything到Computer Use
香港大学数据智能实验室在今年早些时候发布了一个叫CLI-Anything的开源项目。其核心定位是一个自动化的“CLI生成器”:只要给定任意软件的源代码仓库,它就能自动为该软件生成一套功能完备、可供AI直接调用的命令行接口(CLI)。
那这个项目究竟解决了什么问题?
在CLI-Anything出现之前,AI要使用Blender(3D建模)、GIMP(图像编辑)或LibreOffice(办公套件)等专业软件,主要面临两大困境。其一是GUI自动化方案,即让AI模拟人类“看屏幕”和“点鼠标”,这种方式极其脆弱,界面布局的细微变化或意外弹窗都会导致操作失败;其二是手动编码方案,即为每个软件单独编写适配代码,但这种方式不仅开发成本高昂,且软件版本迭代后适配代码极易失效。
CLI-Anything精准解决了上述两大痛点。它的核心解决思路是绕过图形界面,直通软件内核。通过一个涵盖源码分析、命令设计、代码生成、测试打包等七个环节的全自动流水线,该项目能够深入解析软件的底层函数与逻辑接口,从而自动生成稳定、高效的命令行工具。由于生成的命令直接调用软件的真实后端引擎(而非模拟前台操作),其执行具有极高的可靠性和确定性。
接着我们还可以看看OpenAI的GPT5.5,特别是Codex桌面版新增加的一个Computer Use功能。
这个功能的核心是让AI能像人一样,通过“看”屏幕截图、移动光标、点击按钮和输入文字,来直接操作电脑上的各种软件和操作系统界面,而不仅仅是依赖API或命令行。
在OpenAI的生态中,驱动Codex或Operator等产品实现Computer Use的核心模型,被称为CUA(Computer-Using Agent,即“计算机使用智能体”)。这个模型将视觉识别能力与逻辑推理相结合,形成一个“观察-计划-执行”的闭环,从而自主完成任务。
但是实际上我的理解Computer Use也仅仅是一个短期过渡功能,终极目标就是CLI化,而不是让AI模拟人去操作GUI界面。正如我原来谈RPA机器人一样的道理,RPA仅仅是一个折衷解决集成和自动化的方案,而不是一个终极的目标方案。
包括在使用Computer Use功能的时候你也可以看到。类似你让AI模拟你操作去绘制一个流程图,如果这个绘图软件本身支持类似MD文件导入,那么AI一定是优先考虑先写MD文件,再通过导入的方式进行绘图。这也可以简要体现AI操作和人操作的一些关键区别。
传统IT系统能力是如何接入的?
好了,我们再来看下传统IT系统的能力是如何接入AI大模型的。
大家比较熟悉的还是类似ChatBI,智能问数这些AI产品。这个就是我们前面谈到的AI直接对接到传统IT系统的数据层或对接到已经进行了数据采集集成的数据湖,ODS层等。然后通过NL2SQL的方式来实现自然语言对话。但是这种方式本身存在的问题还是查询的幻觉问题,直接对数据库底层进行操作带来的安全隐患等。一般的底层数据库往往并没有承载业务逻辑,也就是我经常说的数据库里面只有静态的数据模型,没有数据形成,数据变化会导致影响的动态行为和规则模型。要想单纯的通过ChatBI来实现业务系统整体能力的对外提供显然是不可能的事情。
而对于业务系统,我个人做SOA项目多年,一直在强调SOA横向分层的思路,包括如何识别遗留系统的能力,将其发布为对外可以复用的业务服务能力接口,统一注册到总线或网关。但是基于个人多年的SOA项目实践来看,所有的总线网关,集成问题解决了,但是能力共享复用的问题仍然没有解决。如果这些注册到总线上的API接口都是对外可用复用的能力,那么对于业务能力的AI接入,最简单可行的方式就是我前面谈到的将整个网关发布为MCP Server,然后接入到AI大模型中。
但是这个本身也存在新问题。如果只是简单的类似查询供应商,录入订单这种对话,AI完全可以精确识别用户意图并调用API接口获取数据返回。但是类似发起一个退货处理这种,往往涉及到要多个API接口能力进行组装,AI往往就无法精确的进行处理。这个也是我常说的,在最终用户问题场景和底层API能力间,还有一个关键的API编排层,这个本身也是需要业务语义支持的。单纯的将网关发布为MCP无法提供这部分场景语义。
如何将业务系统变为接入大模型CLI的能力?
最后,又回到了我们要探讨的关键问题,就是如何将业务系统变为接入大模型CLI的能力?
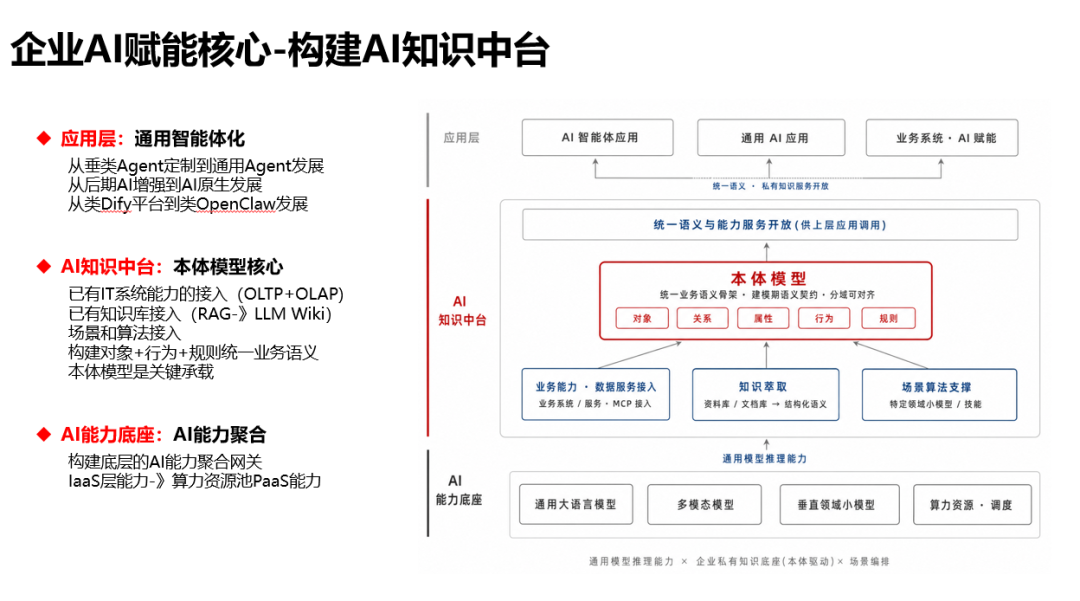
第一个大家容易想到的就是参考我前面的本体建模的思路,来构建一个AI知识中台。这个不仅仅可以逆向业务系统的能力,还可以逆向和萃取企业已有的知识库的能力。在抽象后构建一个完整的覆盖完整业务语义的本体模型,然后将这个本体模型作为AI理解我业务系统的核心上下文。
但是我最近在思考的时候提到了另外一个关键点。
我们去逆向本体模型的目的不是要基于这套本体模型去从0到1全新开发一个一模一样的新系统。我们逆向的核心目的还是将核心业务系统的所有能力暴露出来,而且让大模型能够结合业务流程,业务场景等文档说明精确的理解我的业务能力,方便后续调用。
基于这个思路,实际我们的逆向建模需要分层。这个分层体现在两个方面,一个是只需要逆向到粗粒度的API接口,这个接口偏领域服务能力API接口,而不是底层数据对象的CRUD接口;第二点是这个逆向是面向API接口的,我们不需要下探到具体的数据库和数据对象,而通过横向分层,直接对接业务系统的API接口层即可,以进一步确保数据安全性隔离。
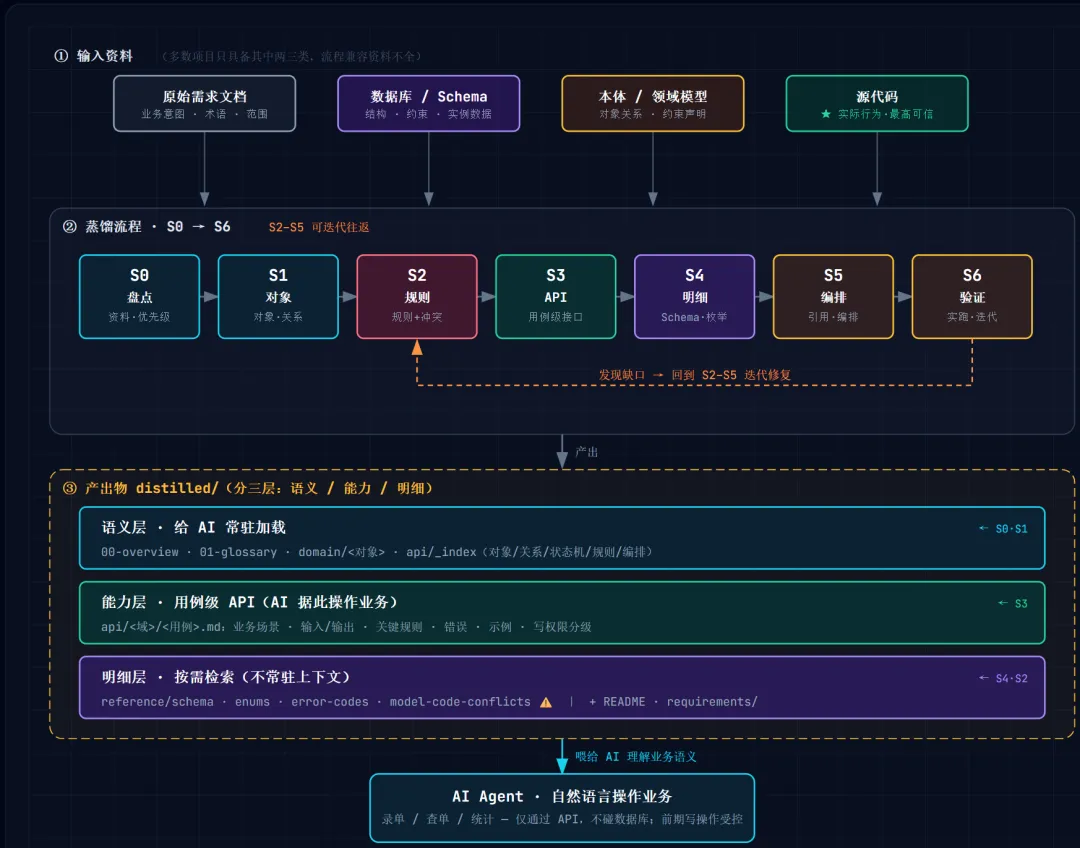
图片
每个阶段有明确产出与检查点。建议顺序执行,但 S3–S5 可迭代往返。
基于这个思路,我在前面文章分享了完整的业务系统逆向方法和步骤。其中覆盖了对象,行为,关系,规则的逆向。但是整个逆向完全是围绕API接口展开的,也就是说业务系统最终接入大模型的仍然是这套API能力调用接口,其它都是辅助说明API接口应该怎么用的场景流程问题,数据对象说明文档,规则文档等。但是API接口内部的实现逻辑实际仍然该高度内聚,不需要对外暴露。
基于这个思路实际我们最终应该形成两个关键逆向文档,即API接口能力清单,这个清单包括了所有的API接口,具体地址,接口的输入输出等。另外一个就是API接口使用清单,这个清单核心就是要基于场景流程来说明不同场景下如何应用这个API接口。这两份文档实际就成为了我们将IT系统变成底层的一个SKills技能包,或者底层的一个能力接入CLI工具的关键点。
当所有的业务系统都CLI化,都能够将能力接入到CLI后,大家想下一个关键的转变出现了。你上次的AI智能体更加变成了一个通用的智能体平台,这个不仅仅具备通用大模型知识库能力,更加重要的是接入了企业的IT系统,资料文档私有知识能力,你原来需要在原来业务系统上做的新增需求或变更需求,你会发现全部都可以通过CLI对话来完成了,这个才是业务系统CLI化的最大价值。
正如我们原来在推SOA架构方法论的时候经常谈,企业核心的共享服务都识别和注册到了总线,那么后期所有的新流程,流程变更都应该可以通过BPEL对API接口的动态编排来灵活实现,而不是去改造系统。这个东西在SOA时代实际没有很好的应用和实践,那么到了AI时代通用的思路,借助AI大模型能力,将业务系统CLI化是否能够真正实践成功?我们拭目以待。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号