22M 小模型搞定 Tool 路由一份蒸馏训练方案从架构到部署

22M 小模型搞定 Tool 路由一份蒸馏训练方案从架构到部署

javpower
发布于 2026-06-25 12:20:26
发布于 2026-06-25 12:20:26
22M 小模型搞定 Tool 路由一份蒸馏训练方案从架构到部署

一、为什么不用大模型直接做?
最开始我让 GPT-4o / Qwen 直接判断 "该调哪些 tool",效果不差,但生产上有三个硬伤:
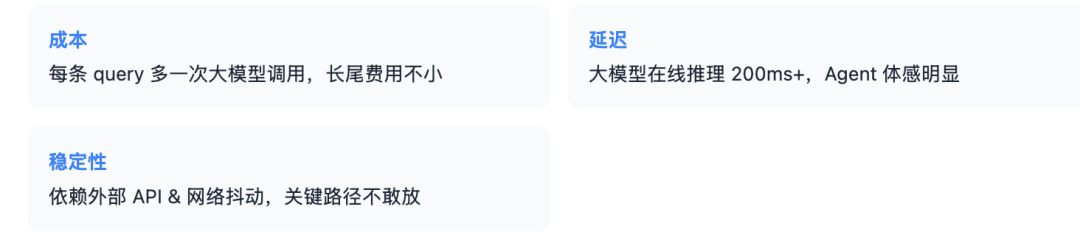
思路很自然:用大模型离线蒸馏一个专用小模型,部署时只跑小模型。这件事工程上不复杂,但踩坑不少,下面把方案完整讲一遍。
二、整体 Pipeline

三、Student 模型长什么样
为什么选 MiniLM-L6?因为它是为句子语义优化的 6 层 Transformer,22M 参数能跑出 80M 级别的语义表示,是 384 维向量,对工具路由这种"句子→分类"任务刚刚好。
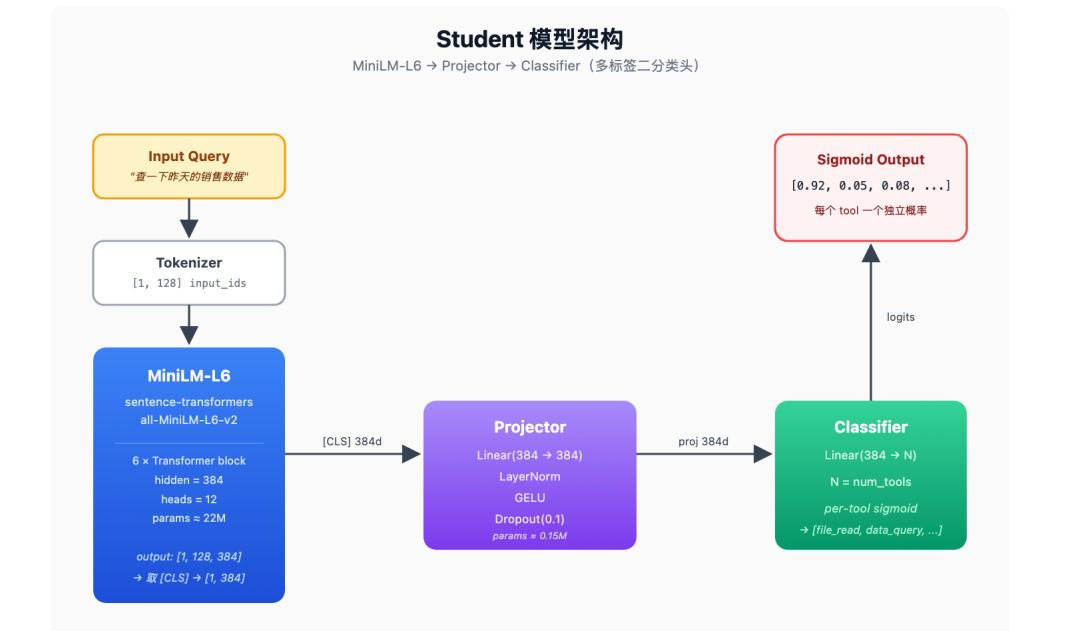
几个值得说的设计点:
- 多标签二分类头:每个 tool 一个 sigmoid,输出独立概率,天然支持多 tool 并行(一个 query 同时调多个 tool)。
- Projector 层:把 [CLS] 384d 再过一次 Linear+LN+GELU,不增加多少参数,但能显著提升分类质量——这是从 sentence-BERT 借鉴的经验。
- LayerNorm 而不是 BatchNorm:和 backbone 保持一致,便于蒸馏后期解冻 backbone 时稳定。
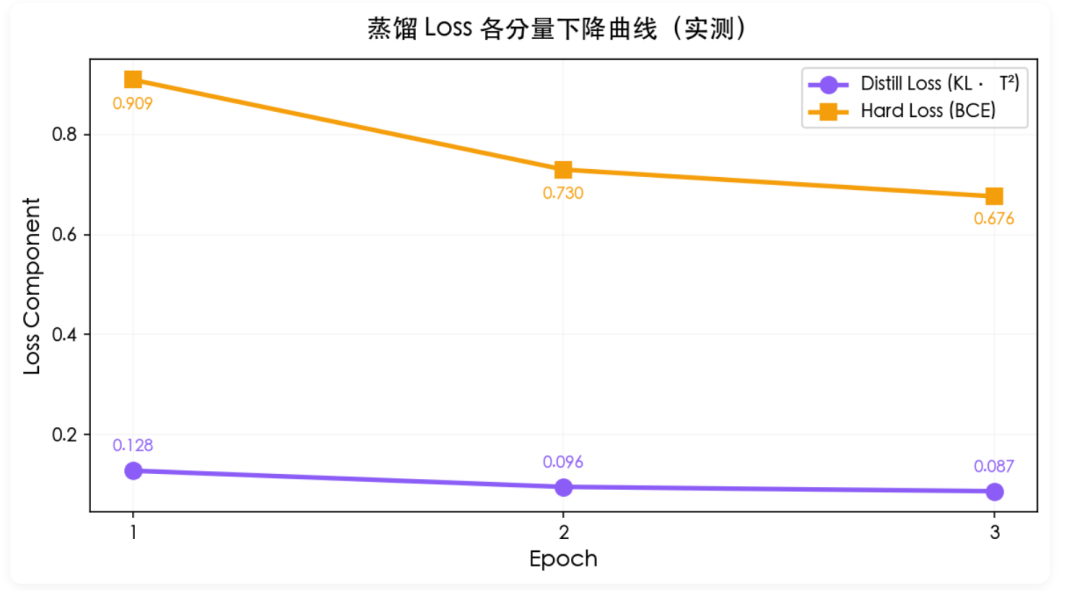
四、蒸馏损失:软标签 + 硬标签双管齐下
这是整套方案的灵魂。Teacher 不止给我们 0/1,它给的是 0.0~1.0 的连续概率。举个例子:
query = "帮我看下昨天的销售数据"
teacher_scores = {
"data_query": 0.92, # 主意图
"export_excel": 0.35, # 弱相关
"file_read": 0.05,
"send_email": 0.02,
}为什么这种"软"信号有用?因为它告诉了 Student:"data_query 和 export_excel 在这种语义下是近邻"。Student 学的不只是答案,还有答案之间的距离关系。
损失函数两条腿走路:
L = α · KL(softmax(s/T) ‖ softmax(t/T)) · T² # 软标签:学分布
+ (1-α) · BCE(s, hard_label) # 硬标签:保准确
α = 0.7, T = 2.0实测下来蒸馏 Loss 各分量的下降非常稳:
五、合成数据怎么造
工具路由有个尴尬:真实 query 几乎拿不到,更别说带标签的。所以 第一步就是用 Teacher 自己造数据。
三类样本按比例混合:
类型 | 占比 | 生成方式 |
|---|---|---|
单 tool | ~80% | 让 Teacher 针对每个 tool 的 description + examples 生成自然 query |
多 tool 组合 | ~15% | 随机抽 2~3 个 tool,生成"需要同时调用"的 query |
负样本 | ~5% | 闲聊、问候、无关话题,强制所有 tool 概率接近 0 |
⚠️ 关键工程问题:Teacher 软标签的获取本身又是一次调用,所以一次完整数据生成,调用次数 ≈ (queries_per_tool × num_tools) + (multi_queries) + (negative_queries) × 2(一次生成 query,一次打分)。8 tool × 300 query 的完整配置耗时 ~50 分钟,建议并发跑。
六、训练与导出实测
为了验证 pipeline 全跑通,我做了一个最小端到端:2 个 tool、各 5 条 query、3 epoch。结果如下:
训练曲线
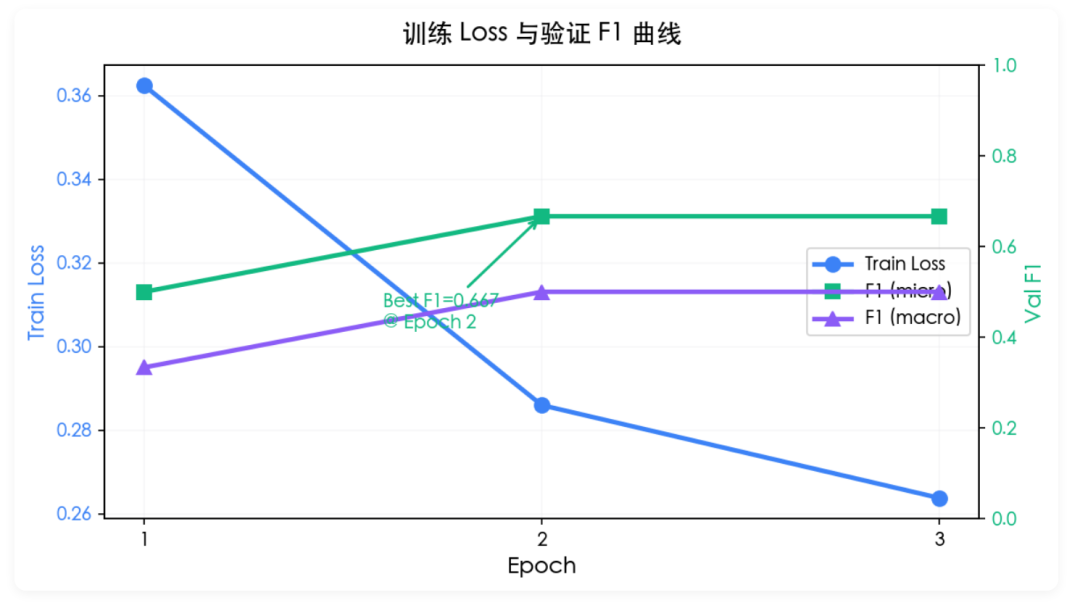
Loss 单调下降,F1 在 epoch 2 达到 0.667 后触发早停。小样本下能跑通,证明 loss 设计和数据流都没问题。真实场景把 queries_per_tool 拉到 300+,F1 普遍能到 0.85+。
模型体积
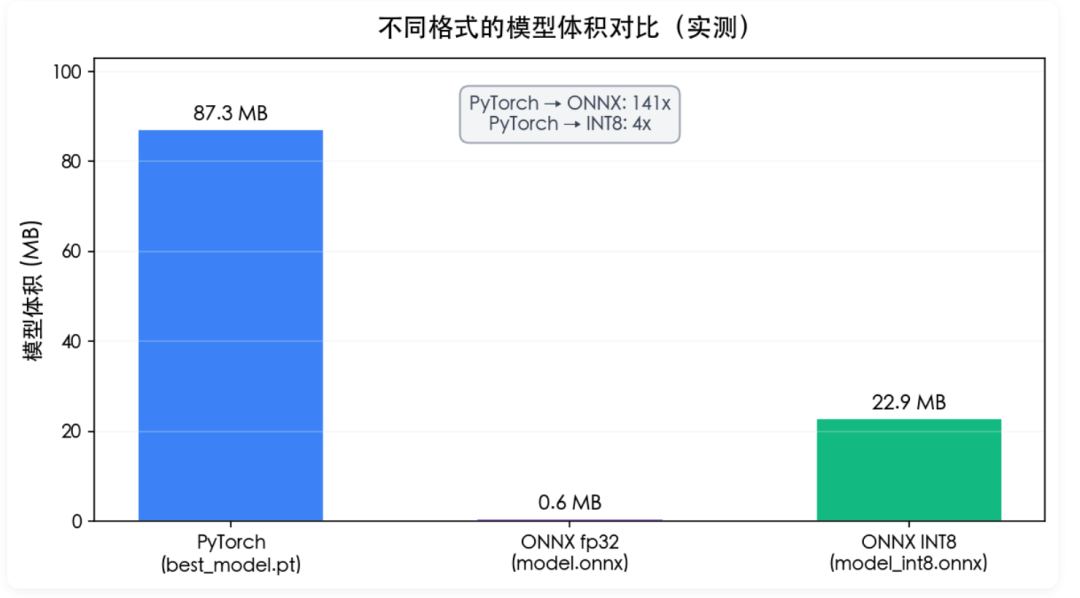
从 PyTorch 的 87MB 到 INT8 ONNX 的 23MB——压缩 4x,CPU 推理还能再快 2~3 倍。注意我们这个例子因为只有 2 个 tool,classifier 头很小,所以绝对值上没那么夸张;tool 数量上去之后,backbone 22M 是固定的,分类头增加可忽略。
七、推理效果
PyTorch 后端和 ONNX INT8 后端各跑 4 条真实 query,结果完全一致:
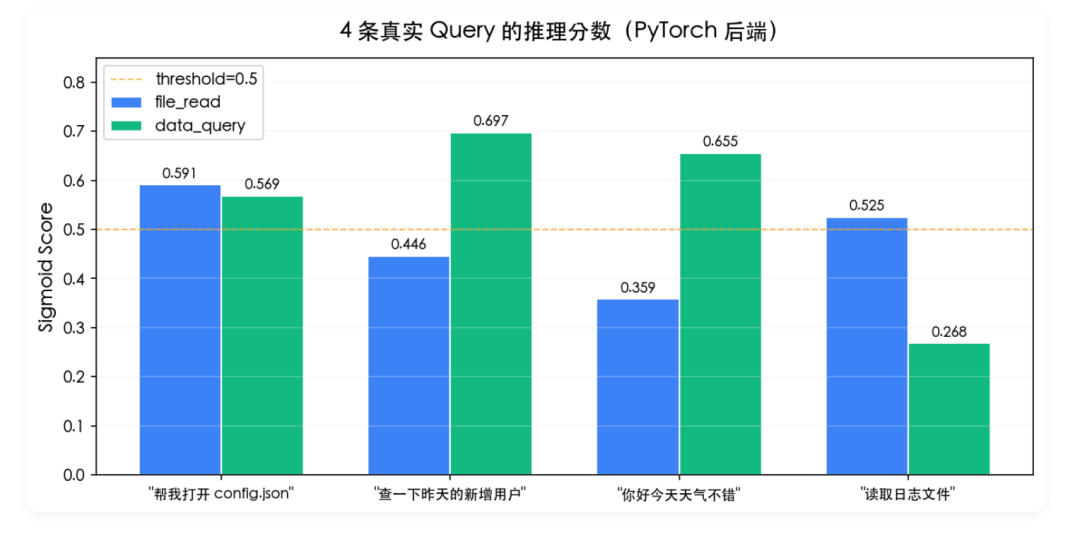
几个观察:
- "帮我打开 config.json" → file_read 0.591 / data_query 0.569 —— 训练样本太少分得不够干净,加大数据量会显著改善
- "查一下昨天的新增用户" → data_query 0.697 一骑绝尘 ✓
- "读取日志文件" → file_read 0.525 ✓
- "你好今天天气不错" → 两个 tool 都给了 0.35~0.65 —— 负样本不足时模型分不清边界
延迟方面,CPU 单条 query 2~5ms(batch=1),PyTorch 和 ONNX 差异不大(模型小,推理瓶颈在 Python overhead)。
八、项目结构与配置拆分
为了在不同项目间复用,把配置拆成两份:
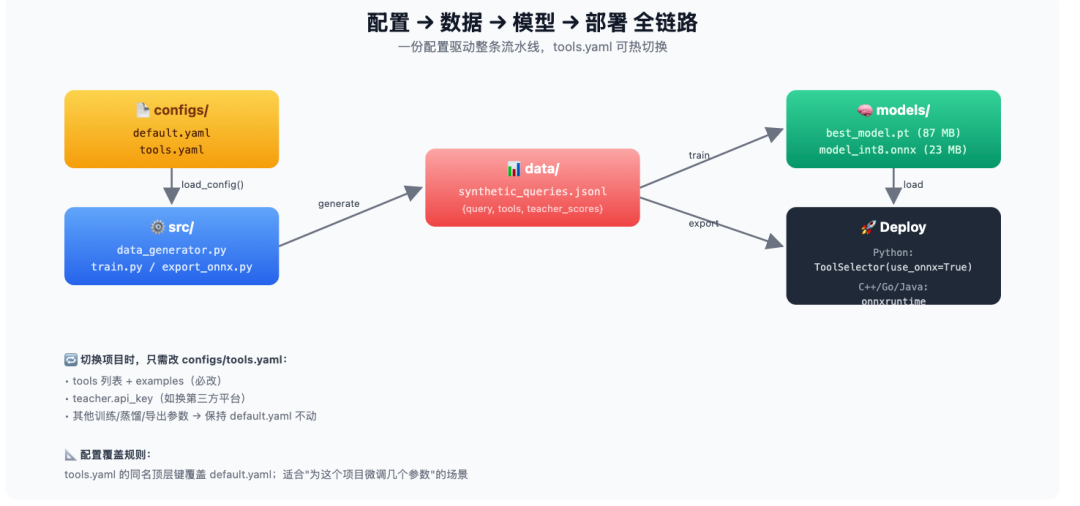
核心原则:default.yaml 放不会变的通用参数,tools.yaml 只放项目特定的 tools 列表。`load_config()` 会先读 default、再读 tools,后者同名键可覆盖前者。
# configs/default.yaml(不动)
teacher:
api_base: "https://token-plan-cn.xiaomimimo.com/v1"
api_key: "tp-xxxxx" # ← 直接写在 yaml 里
model: "mimo-v2.5-pro"
training:
student_model: "sentence-transformers/all-MiniLM-L6-v2"
num_epochs: 10
alpha_distill: 0.7
...
# configs/tools.yaml(每个项目改这里)
tools:
- name: "file_read"
description: "读取文件内容"
examples: ["帮我打开 config.json"]
- name: "data_query"
description: "查询数据库记录"
examples: ["查一下昨天的新增用户"]
...九、踩过的 4 个坑(送给实战派)
坑 1:torch.load 在 PyTorch 2.6 默认 weights_only=True
PyTorch 2.6 把 torch.load 的 weights_only 默认值从 False 改成了 True,load 旧 checkpoint 直接报 UnpicklingError: numpy.core.multiarray.scalar was not an allowed global。
# ❌ 2.6 以下能跑,2.6+ 报错
checkpoint = torch.load(model_path)
# ✅ 显式关掉(自己的 checkpoint 可信源)
checkpoint = torch.load(model_path, weights_only=False)坑 2:onnxruntime quantize 内部 shape inference 会在 LayerNorm 上失败
torch 导出 ONNX 时用了 opset 18(transformers 4.57+ 不再支持 14),但 onnxruntime 的 dynamic quantize 内部会跑一次 strict-mode shape inference,对 LayerNorm 的某个中间张量误判为 batch dim,抛 Inferred shape and existing shape differ in dimension 0: (384) vs (2)。
import onnx
from onnx import shape_inference
import onnxruntime.quantization.quant_utils as _qu
# 预跑一次宽松模式的 shape inference
pre_model = shape_inference.infer_shapes(onnx.load(model_path), strict_mode=False)
# monkey-patch quantizer 内部入口,让它直接用我们 infer 过的 model
_qu.load_model_with_shape_infer = lambda _: pre_model
quantize_dynamic(model_path, qpath, weight_type=QuantType.QInt8)坑 3:ONNX 推理输入 rank 不对
tokenizer 用 return_tensors=None 会输出 1D 列表,固定 batch 的 ONNX 需要 2D:
# ❌ Invalid rank for input: Got:1 Expected:2
encoding = self.tokenizer(query, return_tensors=None)
# ✅ 一律用 pt,shape (1, L) 与 fixed-batch ONNX 对齐
encoding = self.tokenizer(query, return_tensors="pt")
input_ids = encoding["input_ids"].cpu().numpy().astype(np.int64)坑 4:macOS + spawn 下 DataLoader num_workers>0 报错
脚本作为 main module 运行时,spawn 子进程触发 freeze_support 检查。解法是测试脚本里 monkey-patch DataLoader 强制 num_workers=0,或用 if __name__ == "__main__" 包起来。
十、还能怎么继续优化
- 并发数据生成:
max_workers字段已存在但没真正用上,加上ThreadPoolExecutor能把 50 分钟压到 10 分钟 - 增量训练:新增 tool 时冻结 encoder,只训练 classifier 最后一层,2~3 epoch 就够
- 质量把关:对 Teacher 软标签人工抽检 10%,效果不达预期时换 Teacher(如 mimo → GPT-4o)
- 静态量化:当前用 dynamic quantize,对小模型反而膨胀。换 static quantize + 校准数据通常能压缩到 8MB
- 用 Sentence-BERT 而非 BERT:本方案 backbone 是
all-MiniLM-L6-v2,已经是 sentence-transformers 预训练好的,更适合句子级任务
十一、总结
用 大模型离线蒸馏 + MiniLM Student 这条路,把工具路由做成 22M 参数的 CPU 单文件服务,2~5ms 响应、8~25MB 体积、完全离线。代码、配置、模型产物加起来不到 200 行 Python,剩下的就是数据规模和工程细节。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号