斯坦福大学STORM方法,教会普通人怎么用 AI 做深度研究,顺手做了一个skills

斯坦福大学STORM方法,教会普通人怎么用 AI 做深度研究,顺手做了一个skills

AI 生命克劳德
发布于 2026-06-25 16:19:53
发布于 2026-06-25 16:19:53
很多人用AI做研究,第一步是让它总结主题。这个动作只能得到平均答案。Stanford STORM更值得借鉴的地方,在于它把研究拆成一套流程:多视角提问、矛盾映射、综合简报、可信度评审。真正重要的能力,体现在人如何保留视角设计、证据取舍和最终判断权。
普通人应该怎么用 AI 做深度研究

alt text
alt text
很多人用 AI 做研究,第一句话就是:
"帮我总结一下这个主题。"
这句话当然能用。问题是,它通常只能换来一个平均答案。
平均答案看起来完整,却很少告诉你:谁会反对这个判断,哪些证据最硬,哪些结论只是漂亮话,哪个问题还没人真正回答。
这也是很多 AI 内容越写越像资料拼盘的原因——有摘要、有清单、有结论,但没有判断过程。
Stanford OVAL Lab 在 2024 年发表的 STORM 方法,给这件事提供了一个被验证过的思路。
STORM(直译:通过检索和多视角提问合成主题大纲),收录于 NAACL 2024。它不是让模型直接写文章,而是先做多视角提问、检索、对话、整理大纲,再进入生成。
论文里有两组数据值得记住:STORM 生成的文章在事实覆盖度上显著优于直接生成和标准 RAG 基线;在人类评估中,STORM 版本也被认为更全面、更结构化。起作用的关键机制,正是多视角提问——不同视角提出的问题,覆盖面更广、更不容易遗漏。
这套系统本身有工程实现、有检索、有引用、有多轮问答。普通人未必需要把完整系统跑起来。但我们可以先学它背后的研究协议。
我自己用这套四步流程跑过一次"Loop Engineering 是否真的提效",下面先说案例,再说几个容易踩的坑。
我用自己打磨的storm-research技能生成的分析结果页面
我用自己打磨的storm-research技能生成的分析结果页面
一次完整演练:四步拆"Loop Engineering"
最近很多人问:Loop Engineering 是不是真的能让 AI Agent 自动干活、持续提效?
直接问 AI,得到的是标准平衡回答:能自动执行、能减少人工盯盘、能提升自动化效率;同时也会带来成本、失控、幻觉和验证负担。
正确的废话。
我换成四步流程。
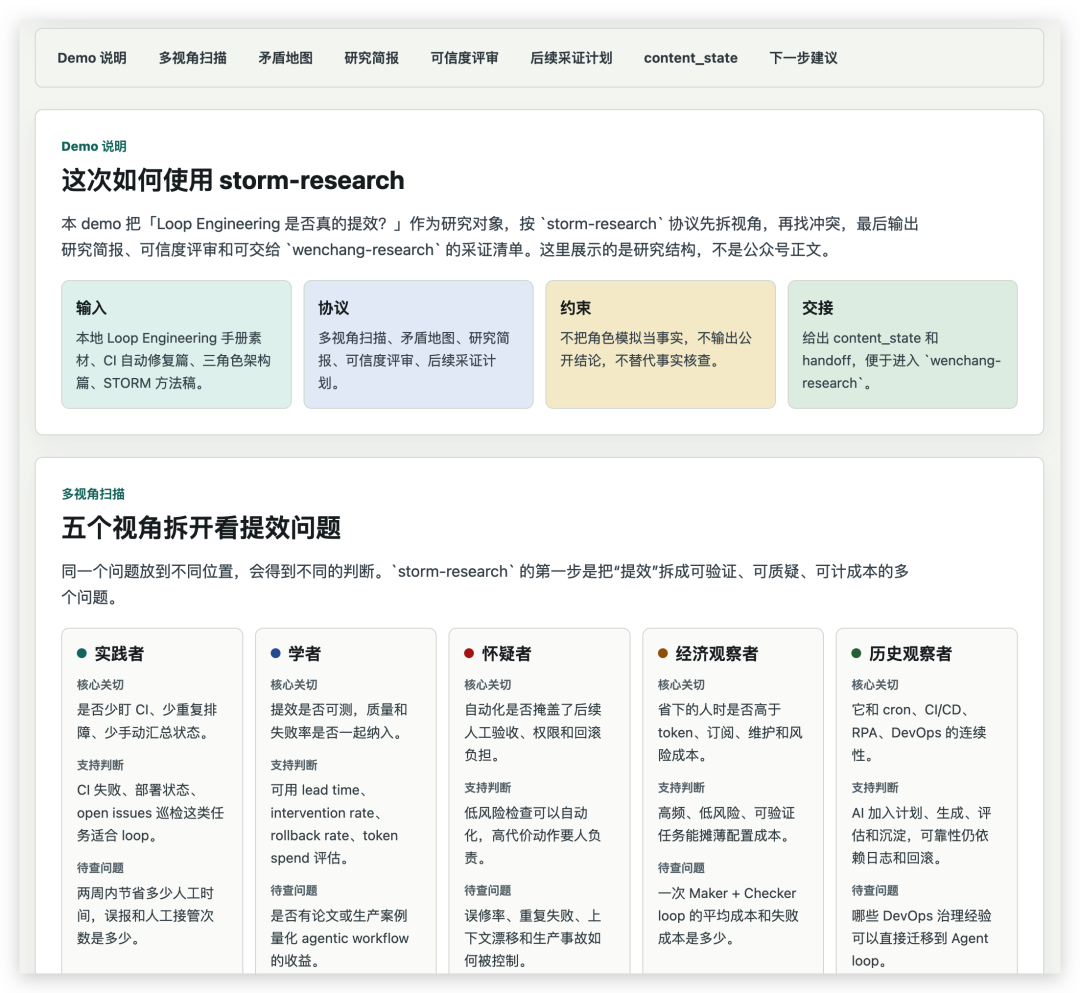
第一步,五视角扫描。
我用的工具是 Claude,但同一套协议Codex 也都能跑。下面让 AI 分别从五个位置看这个问题:
- 实践者:每天在用 Codex、Claude Code、CI、脚本和自动化工具,看见的是工作流变化
- 学者:关心提效有没有可验证指标,任务复杂度、错误率和返工成本是否被一起计算
- 怀疑者:盯着被夸大的部分,看哪些"自动运行"只是把人工检查藏到后面
- 经济学家:看 token、工具订阅、云资源、排障时间和人力节省之间的账是否算得过来
- 历史观察者:把 Loop Engineering 放回自动化、DevOps、RPA 和 CI/CD 的长期演进里看
同一个问题被拆开之后,"提效"这个词的含义就变了:对实践者是工作流解放,对学者是可验证指标,对怀疑者是隐藏成本,对经济学家是成本结构,对历史观察者是自动化浪潮的又一次回响。
第二步,矛盾地图。
我让 AI 专门找冲突:
- 实践者说:"我用 Loop Engineering 让 Agent 每隔一段时间检查 CI、修复失败、更新结果,少了很多手动盯盘。"
- 怀疑者说:"它确实减少了手动调度,但失败排查、权限控制、回滚和结果验收仍然要人负责。"
- 经济学家补一句:"如果 token、云资源、排障时间和误修成本没有算进去,提效可能只是被转移到了另一张账单上。"
如果只停在第一步,我会以为"Loop Engineering 提效"是一个共识。走完第二步,我才发现:执行层的提效和总账上的提效,可能是两件不同的事。
第三步,研究简报,按证据等级排序。
- 强证据:手动调度和盯盘时间减少(实践者一致反馈)
- 中证据:整体提效存在,但依赖任务类型、目标设计和评估器质量
- 弱证据:长期 ROI(缺少标准化的成本核算口径)
这里最关键的是"按证据等级排序"。AI 很擅长把话说完整,但不会天然知道哪句话更值得相信。如果不要求它标出依据来源,实践者感受、厂商宣传、理论推演、个案经验就会出现在同一个语气里,直接污染判断。
第四步,可信度评审。
我让 AI 自查:
- 最不稳的结论:长期 ROI
- 被放大的视角:实践者的个体体验
- 缺失的视角:失败案例、团队整体成本、权限和安全风险
- 必须人工核验:具体提效比例,因为不同任务、不同工具、不同组织的差异极大
走完这四步,我拿到的不再是一个"是或否"的答案,而是一张问题地图。
这套流程,最容易踩的四个坑
跑完这个案例,有几处容易踩的坑值得记下来。
坑 1:视角选得太泛,5 个视角互相重叠。
"实践者""使用者""一线员工"经常是同一个人。选视角时要刻意拉开距离:谁受益、谁付费、谁反对、谁被遗漏。如果 5 个视角给出的答案差不多,说明视角没选对。
坑 2:把"视角不同"当成"观点冲突"。
两个视角给出不同描述,不等于它们打架。真正的冲突是两个视角对同一个判断给出相反结论。只有这种冲突才值得继续深挖。
坑 3:简报按精彩程度排序,而不是按可靠性排序。
AI 给的简报看起来很完整,但里面可能把论文结论、媒体表达、个人猜测放在同一个语气里。必须按证据来源分级,否则会被"说得顺"的那句带走。
坑 4:自查只做样子,最后还是信了最顺的那个结论。
自查不是走流程。如果 AI 自查后说"最不稳的结论是 X",但你还是忍不住把 X 当成文章主线,那自查就白做了。自查的结论必须真的影响你的取舍。
用十次,它就变成你的系统
alt text
alt text
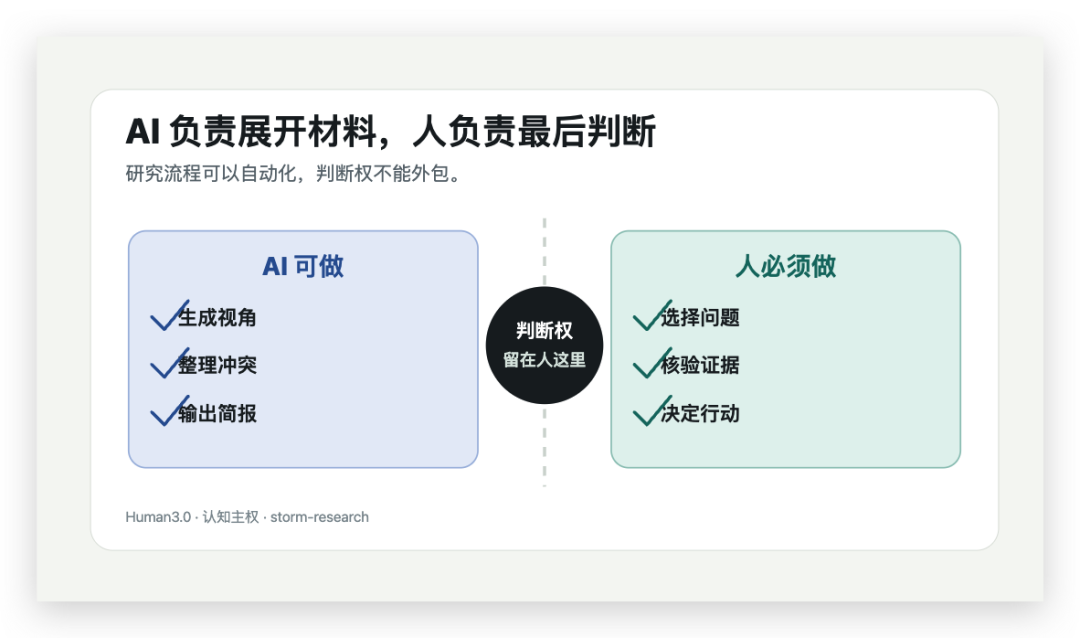
真正值得沉淀的,是你自己的研究协议。
常用的五视角扫描 Prompt、矛盾地图 Prompt、研究简报模板、可信度评审清单、证据日志表、选题复盘记录——这些东西用一次,只是技巧。用十次,就会变成你的个人研究系统。每次写文章、做产品判断、学习新领域之前,都先跑同一套流程,你会慢慢积累出自己的问题库、证据库、反方清单和判断标准。
这也是 Human3.0 一直在说的那件事:在 AI 时代,人真正的杠杆不是会用工具,而是能把自己的判断流程沉淀成可复用的数字生产资料。
这套协议不绑定任何工具。我用 Claude,也见过有人用 Codex 跑同一套流程,效果主要取决于协议设计,而不是模型。模型可以换,协议留在你手里。我把这套流程封装成了一个本地 skill,叫 storm-research,不绑定任何模型,接收主题或选题,按四步输出问题地图、冲突点、可信度风险和下一步采证清单。
一次提示词只能解决一次问题,一个 skill 可以反复接入工作流。
下次研究前,先跑这四步

alt text
alt text
五个视角,一张矛盾地图,一份带证据等级的简报,一次可信度评审。
下次动手前,先跑这四步。AI 给的是材料,你留下的是判断。
斯坦福 Co-STORM
下文会介绍斯坦福又做了 Co-STORM,可以理解为 协作版 STORM。 STORM 偏自动生成报告;Co-STORM 则加入了人类用户参与,让人可以在知识探索过程中插话、引导方向、观察多个 AI 专家讨论。GitHub 里提到,Co-STORM 包含 LLM experts、Moderator 和 Human user;同时维护一个动态 mind map,把收集到的信息组织成层级概念结构。说人话就是
STORM 是 AI 帮你写研究报告。 Co-STORM 是你和一组 AI 专家开圆桌会,边讨论边沉淀知识地图。
彩蛋
我把这套方法整理成了两样东西:
- 《AI 研究四步提示词模板》:五视角扫描、矛盾地图、研究简报、可信度评审四份 Prompt(带变量占位符,可直接复制),附证据日志空表。
storm-researchskill:把四步流程封装成本地 skill,接收主题或选题,按协议输出问题地图、冲突点、可信度风险和下一步采证清单。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号