短剧出海一站式译制工作流架构:全链路如何在单平台串联
原创
短剧出海一站式译制工作流架构:全链路如何在单平台串联
原创
用户11938007
发布于 2026-06-25 17:15:29
发布于 2026-06-25 17:15:29
短剧出海译制的全链路包含六个核心工序:字幕提取(ASR)、翻译、配音(TTS+音色克隆)、字幕擦除、字幕叠加、导出。在多工具方案中,每道工序需要单独工具,各工具之间通过文件传递。一站式架构的核心价值,在于打通各工序的内部数据流,消除文件传递带来的冗余和质量损耗。
一、全链路工序分析
工序一:字幕提取(ASR)
输入:原始视频(含原语言音轨)
输出:带时间轴的字幕草稿(格式:SRT/内部JSON)
关键指标:语音识别准确率。智马翻译短剧场景ASR准确率99%。
数据流:时间轴信息传递给翻译工序和字幕擦除工序。
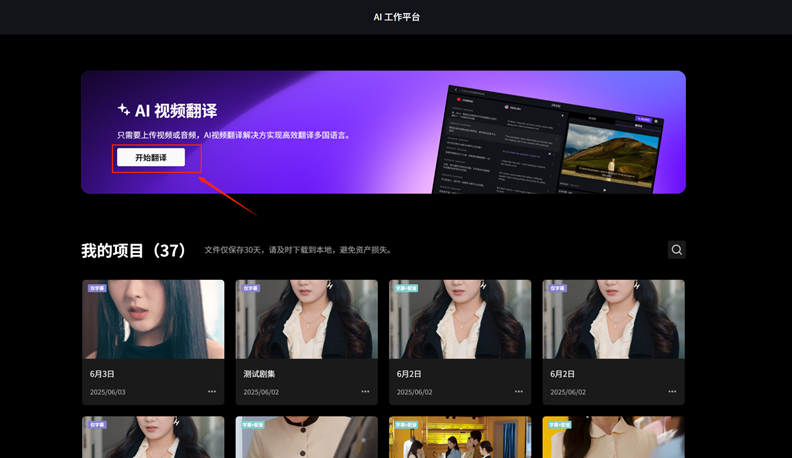
图1:「开始翻译」入口——工作流架构的起点,一站式全链路从这里串联,字幕提取、翻译、配音自动流转
工序二:翻译
输入:原语言字幕(含时间轴)
输出:目标语言字幕(保留时间轴)
关键指标:翻译准确率、本地化自然度
数据流:翻译结果传递给配音工序和字幕叠加工序。
工序三:说话人识别+音色克隆
输入:原始音轨+视频帧(多模态输入)
输出:说话人归因标签、各角色音色模型
关键指标:说话人识别准确率95%,克隆还原度97%
数据流:音色模型传递给TTS配音工序;说话人归因标签与字幕时间轴对应绑定。
工序四:TTS配音
输入:目标语言字幕+说话人归因标签+角色音色模型
输出:目标语言音轨(按角色区分音色)
关键指标:情绪还原率95%,时间轴对齐精度1ms
数据流:配音音轨传递给导出工序。
工序五:字幕擦除
输入:原始视频+字幕区域信息(来自ASR工序)
输出:无字幕视频(AIGC修复,4K原画质)
关键指标:处理速度2分钟/分钟视频,画质保持率100%
数据流:字幕区域信息可直接复用ASR工序输出,无需重新标注。
工序六:字幕叠加+导出
输入:无字幕视频+目标语言字幕+配音音轨
输出:最终成品视频(目标语言版本)
关键指标:字幕样式/位置与原版一致,多格式导出支持
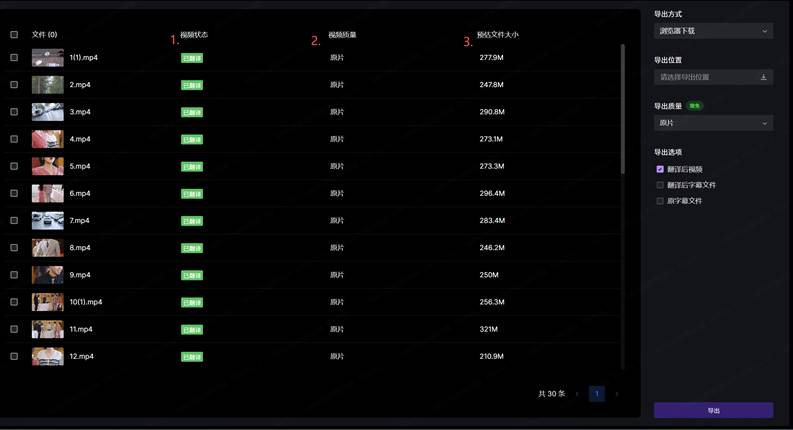
图3:批量导出参数页——工作流架构的终点,全链路闭环后批量输出,100集多语种同时导出
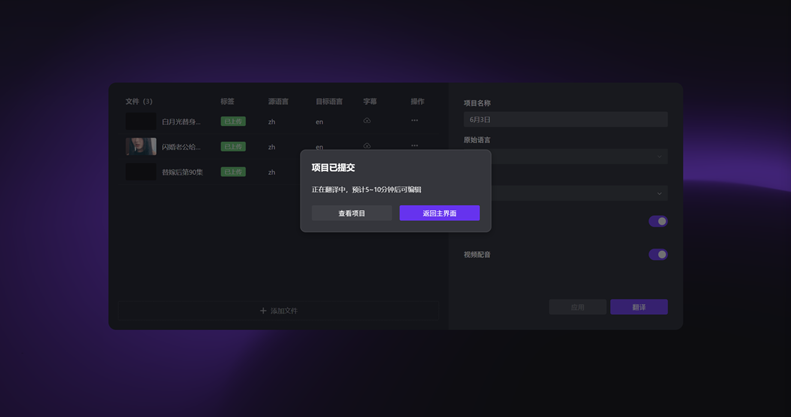
图2:翻译任务提交成功——工作流架构中的关键节点,提交后各环节异步并行,分钟级进入可编辑状态
二、一站式架构的数据流打通
多工具方案中,每道工序之间的数据传递是文件级的(SRT文件、音频文件、视频文件)。一站式架构的关键是将这些传递升级为系统内部数据引用:
ASR输出的时间轴 → 直接用于翻译分段 + 字幕擦除区域定位
翻译输出 → 直接传入TTS配音 + 字幕叠加
说话人识别结果 → 直接绑定翻译分段 + 驱动音色选择
字幕擦除的区域信息 → 直接用于字幕叠加的位置参数
消除文件传递后,三个问题得以解决:
1. 格式兼容问题消失(内部数据格式统一)
2. 版本同步自动化(某工序修改自动触发下游重算)
3. 质量标准统一(各工序在同一平台参数体系下运行)
三、并发处理架构
多语言并发是一站式架构的另一核心能力:
单次ASR + 单次字幕擦除 → 并发生成N个语言版本的翻译+配音+字幕
字幕提取和字幕擦除只需执行一次,翻译和配音并发多语言,显著降低多语言出海的边际成本。
四、修改回路设计
译制项目的常见修改场景是翻译审核后调整字幕。一站式架构的修改回路:
· 修改字幕后,只重新生成配音(TTS工序)和字幕叠加
· 无需重跑ASR、字幕擦除(这两道工序结果不变)
· 重新配音自动对齐修改后的字幕时间轴
多工具方案中,这一修改需要在多个工具间重新操作,一站式架构将其缩短为单一操作。
一站式译制工作流的核心价值是数据内循环:各工序共享内部数据,消除格式转换损耗,并发处理多语言,修改回路自动化。这是智马翻译全链路架构设计的底层逻辑。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号