免费视频翻译工具技术边界拆解:为什么短剧出海需要专业方案
原创
免费视频翻译工具技术边界拆解:为什么短剧出海需要专业方案
原创
用户11938007
发布于 2026-06-25 17:20:44
发布于 2026-06-25 17:20:44
免费视频翻译工具在技术层面有明确的能力边界。这些边界不是"产品策略限制",而是技术架构决定的——要做到专业级效果,底层技术就需要更高的投入,免费工具无法承载。
本文从技术角度拆解每个核心模块在免费工具和专业方案之间的差距。
一、ASR语音识别:准确率差距
免费工具层级:通用ASR模型(如Whisper开源版本或其变体),针对清晰播客/会议场景优化。
短剧场景的特殊挑战:
· 背景音乐干扰:短剧配乐密集,信噪比低
· 方言/口音:国内短剧含大量口音台词
· 多人交叉说话:快节奏对话,音频重叠
通用ASR在短剧场景下的识别准确率通常在85-90%,意味着每100个字有10-15个错误,字幕需要人工大量校对。
专业方案层级:针对短剧音频特征专门调优的ASR模型,准确率可达99%。智马翻译实测短剧场景ASR准确率99%。
差距:每分钟视频约100-150字,99% vs 85%的准确率差距意味着每分钟多出15-20个错误字需要人工校对。
二、TTS配音:情绪还原是技术核心差距
免费工具层级:基础TTS(Text-to-Speech),将文本转换为语音,通常使用开源或低成本TTS引擎。
这类TTS的技术特征是:固定语调范式(每种语言有几套固定语调模板),情绪控制粗粒度(最多支持"开心/悲伤/愤怒"等粗粒度切换)。
短剧场景的特殊挑战:短剧的情绪密度极高,每隔几分钟一个情绪高潮,需要精细的情绪区分(委屈 vs 隐忍 vs 爆发,三种状态完全不同)。
专业方案层级:多模态情绪建模(视频帧表情分析+音频频谱情绪信号+字幕语义)驱动大模型TTS,输出细粒度情绪化语音。智马翻译情绪还原率实测95%以上。
差距:这不是调整参数可以弥补的差距,而是底层技术架构不同。免费TTS没有情绪建模能力,专业TTS有。
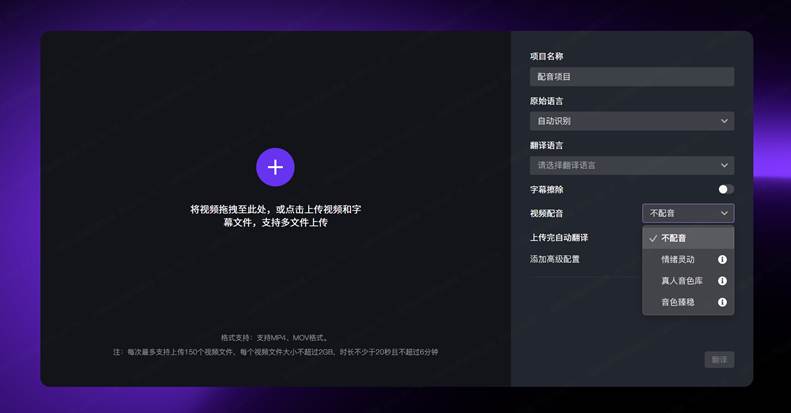
图1:配音模式四选一——不配音/情绪灵动/真人音色库/音色臻稳,免费工具的技术边界通常在"不配音"档就到头了
三、音色克隆:还原度取决于模型容量
免费工具层级:基础音色克隆需要较长参考音频,还原度有限,通常只能还原声线大致特征,细节(气口、呼吸声、音色纹理)丢失。
专业方案层级:少样本音色克隆技术(基于几秒参考音频就能克隆),深度还原音色特征,克隆还原度97%以上(智马翻译实测)。
四、字幕擦除:AIGC修复 vs 区域填充
这是技术差距最直观的模块。
免费工具层级:区域像素填充(均值/插值),本质是打补丁。静态背景勉强可用,动态背景必留痕迹,4K下痕迹放大显现。
专业方案层级:AIGC视频修复(时序一致性生成),参考相邻帧时序信息重建字幕区域背景,4K原画质100%保持率。
这两种方案的技术路径根本不同,不是参数优化可以弥补的差距。

图2:计费项明细——付费专业方案的能力边界与收费项,拆解免费工具能做到什么、在哪里技术触底的对照参考
五、批量处理:系统架构差距
免费工具层级:受限于计算资源分配,免费用户通常在共享资源池的低优先级队列,批量任务排队时间长,月处理量有严格上限。
专业方案层级:弹性计算资源,批量任务并行处理,无月处理量限制,100集剧的全流程处理时间可预估和规划。
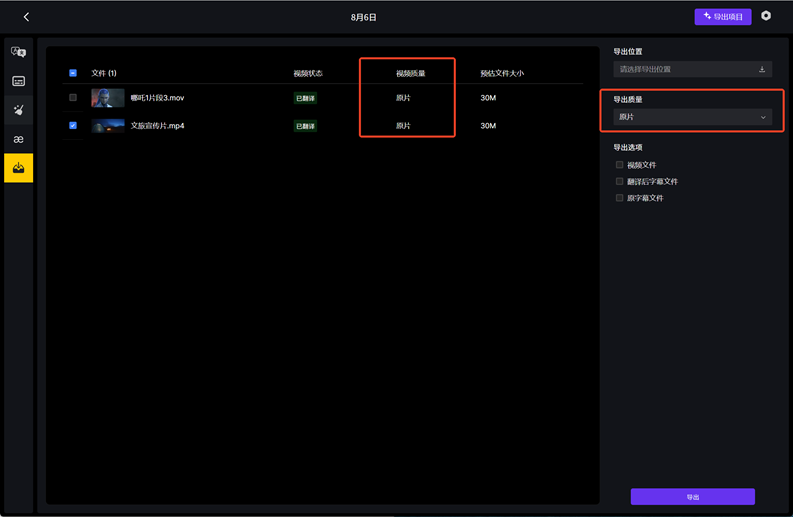
图3:导出质量三档——原片/中度/极致压缩,专业方案提供的导出灵活性,免费工具通常无法提供的精细控制能力
短剧出海需要专业方案,不是因为免费工具"功能少",而是因为在ASR准确率、情绪TTS、音色克隆还原度、4K字幕擦除这四个核心技术维度,专业方案的底层技术架构就是不同的——这些差距无法通过产品功能调整弥补。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号