多线程饥饿死锁 - Claude Code 和 DeepSeek集体幻觉

多线程饥饿死锁 - Claude Code 和 DeepSeek集体幻觉

码农戏码
发布于 2026-06-25 20:00:28
发布于 2026-06-25 20:00:28
线上碰到一个问题,当用户提交一个流程时,经常出现流程中途节点出现超长等待才会出现结果,甚至有时感觉系统hang了
这种现象在数据大时,出现的概率极高。
第一步,查找日志异常信息
对业务流程不是很了解,先看看日志,是否有什么异常信息,方便定位
发现的一个异常是InterruptedException,通过异常信息,定位到了代码位置,大该的代码
@Override
public String call() throws Exception {
System.out.println("[DataCorrectionTask-" + taskId + "] 开始执行,等待 ModelingTask-" + dependsOnModelingTaskId);
Boolean modelingReady = modelingResultMap.get(dependsOnModelingTaskId);
int waitTime = 0;
while (modelingReady == null) {
Thread.sleep(100); // 占用线程等待!
waitTime += 100;
modelingReady = modelingResultMap.get(dependsOnModelingTaskId);
if (waitTime > 5000) { // 5秒超时(模拟)
System.out.println("[DataCorrectionTask-" + taskId + "] ❌ 超时!");
throw new TimeoutException("等待 ModelingTask 结果超时");
}
}
System.out.println("[DataCorrectionTask-" + taskId + "] 获得结果,继续执行");
Thread.sleep(500); // 模拟后续处理
return "DataCorrectionResult-" + taskId;
}这是一个多线程的任务类,在Thread.sleep(100);时被中断了。但这个异常并没有任务处理。对这儿引起了一丝丝警觉。如果没有处理这个异常,会不会造成整个线程池的假死?
InterruptedException
处理InterruptedException异常时要小心,如果在调用执行线程的interrupt()方法中断执行线程时,抛出了InterruptedException异常,
则在触发InterruptedException异常的同时,JVM会同时把执行线程的中断标志位清除,此时调用执行线程的isInterrupted()方法时,会返回false。
此时,正确的处理方式是在执行线程的run()方法中捕获到InterruptedException异常,
并重新设置中断标志位(也就是在捕获InterruptedException异常的catch代码块中,重新调用当前线程的interrupt()方法)
// 设计良好的库方法通常会检查中断状态
public void libraryMethod() {
// 标准做法:定期检查中断状态
for (int i = 0; i < 100; i++) {
if (Thread.currentThread().isInterrupted()) {
throw new RuntimeException("任务被中断");
}
doWork();
}
}
// 如果你的线程不恢复中断标志,这些库方法就无法正常工作
Thread thread = new Thread(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// 不恢复中断
// Thread.currentThread().interrupt(); // 缺少这行
}
// 调用库方法
libraryMethod(); // 这个方法检查不到中断,会继续执行!
});JDK内置的并发库,像线程池之类都会使用这样的方式。所以正确的处理范式都得
public void processTask() {
try {
performLongOperation();
} catch (InterruptedException e) {
// 恢复中断,让调用者知道
Thread.currentThread().interrupt();
throw new RuntimeException("任务被中断", e);
}
}deepseek 协助分析
有了上面的怀疑,再进一步分析代码,发现应该不会造成线程池的假死,因为在异常一步步上抛过程中都没有进行异常catch,整个任务也会结束,不至于系统hang 住
把这些信息先让deepseek帮助分析看看,的确提到了线程池的问题
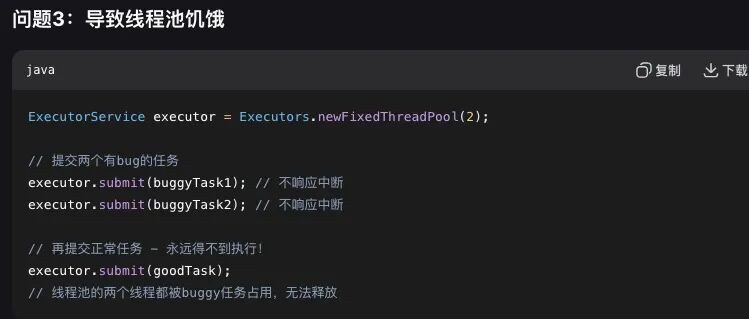
难道真是这个原因?
不至于啊,代码一直是这样,怎么可能最近问题才突显呢
继续往下看,又来了点线索
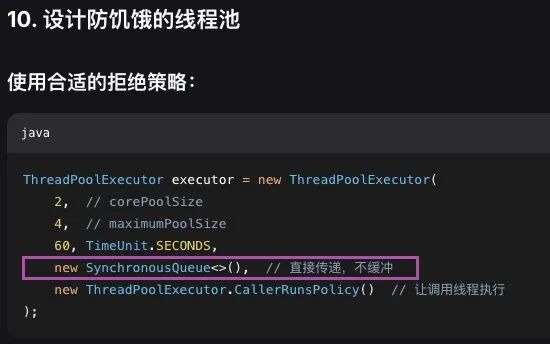
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, // corePoolSize
4, // maximumPoolSize
60, TimeUnit.SECONDS,
new SynchronousQueue<>(), // 直接传递,不缓冲
new ThreadPoolExecutor.CallerRunsPolicy() // 让调用线程执行
);看到了亮点,最近我刚把 SynchronousQueue 改成了ArrayBlockingQueue ,因为之前经常有某一个用户运行超大任务,把资源全部耗尽的情况,需要对资源做一些限制。
分析发现线程池里面使用的是 SynchronousQueue,拒绝策略也正是 CallerRunsPolicy
这样 当任务扩张时,没有被拒绝,也没有被排队,全部使用调用者线程了,而调用者正好又在一个线程池里面。
对线程池完全没有规划,线程池套线程池。
分析到这,基本确定是这儿修改引起的问题,但还是不太理解,为什么造成系统 hang 住呢?
Claude Code 协助
这时需要更多的系统上下文信息给到AI了,拿出Claude Code,切换到最牛逼的Claude Opus 4.5模型,把问题描述一下,让他全局分析一下。
尽然被分析出来了
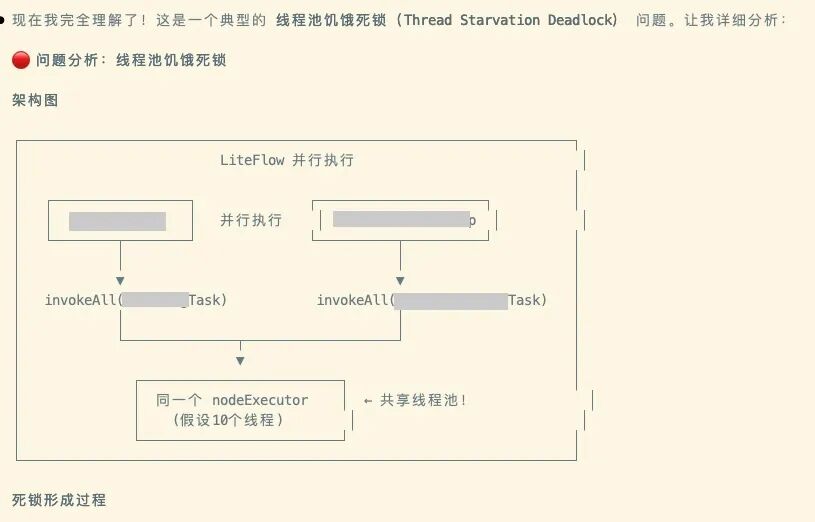
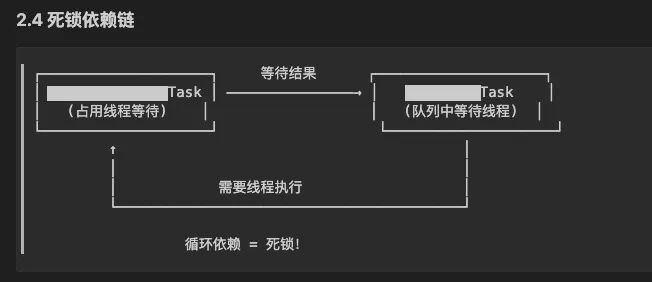
对照代码分析一下,原来在流程里面,节点和节点还有相互并行依赖关系,没想到。
优化时没有考虑到,优化得有问题,现象以及重现步骤都能对得上,AI时代真是个伟大的时代。
AI幻觉
既然已经确定问题,那接下来就是修复问题。
AI比人积极多了,主动提出修复方案,他开始表演了
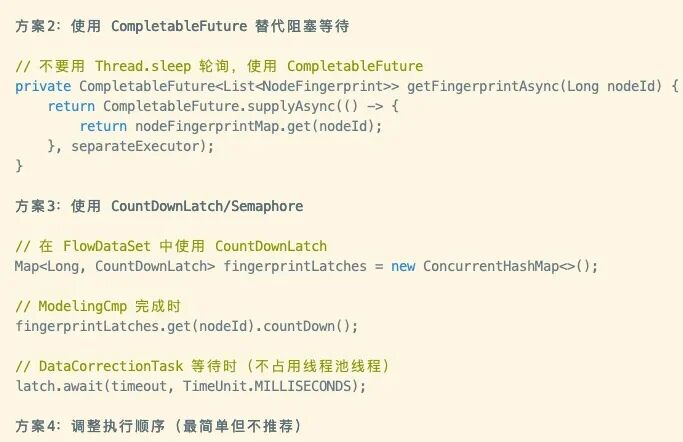
一下子给出了4种方案。太完美了。
让他输出一下文档
现在你有三份文档:
1. THREAD-POOL-STARVATION-DEADLOCK-ANALYSIS.md - 详细分析和错误的方案2
2. THREAD-POOL-DEADLOCK-DEMO.md - 代码示例(演示为什么会死锁)
3. THREAD-POOL-DEADLOCK-REAL-SOLUTION.md - 真正的解决方案(方案A/B/C)
建议采用 方案 B(异步链式调用) 作为长期方案。完美得不要不要的!!
等等~
//等待时(不占用线程池线程)
latch.await(timeout, TimeUnit.MILLISECONDS);这是什么意思? 有点不科学,但也不敢质疑,毕竟人家刚发现了这么牛逼的问题。还是问问deepseek吧,claude code太贵了,公司也不报销。
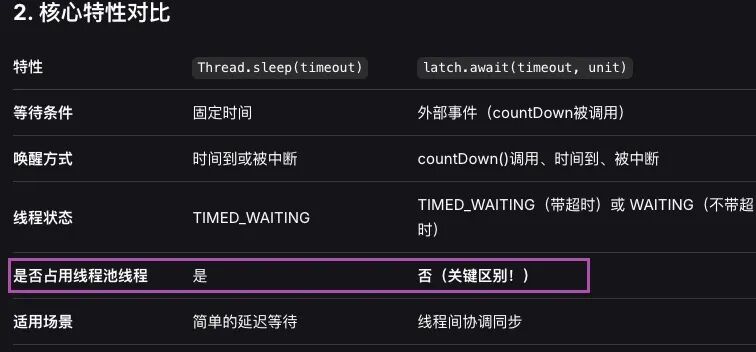
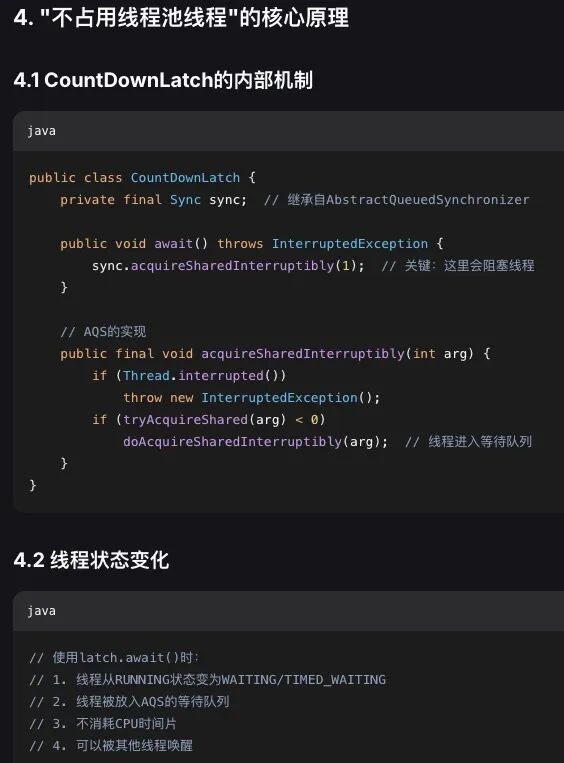

看看这分析,就叫专业。我都不敢说学过线程池了,更不好意思说有十多年的工作经验。

但好像不太对啊。有点超出我的认知,以前白学了,都准备回去从零翻阅源码,好好学习了。
既然都这么说,那先让写个demo吧,我先好好补习一下知识盲区
请出Claude Code,切换成Claude Haiku 4.5


他还是那么牛逼。结果在文档都臆测出来了。
没办法,弱小就要挨打,打开IDE,把这个示例老老实实跑一跑。结果好像不太对啊~~
有了结果佐证,就像拿到bug证据的测试准备怼怼程序员,不过还得保持克制,保持礼貌


现在你有 4 份完整文档:
1. THREAD-POOL-STARVATION-DEADLOCK-ANALYSIS.md - 详细分析
2. THREAD-POOL-DEADLOCK-REAL-SOLUTION.md - 三个真实方案对比
3. ASYNC-CHAIN-SOLUTION-DEMO.md - ✓ 修正后的完整演示代码(可直接运行)
4. ~~THREAD-POOL-DEADLOCK-DEMO.md~~ - 已过期,用新的替代
直接运行演示代码,可以清晰看到异步链式调用如何完全避免线程占用和死锁!去你大爷的,浪费我多少token。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号