深度剖析 Qwen-Image 如何统一视觉理解与生成

深度剖析 Qwen-Image 如何统一视觉理解与生成

唐国梁Tommy
发布于 2026-06-25 20:58:24
发布于 2026-06-25 20:58:24
在人工智能生成内容(AIGC)的浪潮中,文生图模型无疑是最耀眼的明星之一。从 Midjourney 的艺术大片到 DALL-E 的奇思妙想,我们已经习惯了 AI 为我们描绘出各种绚丽的视觉世界。然而,在这些令人惊叹的图像背后,一个看似简单却长期困扰着几乎所有顶尖模型的难题始终存在——在图片里精准地“写字”。
今天,我们要深入探讨的这篇技术报告——《Qwen-Image Technical Report》,正是来自阿里巴巴的团队为攻克这一难题交出的一份亮眼答卷。Qwen-Image不仅是一个强大的通用图像生成与编辑模型,更在“文字渲染”这一核心痛点上取得了突破性进展。

Qwen-Image 带来了什么新东西?
在深入技术细节之前,我们先来提炼一下Qwen-Image最核心的贡献。它主要在以下三个方面实现了显著的进步:

1. 卓越的文本渲染能力:
这是Qwen-Image最引人注目的亮点。它能够高质量地生成包含多行、段落甚至复杂布局的文本,并且同时支持英文和中文等语素文字。在论文的各项测试中,尤其是在中文文本渲染上,它的表现远超现有模型,达到了前所未有的准确性。
2. 高一致性的图像编辑:
除了从零生成,Qwen-Image在图像编辑方面也表现出色。它引入了一种创新的“双重编码”机制,使其在执行编辑指令(如修改物体、变换风格)时,能同时保持高级语义(比如人物身份)和低级视觉特征(比如背景细节)的高度一致性,解决了传统编辑模型“顾此失彼”的问题。
3. 强大的跨基准通用性能:
Qwen-Image并非一个“偏科生”。在专注于文本能力的同时,它在各大通用的图像生成与编辑基准测试(如GenEval、DPG、GEdit等)中也名列前茅。这证明了它是一个能力全面、基础扎实的“基础模型”,而非仅仅是一个功能单一的“专才”。

揭秘Qwen-Image的技术内幕
Qwen-Image的成功并非偶然,其背后是一套系统化的方法论,涵盖了模型架构、数据处理和训练策略。我们可以将其成功的秘诀归结为三大支柱。
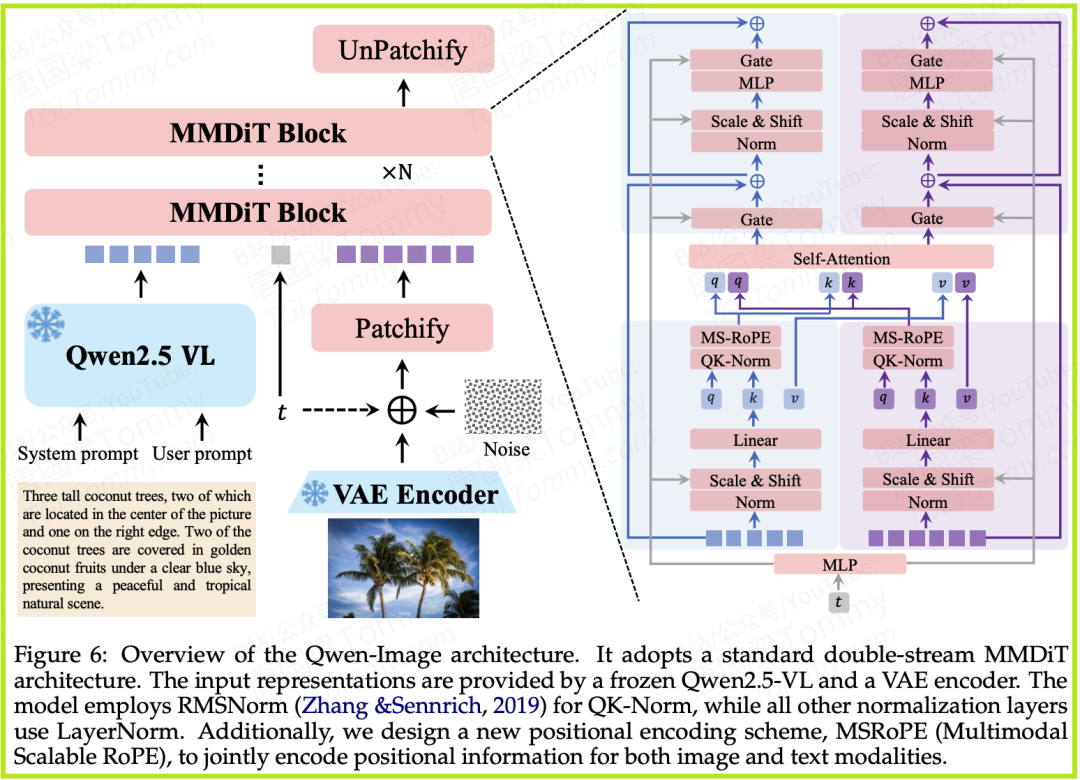
第一支柱:三位一体的先进模型架构
Qwen-Image的架构由三个协同工作的核心组件构成,各司其职,共同完成了从理解用户意图到生成最终图像的复杂过程(见下图)。
1. “大脑”——多模态大语言模型 (MLLM):模型采用了业界领先的Qwen2.5-VL作为其理解用户指令的“大脑”。无论是纯文本提示,还是“图片+文字”的混合指令,Qwen2.5-VL负责将其编码成模型能够理解的深层特征。选择它的最大优势在于,其视觉和语言空间已经经过了充分的对齐训练,天然就具备了强大的多模态理解能力,为后续的生成任务打下了坚实的基础。
2. “画布与画笔”——变分自编码器 (VAE):VAE在模型中扮演着图像“翻译官”的角色。它能将高清图像压缩成一个紧凑的、低维度的“潜在表示”(latent space),就像艺术家将脑海中的灵感浓缩为一幅草图。在生成阶段,它再将模型在潜在空间中创作的内容“解码”回高清图像,如同将草图绘制成一幅精美的油画。值得一提的是,Qwen-Image的团队特别对VAE的解码器进行了微调,使其在重建微小文本和精细细节时保真度更高,这是其文本渲染能力出色的关键之一。
3. “引擎”——多模态扩散变换器 (MMDiT):MMDiT是整个生成过程的核心“引擎”。它基于当前流行的Diffusion Transformer架构,负责在“大脑”(MLLM)的指引下,将一堆随机噪声逐步“去噪”,最终塑造出符合用户要求的图像潜在表示。可以说,从无到有的神奇创造过程,正是在这里发生的。

第二支柱:巧妙的MSROPE位置编码
如果说架构是骨架,那么位置编码就是连接骨架的“关节”。如何让模型精准理解“把‘QWEN’这个词写在图片左上角”这样的指令?这需要一个高效的机制来对齐文本信息和图像空间位置。
传统模型通常将文本指令的特征简单地拼接到图像特征之后,这就像给一张设计图贴上了一张便签,模型很难精确理解便签上的指令具体对应图纸的哪个位置。
为此,Qwen-Image设计了一种新颖的多模态可扩展旋转位置编码 (MSROPE)。
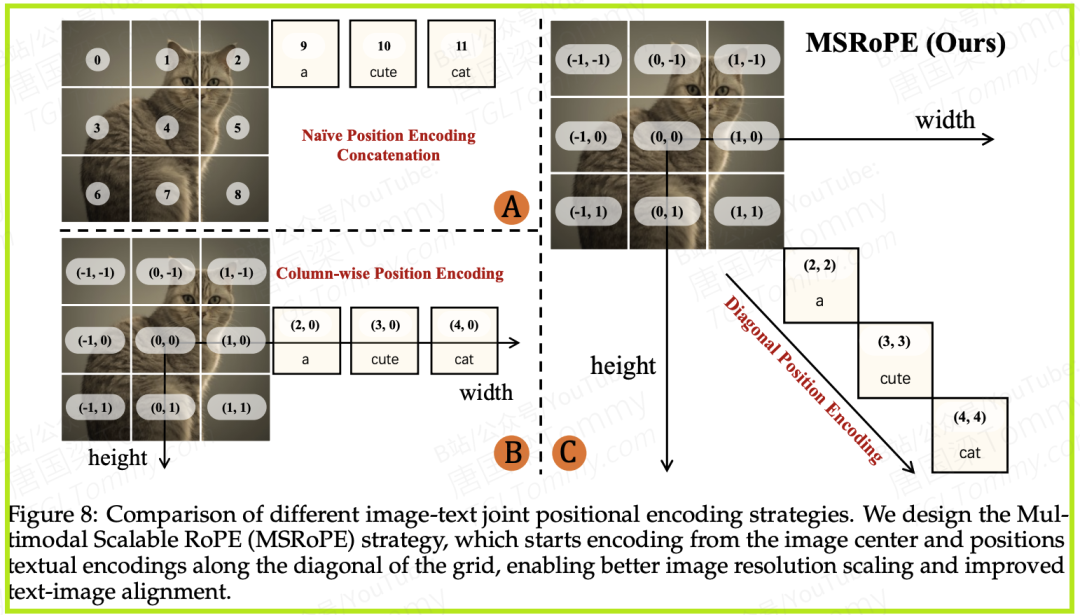
我们可以通过一个形象的类比来理解它:想象一下,我们将图像看作一个网格。
- • 传统方法 (A):将文本指令(a, cute, cat)当作一维序列,直接拼在图像网格特征后面。
- • Seedream 3.0的方法 (B):将文本指令放在了网格的特定一行,但这使得文本和该行图像在位置编码上变得难以区分。
- • Qwen-Image的MSROPE方法 (C):它非常巧妙地将文本指令看作二维元素,并沿着图像网格的对角线进行编码。
这种“对角线编码”的设计,既能让模型清晰地区分文本和图像,又能在不牺牲文本序列信息的同时,充分利用图像二维空间的缩放优势。这极大地提升了模型对文本-图像空间关系的对齐能力,是其能够实现精准文本渲染的“秘密武器”。
第三支柱:极致的数据工程艺术
“Garbage in, garbage out.”(垃圾进,垃圾出)——这句名言在AI领域是颠至不破的真理。Qwen-Image的研发团队深谙此道,他们在数据上投入了巨大精力。
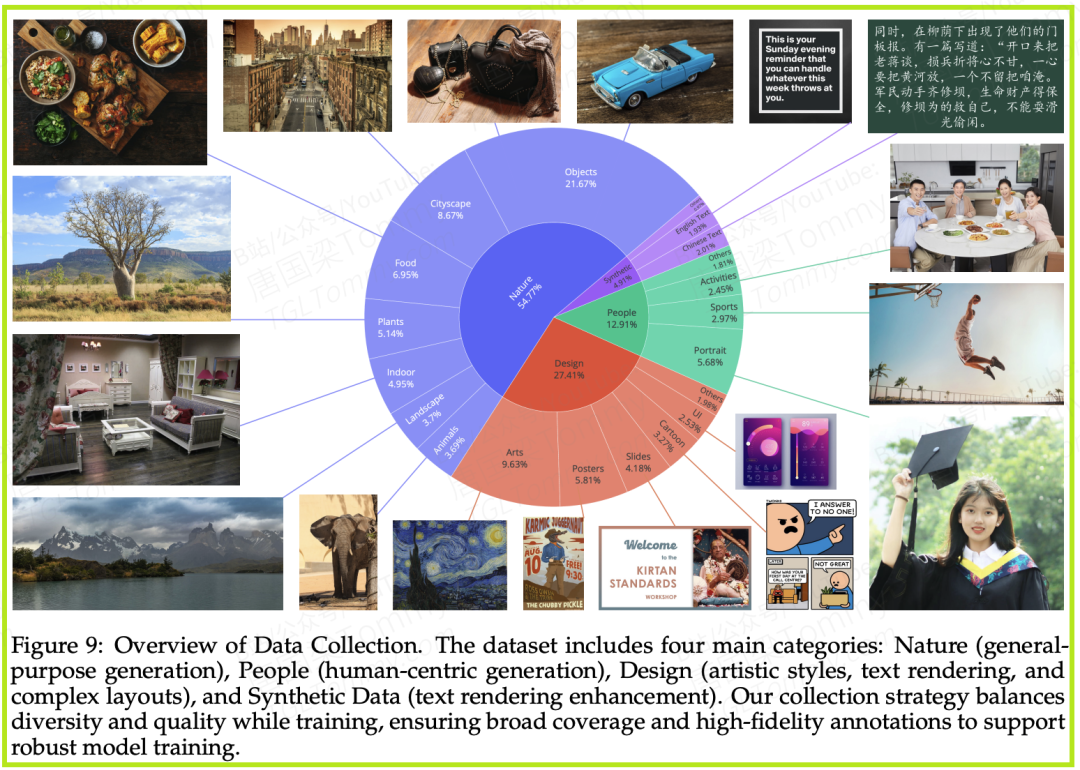
1. 多阶段、高标准的数据过滤:团队设计了一个严苛的、包含七个阶段的过滤流程。从最初的基础清洗(如剔除损坏文件、低分辨率图片),到中期的图文对齐筛选(使用CLIP等模型过滤掉文不对题的数据),再到后期对图像质量和美学的精细打磨,整个过程如同一套精密的筛网,确保最后用于训练的都是高质量的“精神食粮”。

2. 有的放矢的数据合成:真实世界的图像中,包含清晰、高质量文本的场景其实非常稀少。为了解决这一“数据荒”,团队开发了一套三管齐下的数据合成策略,专门用于清华模型的文本渲染能力。
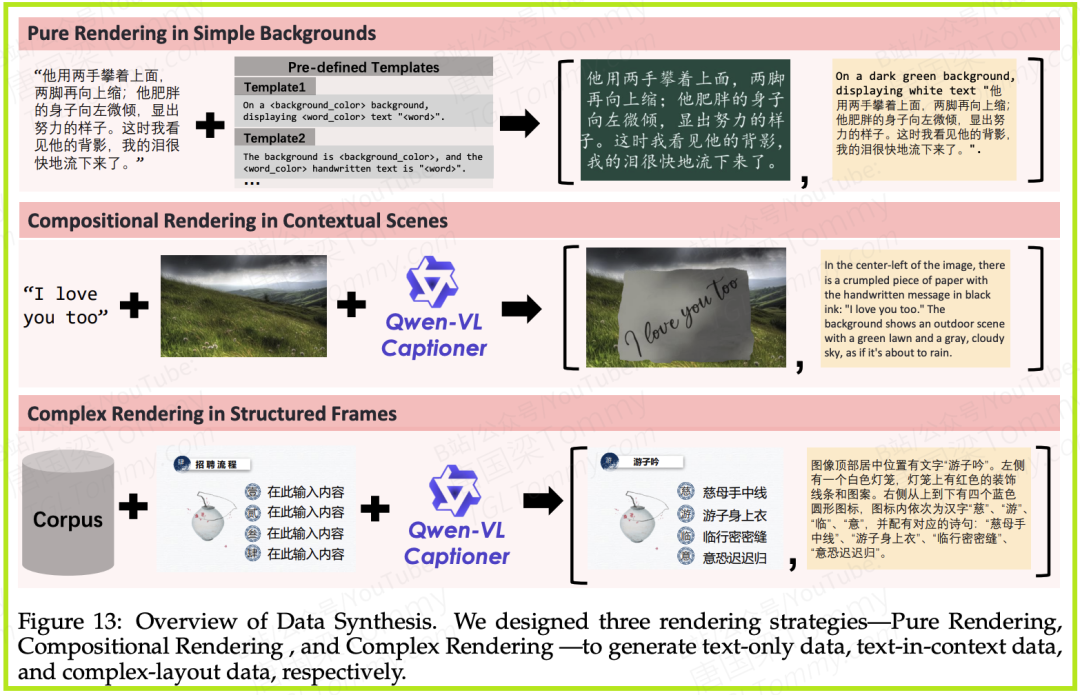
- • 纯粹渲染 (Pure Rendering):如同让一个书法初学者在白纸上反复练习,模型在干净的背景上渲染大量文本段落,以学习单个字符的形态和结构。
- • 情景组合渲染 (Compositional Rendering):将上一步生成的文本,无缝地嵌入到一张真实的照片中,比如一块木牌、一张纸条。这教会了模型如何在真实的环境光影和纹理下渲染文字,学习“上下文”。
- • 结构化模板渲染 (Complex Rendering):通过程序自动生成大量的PPT页面、UI界面或海报。这使得模型能够学习复杂的文本布局、对齐和多元素排版规则。
正是这种对数据的极致追求,为Qwen-Image的强大能力提供了最坚实的数据基础。
实验结果与分析
Qwen-Image在多个维度上与全球顶尖模型进行了正面交锋,并取得了令人瞩目的成绩。
人类盲评:在“AI竞技场”上力压群雄
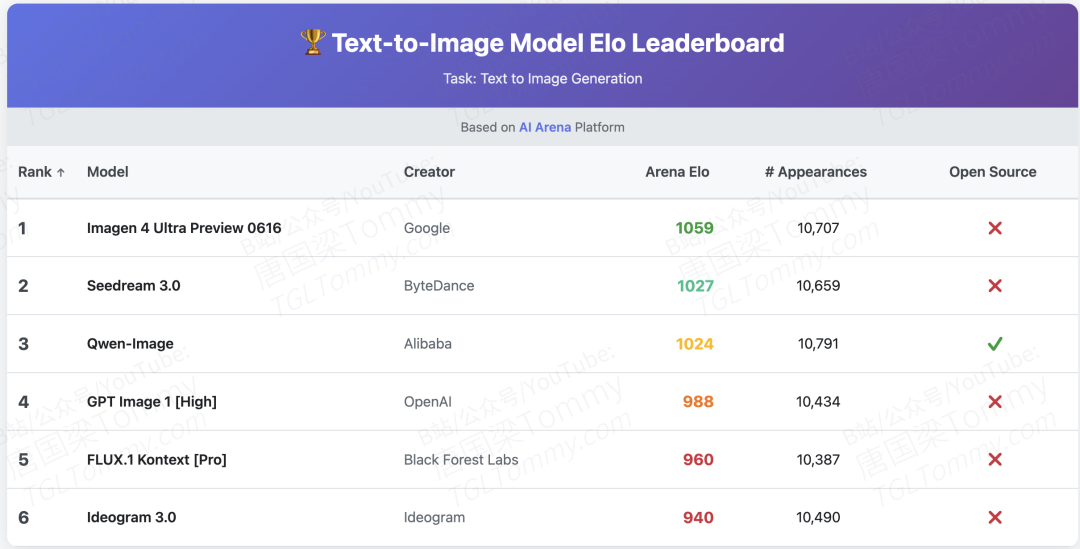
为了进行最公平的比较,团队搭建了一个名为“AI Arena”的匿名评测平台。用户在不知道模型名称的情况下,对同一提示词生成的两张图片进行投票。在这个平台上,Qwen-Image的Elo积分(一种衡量竞技水平的评分系统)达到了1024分,位列第三,显著超越了包括GPT-4o的图像生成模型(988分)和FLUX.1(960分)在内的多个强大对手。作为榜单前列唯一的开源模型,这一成绩含金量十足。
文本渲染:中文能力一骑绝尘
为了精准评估模型的文本渲染能力,尤其是在中文这一难点上,团队构建了一个名为ChineseWord的新基准。结果显示,Qwen-Image的综合准确率高达58.30,而其他顶尖模型,如Seedream 3.0和GPT Image 1,得分仅为33.05和36.14。这种碾压性的优势,充分证明了Qwen-Image在中文渲染上的突破。
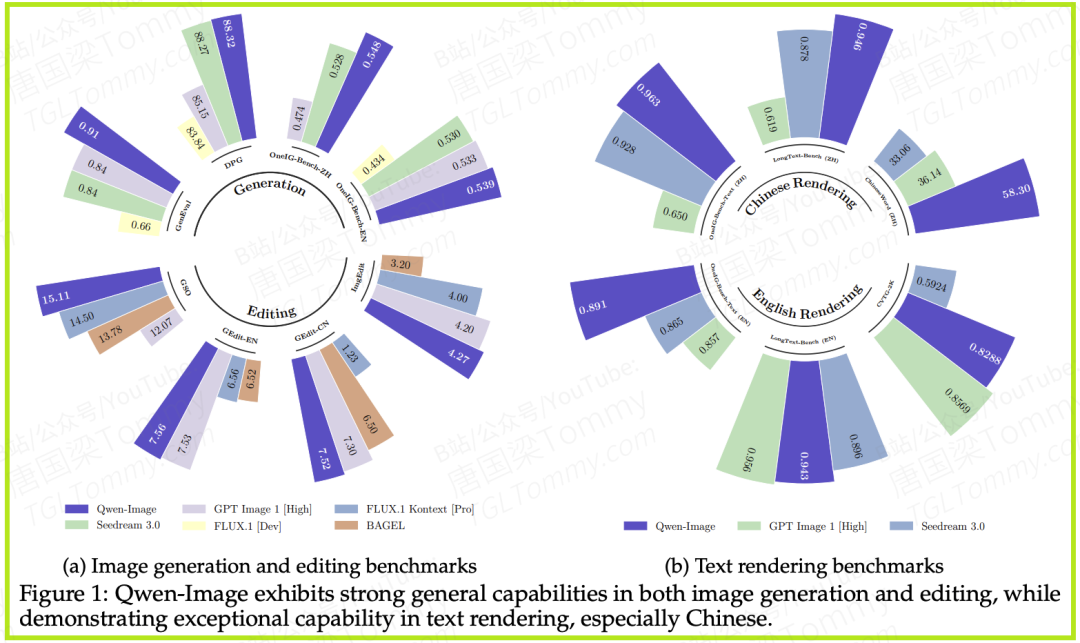
不仅如此,在LongText-Bench(长文本基准)上,Qwen-Image在渲染长段落中文时准确率位居第一,长段落英文位居第二,展现了其处理复杂文本场景的强大鲁棒性。
下面这张图直观地展示了Qwen-Image在生成中文对联时的惊人效果。它不仅准确地写出了所有汉字,还完美还原了书法的风格和悬挂的布局,而其他模型则出现了错字、漏字或无法生成的问题。

通用能力:全能型选手的证明
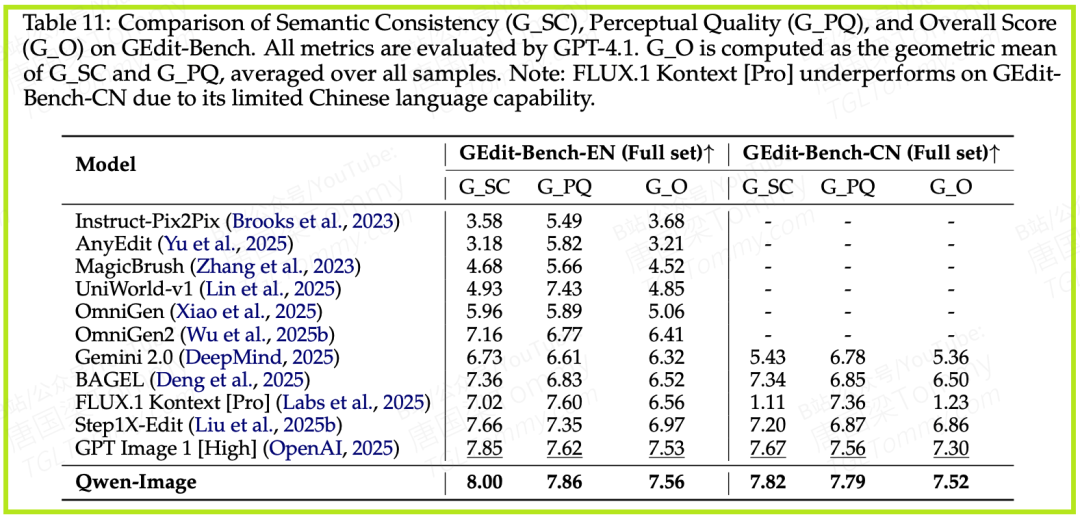
除了文本,Qwen-Image在通用图像生成和编辑基准上也取得了SOTA(State-of-the-Art)的成绩。例如,在综合评估模型指令遵循能力的GEdit-Bench上,无论是在英文还是中文任务中,Qwen-Image的综合得分均排名第一。这表明,它强大的文本能力并没有以牺牲通用性为代价。
启示与未来:从“画图”到“交流”
Qwen-Image的出现,为我们揭示了AIGC未来发展的几个重要方向:
- • 从LUI到VLUI的演进:论文提出了一个引人深思的概念——从**语言用户界面(LUI)到视觉-语言用户界面(VLUI)**的转变。未来的人机交互,或许不再是单调的文字问答。
- • 生成与理解的统一:Qwen-Image的成功证明,一个模型要能精准地“生成”,它必须首先具备深刻的“理解”。能画出正确的汉字,是因为它理解了笔画结构;能进行合理的布局,是因为它理解了空间关系。未来,生成与理解的边界将愈发模糊,两者将螺旋上升,共同推动AI认知能力的提升。
- • 通往视频生成的阶梯:模型在图像编辑中展现出的高度一致性(例如,改变人物姿势但保持身份和服装不变),是实现高质量视频生成的关键前提。Qwen-Image在静态图像上打下的坚实基础,为未来向更复杂的动态视频生成领域迈进铺平了道路。
总而言之,Qwen-Image不仅仅是一个在特定任务上取得突破的模型,它更像是一个宣言,标志着AI文生图技术正在从“艺术创作”的初阶,迈向“信息沟通”的高阶。通过教会AI如何“读”和“写”,我们正在赋予它更强大的交流能力,使其有望在教育、设计、知识整理等领域扮演更重要的角色。
论文名称:Qwen-Image Technical Report
第一作者:阿里
论文链接:https://www.arxiv.org/pdf/2508.02324
最新日期:2025年8月5日
github:https://github.com/QwenLM/Qwen-Image.git本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号