字节重磅开源统一多模态 Lance:3B 参数撑起图、视频、编辑全栈新解法

字节重磅开源统一多模态 Lance:3B 参数撑起图、视频、编辑全栈新解法

唐国梁Tommy
发布于 2026-06-25 21:44:06
发布于 2026-06-25 21:44:06
当"理解"与"生成"还在各练各的
打开当下任何一份多模态模型的能力清单,你会看到一种割裂感:
"我们的模型支持图文理解、视频问答、文档 OCR——但请去看另外一个模型来做图像生成。"
理解侧的模型,沿着 LLaVA、Qwen-VL、InternVL 这条路一路演化,强项是语义抽象与跨模态对齐;生成侧的模型,沿着 Stable Diffusion、FLUX、HunyuanVideo 这条路一路演化,强项是高保真合成与时空动态。两条路径都跑得飞快,但中间隔着一条很深的鸿沟。
https://arxiv.org/pdf/2605.18678v2

要把这两件事塞进同一个模型里,绝不只是"把两个 backbone 拼起来"那么简单。理解需要语言对齐的高层语义,生成需要保留纹理与几何的低层连续表征——视觉表征本身就互相打架。再叠上图像与视频两种模态、生成与编辑两种任务,一旦混训,很容易顾此失彼。
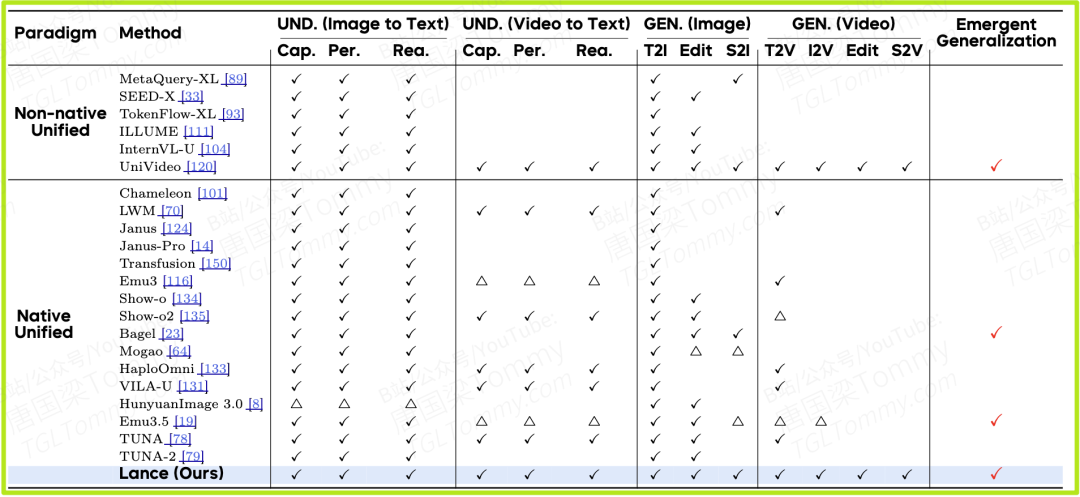
字节跳动智能创作实验室最近放出的 Lance,给出了一份很不同的答卷:在仅 3B 激活参数、128 张 GPU 的训练预算内,把图像与视频的理解、生成、编辑统统装进一个原生统一模型里——并且,多项指标已经追上甚至超过 7B、20B 量级的对手。
它到底要解决什么
把论文里的关键设定翻译成一句话:让多任务训练本身成为加速器,而不是绊脚石。
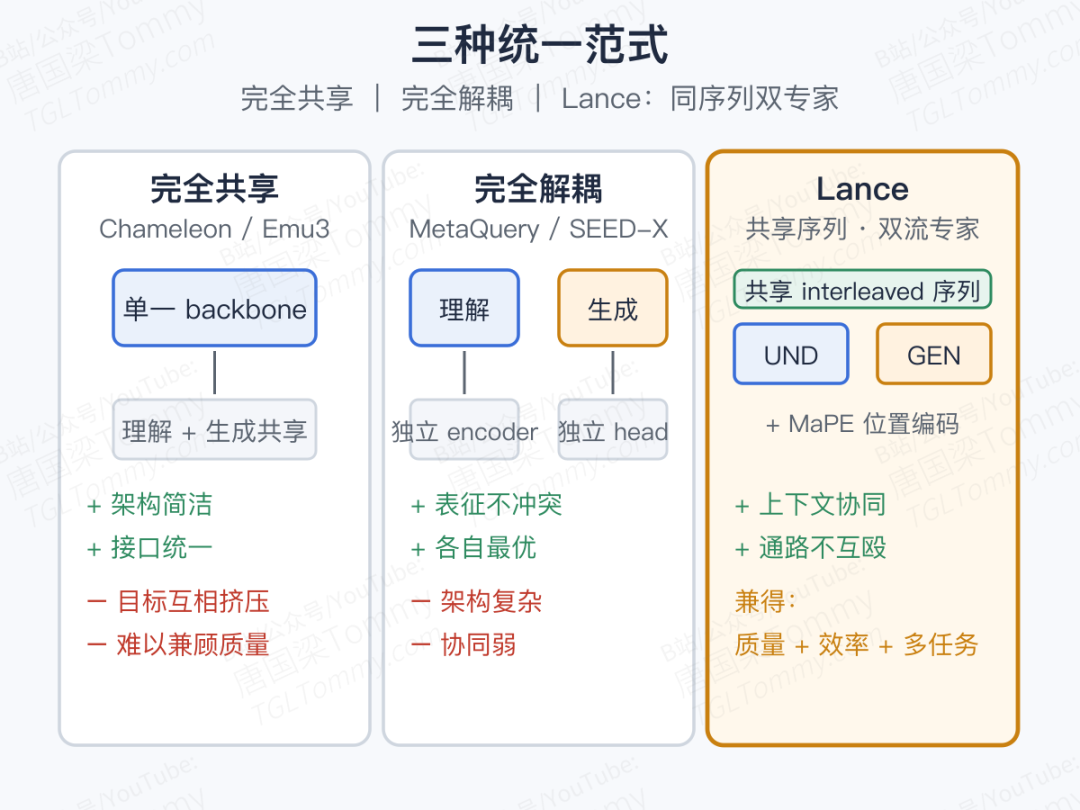
过往统一模型大致沿两条路线走:
- 一条是"完全共享",把理解与生成压进同一套表征、同一组参数。架构干净,但两个目标互相挤压,效果难以两全。
- 一条是"完全解耦",理解和生成各自拥有独立的视觉编码、独立的子模型。性能更稳,但架构复杂、训练成本高。
更棘手的是,大多数现有工作仍以"文 + 图"为中心,视频侧覆盖不全;编辑与主体驱动生成往往被当作下游微调技能,而不是统一训练里被系统优化的目标之一。
Lance 想要的是另一种平衡:统一的上下文学习承载跨任务交互,解耦的能力通路承载各自的目标。前者保留协同,后者避免互殴。
设计的两条主轴
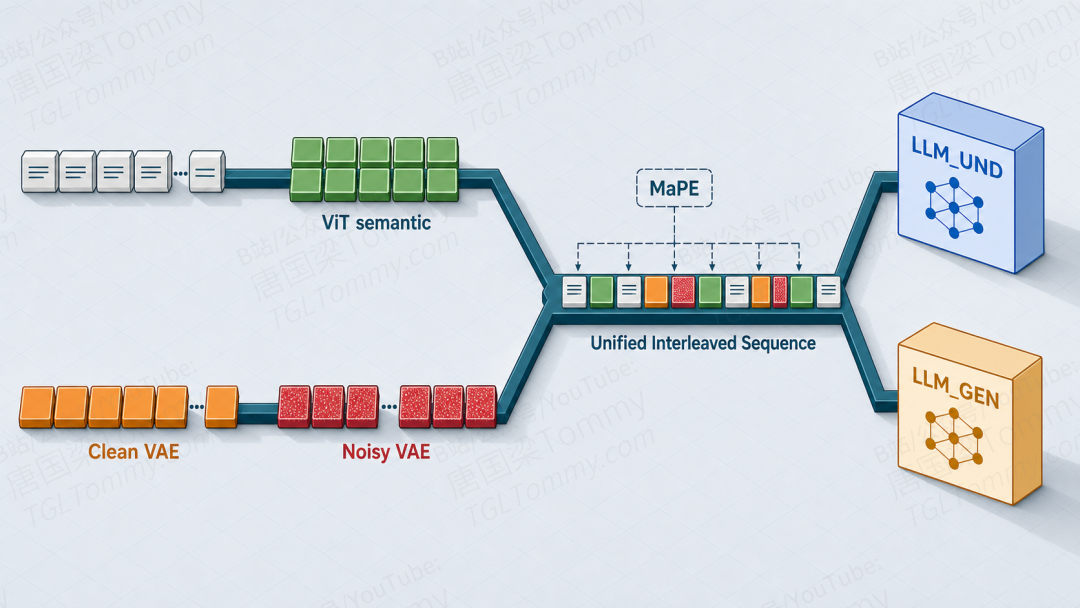
3.1 一条统一的"多模态序列"
Lance 把所有输入都翻译成一条共享的、交错排列的 token 序列:文本 token、ViT 语义视觉 token、干净的 VAE 隐变量 token、加噪的 VAE 隐变量 token——全部活在同一条序列里。

这条序列承担两件事:
- 文本与 ViT 语义 token 喂给理解专家
LLM_UND,做下一 token 预测,负责说话和推理; - VAE 隐变量 token 喂给生成专家
LLM_GEN,做 flow matching 速度预测,负责合成图像与视频。
两位专家共用同一份多模态上下文,但各自走自己的损失、自己的输出头。论文用一行公式概括整体目标:
L = λᵤ · L_UND + λ_g · L_GEN
干净利落:一条序列、双流专家、双任务损失。
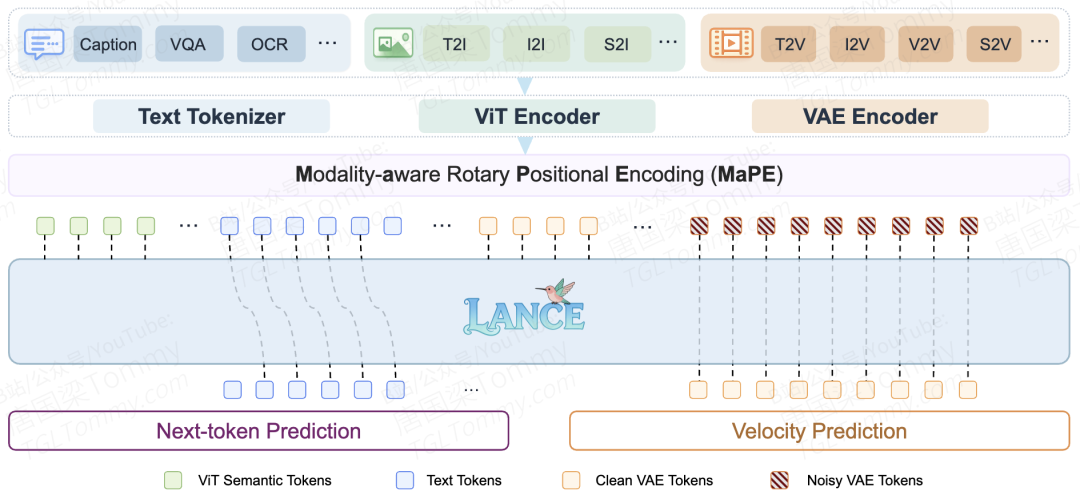
3.2 一个被忽视的小细节:模态位置编码
把三组异质视觉 token 混在同一条序列里,会冒出一个不太显眼但很要命的问题——位置编码会"看不清"它们到底是谁。
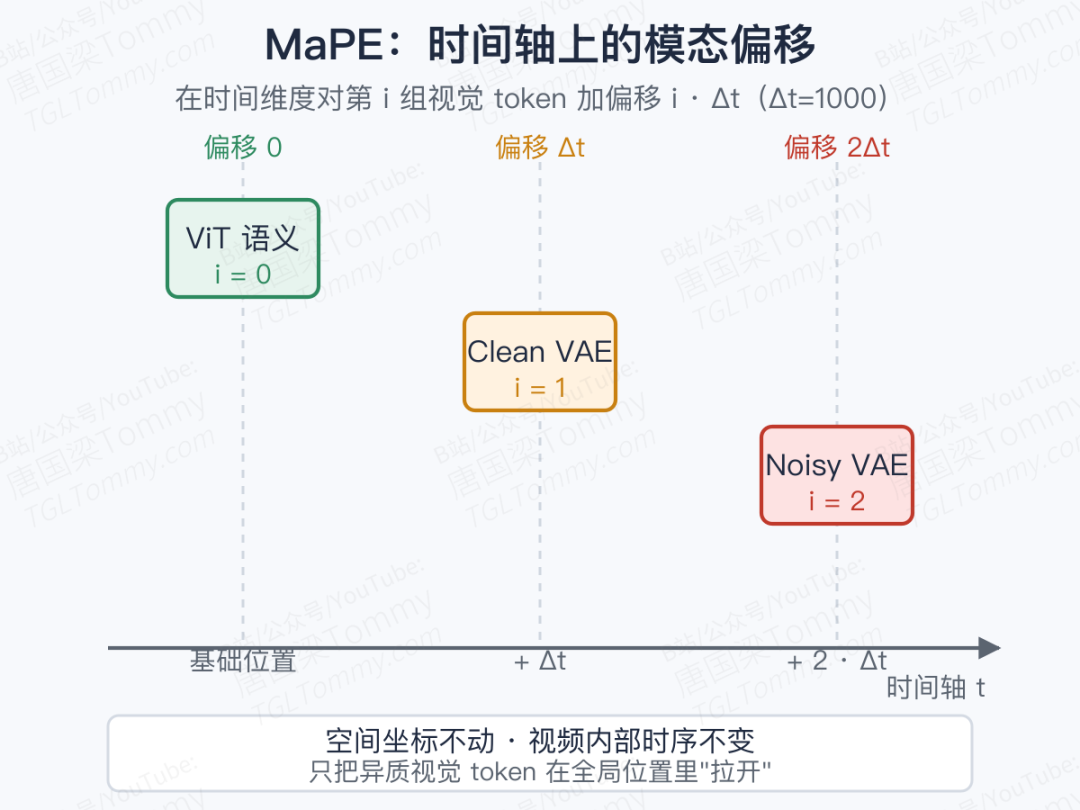
标准 3D-RoPE 只编时空坐标,无法区分"我是 ViT 语义 token"和"我是 noisy VAE 目标 token"。Lance 给出的解法叫MaPE (Modality-aware Rotary Positional Encoding):对第 i 组视觉 token,在时间维度上加一个固定偏移 i · Δt(论文里 Δt = 1000)。
简单一招——只在时间轴上加偏移,空间坐标完全不动。
好处是双重的:不同模态的 token 在全局位置空间里被显式分开,但视频内部的时间顺序和相对距离完全保留,图像内部的空间结构也没被打散。
训练像一场分段长跑
光有架构还不够,把"理解 + 生成 + 编辑 + 视频"全部塞进一个模型,训练顺序错了就是灾难。Lance 把训练拆成四个阶段,每一段都有明确分工:
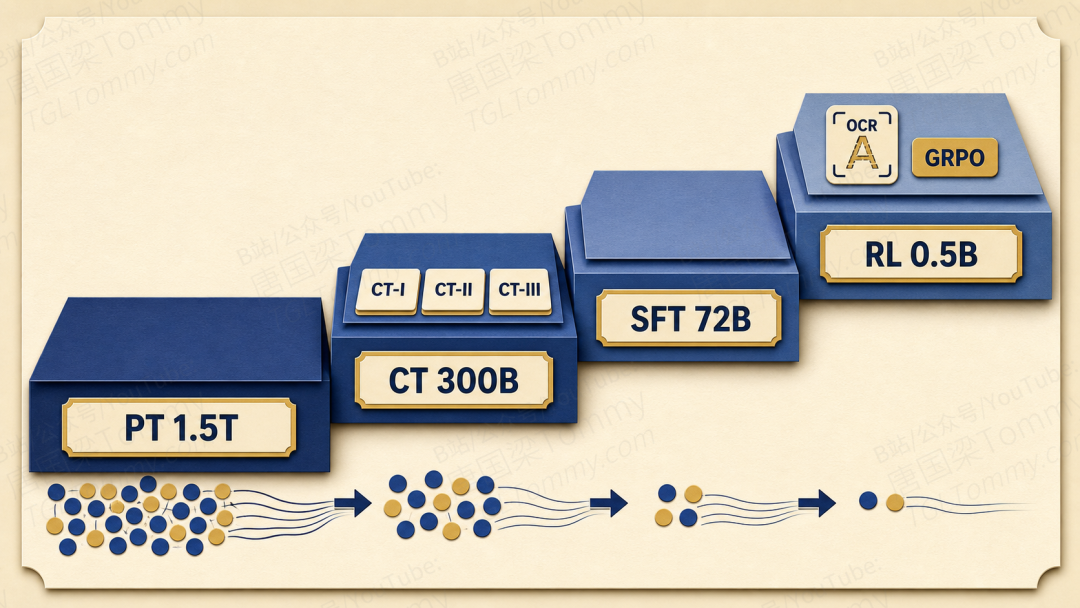
- PT 预训练:约 1.5T tokens,主要是图文/视频文对,建立基础的视觉对齐与生成能力,分辨率从 192p 渐进到 480p。
- CT 持续训练:约 300B tokens,引入交错多模态、编辑、主体驱动等"高难度"任务,并把它们再分三个子阶段,逐步提高编辑数据比例。
- SFT 监督微调:约 72B tokens,用精选高质量数据修指令一致性、视觉保真度、身份一致性这些细致活。
- RL 强化学习:约 0.5B tokens,用 GRPO 直接奖励文本渲染、组合一致性等难以靠 SFT 学到的细节,PaddleOCR 充当 reward 模型。
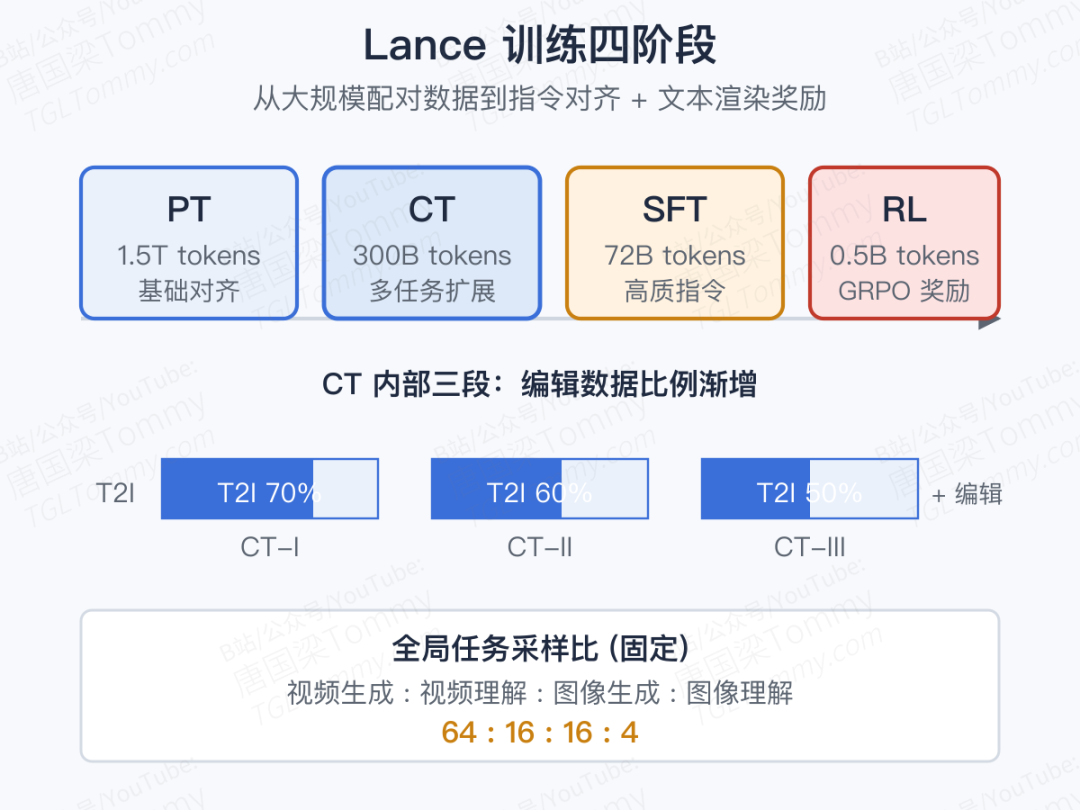
值得多看一眼的是 CT 阶段的数据 mixture:视频-生成 : 视频-理解 : 图像-生成 : 图像-理解维持在 64 : 16 : 16 : 4,并对视频侧给到 1:4 的偏重——这是为了让更难、更慢收敛的视频任务能拿到足够的学习信号。
结果端,哪些数字值得看
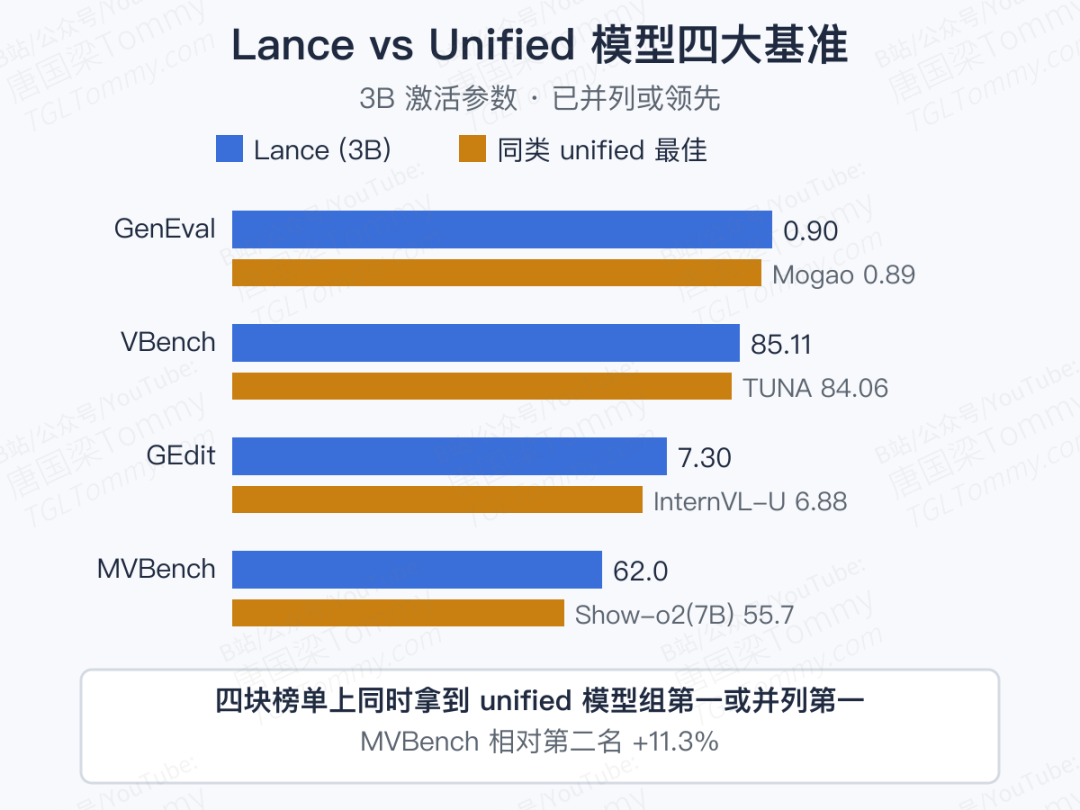
Lance 用 3B 激活参数,在四个方向上同时拿出了不俗的答卷:

- 图像生成:GenEval 综合 0.90,与 Mogao(7B) 并列 unified 模型最佳;DPG-Bench 综合 84.67,在 relation 维度 93.38 位列前茅。
- 视频生成:VBench 总分 85.11,unified 模型第一;Multi-Objects、Human Action、Spatial Relation 几项均明显领先。
- 图像编辑:GEdit-Bench 综合 7.30,unified 模型第一,在背景替换、材质修改、肖像美化等 7 个子项上拿到最高分。
- 视频理解:MVBench 综合 62.0,unified 模型第一,比第二名 Show-o2 (7B) 相对高出约 11.3%;以一半甚至更少的参数,已超过许多"只做理解"的专用模型。
更有意思的是消融结果:当训练数据混合从"只生成"扩展到"生成 + 理解 + 多任务",三个方向的指标都被同时拉高了——GenEval 从 80.88 → 82.06,VBench 从 81.25 → 83.05,MVBench 从无到 59.18。论文据此提出了一个不算激进、但相当有意思的判断:多任务训练不是单纯的能力堆叠,而是促进跨模态、跨任务迁移的机制。
不必夸大的几个限制
读完之后,几个边界也得说清楚:
- 文字渲染编辑仍是短板。GEdit-Bench 上 Lance 在 TT (Text Modification) 子项只有 4.46,明显落后于 GPT Image 1 与 Qwen-Image-Edit——这也是 RL 阶段专门用 OCR reward 想压的方向,仍未补齐。
- 生成-only 大模型仍有压制。20B 的 Qwen-Image 在 GenEval 综合分上仍以 0.87 vs 0.90 接近,但在 DPG-Bench 上以 88.32 优于 Lance 的 84.67——这告诉我们,统一不是免费午餐,纯生成模型在窄目标上仍有体量优势。
- 3B 是激活参数,不是总参。Lance 是双流 MoE,初始化自 Qwen2.5-VL 3B,工程上的算力门槛仍在;只是相较 7B-20B 体量的对手,激活参数的确轻得多。
- 依赖外部预训练组件。VAE 采用 Wan2.2 的 3D causal VAE,理解侧编码器沿用 Qwen2.5-VL 的 ViT——可以说 Lance 不是"从零造一个统一模型",而是"以已有强组件 + 新协同框架"做统一。
写在最后
Lance 给到这个领域的,不只是一个新的 SOTA 数字,更是一个相对清晰的工程范式:
当能力多、目标杂、模态异,结构上让它们走自己的路;语义上让它们共享一条上下文。
理解专家和生成专家在同一条序列里看着彼此发生的事,但又不必为彼此让步——这种"一起呼吸但各做各事"的安排,可能是统一多模态模型未来一段时间的基线姿势。
对开发者来说,更现实的好处是:训练统一模型不再必须用 7B 起步;3B 量级、128 GPU 的预算,已经能拿到接近一线效果的图、视频、编辑、理解的全栈能力。这意味着统一多模态开始具备一种新的可行性——它不再只是大厂的奢侈品。
至于"emergent generalization 是不是会随着任务覆盖度的扩张而进一步显现"——表 1 已经透露了一个倾向:任务谱越宽,越容易在未见过的任务上自发泛化。Lance 把这件事做到了 unified 模型里目前最完整的版本之一,下一步会发生什么,可能比指标本身更值得等。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号