蚂蚁 Ling / Ring 2.6 技术报告

蚂蚁 Ling / Ring 2.6 技术报告

唐国梁Tommy
发布于 2026-06-25 21:49:36
发布于 2026-06-25 21:49:36
当所有人都在比谁的模型更大、谁烧的算力更多时,蚂蚁 Inclusion AI 的这份技术报告反其道而行:它没有从零再训一个万亿参数模型,而是把一个已经训好的万亿模型推上手术台,给它「换了一颗心脏」,再用三路协同的后训练把它打磨成既能秒回、又能深度推理、还能在真实环境里调用工具干活的 Agent 大脑。
论文链接:https://arxiv.org/abs/2606.15079

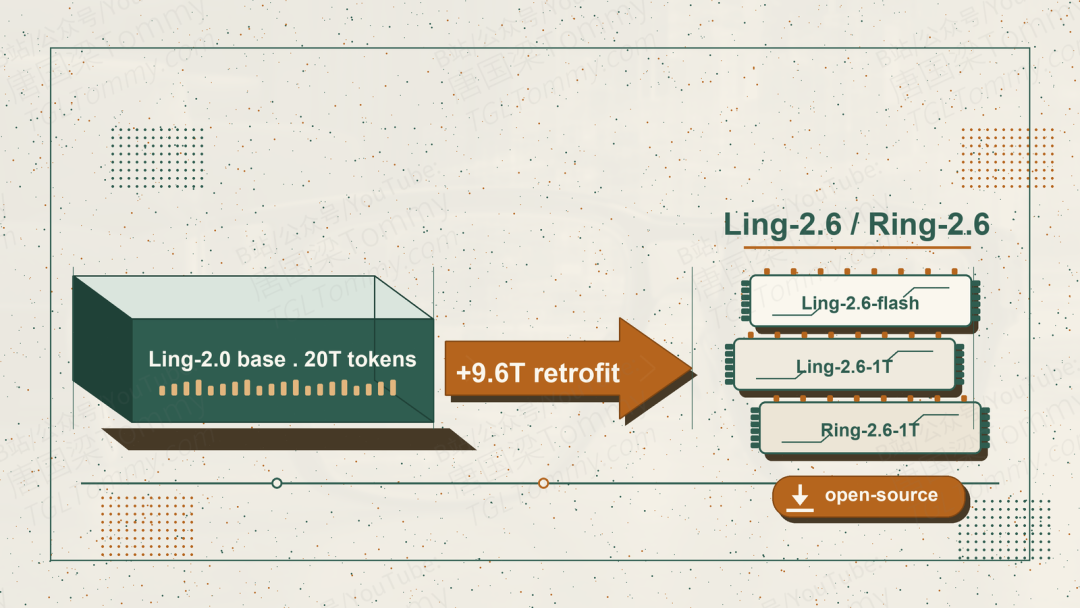
这篇文章拆解的是 arXiv 上的《Ling and Ring 2.6 Technical Report》。它一口气交付了一个模型家族——主打即时响应的 Ling-2.6 和主打深度推理与智能体的 Ring-2.6,参数规模从 104B 横跨到 1T,并且把三个权重(Ling-2.6-flash、Ling-2.6-1T、Ring-2.6-1T)全部开源。比单纯的「又一个 SOTA」更值得讲的,是它背后那套「不重训、靠改造」的工程哲学。
Agent 时代,大模型被三个目标同时撕扯
大模型正在从「聊天机器人」变成「智能体」。这个转变听起来只是换了个用法,实际上把模型的优化目标彻底改写了:一个实用的 Agent,必须同时推理得好、用工具用得稳、还得足够高效。
问题在于,这三件事天生互相打架。
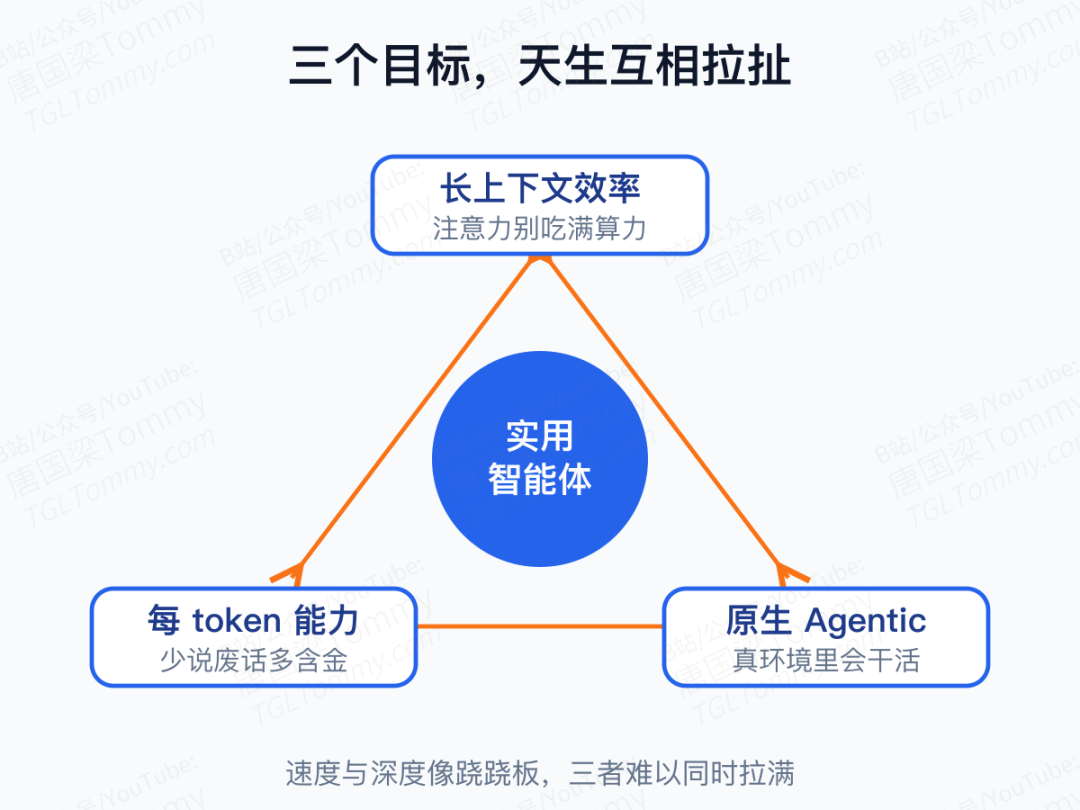
想让模型答得准,往往要让它「想得久」——把推理链拉长。可链一长,延迟和 token 成本就跟着飙升。反过来,把模型做得又小又快确实好部署,但它在需要严密推理、需要跨多步操作的长任务上又频频掉链子。速度与深度,像跷跷板的两头。
而万亿参数这条路还埋了第三个坑:从头训练一个 1T 模型贵得离谱。蚂蚁的上一代 Ling-2.0-1T 已经吃进去了 20T tokens 的训练投入,推倒重来等于把这笔巨额沉没成本直接扔掉。
所以报告开篇就立了一个明确的靶子:实用的智能体智能,必须沿着长上下文效率、每个 token 的能力密度、面向真实 Agent 工作流的原生优化这三个方向同时往前推,而不是顾此失彼。
不重训,而是给万亿模型「换心」
第一刀,砍向注意力机制。
在传统的 GQA(分组查询注意力)架构里,上下文一长,注意力就成了吞算力的黑洞。报告给出一个很扎眼的数字:当上下文超过 32K tokens,注意力消耗的算力占比就超过总 FLOPs 的 60%;到了 256K,全注意力直接变成绝对瓶颈。
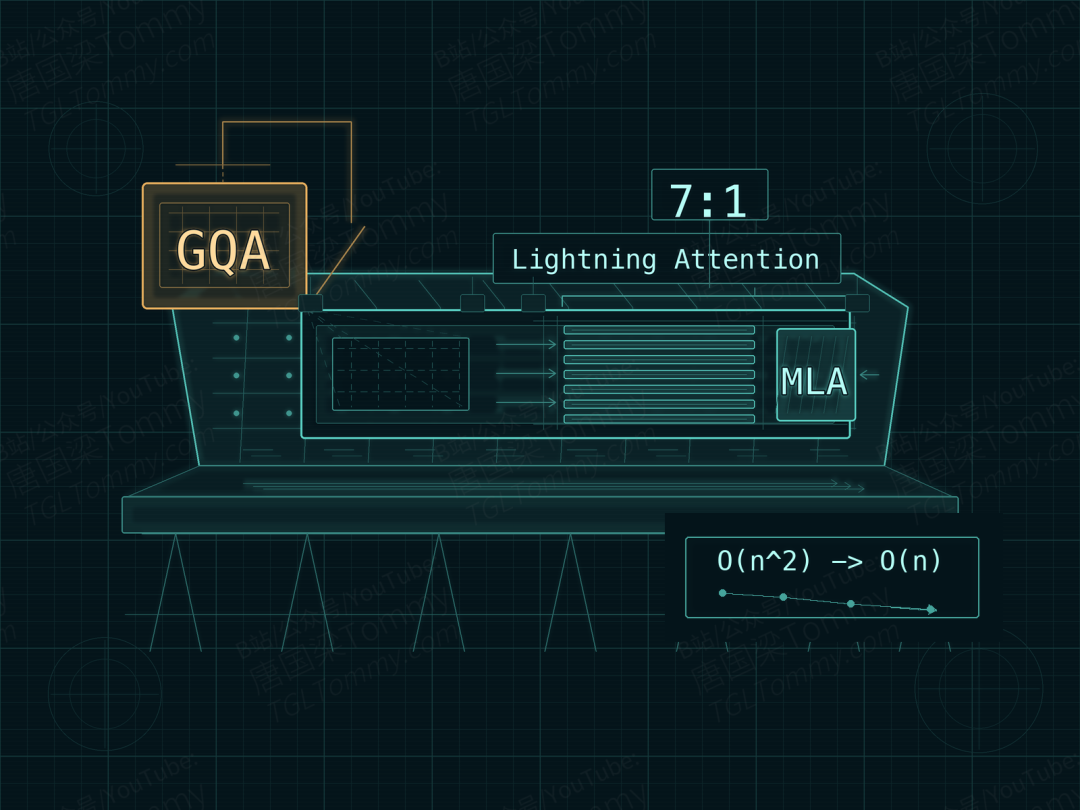
2.6 的解法是换一套混合线性注意力:把 Lightning Attention(线性注意力)和 MLA(多头潜注意力)按 7∶1 的比例混搭。线性注意力把每个 token 的计算成本从 O(n²) 压到 O(n);MLA 则把庞大的 KV 缓存压进一个低秩的潜空间。这个 7∶1 不是拍脑袋定的,而是团队在等算力约束下跑了一组 scaling law 实验,从 1∶1、3∶1、7∶1、15∶1 里挑出的最佳平衡点——再激进到 15∶1,性能就开始明显退化了。
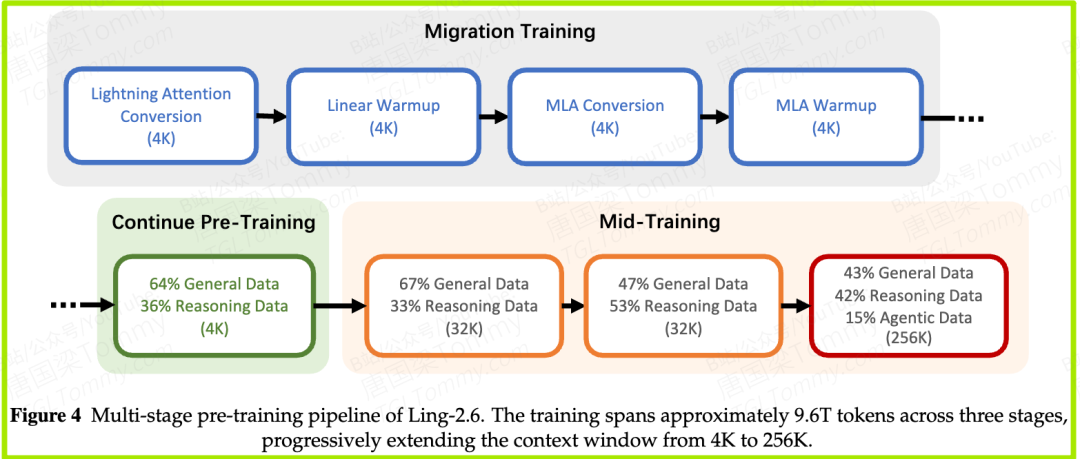
但真正精彩的是「怎么换」。给一个已经训好的万亿模型动注意力,相当于在心脏跳动时做移植手术,稍有不慎整个模型就废了。团队设计了一套四步平滑迁移,用大约 400B tokens 完成:先做 Lightning Attention 转换,再用 Linear Warmup 让新初始化的线性注意力参数对齐已有表征,接着做 MLA 转换,最后用 MLA Warmup 把损失拉回手术前的水平。

过程中还有两块「排异反应」要处理:原模型的 QK Norm 是个非线性操作,会挡住 MLA 推理所需的权重吸收——团队用一套基于校准样本的方法,把归一化的效果近似融进 Q、K 投影权重里,从而干净地移除它;原模型用的是 Partial RoPE 而非 Full RoPE,团队把受位置编码影响的维度单独解耦出来做 PCA 旋转,再拼回去,保住了原有结构。
完成换心后,模型在大约 9.6T tokens 的继续训练里分三阶段长大:迁移预训练、继续预训练(8T tokens、4K 上下文),以及中段训练(1.2T tokens),上下文窗口一路从 4K 扩到 32K、再扩到 256K,最终支持 262,144 tokens 的超长输入。一整套下来,解码吞吐比上一代基于 GQA 的 2.0 还要高。
让每个 token 都更值钱
第二刀,砍向「废话」。
这里有个容易误会的点:所谓 token 效率,不是简单地让模型把话说短。报告说得很直白——他们追求的是「每个生成出来的 token 携带更高的能力密度」,而不是把回答粗暴截短的表面文章。
为此 2.6 在后训练里叠了好几层手段:用 Evolutionary Chain-of-Thought(Evo-CoT)剔掉冗余的推理步骤,但不靠「越短越好」这种幼稚的长度最小化;用 LPO(语言单元策略优化)把优化的颗粒度从「单个 token」上移到「语义连贯的语言单元」,让信用分配更准、减少无意义重复;用双向偏好对齐去奖励信息量足、约束满足的输出,同时惩罚逻辑错误、幻觉和套路化的啰嗦;最后再用「最短正确答案蒸馏」进一步压实能力密度。报告还提到一个细节:光是在数据层面剪掉那些「答对之后还要再反思一遍」的过度反思段落,平均输出长度就能减少 200 到 300 个 token。
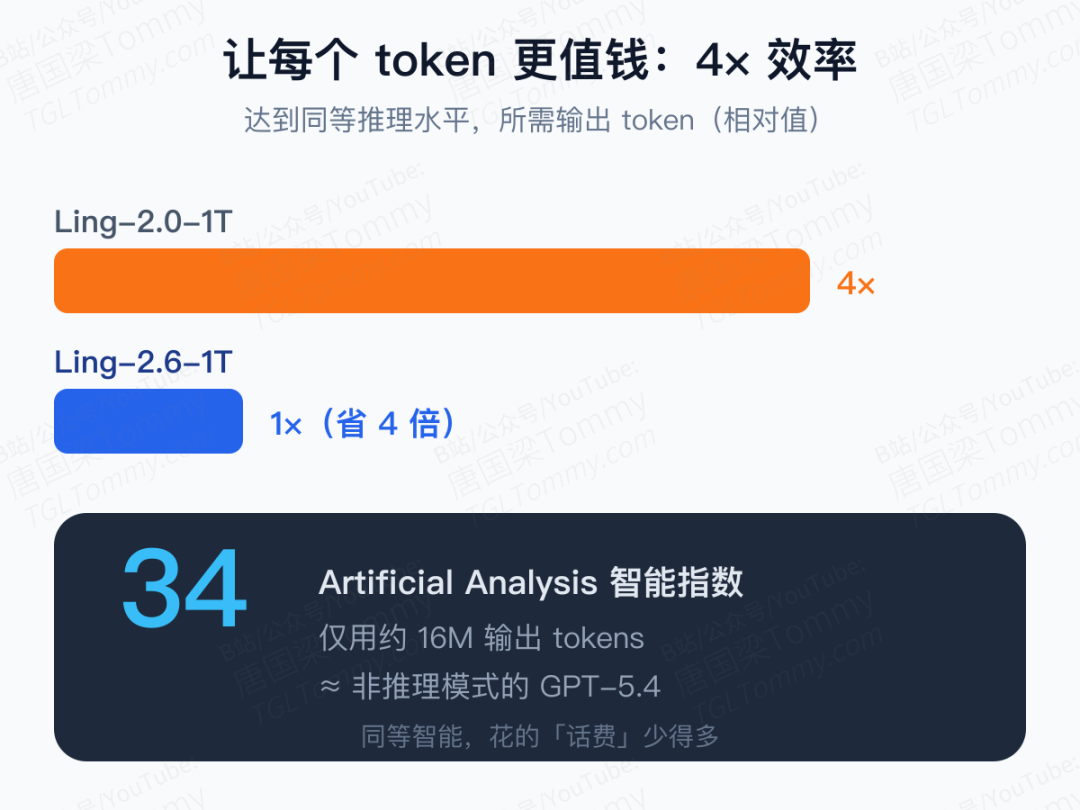
这套组合拳的效果是:在推理类任务上,2.6 的 token 效率比 2.0 提升了约 4 倍。一个更有冲击力的对照是——Ling-2.6-1T 在 Artificial Analysis 智能指数上拿到 34 分,却只用了约 16M 输出 tokens,这个表现已经和非推理模式下的 GPT-5.4 相当。说白了,同样的智能水准,它花的「话费」少得多。
Agent 能力是「训」出来的,不是「蹭」出来的
第三刀,砍向「假智能体」。
很多模型的所谓 Agent 能力,其实是从聊天数据里顺带蹭来的——本质还是个会聊天的模型,套了层指令微调的壳。2.6 的态度截然不同:智能体能力是被当成一等训练目标直接训出来的。

为此团队构建了覆盖工具调用、编程、搜索、工作流执行、多轮交互的庞大智能体语料:调用了 500 多个真实 MCP 环境、3000 多种不同工具;编程智能体的数据则是从 GitHub 的 GH-Archive 里大规模挖掘「PR—Issue 配对」,层层筛选后得到约 2500 个高质量实例,覆盖 1550 个仓库、30 多种编程语言,而且每个 PR 都必须自带测试补丁以保证可验证。
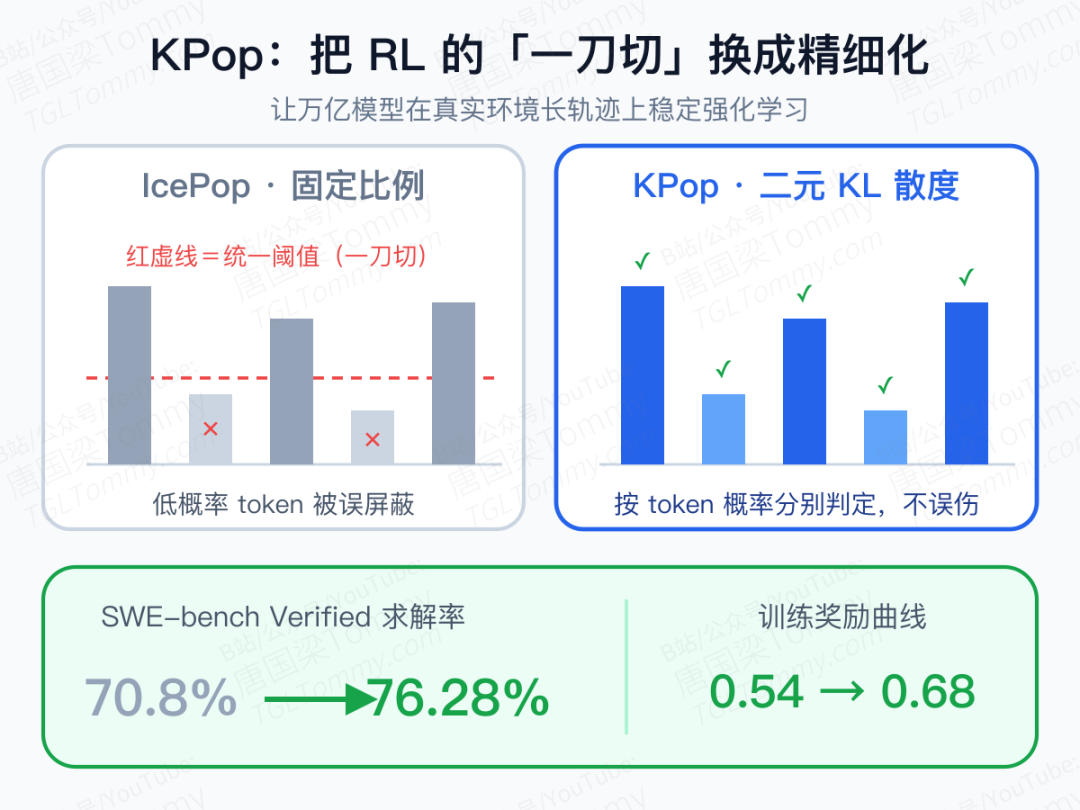
而 Ring-2.6 真正的杀手锏,是一个叫 KPop 的强化学习算法。它要解决的是一个很硬核的工程难题:让万亿参数模型在真实环境的「长轨迹」上做 RL,训练极易崩。上一代的 IcePop 用一个统一的固定比例阈值去约束所有 token,但现实是不同概率的 token 失配程度天差地别——一刀切会过度屏蔽掉那些低概率 token。KPop 用二元 KL 散度替换了这个固定阈值,把整个词表看成「当前采样到的这个 token」对「其余所有」的二元划分,从而精细地刻画高、低概率区域里各自的失配,整个机制只靠一个超参数控制。
配合「把数据采集和参数更新解耦」的异步 RL,长达 200 轮(评测时放宽到 500 轮)的环境交互轨迹终于变得可训。KPop 带来的提升很实在:在 SWE-bench Verified 上,求解率从 70.8% 一路涨到 76.28%,训练奖励曲线也从 0.54 稳步爬到约 0.68。值得一提的是,团队还实时监控训练中的「奖励作弊」行为,发现只有约 0.2% 的轨迹存在投机取巧,基本可以忽略。
成绩单:又快又强,还能干活
把这三刀的效果摊开看,数字相当能打。
主打即时响应的 Ling-2.6-1T,在一众非推理 / 即时模式的顶尖模型里表现亮眼:知识类的 C-SimpleQA 拿到 76.53,推理类的 AIME26 高达 87.40、ARCPrize 50.94,智能体类的 PinchBench 85.24、τ²-bench 78.36,长上下文的 MRCR(16K—256K)更是冲到 80.37。轻量版的 Ling-2.6-flash 同样能打,在 4×H20 的部署条件下,解码吞吐做到 Nemotron-3-Super 的 1.3 倍、Qwen3.5-122B 的 2.4 倍、GLM-4.5-Air 的 4.3 倍,prefill 和 decode 都有最高 4 倍的加速。
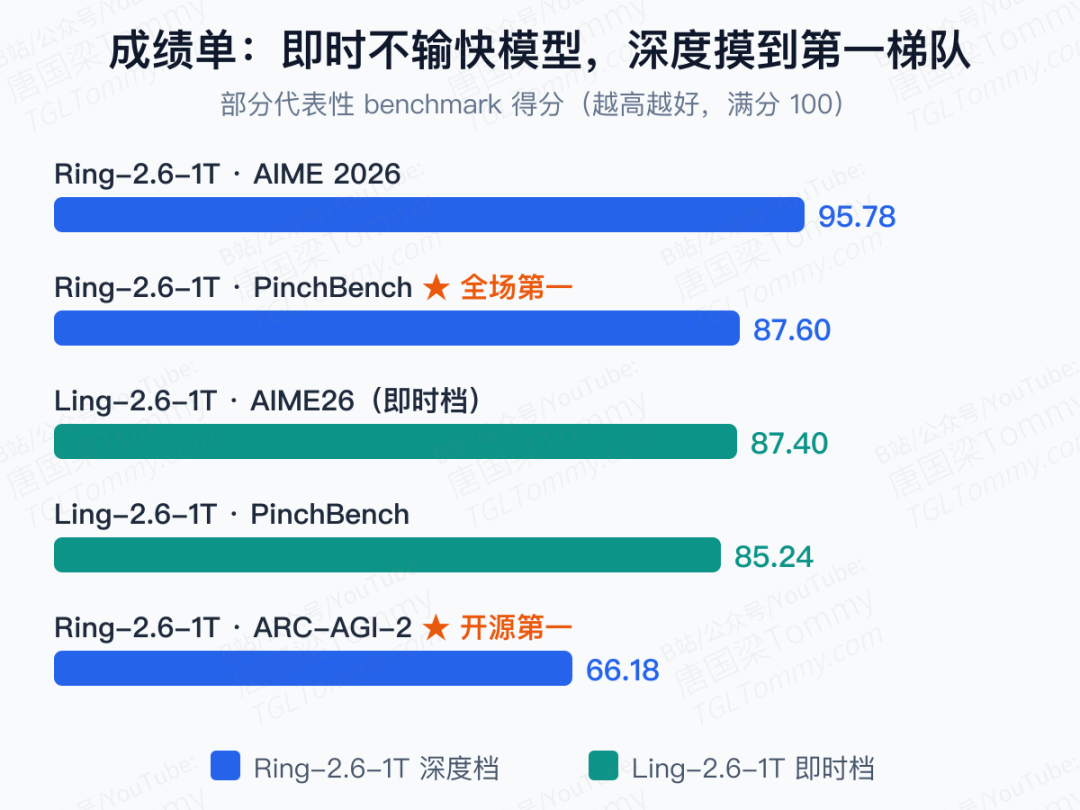
主打深度推理的 Ring-2.6-1T,在开它的「xhigh」满血思考档时,AIME 2026 飙到 95.78,HMMT-Feb26 拿下 93.47,而在号称最难的抽象推理 ARC-AGI-2 上以 66.18 登顶所有开源模型第一。切到更省算力的「high」档,它在 OpenClaw 的 PinchBench 上以 87.60 拿下全场(含闭源)第一,ClawEval 的 63.82 也是开源第一。
一句话总结这张成绩单:即时档不输闭源快模型,深度档摸到第一梯队,而且这一切是在「不重训」的前提下做到的。
六、它意味着什么,又还差什么
这份报告最有价值的,未必是某个榜单的最高分,而是它示范了一条务实的路径:当一个组织已经在某代基座上投入了海量算力,下一代不一定要推倒重来。架构可以「换心」式地原地改造,能力可以靠后训练精细蒸馏,智能体行为可以被当成原生目标直接训练。这对算力没有那么奢侈的团队,是一个很有借鉴意义的范式。
当然,它并非全能。报告自己也坦诚:在 Agentic coding(如 SWE-bench Verified)这类硬核软件工程任务上,Ring-2.6 与 Kimi-K2.6、DeepSeek-V4-Pro 等头部模型仍有差距;轻量的 flash 版在纯推理深度上,也敌不过参数更大的开源模型——这正是「效率与能力」那杆秤无法回避的取舍。
但方向是清晰的:把模型做得又快、又强、又真的能用工具完成任务,并且把全部权重开源出来。在这个人人都谈 Agent 的时间点上,能把这三件互相打架的事捏到一起,本身就是一份分量十足的答卷。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号