zilliztech MFS 拆解:一套动词打通 20+ 数据源,Open Tag 怎么复刻 Claude Tag
原创
zilliztech MFS 拆解:一套动词打通 20+ 数据源,Open Tag 怎么复刻 Claude Tag
原创
术哥
发布于 2026-06-28 11:02:38
发布于 2026-06-28 11:02:38
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 151 篇,Milvus 最佳实战「2026」系列第 15 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。

MFS 统一工作空间信息图封面
封面:MFS 把 20+ 数据源统一成一棵可检索的文件树
这阵子在翻 zilliztech 的开源项目,发现一个现象:社区里聊 AI Agent,绕不开一个问题——上下文从哪来、怎么管。
一个稍微正经点的 Agent,要读代码仓库、翻文档、查 Issue,还要对接 CRM、数据库、对象存储、聊天记录。这些数据散落在几十种来源、几十种格式里。Agent 想用它们,要么一个个写对接代码,要么把数据搬到一个地方再喂进去。更麻烦的是,每接一个新数据源,就得学一套新的查询语言、装一个新的 SDK。
这就是所谓的上下文孤岛。
zilliztech 的 MFS(Multi-source File-like Search)想解的就是这个,它给 Agent 的承诺是:一个统一的工作空间,一套动词触达所有数据源。而在 MFS 之上,还长出了一个叫 Open Tag 的示例应用,专门开源复刻 Slack 里 @Claude 那套工作流。
这篇文章把这三者的关系和源码事实讲清楚——它们经常被放在一起说,但其实是三个完全不同层次的东西。
说明:本文内容基于 zilliztech/mfs 源码(GitHub
zilliztech/mfs仓库的 README、SKILL、docs 及examples/open-tag-skill/示例)分析整理而成,源码分析基于笔者本地仓库版本,尚未在生产环境中完成全场景验证。文中的配置模板和参数建议仅供参考,实际效果请以你的业务数据和环境测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
1. 三个名字,其实是三层东西
先把容易混淆的地方说清楚。Claude Tag、MFS、Open Tag 不是平级的竞品,而是三个层次的东西:
名字 | 性质 | 归属 | 角色 |
|---|---|---|---|
Claude Tag | 官方产品形态 | Anthropic 生态 | 被复刻的范式 |
MFS | 开源基础设施 | zilliztech/mfs | 底层地基 |
Open Tag | 开源示例应用 |
| 示范上层应用 |
Claude Tag 是 Slack 里的 @Claude——你在频道里 @ 它,召唤一个由 Anthropic 托管的智能体,它带着企业治理、零运维、主动模式等能力。这是被复刻的范式。
MFS 是 zilliztech 开源的 Agent 上下文管理项目,License 是 Apache-2.0,向量检索能力由 Milvus 提供。它不关心你怎么在 Slack 里 @ 谁,只管一件事:把 20 多种数据源统一成一棵可检索的文件树,给 Agent 当记忆用。它是地基。
Open Tag 是 MFS 仓库 examples/open-tag-skill/ 目录下的一个小型示例,它把 Claude Tag 那套工作流在 MFS 之上重新做了一遍,当作参考实现(reference pattern)。
一句话总结:MFS 是 Open Tag 的 Memory 引擎,Open Tag 是 MFS 之上对 Claude Tag 工作流的开源复刻。搞清这个层次关系,后面读源码才不会拧巴。

三者分层关系图
图 1:三者不是并列关系而是分层关系——MFS 是地基,Open Tag 是上层示例,Claude Tag 是被复刻的范式
2. MFS:一套动词触达所有数据源
MFS 的官方一句话定位很直白:
A context harness for AI agents — and for building them: one unified workspace over your code, memory, skills, docs, messages, and every data source.
翻译过来就是:给 AI Agent 一个统一的工作空间,覆盖代码、记忆、技能、文档、消息和所有数据源。
它的架构是瘦客户端 + 有状态服务器(thin client + stateful server),对外只暴露一个 HTTP /v1 接口。客户端那侧是无状态的:mfs 命令行(Rust 写的)、Python/TypeScript SDK,还有给 Agent 用的两个 Skill——mfs-ingest(注册并索引数据源)和 mfs-find(跨已索引内容查找)。
所有状态都集中在 mfs-server 这一头:配置、凭据、环境变量、任务队列加 workers、engine/connectors/processors,还有数据后端。客户端瘦、服务器重——这么分的好处很实在:不同语言的客户端不用各自重写一遍索引逻辑,都复用同一套服务端能力就行。
同一套动词,到处适用
MFS 有个设计我印象很深:它没有发明新的查询语言,也没有给每个数据源配一个 SDK。
无论你面对的是本地目录、Postgres、GitHub 仓库、Slack workspace 还是 S3 bucket,统一用 <scheme>:// 这样的 URI 来寻址,然后用同一套动词去操作:
ls / tree / cat / head / tail / grep / searchAgent 本来就会说 shell,所以学一次就能到处用。想看某个 GitHub 仓库的结构,ls github://org/repo;想搜 Slack 里的历史讨论,search slack://workspace。两件事用的是同一套语法。
两条心智腿:Search 和 Browse
检索分两条路走:
- Search(需要先索引):
mfs search走的是混合检索,把 dense 向量语义和 BM25 关键词融合到一起;mfs grep则不需要索引,做精确或全文匹配。 - Browse(不需要索引):
ls / tree / cat / head / tail,可以渐进式地一路精确定位到字节或记录级别。
每条命中结果都带一个 locator——文本和代码是行号区间 {"lines":[s,e]},结构化记录(数据库行、Issue、聊天线程)则是主键字典。Agent 拿到结果就知道去哪儿读、读哪一段,不用再猜。
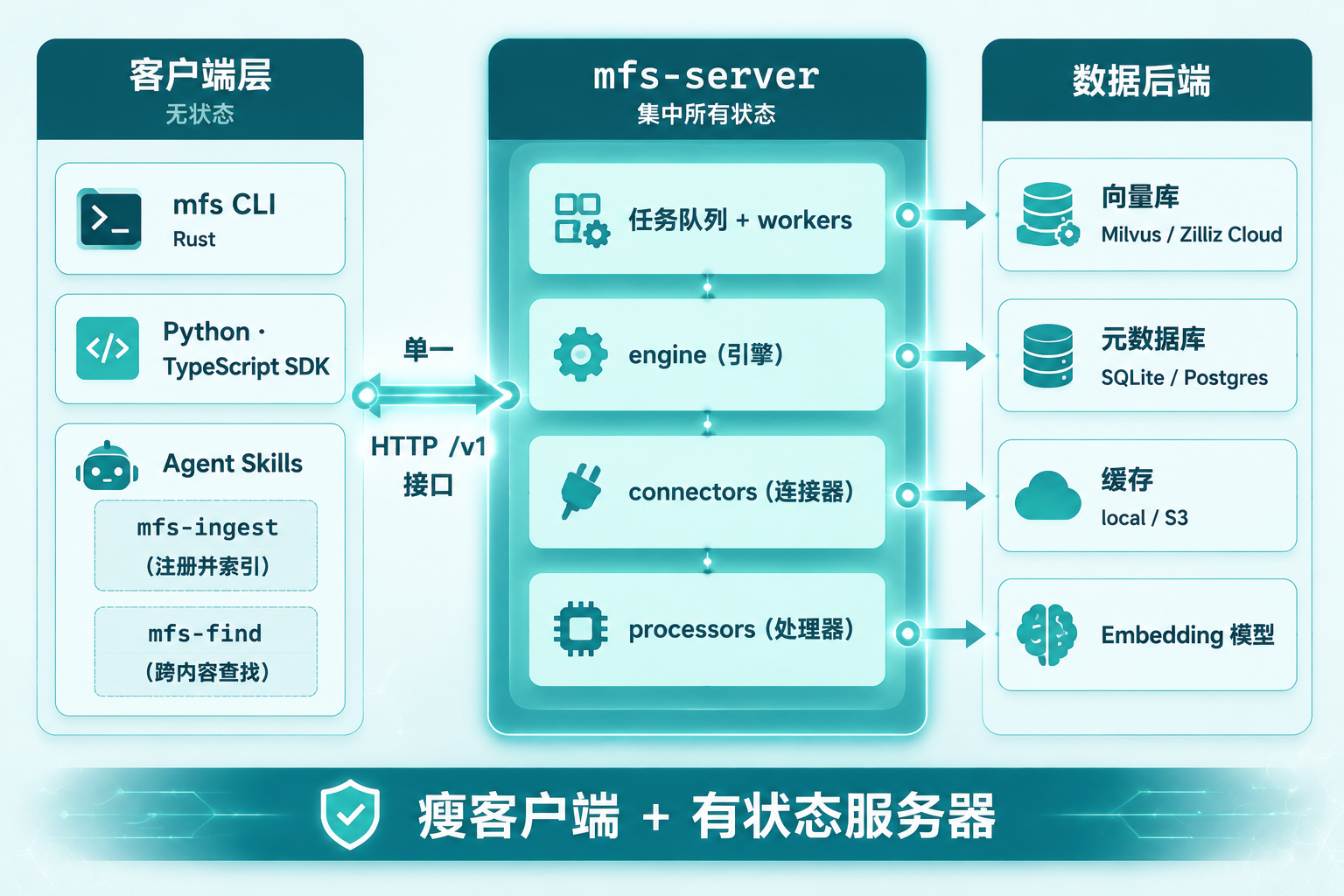
MFS 三层架构图
图 2:MFS 瘦客户端 + 有状态服务器架构,客户端无状态,所有状态集中在 mfs-server,单一 HTTP /v1 接口
3. 从本地零 key 到 Zilliz Cloud:后端按配置切换
MFS 的后端是按配置切换,而不是按代码切换的。本地一切数据都落在 $MFS_HOME(默认 ~/.mfs),换生产环境就是改配置:
后端类型 | 本地默认 | 生产替换 |
|---|---|---|
向量库 | Milvus Lite(本地文件) | 自托管 Milvus 或 Zilliz Cloud |
元数据库 | SQLite | Postgres |
缓存 | 本地文件系统 | S3 |
Embedding | 本地 ONNX(BGE-M3 int8,无 key) | OpenAI / Gemini / Voyage / Ollama |
图像描述 | 关闭 | OpenAI / Anthropic / Gemini |
本地优先,但天生为生产设计
这点很关键。MFS 本地可以完全离线跑:初次运行会下载大约 600 MB 的本地 embedding 模型到 ~/.mfs/,之后不需要 API key、不需要 GPU、不需要云账号。对开发者本地试验非常友好。
但它真不是个写着玩的 demo。README 里有一句原话:MFS was built for production from day one — not a weekend demo。意思是 MFS 一开始就是冲着生产环境去的,不是周末写着玩的 demo。同一套设计,把配置从 Milvus Lite 切到 Zilliz Cloud、把 SQLite 切到 Postgres,就能索引和搜索更大规模的语料。
这也是 Milvus 和 Zilliz Cloud 在整个故事里的角色:MFS 的向量检索能力由 Milvus 提供。你在本地用 Milvus Lite(一个嵌入式的本地文件向量库)起步,数据量大了,可以平滑升级到自托管 Milvus 集群,再往后还可以走 Zilliz Cloud 这个托管的 Vector Lakebase 服务。这条升级路径是连续的,应用代码不用推倒重来。
还有个让人安心的设计:索引是派生的、crash-safe 的。上游数据源永远是真相源头,索引只是它的衍生品——坏了、被删了,随时能从原始源重建,什么都不丢。生产环境里这个属性挺重要。
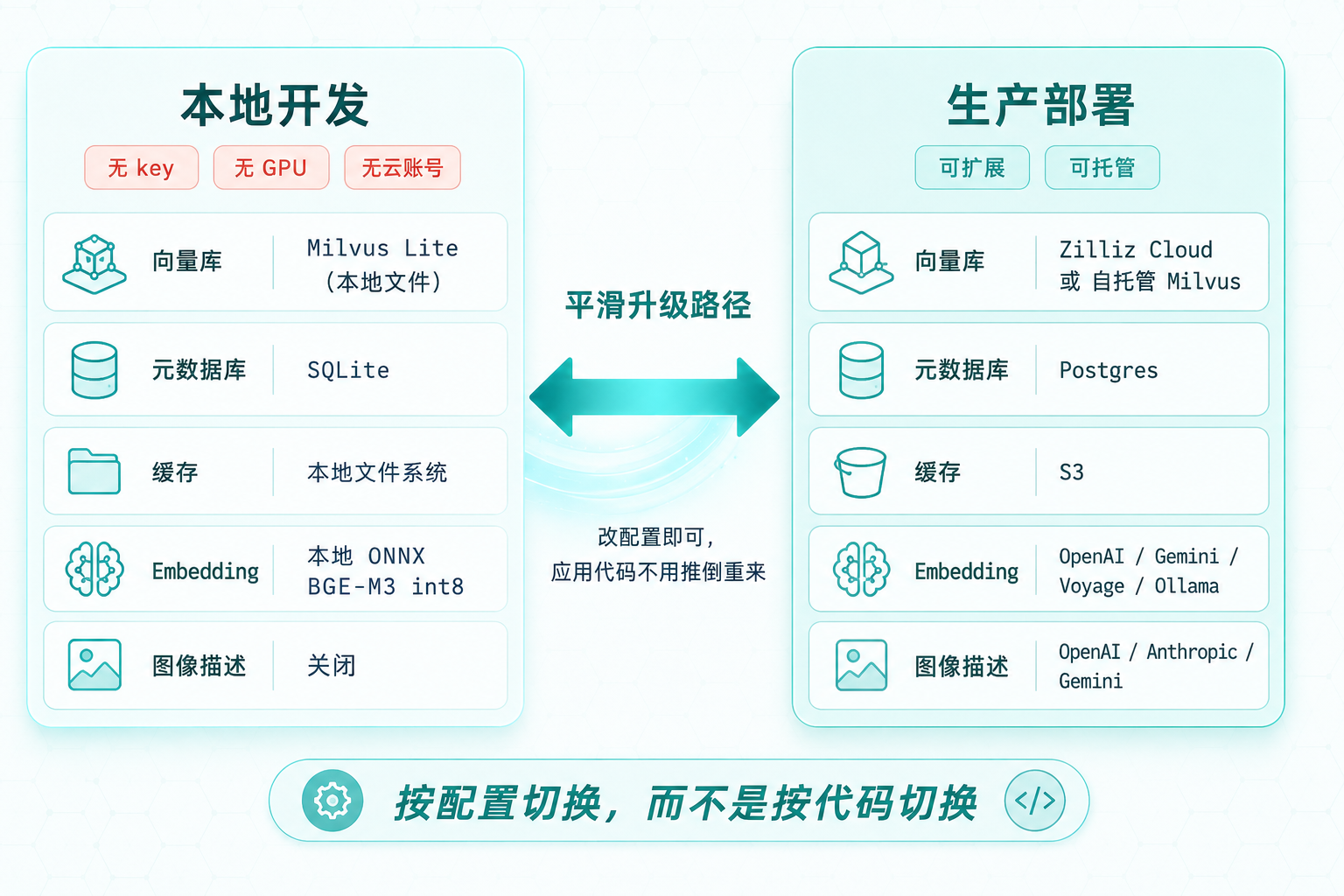
后端切换对比图
图 3:同一套设计,改配置即可——本地零 key 零 GPU 起步,平滑升级到 Zilliz Cloud 生产环境
4. Open Tag:把 Claude Tag 三要素映射到 MFS
讲完地基,来看上层的 Open Tag。
Open Tag 要复刻的 Claude Tag 工作流,可以拆成三个要素:Brain(大脑)、Memory(记忆)、Tools(工具)。Open Tag 把这三者明确映射到了自己的开源组件上:
要素 | Claude Tag(官方) | Open Tag(开源复刻) |
|---|---|---|
Brain | Anthropic 托管的模型服务 | CLI agent backend: |
Memory | Anthropic 端托管 | MFS 索引的、运营者授权的上下文 |
Tools | Anthropic 平台工具 | MFS Connector 暴露的外部检索 + 工作区工具 |
命名上 Open Tag 也刻意保持一致:官方 tag 响应 @Claude,Open Tag 响应 @OpenClaude(Claude 后端)或 @OpenCodex(Codex 后端),读起来风格统一。
Slack bridge 薄得出乎意料
读完源码我第一印象是:Slack 桥接那层(slack_socket_agent.py)薄得有点出乎意料,它只做五件事:
- 通过 Socket Mode 接收
app_mention事件 - 通过 Slack Web API 读取当前线程(
conversations.replies,limit=30) - 发一条临时的 working 回复占位
- 调用
scripts/opentag_agent.py,传入选定的 backend - 用 agent 的答案替换那条临时回复
bridge 自己不回答任何问题。它只把线程内容、channel id 和允许的 MFS scope 打包好,丢给一个全新的 CLI agent 进程。所有的智能都在那个 backend agent 里,bridge 就是个传话的。
每次 mention 都是一个全新 agent
这里有个运行时的关键事实:每次有人 @ 它,就起一个全新的 agent 进程(opentag_agent.py)。
claude后端的调用方式:claude -p --dangerously-skip-permissions --add-dir <workdir> --add-dir <skill-dir> --add-dir <memory-root>,prompt 走 stdin。codex后端的调用方式:codex exec --dangerously-bypass-approvals-and-sandbox ... --output-last-message <tmp>,并且内置了重试逻辑(OPENTAG_BACKEND_ATTEMPTS,默认 3 次),用来应对容量和限流问题。
因为 backend 本身不提供会话连续性,每次 mention 都是一次 fresh run——没有跨对话的状态残留。听着有点浪费,但好处也实在:状态干净、好调试,也避开了长会话的上下文污染。
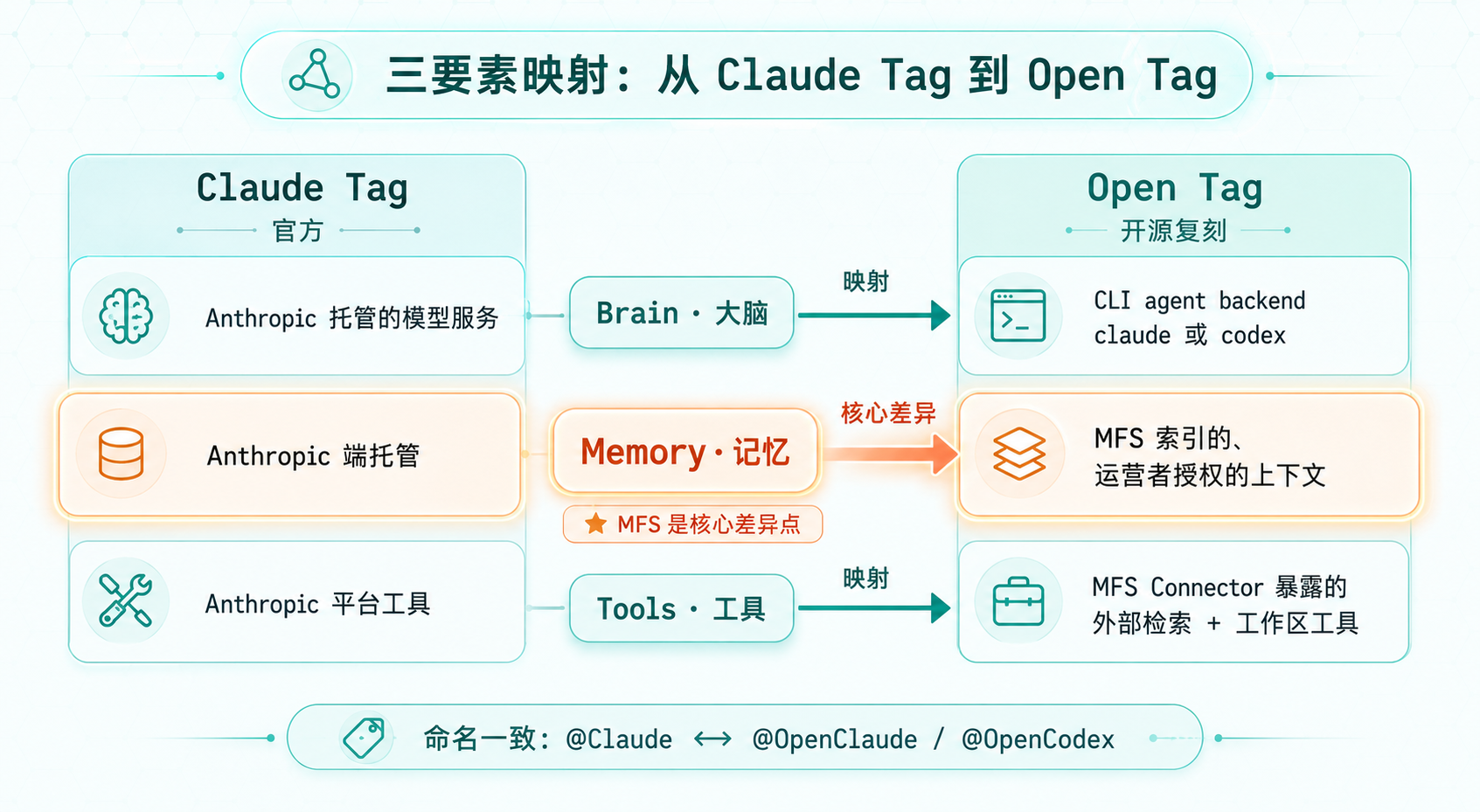
三要素映射对比图
图 4:Open Tag 把 Claude Tag 三要素映射到开源组件,Memory 行高亮——MFS 是核心差异点
记忆边界:MFS_ALLOWED_SCOPES
Open Tag 怎么管 Agent 能看到什么?答案是一个叫 MFS_ALLOWED_SCOPES 的环境变量。
mfs_search.py 和 mfs_cat.py 这两个 helper 脚本,在调用 MFS 的 HTTP /v1/search 之前,会先做一次 is_scope_allowed() 检查。如果某个 scope 超出运营者允许的范围,直接拒绝,退出码是 2。
换句话说,运营者在启动 Open Tag 之前,要显式列出 Agent 允许访问的 source 根。记忆边界就是这么强制的——不靠 Agent 自觉,靠 helper 脚本在调用前拦一刀。
5. 诚实说边界:它不是生产安全防线
这部分必须如实说,也是 Open Tag 在 README 和 SKILL 里反复强调的。Open Tag 的官方定位原文是这样的:
This is a demo/reference implementation, not a production security boundary. It has no hardened sandbox, multi-user policy engine, audit system, or approval flow.
翻译过来:这是一个 demo / 参考实现,不是生产安全边界。它没有加固的沙箱、没有多用户策略引擎、没有审计系统、也没有审批流程。
作为 milvus 社区的布道者,我反而觉得这种诚实很加分。Open Tag 故意跳过了托管 tag bot 提供的那一整套东西——零运维、企业治理(审批/审计/消费限额)、环境主动模式(ambient proactive mode)、组织级身份模型。这些它都不碰。
它真正的优势在 Memory 的广度
那 Open Tag 图什么?它的优势在记忆这一层的广度。
MFS 提供 20 多个 connector,覆盖范围相当宽:原始数据层有 Postgres、MongoDB、BigQuery、S3;任务跟踪有 GitHub、Jira、Linear;聊天和协作有 Slack、Discord、Gmail、飞书;文档有 Notion、Web 爬取;文件有本地和各家对象存储。而且全部自托管,数据和凭据不离开你的机器。
对比一下:Claude Tag 的 Brain 和 Tools 都很强,但 Memory 这一层的广度和可控性,恰恰是开源方案能补上的地方。Open Tag 把赌注压在 Memory 上,是个有意思的取舍。
至于那些被跳过的治理能力,恰恰是社区可以参与改进的方向——开源项目本来就是这么长大的。
6. 凭据管理与设计取舍
下面聊几个 MFS 在安全和工程上的取舍,这些细节挺能看出项目的工程审美。
凭据只存引用,不存明文
这是 MFS 一个明确的安全设计。每个 connector 的 TOML 配置绝不放明文密钥,只放引用:
# 只写引用,真值不落盘到配置里
token = "env:SLACK_BOT_TOKEN"
password = "file:/run/secrets/db_password"真正的 token、密码、凭据文件,都保存在服务器端(进程环境变量或挂载文件)。CLI 和 Agent 永远碰不到原始凭据。这么做的直接好处是:配置文件能直接提交到代码仓库、能分享,密钥不会跟着泄露。
既是 Agent 的工具,也是 Agent 应用的地基
MFS 不只是给 Agent 用的检索工具,它还能作为 Agent 应用的检索和上下文基座:
- SDK(Python / TypeScript)可以直接从你的应用代码里调用
- CLI 可以用来搭自己的 Skill、MCP server 或插件
- 索引管线、chunking、embedding、向量库、缓存、connector 目录,这些脏活累活全由 MFS 包了,上层应用不必碰
这层抽象真正省事的地方在于:你不用从零搭一套向量检索加数据接入的管线,MFS 把这块标准化了。
总结
回到开头那个问题:上下文从哪来、怎么管。
MFS 给的答案是——把 20 多种数据源统一成一棵文件树,用同一套动词去检索,本地零 key 起步,改个配置到 Zilliz Cloud 就能上生产。它是 Open Tag 的记忆引擎,也是任何想认真管上下文的 Agent 应用可以站上去的地基。
Open Tag 则是这张地基上交出的一份答卷:它把 Claude Tag 的三要素(Brain / Memory / Tools)映射到开源组件,用一个极薄的 Slack bridge 和每次 mention 都重启的 fresh agent,复刻出了一套可以自己托管、自己掌控的 tag 工作流。它诚实地承认自己不是生产安全防线,但把 Memory 的广度和数据自主权交还给了用户。
如果你正在搭自己的 Agent 应用,或者想把 Claude Tag 那套工作流搬到自己的基础设施里,MFS 和 Open Tag 值得花一个下午翻一翻源码。从 Milvus Lite 起步,数据量上来再走向 Zilliz Cloud,这条路是通的。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号