从零搭建一个招投标数据监测看板-我开源了全国文旅行业IT采购监控系统

从零搭建一个招投标数据监测看板-我开源了全国文旅行业IT采购监控系统

瑭宋元
发布于 2026-06-29 12:15:13
发布于 2026-06-29 12:15:13
一、缘起:为什么做这个系统?
最近在做一个文旅数字化方向的项目,需要持续跟踪全国范围内文化、旅游、体育、宣传等领域的信息化采购动态。说白了就是——哪些省在搞智慧旅游平台,哪些部委在招标融媒体系统,谁中标了,预算多少。
一开始是手动去中国政府采购网(ccgp.gov.cn)搜关键词,复制粘贴到 Excel 里。做了两天就崩溃了:信息散落在几十个页面里,格式五花八门,手动整理效率极低。
于是我想:为什么不写个程序自动搞定这件事呢?
说干就干。经过几周的迭代,从最初的一个爬虫脚本,慢慢演变成了一个完整的数据监测看板系统。现在它已经开源到了 GitHub,今天就把整个技术过程分享出来。
二、系统能做什么?六大模块一览
先上总览截图,感受一下最终效果:
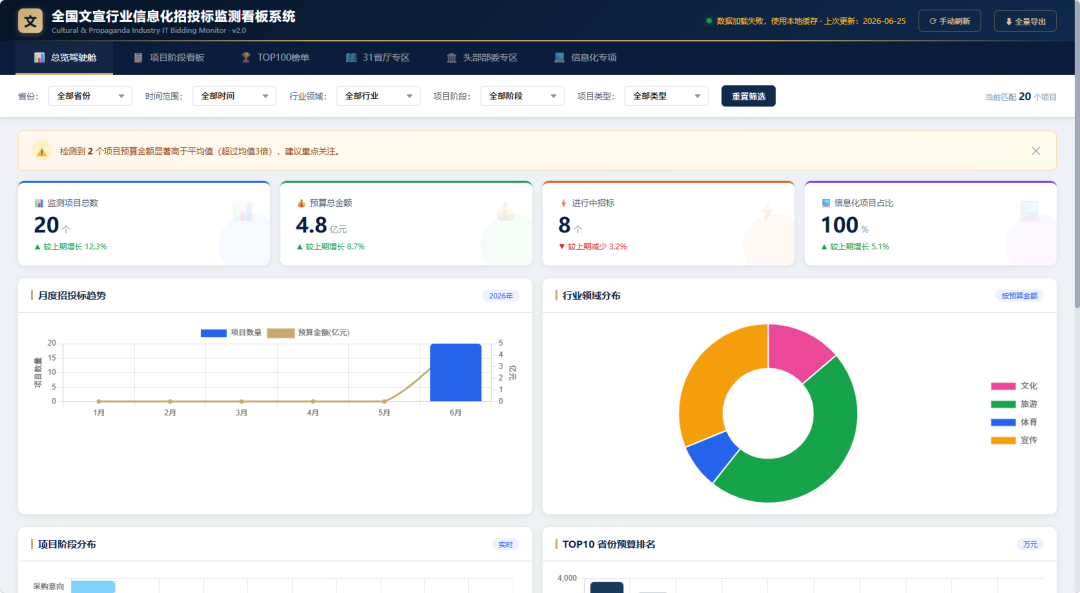
打开看板的第一眼,你看到的是四个关键指标卡片:
- 监控项目总数— 当前筛选条件下有多少个项目
- 预算总金额— 所有项目的预算汇总(亿元)
- 进行中招标— 当前还在招标阶段的项目数
- 信息化项目占比— IT 类项目占全部项目的比例
下方是月度招投标趋势图和行业领域分布饼图,一眼就能看出哪个月份采购最活跃、哪个行业投入最多。再往下还有项目阶段分布和省份 TOP 排名。
阶段看板:按采购流程分列
这是我觉得最有用的模块之一——把所有项目按照采购流程的四个阶段分栏展示:
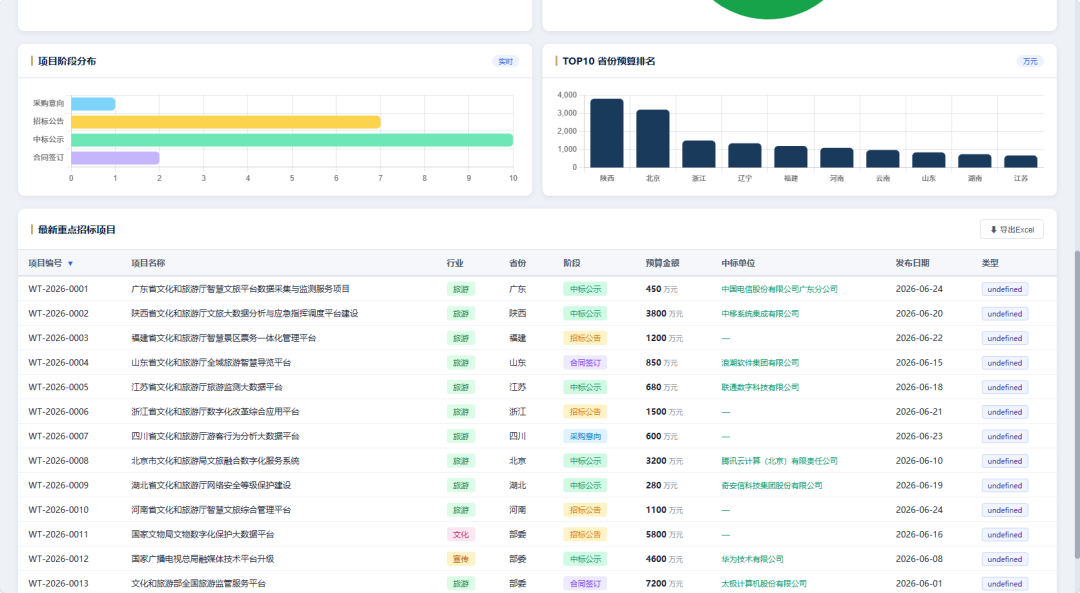
每个卡片显示项目名称、所属行业、预算金额、发布日期、采购单位。颜色编码区分不同状态,一目了然。对于做销售或 BD 的同学来说,这个视图可以直接用来判断哪些项目还来得及跟进。
TOP100 项目榜单
按预算金额排序的项目排行榜,大单子一目了然:
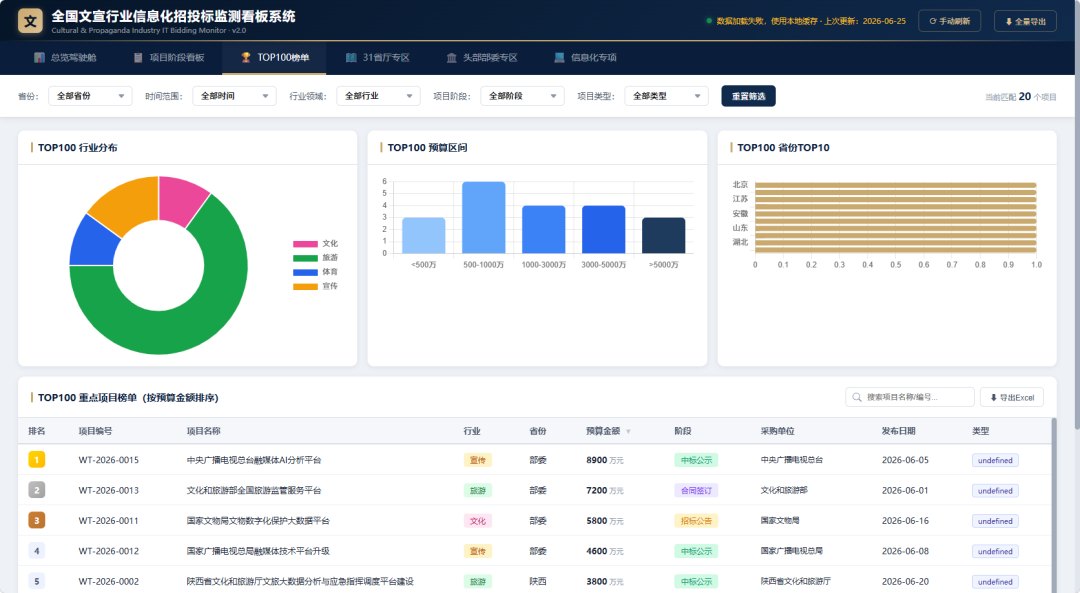
其他功能大家可以自己去github上下载开源项目体验,我就不赘述了。
三、技术架构:轻量但完整
整个系统的技术栈非常精简,没有后端服务器,纯静态部署即可运行:
HTML5 + CSS3 + Vanilla JSChart.js 图表渲染Python 3 数据采集SheetJS Excel导出GitHub 托管
核心设计理念是「数据与展示分离」:ccgp_data.json 是唯一的数据文件,包含 349 条结构化项目数据;dashboard.html 是纯前端应用,读取 JSON 文件渲染所有内容;Python 脚本负责数据的采集、清洗、合并,不参与前端展示。这样的好处是:更新数据不需要改任何前端代码,重新生成 JSON 即可。
其实就是基于workbuddy开发的,架构也是Agent规划,我只是确认下,不过改BUG真得改到死。
四、数据从哪来?政府采购网的采集方案(这块是核心)
数据源是中国政府采购网(ccgp.gov.cn),这是国内最权威的政府采购信息发布平台。我的采集策略分三步走:
第一步:多关键词覆盖搜索
单一关键词搜索覆盖面不够,我设计了 7 组关键词组合来最大化覆盖文宣领域的 IT 采购项目:
# | 关键词组合 | 覆盖领域 |
|---|---|---|
1 | 智慧文旅 | 智慧文旅综合项目 |
2 | 文化 + 数字化 | 文化数字化工程 |
3 | 体育 + 信息化 | 体育信息化建设 |
4 | 融媒体 + 平台 | 融媒体中心建设 |
5 | 智慧旅游 + 系统 | 智慧旅游管理系统 |
6 | 文物 + 数字化 | 文物保护数字化 |
7 | 广电 + 信息化 | 广电信息化项目 |
第二步:详情页精确抓取
搜索结果列表只显示标题和摘要。为了获取准确的预算金额和中标单位,需要对重点项目的详情页进行二次抓取。例如北京石刻艺术博物馆 100.8 万、天津市体育局 79.45 万、浙江省文旅厅 299 万、盐池县图书馆 99.33 万等。
第三步:数据合并与去重
多轮抓取必然产生重复数据。合并逻辑采用 URL 去重 + 阶段优先级策略:同一 URL 的项目只保留一条记录;如果同一项目出现在多个阶段,按「合同签订 > 中标公示 > 招标公告 > 采购意向」优先级保留。每次合并后自动重算统计数据(总金额、各月数量等)。
五、踩过的坑:三个让你头秃的 Bug
开发过程中遇到几个比较有意思的问题,分享出来供大家参考避坑。
Bug #1:「加载中」永远转圈
这是第一个正式报告给我的产品 BUG。首次打开看板时,页面一直显示「加载中...」,必须手动选择「部委」筛选项才会出现数据。排查过程像剥洋葱一样——第一轮发现是 JavaScript 语法错误(配置对象少写了三个闭合大括号),用 Node.js --check 验证语法后才定位到问题。修复完语法错误后用户反馈还是不行,第二轮深入排查才发现根本原因是数据初始化缺陷:allData = [] 加上异步加载数据,任何一个环节出错就会导致永久空数据状态。解决方案是预填充种子数据 + 双层 try/catch 兜底。
Bug #2:Chart.js CDN 竞争条件
看板依赖 Chart.js CDN 加载。在某些网络环境下,内联 script 执行时 Chart.js 还没下载完成,导致 Chart is not defined 错误。加了 typeof Chart !== 'undefined' 守卫和 window.addEventListener('load') 兜底才彻底解决。
Bug #3:Git Push SSL 握手失败
这个不是代码 Bug 而是环境问题——在本机环境下 git push 到 GitHub 一直 SSL 握手失败。试过关 SSL 验证、换 OpenSSL 后端都不行。最终用 Python requests 库直连 GitHub Contents API 推送文件才解决,顺便封装成了一个可复用的同步工具 github_sync.py。
六、为什么开源?如何使用?
开源的初衷
这个项目虽然起源于个人工作需求,但我相信它对很多人都有价值:
- 文旅/宣传/体育行业的从业者— 了解同行在投什么项目、花多少钱
- B端销售人员— 发现有价值的商机线索
- 前端开发者— 学习如何用原生 JS 构建复杂的单页数据看板
- 数据采集爱好者— 参考政府采购网的数据抓取方案
项目亮点
- 零依赖启动— 不需要 Node.js、不需要数据库、不需要后端服务
- 真实数据— 349 条来自中国政府采购网的真实采购项目数据
- 可扩展— 更换数据源只需替换 ccgp_data.json,前端代码完全通用
快速开始
项目文件说明
文件 | 说明 | 大小 |
|---|---|---|
dashboard.html | 看板主应用(SPA) | 90 KB |
ccgp_data.json | 项目数据文件 | 218 KB |
scripts/crawler_ccgp_safe.py | 安全频率爬虫 | — |
scripts/sync_ccgp_data.py | 数据同步合并脚本 | — |
scripts/github_sync.py | GitHub 同步工具 | — |
七、写在最后
从第一个爬虫脚本到现在的 v1.0.0 开源版本,这个过程让我深刻体会到:好的工具是从真实痛点中生长出来的。一开始只是想省掉每天手动查政府采购网的时间,做着做着就成了一个有六个可视化模块的完整系统。
技术栈上没什么花哨的东西——原生 JS + Chart.js + Python 爬虫,都是最基础的工具。但正是这种简单够用的组合,让整个系统可以在没有任何构建步骤的情况下直接运行。有时候,最好的架构就是不需要架构。
如果你觉得这个项目对你有帮助,欢迎 Star 和 Fork!也欢迎提交 Issue 和 PR——无论是新功能建议、Bug 修复,还是新的数据源接入,都热烈欢迎。
仓库地址https://github.com/songweilovelj-cyber/culture-procurement-monitor
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-26,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Agent 政企应用研习社 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号