从运维数据到本体与知识图谱:构建 AI 能理解、会推理、可行动的运维世界

从运维数据到本体与知识图谱:构建 AI 能理解、会推理、可行动的运维世界

Wangzy
发布于 2026-06-29 12:26:37
发布于 2026-06-29 12:26:37
从分散的运维数据到统一运维世界模型
从数据孤岛走向对象、关系、知识与受控行动统一的运维世界模型
前记
这一周,笔者一直在研究数据中台规划相关的内容。
调研了一圈之后,我逐渐意识到:数据中台的建设如果只停留在数据汇聚、存储和加工层面,最终解决的仍然只是“数据放在哪里、怎样查询”的问题。当它进一步走向统一对象、统一语义和业务认知时,就不可避免地会触及本体;而从本体出发,把真实对象、关系、状态、事件和经验组织起来,又自然会落到知识图谱。
此前我对本体和知识图谱的理解也不够深入,甚至习惯性地把本体简单理解成知识图谱的 Schema,把知识图谱理解成实体与关系的集合。这次调研中,我关注到了阿里云近期对 UModel 的持续实践。它不再把本体停留在概念或模型设计层面,而是尝试将实体、可观测数据、领域知识、存储位置和运维行动组织成一个能够真正运行的运维世界模型。
这给了我一个很重要的启发:运维智能化需要的并不只是一张更复杂的拓扑图,也不只是把更多数据交给大模型,而是先让系统建立一套关于“运维世界”的共同认知——这里有哪些对象,它们如何关联,现在处于什么状态,我们掌握了哪些知识,以及可以在怎样的权限和规则下采取行动。
也正是沿着这条线索,我重新梳理了运维数据、本体与知识图谱之间的关系,并形成了这篇文章。它既是本周调研过程的一次阶段性总结,也是我对运维数据如何从“可以查询”走向“可以理解、推理和行动”的一次重新认识。
一、为什么“数据都采上来”仍然不够
传统监控体系通常擅长回答“发生了什么”,却不一定能解释“为什么发生”。
日志、指标和链路提供的是系统运行的现象。只有把这些现象与服务、实例、主机、数据库、变更、告警、负责人等对象关联起来,系统才有可能理解故障发生的上下文。
现实中常见的障碍主要有四类:
- 数据孤岛:监控、日志、CMDB、工单、发布、安全等平台各自维护数据,缺少统一视图。
- 对象不统一:同一个服务在不同平台使用不同名称和标识,数据无法稳定关联。
- 语义不一致:“宕机”“down”“不可用”可能表达同一种状态,不同系统的严重级别也可能完全不同。
- 经验未结构化:根因、排查步骤和处置方法大量存在于自然语言中,难以被程序和大模型可靠调用。
因此,运维数据中台不应只是“再建一个大数据平台”,而应成为面向稳定性、效率和智能化决策的统一数据与知识底座。
二、数据治理:把原始信号变成可识别的运维对象
知识图谱不能直接吞下原始日志、CMDB 快照和告警流水。数据入图之前,至少要完成四个动作:
- 清洗:剔除脏数据,补齐必要字段,统一时间格式。
- 归一:统一标签、状态、严重级别和字段口径。
- 关联:通过
trace_id、span_id、change_id、ci_id、service_id等标识,把分散数据对齐到同一个运维对象。 - 收敛:合并重复告警,抽取日志或告警模板,避免同一事件在图中无限膨胀。
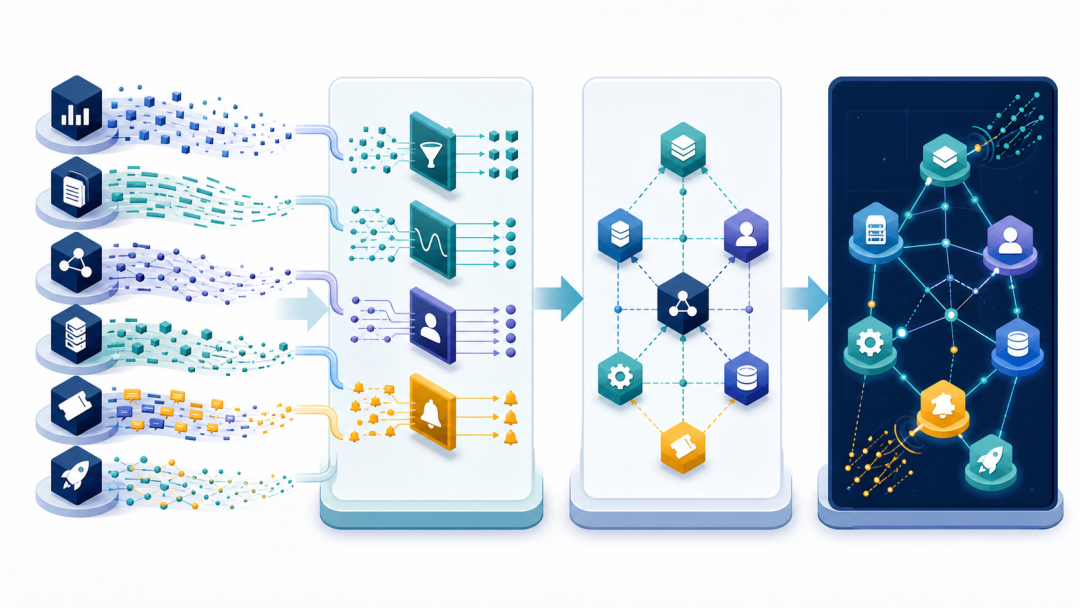
运维数据处理、本体建模与知识图谱的全链路
多源信号经过清洗、归一和对象对齐,在统一语义约束下形成持续更新的关系网络
其中,统一对象 ID 是整条链路的关键。如果日志中的“trade-service”、CMDB 中的“交易服务”和发布平台中的“某应用”无法被识别为同一个对象,再复杂的图算法也只能在几座互不连通的数据孤岛上打转。
流处理与批处理各管什么
运维数据既有持续到来的实时信号,也有需要周期校准的全量数据,因此通常需要流、批两条处理链路。
流处理负责“让图谱活在当下”。 Kafka、Flink 等组件可以处理实时告警、日志、链路、变更和实例上下线事件,完成清洗、归一、关联和收敛后,驱动图谱秒级或分钟级增量更新。
批处理负责“让图谱底子扎实”。 CMDB 全量同步、历史因果发现、复盘文档抽取、孤儿节点检查和拓扑校准,更适合按小时或按天执行。它既用于初始化图谱,也用于持续纠正实时链路可能产生的漂移。
两条链路最容易踩的坑,是口径不一致。实时计算与离线重算必须共享同一套对象定义、字段语义和质量规则,否则同一个指标会出现两套答案。
三类数据,三种处理策略
在运维场景中,可以遵循“结构化优先、半结构化补充、非结构化增强”的顺序:
- 结构化数据建骨架:CMDB、Kubernetes API、主机清单、发布记录和 APM 拓扑可直接映射为服务、实例、主机、数据库以及它们之间的关系。这部分可信度最高,应优先建设。
- 半结构化数据叠事件:告警 JSON、工单表单等需要解析和归一,再挂载到已有实体上,用来描述“发生了什么”。
- 非结构化数据补知识:故障复盘、值班记录和 Runbook 中包含根因、证据、处置动作和专家经验,可借助规则、信息抽取或大模型转成实体与关系,但重要结论应经过人工审核后再进入生产图谱。
这个建设顺序很重要:骨架越完整,后续从文本中抽取出的告警、根因和处置经验,才越容易准确地挂到真实对象上。
三、运维本体:定义这个世界的统一语义与行动边界
数据处理解决的是“干不干净、能不能关联”,本体解决的是“大家说的是不是同一件事”。
在传统知识图谱工程中,本体常被简化为图谱的模式层:预先定义对象类型、属性、关系和约束。这种理解适合解释 Schema,但不足以覆盖面向企业运营的“运维本体”。
完整的运维本体不仅规定“能有什么”,还要把真实对象的当前状态、可调用的分析方法、受控动作、权限和审计规则统一组织起来。它不是夹在数据层和应用层之间的一张静态图纸,而是贯穿数据、工具、智能体和业务场景的语义骨架。
其中的模式定义通常包括:
- 运维世界中有哪些类型的对象,例如系统、服务、实例、主机、Pod、数据库、告警、变更、工单和 Runbook;
- 每类对象有哪些属性和唯一标识;
- 对象之间允许建立哪些关系,例如“服务依赖服务”“实例运行在主机”“告警指向数据库”“变更影响服务”;
- 字段、枚举值和关系两端需要满足哪些约束。
Schema 可以比喻为“图纸”,真实对象和关系则是依照图纸持续维护的“建筑”;但运维本体还包括这座建筑的运行规则、允许执行的动作以及安全边界。如果缺少这层语义骨架,项目很容易退化成临时拼接的拓扑图:名称不统一、关系含义模糊、动作没有边界,也难以被其他系统和大模型稳定使用。
从“收集数据”转向“建模世界”
阿里云 UModel 提出了一条值得借鉴的路线:不要只从海量数据中逆向猜测系统状态,而应先对真实的 IT 世界建模,再有针对性地获取和组织数据。
UModel 使用 Set 描述实体、可观测数据、存储和 Runbook,使用 Link 描述实体之间、实体与数据之间、模型与存储之间以及实体与操作手册之间的关联。这样,一个服务不再只是 CMDB 中的一条记录,而是一个拥有依赖关系、日志、指标、链路、存储位置、分析方法和处置动作的完整对象。
它进一步把运维语义组织为三个层次:
- 数据层:描述“有什么”和“如何连接”,包括实体、观测数据及其关联关系。
- 知识层:把黄金指标、健康度、告警规则、分析模板和领域经验附着到对象上,填平数据与认知之间的语义鸿沟。
- 行动层:定义重启、回滚、扩容、降级和预案执行等可操作能力,让分析结论能够走向执行闭环。

运维本体的数据、知识与行动语义
运维本体不是独立的一层:它用统一语义连接底层数据、中间知识和上层受控行动
UModel 还通过 StorageLink 解耦逻辑模型与物理存储:同一类数据可以被统一建模,但底层仍由最适合它的系统保存。这种思路尤其适合异构技术栈长期共存、底层组件需要持续替换的企业环境。
因此,本体建设的目标不是画出一张更复杂的拓扑图,而是构建一个能理解、会推理、可行动的运维世界模型。
四、知识图谱:运维本体的重要运行载体
知识图谱负责高效组织和计算真实对象之间的连接,是运维本体的重要运行载体之一。两者不是简单的前后工序关系:本体提供统一语义、约束与动作边界,图谱则承载对象实例、动态关系、事件传播和推理路径。
例如,本体中预先定义了 Service、Database、Alarm、Change 和 Runbook 等类型,以及 depends_on、points_to、affects、caused_by 等关系。真实数据进入后,图中才会出现“交易网关依赖订单库”“某次发布影响交易网关”“P1 告警指向订单库”等具体事实。
图谱的内容可以分为三层:
- 实体与拓扑骨架:服务、实例、主机、Pod、数据库等实体,以及部署、归属、调用和依赖关系。
- 动态事件层:告警、变更、工单、异常和状态变化,持续挂载到相关实体上。
- 经验知识层:根因、因果链、证据、处置动作和 Runbook,在复盘和实际使用中不断补充。
图谱也不是“一次建成”。新告警、新变更、Pod 重调度等事件会触发实时增量更新;CMDB 全量快照、因果权重重算和图谱质量检查则负责周期性校准。所有写入都应通过统一质量门禁,包括唯一标识、必填字段、枚举值域、关系两端类型、数据新鲜度和幂等性检查。
图谱不是明细数据仓库
这里有一个常见误区:既然要建设知识图谱,是不是要把所有日志、指标和链路明细都存入图数据库?
答案是否定的。
图数据库擅长的是关系遍历和路径推理,而不是保存每秒产生的海量时序点或日志正文。更合理的做法是:
- 指标明细继续留在时序数据库;
- 日志和 Trace 明细留在检索或列式存储中;
- CMDB、工单等完整记录留在原有主数据或事务系统中;
- 图谱只保存关键实体、关系、少量核心属性,以及指向原始数据的存储链接或查询指针。
可以把图谱理解为图书馆的“索引卡片柜”:它记录有哪些书、书与书之间有什么关系、每本书放在哪里;真正的海量内容仍然留在各自最合适的书库中。
这也形成了智能运维中非常实用的两步查询方式:
先在图上找线索,再回原库取证据。
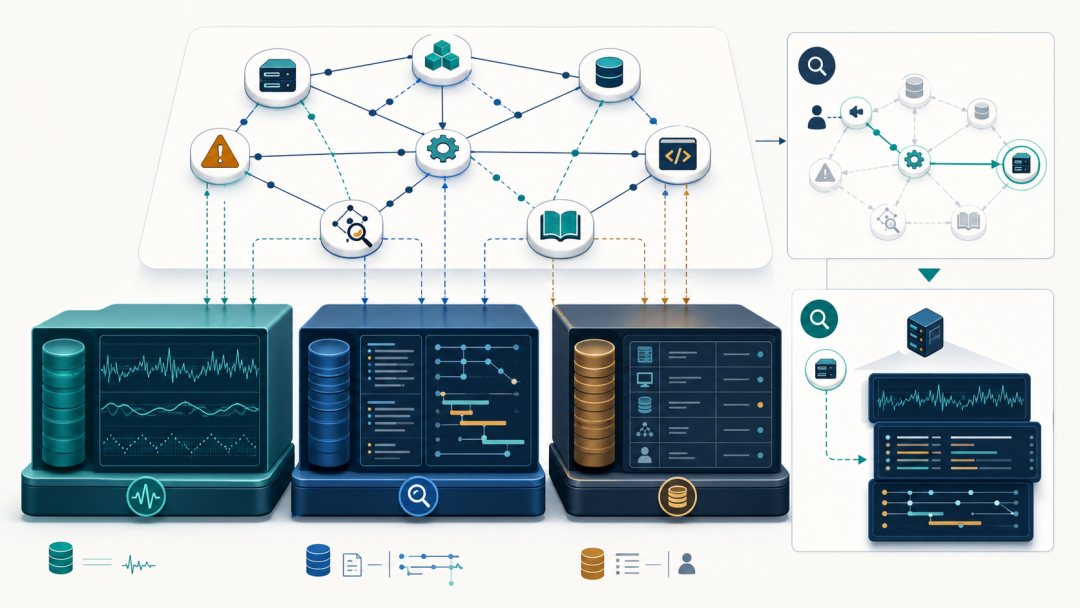
知识图谱与原始明细存储的协同边界
图谱保存对象、关系与查询指针;指标、日志、链路和主数据明细仍留在适合它们的专业存储中
五、一条告警如何完成从数据到知识的旅程
假设交易系统突然出现大量超时告警。
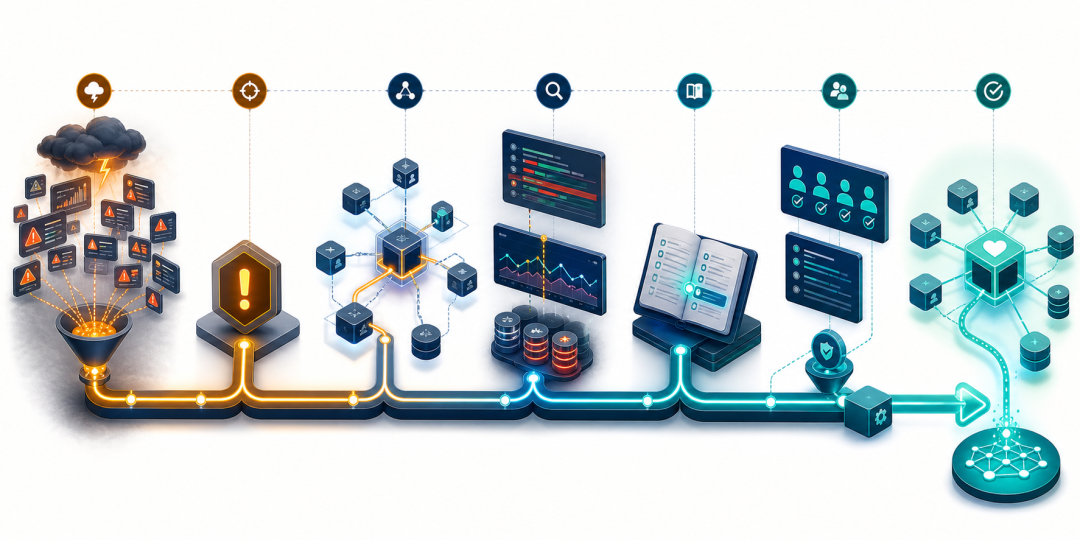
一条告警从发现到根因定位和受控处置的闭环
告警收敛、对象关联、证据验证、Runbook 推荐、审批执行与经验回流构成完整闭环
第一步,实时链路接收告警,将严重级别统一为 P1,并通过服务标识把告警关联到“交易网关”。重复告警经过模板归并后,只保留一个可持续更新的事件对象。
第二步,知识图谱沿依赖关系发现“交易网关”调用“订单数据库”,并检索到数据库连接池指标同步异常。系统还发现,十分钟前刚有一次相关服务发布。
第三步,图谱沿“变更影响服务—服务依赖数据库—告警指向数据库”的路径,给出疑似故障传播链。随后依据存储指针回到指标库查看连接池曲线、到日志库提取错误日志,完成证据验证。
第四步,系统从历史复盘中找到相似事件及其 Runbook,向值班人员建议“回滚版本并恢复连接池配置”。处置完成后,本次事件的真实根因、有效动作和恢复结果又被沉淀回图谱。
至此,运维系统才完成了从“发现一个异常信号”到“理解上下文、定位根因、给出行动并积累经验”的闭环。
六、知识图谱最终要服务哪些场景
知识图谱不是为了“有一张图”,而是为了缩短从信号到决策的距离。
最适合优先验证的场景包括:
- 告警收敛:把告警挂载到软硬件实体上,结合拓扑与因果关系区分根告警和衍生告警。
- 根因定位:沿依赖、变更和因果边搜索候选路径,再回原库验证日志、指标和链路证据。
- 变更影响分析:在变更前沿服务依赖关系计算潜在影响范围,辅助风险评估。
- 故障传播分析:结合拓扑、时间窗口和因果权重判断异常可能的传播方向。
- 智能问答与处置建议:通过图谱为大模型补充对象、关系、历史事件和 Runbook 上下文,减少“只看一段日志就下结论”的风险。
未来,图谱还可以通过 MCP、API、GraphRAG 等方式成为智能体的上下文与工具入口。但前提始终没有变化:数据可信、对象统一、语义清楚、关系可追溯、动作有权限边界。
七、落地从最短价值闭环开始
运维本体很容易越建越大。更稳妥的方式不是一次性覆盖所有 IT 对象,而是围绕一个可量化场景构建最短闭环。
例如,以一个企业的核心系统的根因定位为先锋场景,先建模:
服务 → 实例 → 主机/Pod → 数据库/中间件 → 告警 → 变更 → 根因 → Runbook
随后分三步演进:
- 先建立最小语义闭环:围绕先锋场景定义核心对象、关系和统一 ID,同时接入日志、指标、链路、事件与 CMDB,而不是先汇聚所有数据再补模型。
- 再扩展知识与图谱能力:补充状态、规则、历史经验和 Runbook,优先落地告警收敛、RCA 或变更影响分析。
- 最后自动化、自愈:在充分验证的场景中接入大模型与智能体,将建议逐步升级为受控执行。
衡量项目是否有效,也不能只看“接入了多少数据、建了多少节点”。更有意义的指标是:对象匹配率是否提升,关键链路是否完整,图谱更新是否及时,告警量是否有效下降,MTTD/MTTR 是否缩短,变更成功率是否提高,以及处置过程是否可审计、可复盘。
结语
运维智能化真正缺少的,往往不是一个更大的模型,而是一个足够清晰的世界。
数据处理让原始信号变得干净、统一、可关联;本体让人、系统与大模型使用同一种运维语言,并明确对象能够执行哪些受控动作;知识图谱则为对象、事件、关系和证据提供高效的连接、查询与推理能力。
当这三层能力形成闭环,运维平台才会从“展示数据”走向“理解系统”,再从“辅助判断”走向“受控行动”。这条路不必从一张包罗万象的大图开始,它可以从一个服务、一类告警和一次真实故障出发——先跑通最短闭环,再让每一次处置都成为下一次更快恢复的知识。
参考资料
- 阿里云开发者社区:《UModel 数据治理:运维世界模型构建实践》
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号