GPT-5.6 发布了,比神话(Claude Mythos)还强三个点,但你用不上

GPT-5.6 发布了,比神话(Claude Mythos)还强三个点,但你用不上

用户11563501
发布于 2026-06-29 12:27:45
发布于 2026-06-29 12:27:45
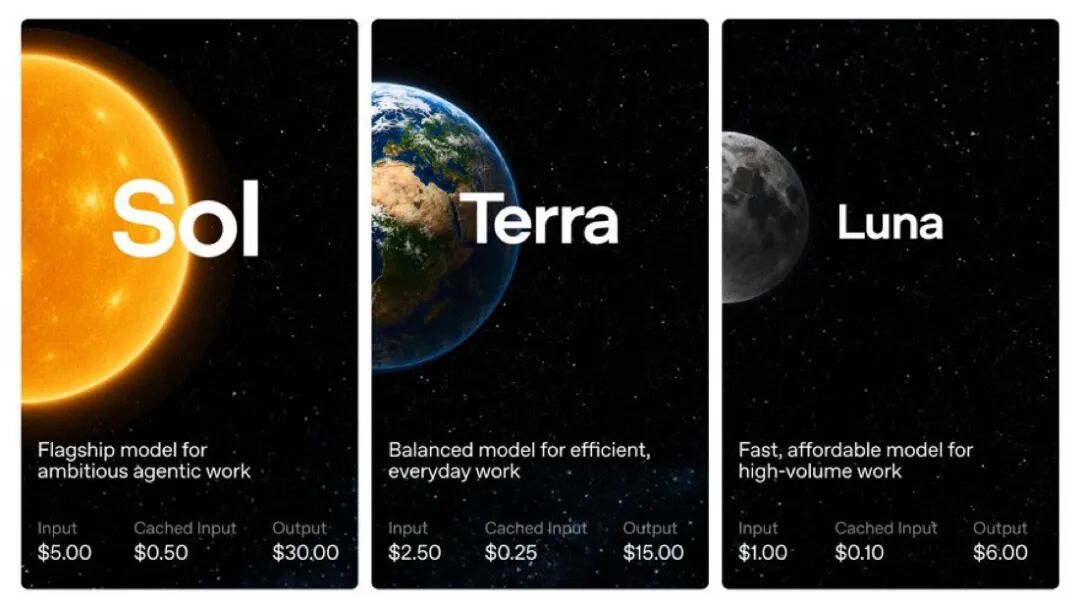
OpenAI 今天发布 GPT-5.6 系列,三个型号:Sol、Terra、Luna。
Sol 是旗舰。OpenAI 称其为"step function"级别的提升——不是渐进式改进,是跳跃。新增 max 模式和 ultra 模式:max 模式让模型花更长时间深度推理;ultra 模式由模型自行拆解任务,分配给一组子 agent 并行处理,最后汇总结果。
Terra 性能接近 GPT-5.5,价格砍半。Luna 主打低成本高吞吐。
API 定价:
模型 | 输入(每百万 token) | 输出(每百万 token) | 缓存输入 |
|---|---|---|---|
Sol | $5.00 | $30.00 | $0.50 |
Terra | $2.50 | $15.00 | $0.25 |
Luna | $1.00 | $6.00 | $0.10 |
7 月将上线 Cerebras 硬件加速版本,推理速度 750 token/秒。
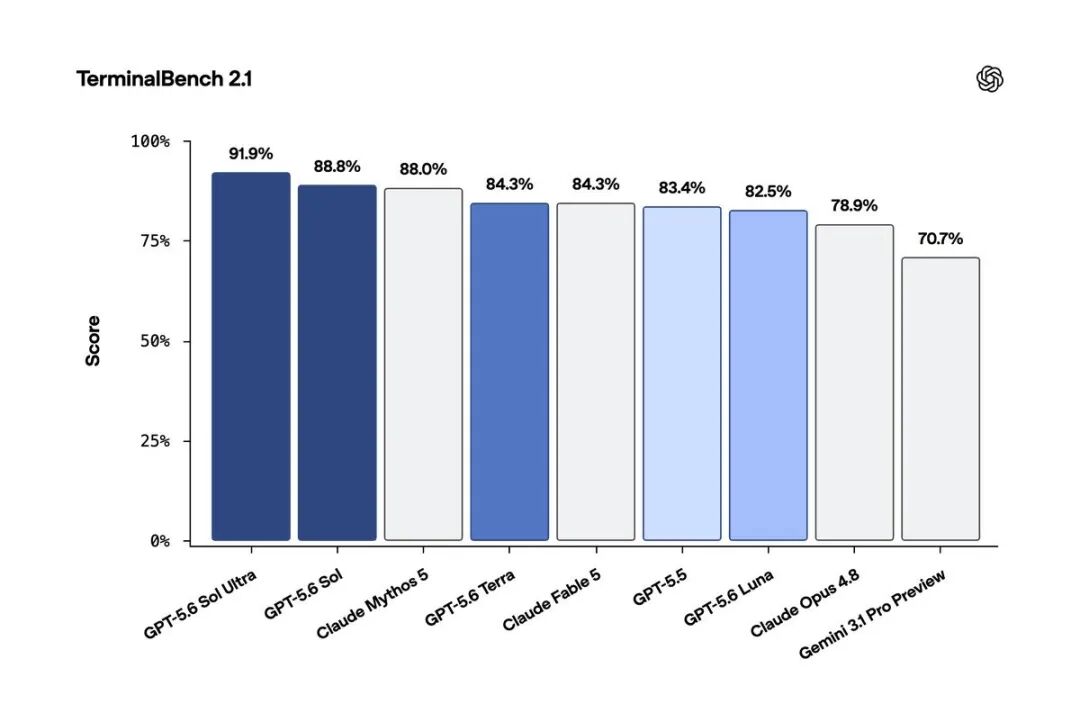
Terminal-Bench 2.1 测试结果——该基准评估模型在命令行环境下的规划、迭代和工具协调能力:
- GPT-5.6 Sol Ultra: 91.9%
- GPT-5.6 Sol: 88.8%
- Claude Mythos 5: 88.0%
- GPT-5.6 Terra: 84.3%
- Claude Fable 5: 84.3%
- GPT-5.5: 83.4%
- GPT-5.6 Luna: 82.5%
- Claude Opus 4.8: 78.9%
- Gemini 3.1 Pro Preview: 70.7%
Sol Ultra 领先 Claude Mythos 5 约 4 个百分点。Terra 与 Claude Fable 5 持平,价格更低。
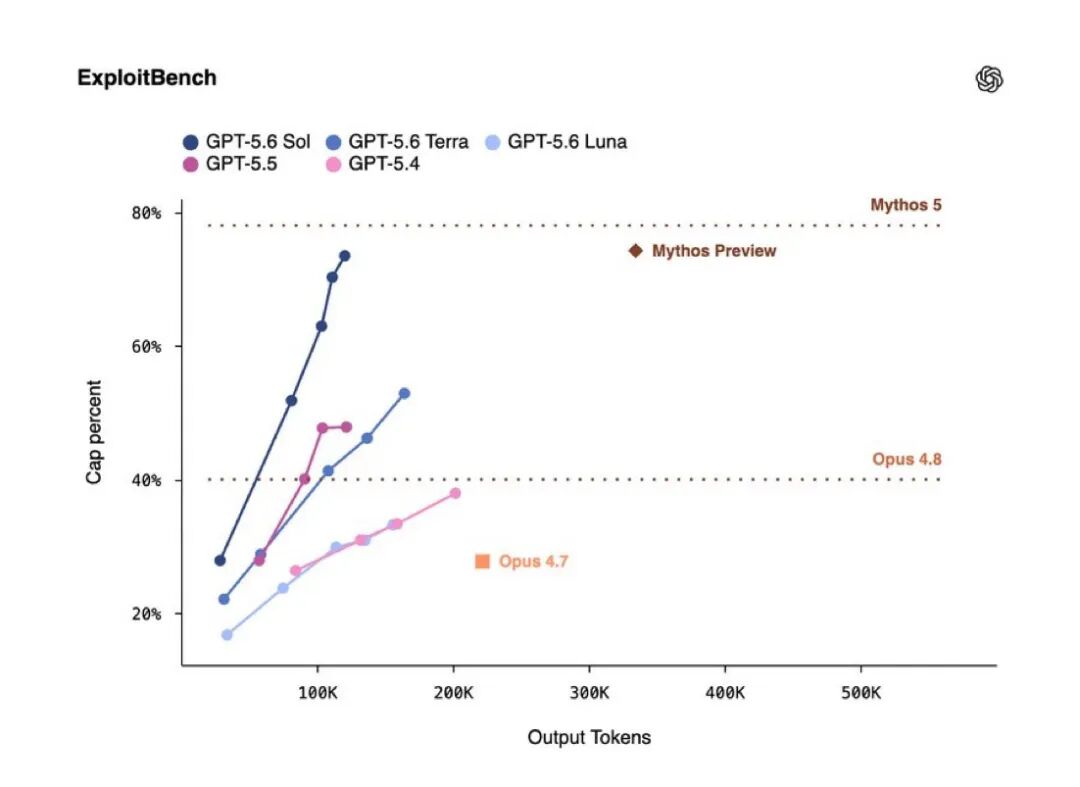
网络安全方面,ExploitBench 测试结果显示:Sol 用约三分之一的 token 消耗达到 Claude Mythos Preview 的同等水平。OpenAI 将 Sol 的网络安全能力定级为"高",未达到"关键"等级。模型能够发现浏览器漏洞和利用原语,但在测试条件下无法自主完成完整攻击链。
安全方面,OpenAI 投入超过 70 万 A100 等效 GPU 小时进行自动化红队测试,专门寻找可跨场景通用的越狱攻击。模型内置实时拒绝机制,生成过程中检测网络安全和生物领域的滥用行为。可疑输出会被暂停,交由更大的推理模型复审。
GPT-5.6 目前仅向约 20 家经美国政府审批的合作伙伴开放。普通开发者和 ChatGPT 用户暂不可用。
这不是事后监管或合规审查,而是发布前就限定了分发范围。
有评论写道:"想象一下未来 AI 公司的 PR 合并请求,得华盛顿批准才能合并。"
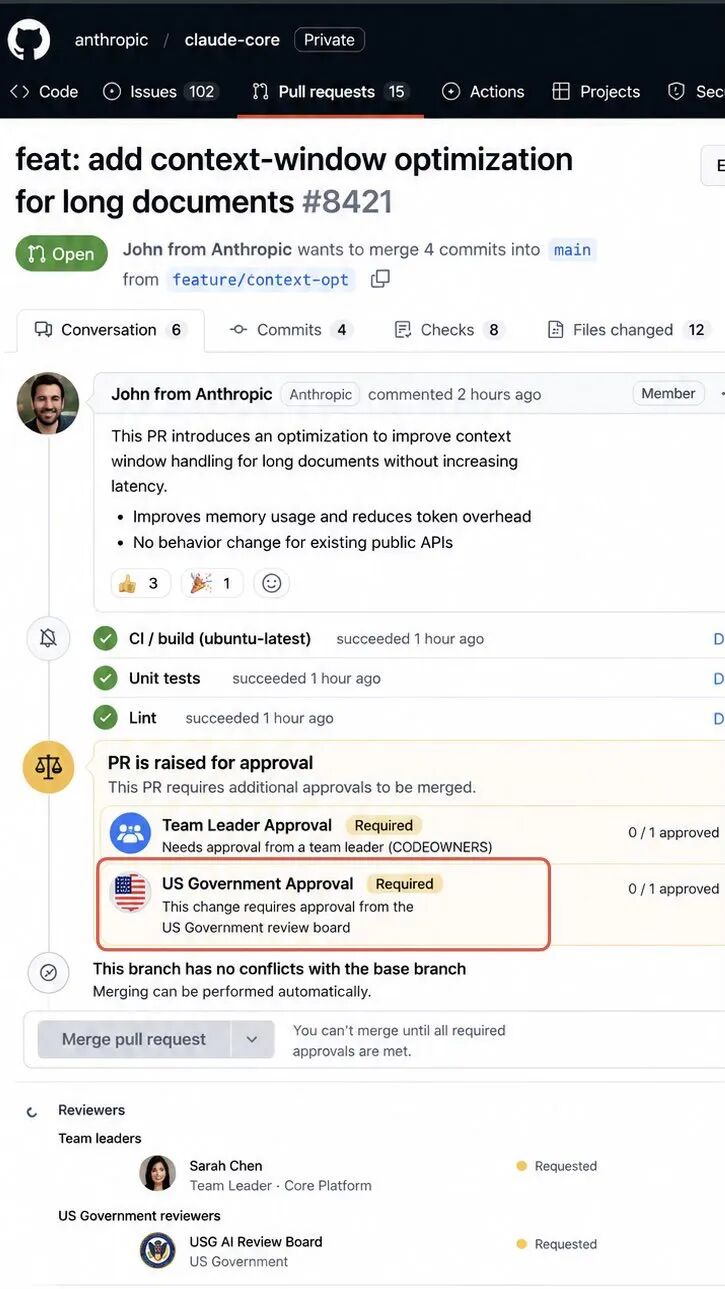
也有用户直接质疑:"你们根本不相信广泛访问。你们被 Claude 打得抬不起头,然后让政府来救场。"
对 API 用户而言,Terra 是短期内最实际的选项:性能接近 GPT-5.5,价格为其一半。Luna 适合对成本敏感的高吞吐场景。
Sol 的 ultra 模式如果稳定运行,开发者无需自行搭建 agent 编排框架即可处理复杂多步骤任务。这与 Anthropic 在 Claude 上的 agent 能力、Cursor 在 IDE 中的 background agent 方向一致——都在实现"AI 管理 AI"。
OpenAI 表示几周内会扩大开放范围。据 Axios 报道,下周将增加更多客户。ChatGPT 用户的使用时间尚未明确。
前沿 AI 能力的分配权,正在从公司转移到政府。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号