一道LLM推理部署面试题:KV缓存淘汰90% token,显存为什么没降?

一道LLM推理部署面试题:KV缓存淘汰90% token,显存为什么没降?

用户11563501
发布于 2026-06-29 12:28:00
发布于 2026-06-29 12:28:00
这是一道LLM推理部署面试题,答对的人不多。
用vLLM部署推理模型,长序列推理时频繁爆显存。于是给服务加了KV缓存压缩策略,淘汰90%的非重要缓存token,重启后显存占用几乎没变,还是会在相近的序列长度下OOM。
为什么?
先理清楚基础背景。
KV缓存是推理场景下GPU显存的第一消耗项。模型每生成一个token,都会在每一层追加对应的键、值向量,整个生成过程中这些数据不会释放,序列越长占的显存越多。
举个具体的例子:4bit量化的Qwen3-32B模型跑32K长度的思维链推理,24GB显存的GPU,通常跑到24K token左右就会爆显存。
有网友做了个很形象的类比:预填充阶段相当于读完整场会议的纪要,解码阶段才是真正发言。难怪大家总觉得首token慢——模型跟大部分人开会一样,90%的时间都在补上下文。KV缓存之所以关键,正是因为它是"不起眼的突破性技术":模型本身没有任何变化,就能换来更快的首token速度、更低的推理成本。有从业者直言,现在LLM的瓶颈早就不是算力,而是内存,这种权衡在各个技术栈里都能见到。
如果你对KV缓存的工作机制还比较模糊,有开发者做了GPT-2的2D和3D可视化工具(llm-visualized.com,需在设置中开启KV缓存模式),可以直观看到每层缓存如何存储、注意力分数如何在不同token间分布。
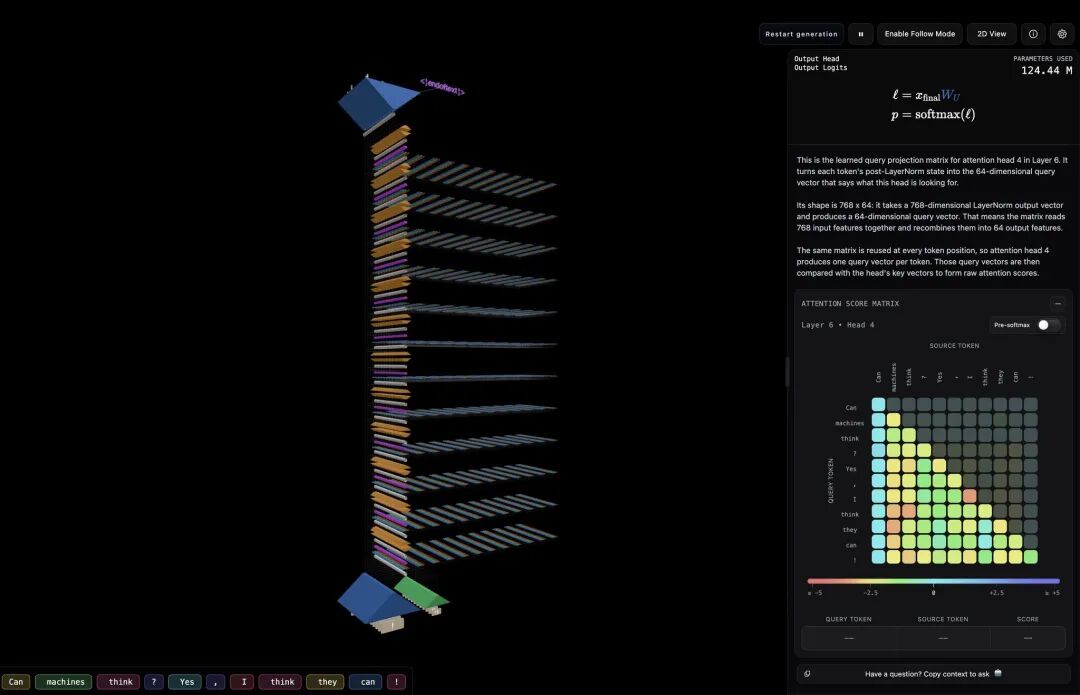
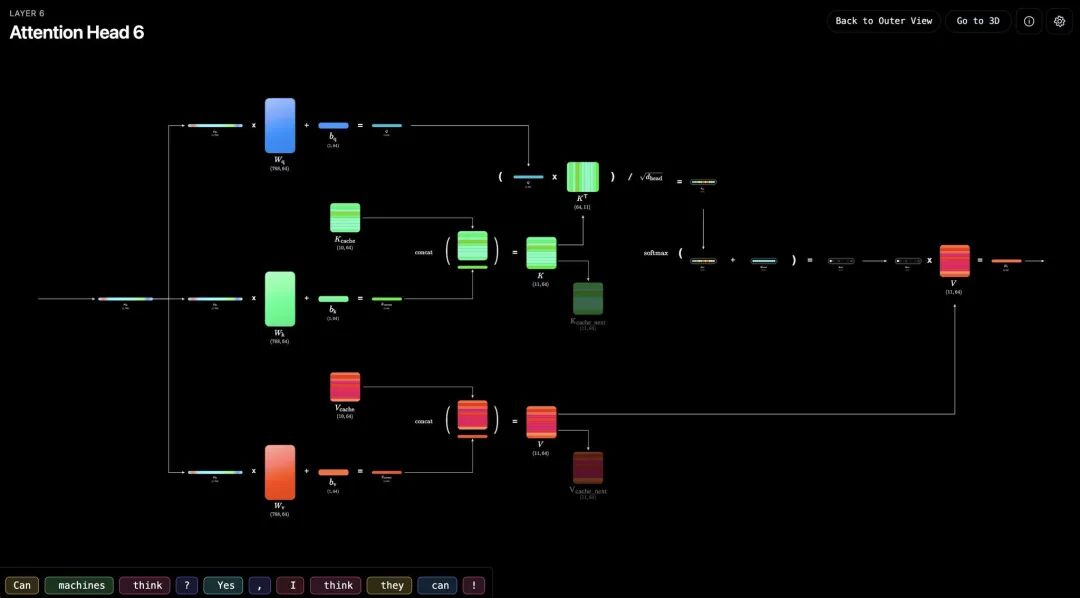
回到那道面试题。很多人的第一反应是删不重要的token,毕竟注意力机制本身是稀疏的,大部分历史token对当前生成的影响可以忽略,理论上只要留下核心token就能保证效果。但这个方法在真实生产环境里,解决不了显存问题。原因有两个。
第一个坑:分页内存的块机制。
目前vLLM和绝大多数生产级推理服务用的内存管理机制是Paged Attention,它会把GPU显存拆成固定大小的物理块,每个块大概能存16个token的KV数据。只有当一个块内的所有槽位都空了,这个块才会被还给内存分配器,供其他请求使用。
而KV缓存淘汰策略是按照重要性选token留的,剩下的重要token通常散落在各个物理块里。比如总共16K token,淘汰了14K,分布在1000个物理块里,最终大概率每个块都还剩1-2个存活token。没有一个块完全清空,自然没有显存被释放。逻辑上少了90%的缓存,物理占用纹丝不动。
就算想把新生成的token塞进各个块里的空槽位,也会带来新的开销。原本KV缓存是严格按token生成顺序存储的,要是把第16001个token塞到原来第40个token的位置,缓存的顺序就乱了。注意力计算还能出正确结果,但每个槽位都要额外记录自己对应的真实token位置,多出来的簿记开销,原本顺序存储的结构是完全没有的。
第二个坑:快速内核的天生缺陷。
KV缓存淘汰要判断哪些token重要,通常依赖注意力分数。但生产环境普遍用的FlashAttention等快速注意力内核,根本不会存完整的注意力分数矩阵。它分块计算注意力,算完就把完整的分数矩阵扔掉,这也是它速度快的核心原因。
要拿到完整的注意力分数做淘汰,只能切回eager注意力模式,等于完全放弃了FlashAttention的速度优势。
目前的落地方案。
英伟达最近公开的TriAttention方法同时解决了这两个问题。
首先,它完全不需要注意力分数。它在RoPE位置编码应用之前,根据键、查询向量的几何聚类特征给token打分,不需要构建完整的注意力矩阵。
其次,针对显存释放的问题,它每解码128个token就做一次压缩整理:把存活的token向前移动,填满空出来的槽位,把零散的空位凑成完整的空块还给分配器,同时全程保持缓存的token顺序。
实测数据显示,在长推理序列场景下,这个方法和全注意力的精度一致,解码速度快2.5倍,KV缓存的显存占用减少10.7倍。
最后提一个行业共识:KV缓存压缩能不能落地,核心指标是最终释放了多少个完整的物理块,不是淘汰了多少个token。很多相关研究的测试结果和生产环境表现差异极大,就是因为测试是在预分配的连续张量上做的,不是真实部署用的分页内存环境。这也是支撑大上下文、多agent场景又不把GPU跑炸的核心。
相关资源链接:
- 英伟达完整技术博客:https://research.nvidia.com/labs/eai/blogs/kv-cache-compression-and-its-infra-problems/
- Avi Chawla从第一性原理拆解KV缓存的文章:http://x.com/i/article/2034896077460316163
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号