为什么说 ETCD 是 Kubernetes 的命门?

为什么说 ETCD 是 Kubernetes 的命门?

一根头发丝的宽度
发布于 2026-06-29 13:08:26
发布于 2026-06-29 13:08:26
Kubernetes 可以没有业务 Pod,但绝不能失去 ETCD。
在学习 Kubernetes 时,认为:
- kube-apiserver 最重要
- scheduler 最重要
- kubelet 最重要
直到某一天,集群突然出现:
etcdserver: request timed out
或者:
context deadline exceeded
整个集群瞬间失去响应。
- Pod 无法创建。
- Deployment 无法更新。
- kubectl 无法操作。
控制平面几乎完全瘫痪。
而这一切,往往只是因为一个组件出了问题:ETCD。
前两天在一次 Kubernetes 集群升级过程中,我也真实踩到了 ETCD 的坑,再次意识到:
ETCD 才是 Kubernetes 真正的命门。
一、ETCD 到底是什么?

官方对 ETCD 的定义是:
一个高可用、强一致性的分布式键值数据库。
简单来说:
Kubernetes = 大脑
ETCD = 记忆
如果没有记忆。
再聪明的大脑也无法工作。
Kubernetes 中几乎所有状态数据都会保存到 ETCD:
- Pod
- Deployment
- Service
- ConfigMap
- Secret
- Node
- Ingress
- CRD
甚至你每天执行的:
kubectl get pods
最终看到的数据,也全部来自 ETCD。
二、ETCD 不就是数据库吗?为什么不用 Redis?
很多人第一次接触 ETCD 时都会问:
既然都是存数据,为什么 Kubernetes 不直接使用 Redis?
甚至:
- MySQL
- PostgreSQL
- MongoDB
这些数据库看起来都比 ETCD 更成熟。
事实上:
ETCD 确实是一种数据库。
但它和传统数据库解决的问题完全不同。
简单对比:
数据库 | 主要用途 |
|---|---|
MySQL | 业务数据 |
PostgreSQL | 关系数据 |
Redis | 缓存、会话 |
MongoDB | 文档数据 |
ETCD | 集群状态数据 |
Kubernetes 保存的数据其实长这样:
/registry/pods/default/nginx
/registry/services/default/web
/registry/nodes/master01
本质上:
Key:
/registry/pods/default/nginx
Value:
Pod 的完整状态信息
因此 ETCD 更像:
一个专门存储集群状态的数据库。
三、为什么 Redis 不适合 Kubernetes?
Redis 最大的优点:
- 快
- 简单
- 内存存储
- 主从复制
但 Kubernetes 最需要的并不是速度。
而是:
数据必须绝对一致。
假设:
master01 认为副本数是 5
master02 认为副本数是 3
master03 认为副本数是 4
整个调度系统都会陷入混乱。
Redis 主从复制本质上属于:
最终一致性
而 Kubernetes 需要:
强一致性
只有多数节点确认写入成功。
数据才算真正提交。
这正是 ETCD 的核心能力。
四、Kubernetes 为什么最终选择了 ETCD?
因为 ETCD 同时具备三个关键能力。
1、强一致性
所有节点看到的数据永远一致。
2、Watch 机制
Kubernetes 最大的特点就是:
状态驱动。
例如:
- Pod 删除
- Node 下线
- Deployment 更新
Controller 可以实时收到通知。
而不是不断轮询数据库。
3、高可用
3 个节点:
允许损坏 1 个节点
5 个节点:
允许损坏 2 个节点
这也是为什么生产环境通常采用:
3 Master
架构。
五、Kubernetes 为什么离不开 ETCD?
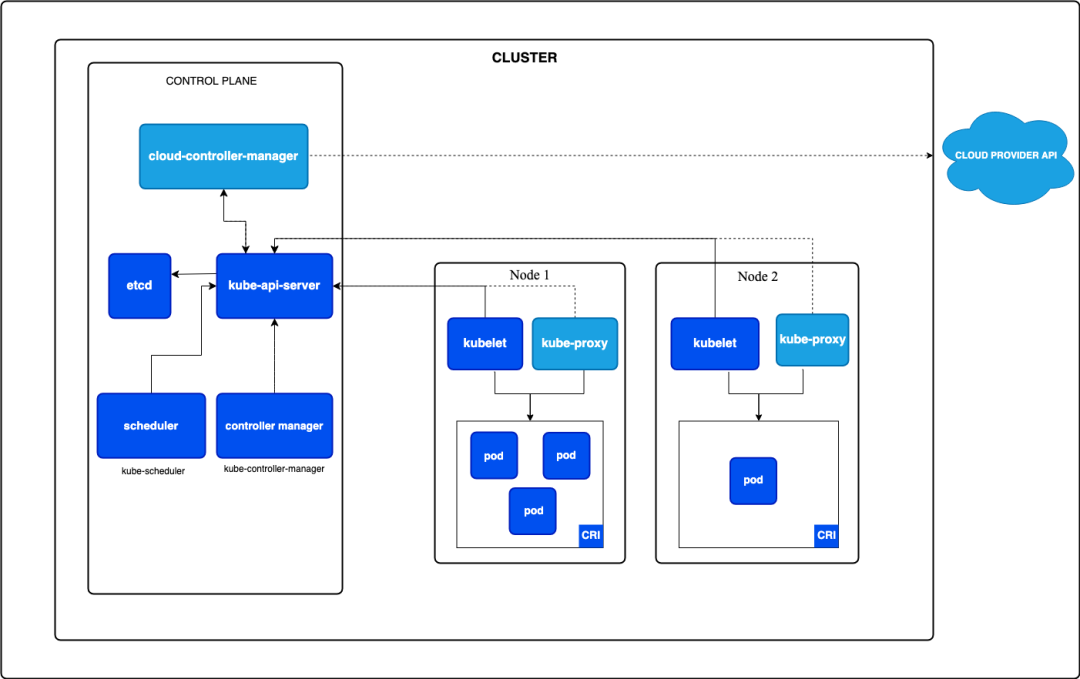
整个控制平面的工作流程其实非常简单。
kubectl
│
▼
API Server
│
▼
ETCD
例如:
kubectl apply -f nginx.yaml
实际上发生的是:
用户提交 YAML
│
▼
API Server
│
▼
写入 ETCD
│
▼
Scheduler 调度
│
▼
Kubelet 创建 Pod
如果 ETCD 无法写入。
整个流程都会停止。
六、ETCD 挂了会发生什么?

很多人认为:
ETCD 挂了,业务 Pod 就会全部停止。
其实不是。
已经运行中的 Pod 往往还能继续工作。
但控制平面会失去能力:
- 无法创建 Pod
- 无法删除 Pod
- 无法扩缩容
- 无法调度
- 无法修改配置
- 无法查看资源
此时执行:
kubectl get pods
可能看到:
etcdserver: request timed out
或者:
The connection to the server was refused
整个集群就像突然失忆了一样。
七、为什么 ETCD 一定是奇数节点?
生产环境常见:
3 节点 ETCD
或者:
5 节点 ETCD
很少看到:
2 节点
4 节点
原因是 ETCD 使用了:
Raft 一致性算法。
例如:
3 个节点:
2 个节点同意即可写入。
允许:
损坏 1 个节点。
5 个节点:
3 个节点同意即可写入。
允许:
损坏 2 个节点。
因此:
奇数节点可以获得最高的容错能力。
八、Leader 到底在干什么?
ETCD 集群通常:
master01 Leader
master02 Follower
master03 Follower
写请求流程:
API Server
│
▼
Leader
│
▼
Followers
│
▼
多数确认
│
▼
提交成功
如果 Leader 故障:
Leader Down
│
▼
重新选举
│
▼
New Leader
整个过程通常只需要几秒。
九、升级时,为什么 ETCD 最危险?

最近在一次 Kubernetes 升级过程中,我就遇到了:
static Pod hash for component etcd
did not change after 5m0s
随后:
context deadline exceeded
控制节点直接变成:
NotReady
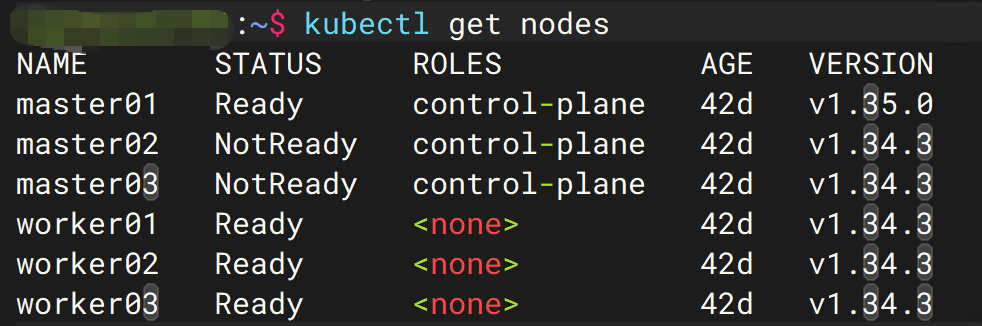
最终排查发现:
kubelet 参数异常
导致新的 ETCD Static Pod 无法启动。
这时真正理解:
Kubernetes 升级,本质上是在升级控制平面。
而控制平面中最敏感的组件,就是 ETCD。
十、为什么升级前一定先备份 ETCD?
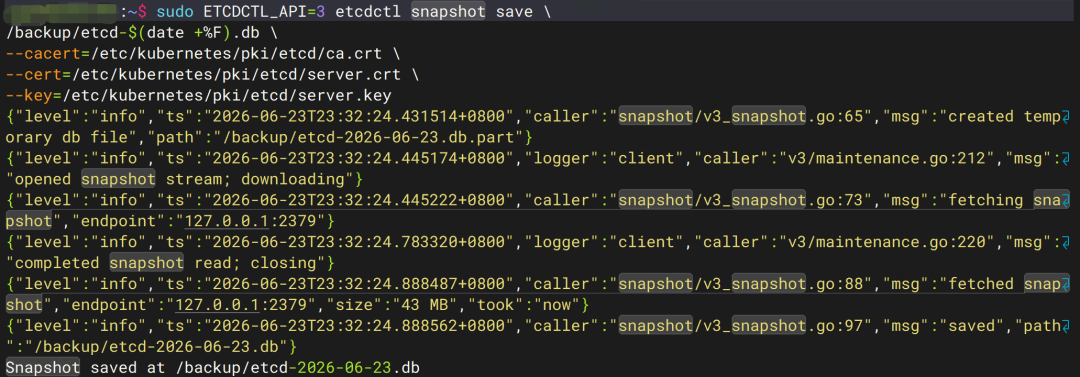
官方升级文档第一步:
etcdctl snapshot save snapshot.db
很多人觉得:
我只是升个版本,有必要吗?
答案是:
非常有必要。
因为 ETCD 保存着:
- 所有资源
- 所有状态
- 所有配置
如果升级过程中发生:
- 数据损坏
- 人工误操作
- 磁盘故障
- 节点故障
没有备份。
整个集群可能无法恢复。
所以生产环境中:
升级第一步永远是备份 ETCD。
十一、如何检查 ETCD 是否健康?
查看 ETCD Pod:
kubectl get pods -n kube-system | grep etcd
查看成员:
etcdctl member list
查看健康状态:
etcdctl endpoint health
查看 Leader:
etcdctl endpoint status -w table
建议把这些命令保存下来。
很多控制平面故障,最终都会定位到 ETCD。
保持敬畏
很多运维同学第一次真正认识 ETCD,往往不是通过学习。
而是通过一次事故。
可能是:
- 升级失败
- 磁盘满
- 网络故障
- Leader 切换
- 数据损坏
然后才发现:
原来 Kubernetes 最重要的并不是 Pod,也不是 API Server,而是 ETCD。
如果说:
- kubelet 是节点的大脑;
- API Server 是控制中心;
那么:
ETCD,就是整个 Kubernetes 集群的记忆。
它并不是最快的数据库。
也不是功能最多的数据库。
但它具备 Kubernetes 最需要的三个能力:
- 强一致性
- 高可用
- 实时监听
因此:
Kubernetes 不是选择了性能最好的数据库,而是选择了最适合自己的数据库。
而失去记忆的 Kubernetes,将什么都做不了。如果 Kubernetes 只有一个组件绝对不能丢数据,那一定是 ETCD。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号