ICML 2026 | 从 TimeOmni-1 到 TimeOmni-VL:时间序列大模型迈向统一的理解和生成

ICML 2026 | 从 TimeOmni-1 到 TimeOmni-VL:时间序列大模型迈向统一的理解和生成

时空探索之旅
发布于 2026-06-29 14:41:20
发布于 2026-06-29 14:41:20
标题:TimeOmni-VL: Unified Models for Time Series Understanding and Generation
作者: Tong Guan1,2, Sheng Pan1, Johan Barthelemy3, Zhao Li4, Yujun Cai5, Cesare Alippi6,7, Ming Jin1,*, Shirui Pan1,*
单位:1 格里菲斯大学(Griffith University) 2 浙江大学 3 英伟达(NVIDIA) 4 之江实验室(Zhejiang Lab) 5 昆士兰大学(The University of Queensland) 6 瑞士意大利语区大学(Università della Svizzera italiana) 7 米兰理工(Politecnico di Milano) (* 通讯作者)
- 📄 论文:https://arxiv.org/abs/2602.17149
- 🤗 模型:https://huggingface.co/TimeOmni-VL/TimeOmni-VL
- 🔮 在线 Demo:https://huggingface.co/spaces/anton-hugging/TimeOmni-VL
- 💻 代码:https://github.com/AntonGuan/TimeOmni-VL

点击文末阅读原文跳转本文arXiv链接
序言
来自 格里菲斯大学(Griffith)、浙江大学、英伟达(NVIDIA)、之江实验室、昆士兰大学(UQ)、瑞士意大利语区大学(USI)、米兰理工(Politecnico di Milano) 的研究团队联合推出了 TimeOmni-VL。这项工作提出以“视觉”为中心的统一多模态时间序列模型,将时间序列的理解、预测、插补和推理放进同一套模型框架中。
TimeOmni-1 是 TimeOmni 系列的首个工作,它首次系统性地让大模型具备了面向时间序列问题的复杂推理能力。目前,TimeOmni-1 的模型权重在 Hugging Face 上累计下载量已超过 8000 次。基于这一基础,TimeOmni-VL 进一步将能力从“理解与推理”拓展到“预测与插补”,使模型能够在同一套权重中同时完成时序理解和时序生成。两项工作都属于 TimeOmni 系列,目标都是让大模型具备时序智能能力。
0. TimeOmni-1 回顾
ICLR 2026 | 打破时间序列“黑盒”:TimeOmni-1开启深度时间序列推理新篇章
TimeOmni 系列的第一项工作 TimeOmni-1 (https://arxiv.org/abs/2509.24803)发表于 ICLR 2026,目标是让大模型像领域专家一样,对时间序列进行多步推理。为此,我们将复杂时间序列推理拆解为三类核心能力:
- 🔍感知(Perception):识别序列里的模式,并进一步理解这些模式可能对应什么场景、哪些变量之间可能有关联;
- 🔭外推(Extrapolation):结合外部事件(文本模态)和历史序列,预测未来。例如,一场演唱会可能会怎样影响附近区域的出租车需求;
- 🎯决策(Decision-making):在理解历史和预测未来的基础上,给出可执行的行动方案。例如,根据电价和历史用电,安排储能电池的充放电策略。
进一步地,这些能力被组织成四个原子任务:场景理解、因果发现、事件感知预测和决策,并构成了时间序列推理套件 TSR-Suite(Time Series Reasoning Suite)。
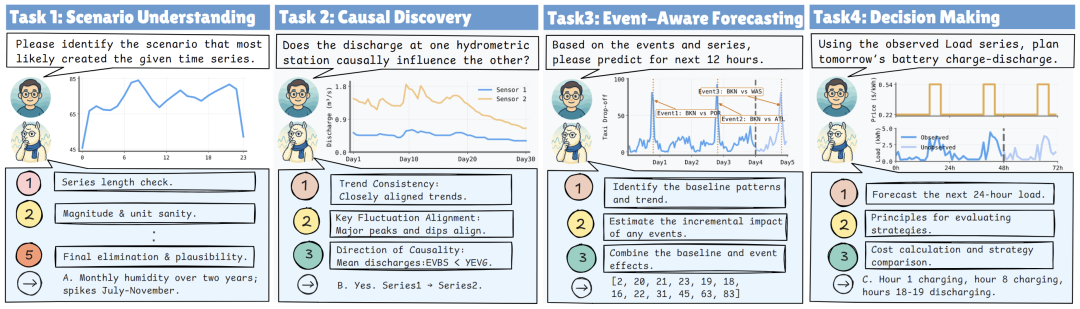
TimeOmni-1 的四个时序推理任务
TimeOmni-1 的四个时序推理任务
TimeOmni-1 证明了大语言模型不仅可以处理自然语言,也可以通过合适的数据和任务设计,学习时间序列中的复杂推理能力。目前,TimeOmni-1 在 Hugging Face 上的模型权重累计下载量已经超过 8000 次,也被后续工作用于金融推理(https://arxiv.org/abs/2605.03460)等场景。
但将时间序列转成离散文本 token 送给大模型做理解,依然存在以下潜在困难:第一,连续数值会被拆成离散 token,数值的整体结构容易被破坏。例如,一个多位数字可能被 tokenizer 拆成多个片段,模型看到的是 token,而不是连续数值。第二,长序列会受到 context length 的限制。时间序列往往很长,变量也可能很多,直接以文本形式输入会迅速占满上下文窗口。第三,语言模型本身并不擅长精确生成连续数值。它可以生成文字解释,但要稳定地产生高精度、多变量、长跨度的数值序列并不容易。以上困难限制了 TimeOmni-1 在复杂场景的可用性,为此团队思考:能否以更原生的方式理解、生成和推理时间序列数据?
1. 引言
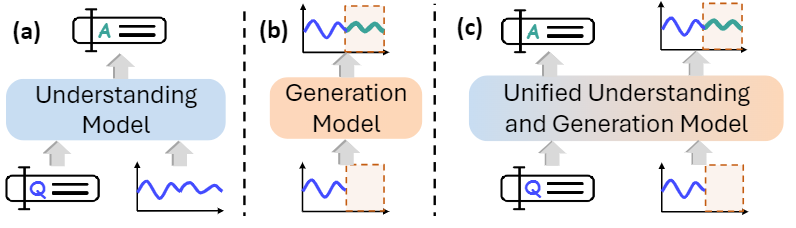
时间序列无处不在:交通流量、电力负荷、金融价格、医疗监测、工业传感器,都可以被表示成随时间变化的数值序列。长期以来,时间序列建模大致沿着两条路线发展。
一条线更关心生成,如上图(b)所示:给定历史序列,预测未来;或者在序列中有缺失时,补全缺失片段。典型任务包括 forecasting 和 imputation。这类模型通常擅长输出连续数值,但很难像人一样解释“为什么会这样变化”。
另一条线更关心理解,如上图(a)所示,比如 TimeOmni-1:模型不仅要看到曲线,还要判断趋势、识别异常、理解变量关系,甚至结合外部事件进行因果推断和决策。这类模型可以输出文字解释和判断,但要直接生成精确、连续的数值序列并不容易。
能否让同一个模型既能理解时序数据,又能生成时序,如上图(c)所示?
TimeOmni-VL 给出的答案是:把时间序列先转成图像(TS-image),让对时序的“理解”和“生成”都发生在视觉空间里。这样一来,时序理解任务可以转化为图像理解任务,输出文本答案;预测和插补任务则可以被转化成图像编辑任务,生成的图像再转化回时序模态。
2. 核心思路:好风凭借力,将时序的“理解”和“生成”内化为统一多模态模型的能力
目前以 Bagel 为代表的统一多模态模型 UMMs(Unified Multimodal Models)已经具备较强的图像理解和图像生成能力。如果我们能把时间序列可靠地表示成图像,那么很多原本属于时序建模的问题,就可以自然地转化为视觉任务。
具体来说,TimeOmni-VL 把一条或多条时间序列渲染成一张结构化的时序图像 TS-image。
在这张图中,变量、时间、周期和数值变化都会以视觉结构呈现出来。这样一来:
- 时间序列理解任务可以转化为图像理解任务,模型观察 TS-image 后输出文本答案;
- 时间序列预测和插补任务可以转化为图像编辑任务,模型先补全 TS-image 中被遮挡的区域,再将编辑后的图像还原到时序模态;
- 理解和生成不再是两套模型、两条路线,而是可以共享同一个统一多模态模型,理解和生成能力甚至可以相互促进。
3. 整体框架
TimeOmni-VL 以统一多模态模型为骨干模型,整体流程可以分成三步:
第一步,输入时间序列 (X) 经过 TS2I Converter,被转换成 TS-image (I)。
第二步,统一多模态模型根据不同任务执行不同操作:
- 如果是理解任务,模型读取时序图像,并根据指令 Cund 输出文本答案 o;
- 如果是生成任务,模型先在指令 Cgen 下产生一段面向生成的分析 Rgen,再据此补全目标区域,生成目标图像 Itgt。
第三步,生成后的目标图像 Itgt 通过 I2TS Converter 被还原成时间序列。
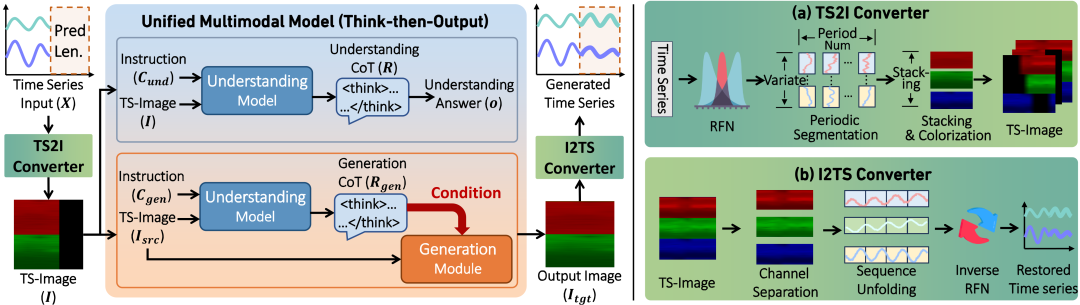
TimeOmni-VL 整体框架
TimeOmni-VL 整体框架
TimeOmni-VL 建立了一条完整的闭环:时间序列 → 图像 → 理解/生成 → 图像 → 时间序列。
这条闭环要真正有效,至少需要解决两个关键问题。第一,时间序列转图像时不能丢失太多信息。否则,后续模型再强,也只能基于失真的图像进行理解和生成。第二,生成不能只是像素级补全。时间序列预测和插补往往依赖趋势、周期、异常和变量间关系,因此模型最好先理解图像中的结构,再进行生成。TimeOmni-VL 分别用 Bi-TSI 和 Understanding-guided Generation 来解决这两个问题。
3.1 关键技术一:Bi-TSI,让时间序列和图像之间尽量无损转换
如果在时序到图像的转换过程中丢掉了尖峰、局部波动、长序列细节或多变量结构,那么模型看到的就不再是原始时间序列,而是一个被压缩甚至失真的视觉近似。现有方法(VisionTS 类)会遇到以下两个典型问题:
一是尖峰容易被压平。标准方差归一化对离群值比较敏感,一个极端值可能会拉大整体尺度,让大部分正常波动被挤压到很窄的像素区间里。
二是长序列容易被降采样。当序列很长、变量很多时,如果固定画布容量不足,就会不可避免地压缩时间轴或变量维度,导致细节损失。
为了解决这个问题,TimeOmni-VL 提出了 Bi-TSI(Bidirectional Time Series ⇄ Image),即一组高保真的双向时间序列-图像转换器:TS2I Converter 负责将时间序列转换为结构化时序图像;I2TS Converter 负责将生成后的图像还原为数值时间序列。其中有两项关键设计:

Bi-TSI 相比基线的两点改进
Bi-TSI 相比基线的两点改进
第一是鲁棒保真归一化(Robust Fidelity Normalization, RFN)。RFN 结合基于 MAD 的稳健尺度估计和有界压缩,减少异常值对整体归一化的影响,同时保证数值能映射到合法像素范围内。这样,即使序列中存在尖峰,图像也能尽量保留其形状和相对变化。
第二是编码容量控制(Encoding Capacity Control),即使用高分辨率画布,并通过容量约束减少隐式降采样,使更多变量和更长时间跨度可以被编码到同一张图像中。
简单说,Bi-TSI 解决的是一个基础问题:当我们把时间序列交给视觉模型之前,必须先确保“时序信息还在”。只有这一步足够可靠,后面的视觉理解和图像补全才有意义。
3.2 关键技术二:Understanding-guided Generation,理解引导生成
TimeOmni-VL 的第二个重要设计是:生成之前,先让模型理解当前时序图。TimeOmni-VL 将这个过程显式建模为 Generation CoT,即面向生成任务的分析过程,并利用这段分析来引导生成。在训练时,我们将样本组织成如下交错序列:
seq = Psys ⊕ Isrc ⊕ Cgen ⊕ Rgen ⊕ Itgt
其中,Psys 表示系统提示词,Isrc 是待编辑的时序图像,Cgen 表示生成指令,Rgen 表示模型在生成前需要学习的理解过程,Itgt 则是目标时序图像的真值。通过这样的构造,Rgen 成为连接“理解任务”和“生成任务”的条件上下文,使模型在预测或插补之前,先显式理解当前时序图中的结构信息,并由理解来引导生成。
消融结果显示,如果去掉这层理解上下文,预测和插补的 nMASE 平均恶化8.2%。这说明,在 TimeOmni-VL 中,理解能够引导生成过程,提升生成质量。
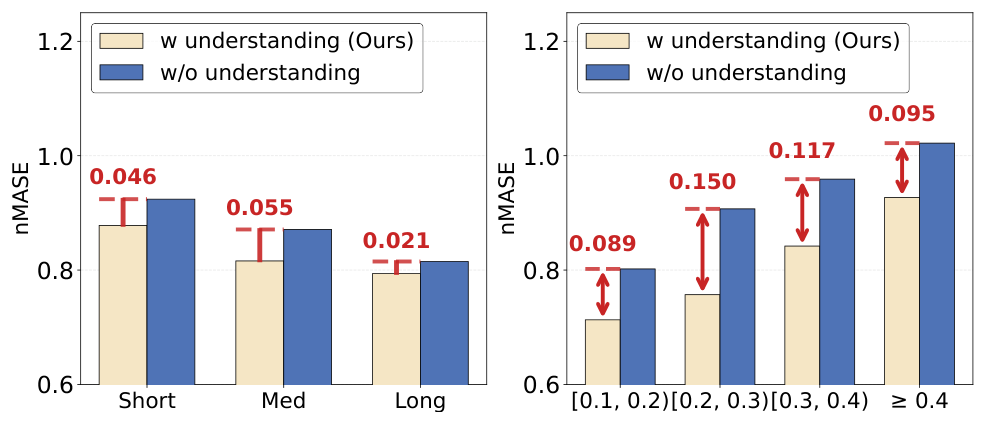
有无理解引导的生成对比
4. TSUMM-Suite:训练与评估
为了训练和评估 TimeOmni-VL,我们构建了 TSUMM-Suite(Time Series Unified Multimodal Model Suite),覆盖三类任务。
第一类是理解任务,共 6 个,包括变量计数、Y 值域判断、周期定位、均值比较、异常检测和趋势分析。模型需要观察时序图像,并输出文本答案。
第二类是生成任务,共 2 个,包括多变量预测和多变量插补。预测任务要求模型补全未来区域,插补任务要求模型补全中间缺失区域。生成完成后,图像会被解码回数值时间序列。
第三类是文本推理任务,沿用 TimeOmni-1 中的场景理解、因果发现、事件感知预测和决策任务,用于观察模型是否仍然保留时间序列推理能力。
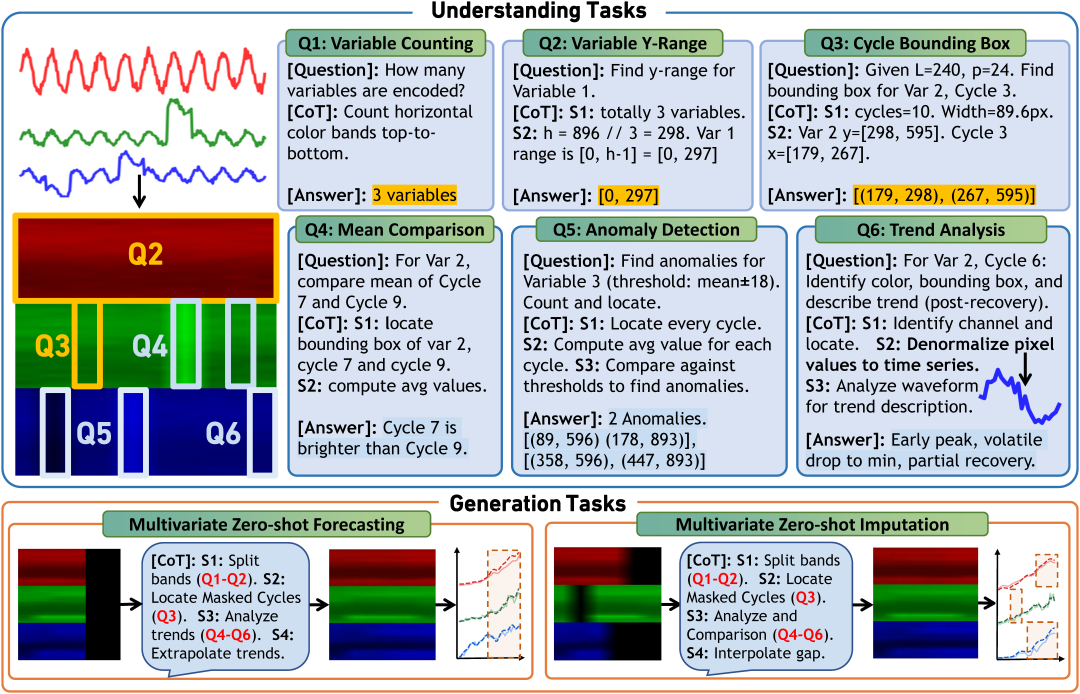
TSUMM-Suite 任务总览
TSUMM-Suite 任务总览
5. 实验验证
以下结果均基于 Bagel-7B 骨干模型,并在零样本、分布外(OOD)设置下进行评估。
5.1 理解任务
未经 TSUMM-Suite 训练的 Bagel 骨干,几乎无法完成时序图理解任务。经过 TimeOmni-VL 数据的后训练,模型在多个理解任务上显著提升,其中 QA1 到 QA4 的准确率接近 1.0,其余任务也有大幅提升。这说明统一多模态模型可以通过后训练,学会从结构化时序图像中读取变量数量、周期位置、数值范围、异常模式和趋势变化。
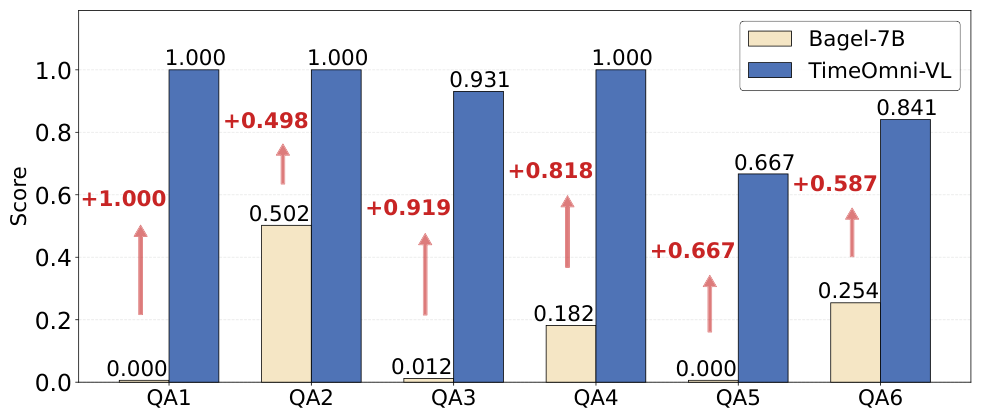
理解任务上的表现
理解任务上的表现
5.2 预测任务
使用 nMASE 作为指标,数值越低越好。TimeOmni-VL 在短期预测中取得 0.878,为表中最佳结果;在长期预测中取得 0.784,位列第二。这表明,TimeOmni-VL 在数值生成任务上可取得有竞争力的表现。
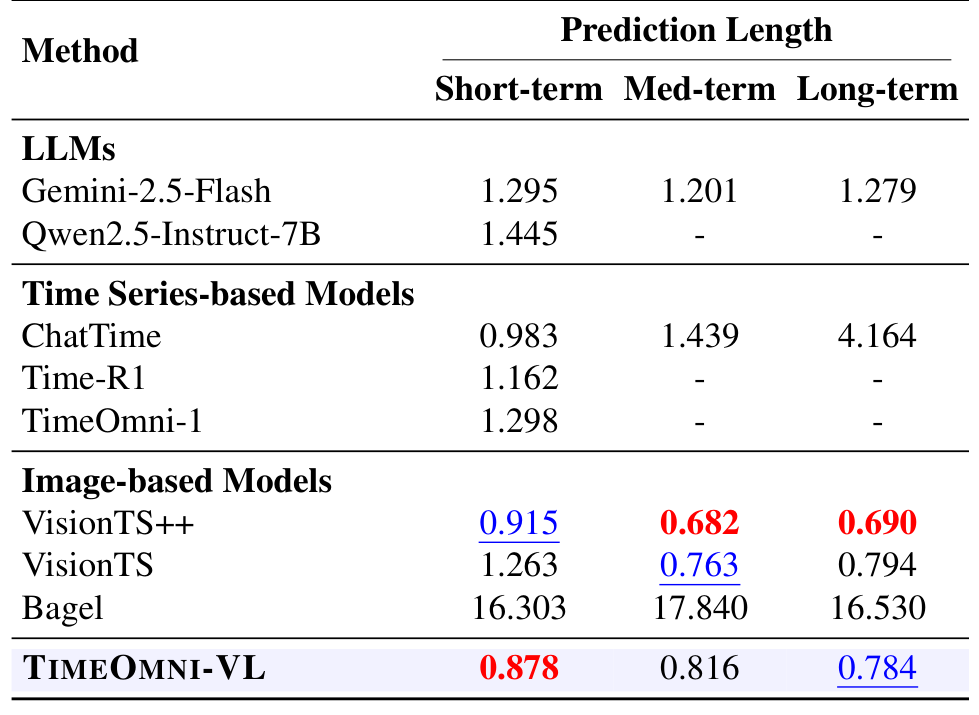
预测性能(nMASE)
预测性能(nMASE)
5.3 插补任务
使用 nMASE 作为指标,数值越低越好。TimeOmni-VL 在 10%、20%、30%、50% 四档缺失率设置下,nMASE 分别为 0.713、0.757、0.842、0.927,在本文对比方法中均为最低。这也符合图像补全的直觉:插补任务可以同时利用缺失区域前后的上下文,而视觉生成模型天然擅长根据周围结构补全缺失部分。
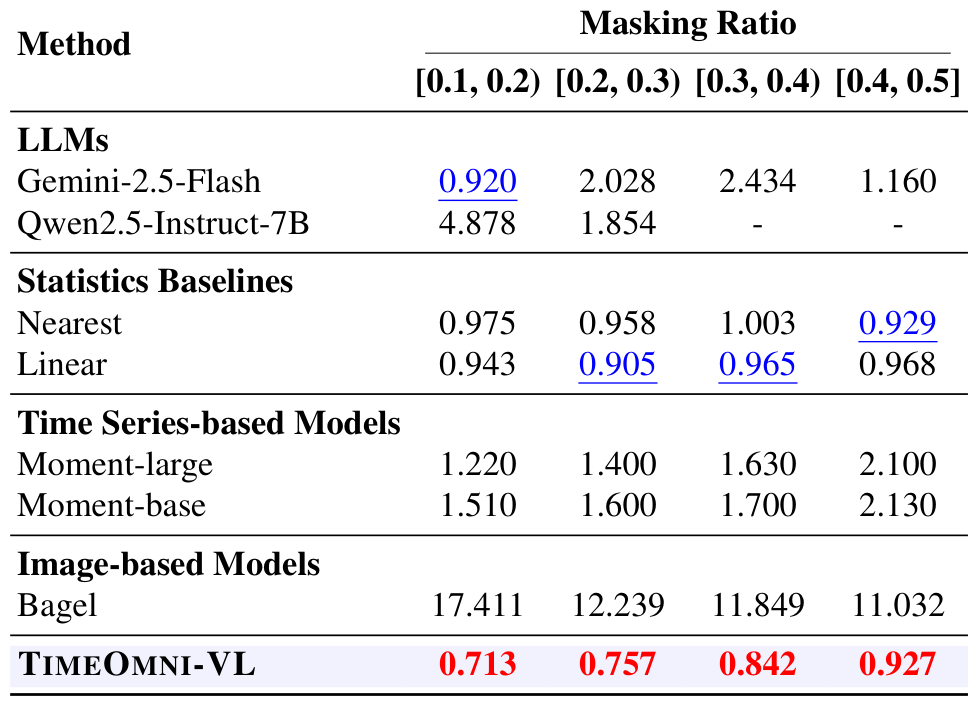
插补性能(nMASE)
插补性能(nMASE)
5.4 推理任务
论文还测试了纯文本时间序列推理任务。在这些任务中,TimeOmni-VL 没有像 TimeOmni-1 那样专门使用 RL 强化推理能力,而主要经过 SFT。在这种情况下,TimeOmni-VL 仍然在 Task1、Task2 上接近 TimeOmni-1,并在 Task4 上取得更高数值。这表明,将理解和生成统一到同一模型中,并没有明显破坏模型原有的文本推理能力。
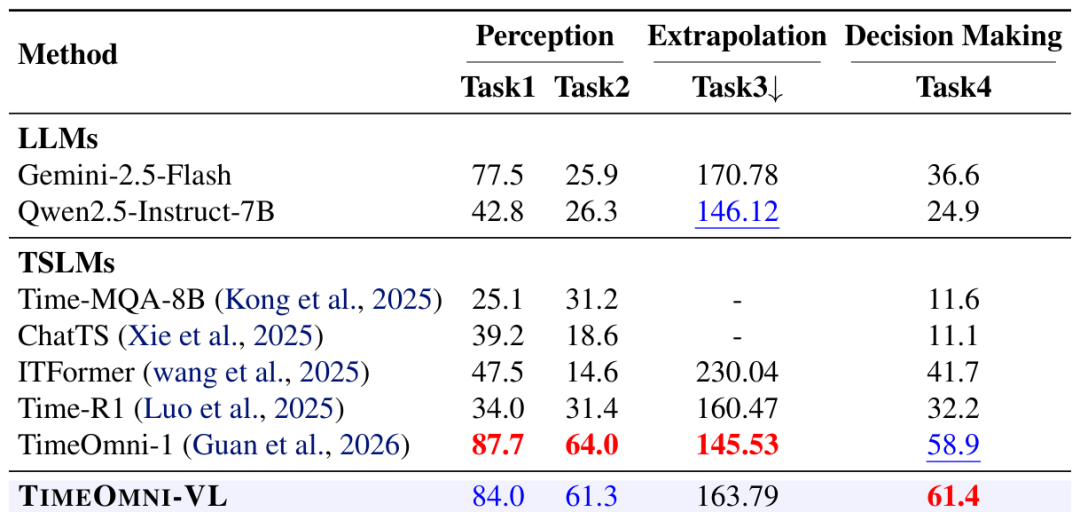
文本推理任务上的表现
文本推理任务上的表现
6. 上手体验
为了方便大家直观体验 TimeOmni-VL,我们提供了在线 Demo、模型权重和代码。
在线 Demo 中可以体验三类能力。
第一类是理解。上传一张时序图后,模型会围绕变量计数、Y 值域判断、周期定位、均值比较、异常检测和趋势分析等任务逐一作答。
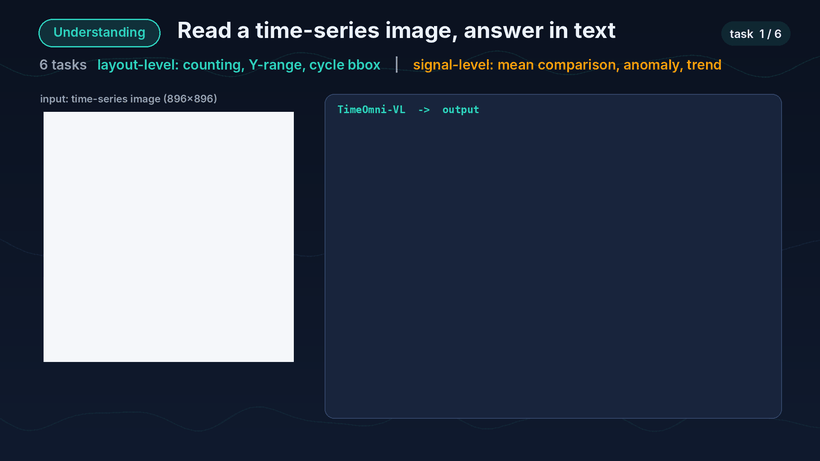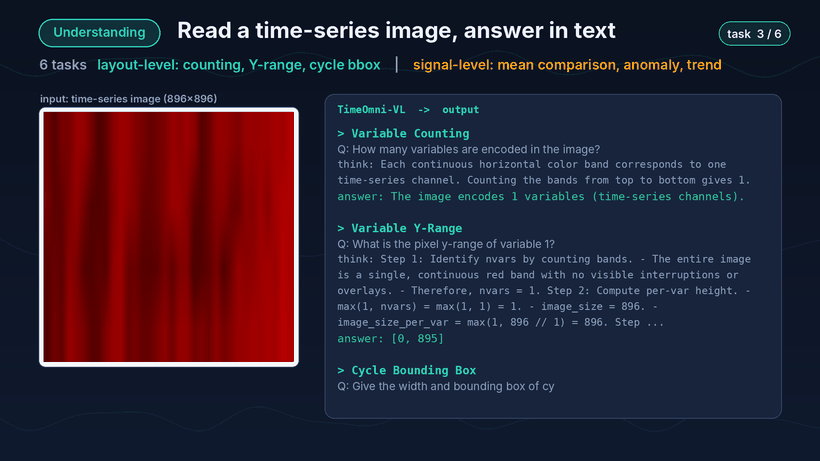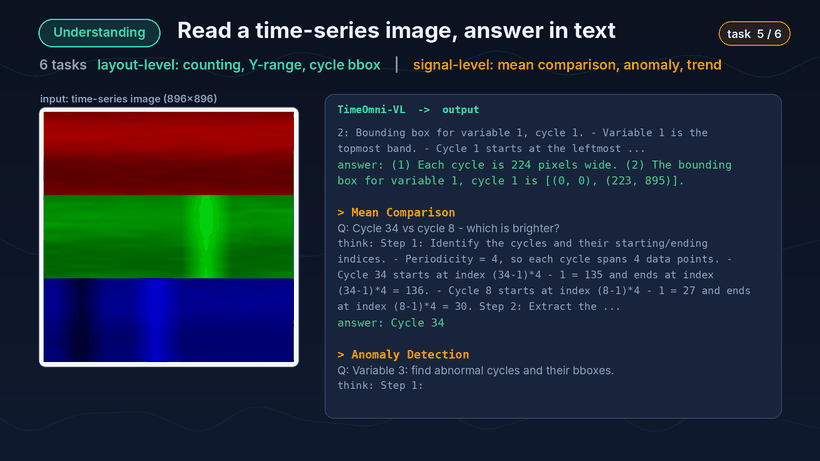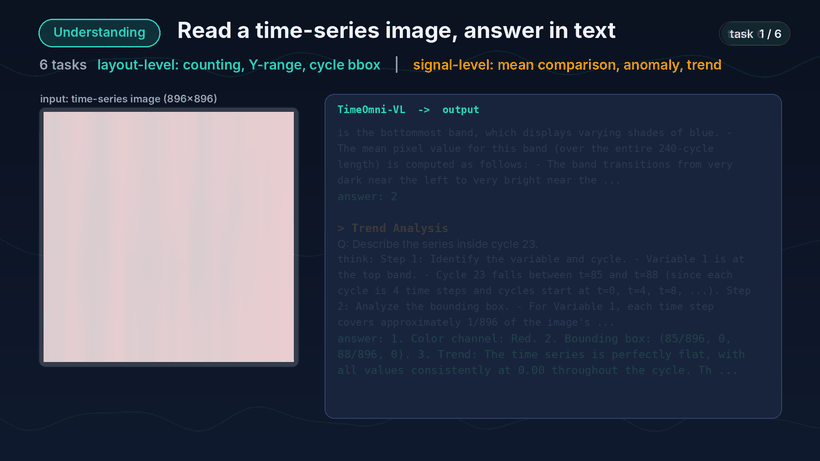
理解 Demo
理解 Demo
第二类是预测。模型会将未来区域视为待补全区域,先对当前输入图像进行分析,再生成补全后的图像,并最终解码成预测曲线。
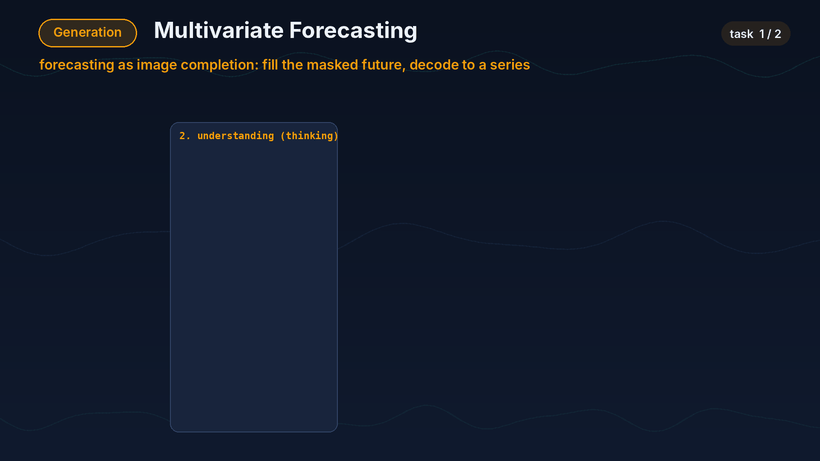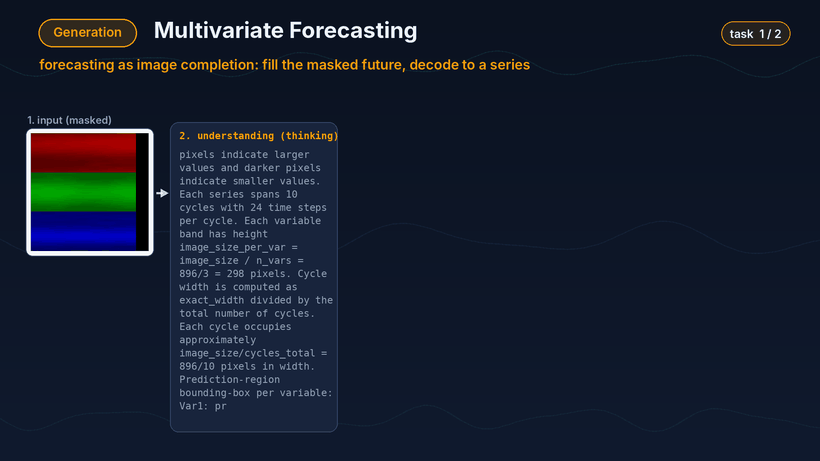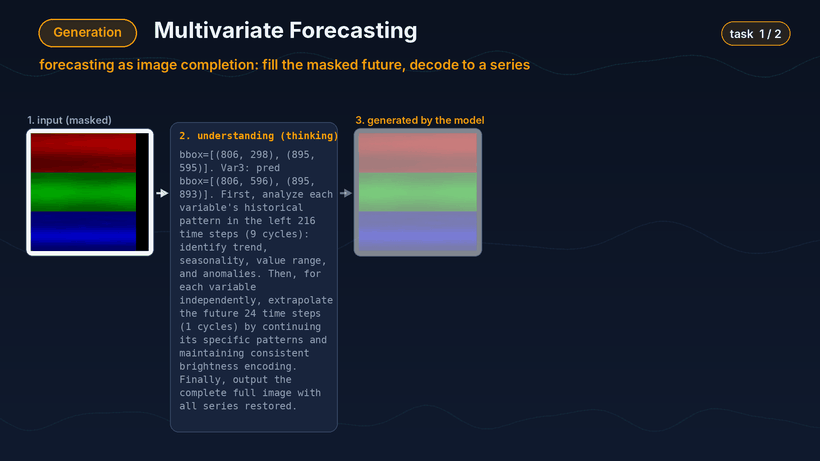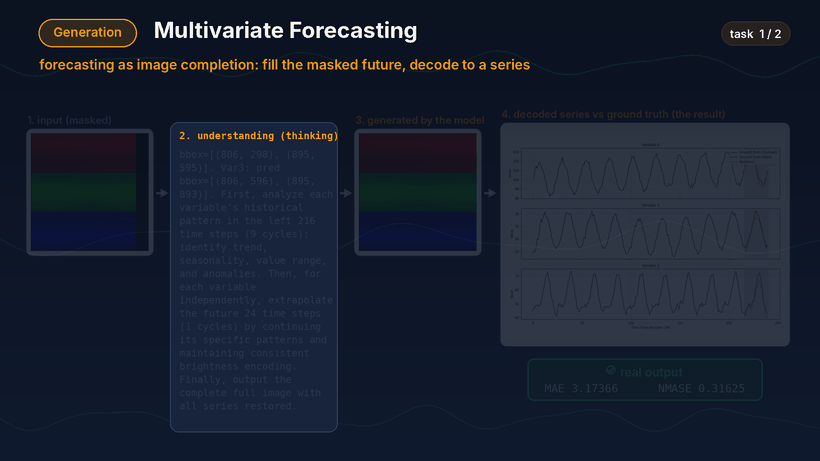
预测 Demo
预测 Demo
第三类是插补。与预测不同,插补任务的缺口位于序列中间。模型需要结合缺口前后的上下文,补全缺失片段。

插补 Demo
插补 Demo
相关资源如下:
- 📄 论文:https://arxiv.org/abs/2602.17149
- 🤗 模型:https://huggingface.co/TimeOmni-VL/TimeOmni-VL
- 🔮 在线 Demo:https://huggingface.co/spaces/anton-hugging/TimeOmni-VL
- 💻 代码:https://github.com/AntonGuan/TimeOmni-VL
7. 小结
TimeOmni-1 让我们看到,大语言模型可以通过合适的任务设计,学习时间序列中的复杂推理能力。TimeOmni-VL 则进一步尝试回答:能否将时间序列的理解、预测、插补和推理放进同一套模型框架中。从 TimeOmni-1 到 TimeOmni-VL,我们希望推动时间序列大模型从“能读懂、能推理”,进一步走向“能理解、能生成、能统一建模”。这也是 TimeOmni 系列持续探索的方向:让大模型真正具备时间序列智能。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号