K8s 资源 Requests vs Limits:调度器保证调度,内核保证限制

K8s 资源 Requests vs Limits:调度器保证调度,内核保证限制

一根头发丝的宽度
发布于 2026-06-30 13:59:13
发布于 2026-06-30 13:59:13
调度器保证的是调度,内核保证的是限制。这两者之间没有任何协调。
你给 Pod 设置了 requests,也设置了 limits。Pod 还是被限流了,或者被杀了。
不是 Kubernetes 有问题,而是多数人对这两个字段的理解有偏差。
很多人把 requests 和 limits 当成简单的 min/max 对——requests 是预留的资源,limits 是能用的上限。这个理解很直观,但不够准确。
Requests 和 limits 运行在完全不同的两个层面,由完全不同的两个系统执行。搞不清这个区别,生产环境的 Pod 就会在半夜莫名其妙地消失。
Requests 不是"预留"
设置一个 500m CPU 的 request,并不意味着这 500m 毫核被独占保留给这个 Pod。
它的真实意思是:调度器只会把这个 Pod 放到它的账本里还有 500m CPU 可用的节点上。
节点可能正承受着真实的 CPU 压力,但只要调度器的账本上还有额度,它就会认为这个节点"合格"。
Request 是一个调度信号,不是一个性能保证。
Limits 也不是简单的"上限"
对于 CPU 和内存,limit 的后果完全不一样:
- CPU 超限:cgroups 会进行限流,Pod 继续运行,只是变慢了
- 内存超限:内核 OOM Killer 直接杀掉容器,服务中断了
这两个行为完全不等价:一个默默降级,一个毫无预警地宕机。
核心结论:requests 和 limits 不是资源配置,它们是调度信号和运行时故障触发器。调度器用一个,内核强制执行另一个,它们之间从不交互。
两层系统,零协调
对 requests 和 limits 的困惑,源于把 Kubernetes 当成一个单一系统。实际上,调度和强制执行由完全不同的组件处理。
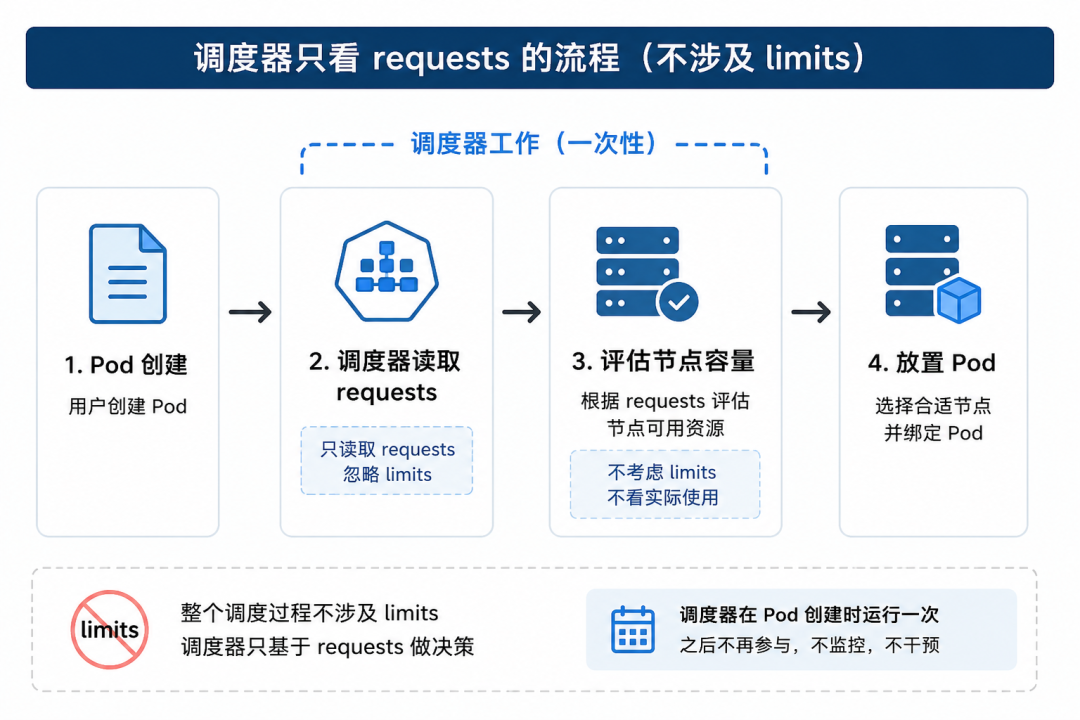
第一层:调度器的放置决策
使用:requests only
调度器在 Pod 创建时运行一次。它根据 requests 评估节点容量,然后做出放置决策。
之后,调度器的工作就结束了。它不会监控 Pod,不会在节点过载时介入,它甚至不知道 limits 被设置成了什么。
第二层:Kubelet + 内核的运行时执行
使用:limits only
Kubelet 在每个节点上持续运行。它监控容器的资源使用情况,在运行时强制执行 limits。
Kubelet 不知道调度器做了什么决定,它只关注实际使用量是否超过了 limits。
这两个系统不共享任何状态。
一个 Pod 可能被调度器完美放置——requests 满足、节点容量充足——但在运行时仍然被限流或杀掉。
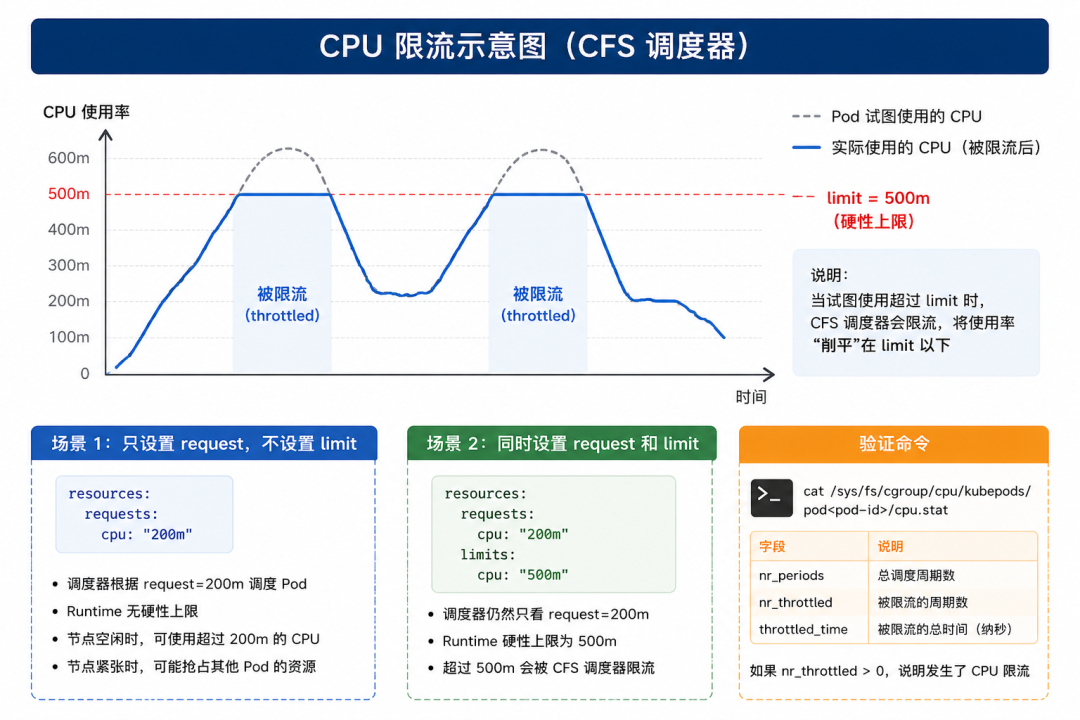
CPU:限流,但不会死
场景 1:只设置 request,不设置 limit
resources:
requests:
cpu: "200m"
# 没有设置 limits
- 调度器根据 request=200m 调度 Pod
- 运行时,如果节点 CPU 空闲,Pod 可以使用超过 200m 的 CPU
- 如果节点 CPU 紧张,Pod 没有硬性上限,可能抢占其他 Pod 的资源
场景 2:同时设置 request 和 limit
resources:
requests:
cpu: "200m"
limits:
cpu: "500m"
- 调度器仍然只看 request=200m
- 运行时,无论节点是否空闲,Pod 都不能使用超过 500m 的 CPU
- 超过 500m 就会被 CFS 调度器限流
验证命令:
# 查看 CPU 限流统计
cat /sys/fs/cgroup/cpu/kubepods/pod<pod-id>/cpu.stat
# nr_periods: 总调度周期数
# nr_throttled: 被限流的周期数
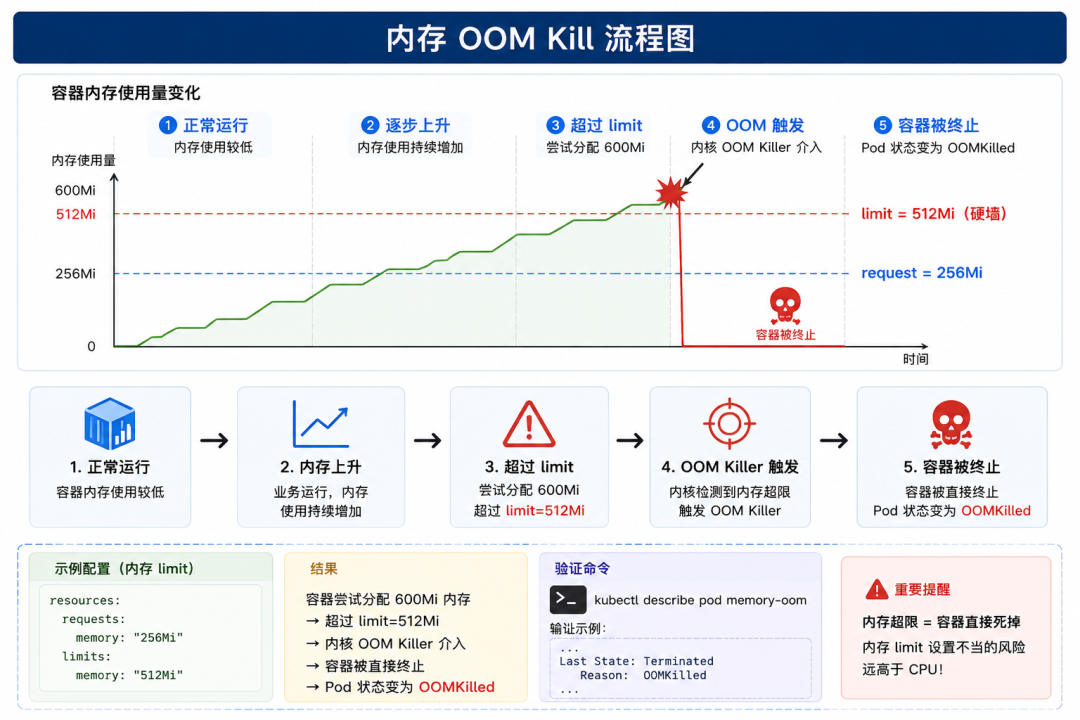
内存:超了就是死
内存 limit 是一堵硬墙。
resources:
requests:
memory: "256Mi"
limits:
memory: "512Mi"
容器尝试分配 600Mi 内存 → 超过 limit=512Mi→ 内核 OOM Killer 介入 → 容器被直接终止→ Pod 状态变为 OOMKilled。
内存超限 → 容器直接死掉。内存 limit 设置不当的风险远高于 CPU。
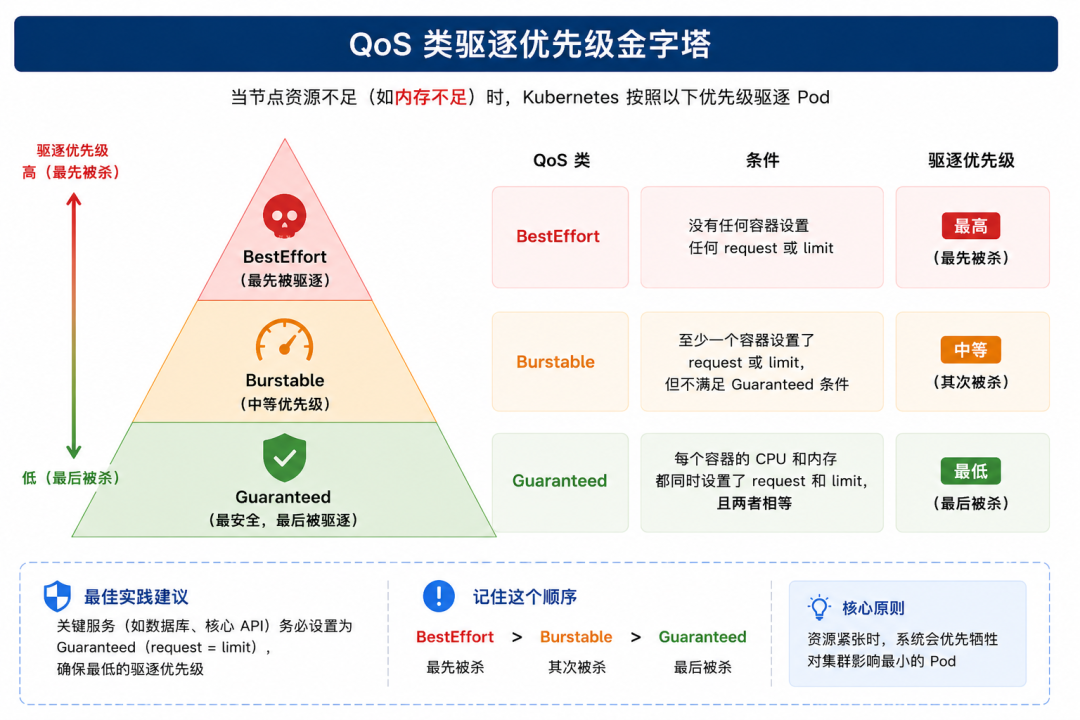
QoS 类:谁先被杀?
Kubernetes 根据 requests 和 limits 的设置方式,将 Pod 划分为三个 QoS 类,决定了当节点资源不足时,谁先被驱逐。
QoS 类 | 条件 | 驱逐优先级 |
|---|---|---|
Guaranteed | 每个容器的 CPU 和内存都同时设置了 request 和 limit,且两者相等 | 最低(最安全) |
Burstable | 至少一个容器设置了 request 或 limit,但不满足 Guaranteed 条件 | 中等 |
BestEffort | 没有任何容器设置任何 request 或 limit | 最高(最先被杀) |
当节点内存不足时:BestEffort 最先被驱逐 → Burstable 其次 → Guaranteed 最后。
关键服务(如数据库、核心 API)务必设置为 Guaranteed(request = limit),确保最低的驱逐优先级。
最佳实践
1. 永远同时设置 requests 和 limits
只设置 request 不设置 limit → 单个容器可能耗尽节点所有资源。
只设置 limit 不设置 request → 调度器无法合理调度。
2. 记住 CPU 和内存的不同
资源 | 超限后果 | 风险等级 |
|---|---|---|
CPU | 变慢(限流) | 中 |
内存 | 死掉(OOM Kill) | 高 |
3. 基于实际使用量设置
先用监控工具观察实际使用量:
- requests 设为 P50-P75分位数(典型使用量)
- limits 设为 P95-P99或 requests 的 1.5-2 倍
4. 关键服务用 Guaranteed
数据库、核心 API 等关键服务:request = limit,获得 Guaranteed QoS。
一般服务:Burstable,允许在资源空闲时适当突破。
批处理任务:可设为 BestEffort,利用闲置资源。
总结
概念 | 谁在用 | 什么时候用 | 超限后果 |
|---|---|---|---|
Requests | 调度器 | Pod 创建时 | 调度失败(Pending) |
Limits | Kubelet + 内核 | 运行时持续 | 限流或被杀 |
记住:requests 保证调度,limits 保证限制。它们各司其职,从不交互。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号