K8s 计算资源优化实战:刚配好 Requests|Limits?三招用 Prometheus 揪出集群里的“刺头”和“败家子”

K8s 计算资源优化实战:刚配好 Requests|Limits?三招用 Prometheus 揪出集群里的“刺头”和“败家子”

一根头发丝的宽度
发布于 2026-07-01 20:19:39
发布于 2026-07-01 20:19:39
别再让开发和运维为了资源配置吵架了,让数据说话。
在前两天的文章中,我们深入探讨了 Kubernetes 中 Requests(调度看它)与 Limits(运行时看它)的底层恩怨。
理论搞懂了,但在实际落地时,运维和开发之间往往会陷入永无止境的拉锯战:
- 业务开发:“我的微服务到底该配多少 CPU 和内存?我心里也没底啊,反正往大了配总没错,别崩就行!”
- 运维/老板:“你一个日活几百的内部服务,Request 申请了 4 核 8G,实际利用率不到 5%,服务器成本在滴血啊!”
在 Kubernetes 的世界里,资源配置从来不是靠玄学硬猜的,而是靠监控数据喂出来的。
本篇文章,我们就来点实战:如何利用 Prometheus 和 Grafana,精准揪出集群中那些被严重限流的“受害者”、游走在 OOM 边缘的“高危分子”,以及占着茅坑不拉屎的“资源浪费大户”。
一、揪出被限流的 CPU 刺头:别让 CFS 成为性能杀手
很多时候,开发会跑来抱怨:“运维,我的接口响应怎么变慢了?但我看 Grafana 里的 CPU 使用率曲线,明明连 Limit 的 50% 都没到啊,是不是底层网络丢包了?”
这其实是一个极具欺骗性的表象。
Kubernetes 限制容器 CPU 采用的是 Linux 内核的 CFS(完全公平调度器)周期机制。即使在 1 分钟的平均周期内,你的容器 CPU 使用率看起来很安全,但如果在其中的某几个毫秒内流量突增,容器的 CPU 就会瞬间触顶,进而触发内核的 CPU Throttling(CPU 节流/限流)。一旦被限流,业务接口就会出现神秘的响应变慢(Latency 飙升)。
我们不能只看 CPU 使用率,必须直接监控 CPU 节流时间比例。
💡 核心 PromQL:计算 Pod 的 CPU 限流比例
通过以下语句,可以计算出容器在过去 5 分钟内,有多少比例的时间段是被内核强行限流的:
sum(rate(container_cpu_cfs_throttled_periods_total[5m])) by (pod, namespace)
/
sum(rate(container_cpu_cfs_periods_total[5m])) by (pod, namespace) * 100
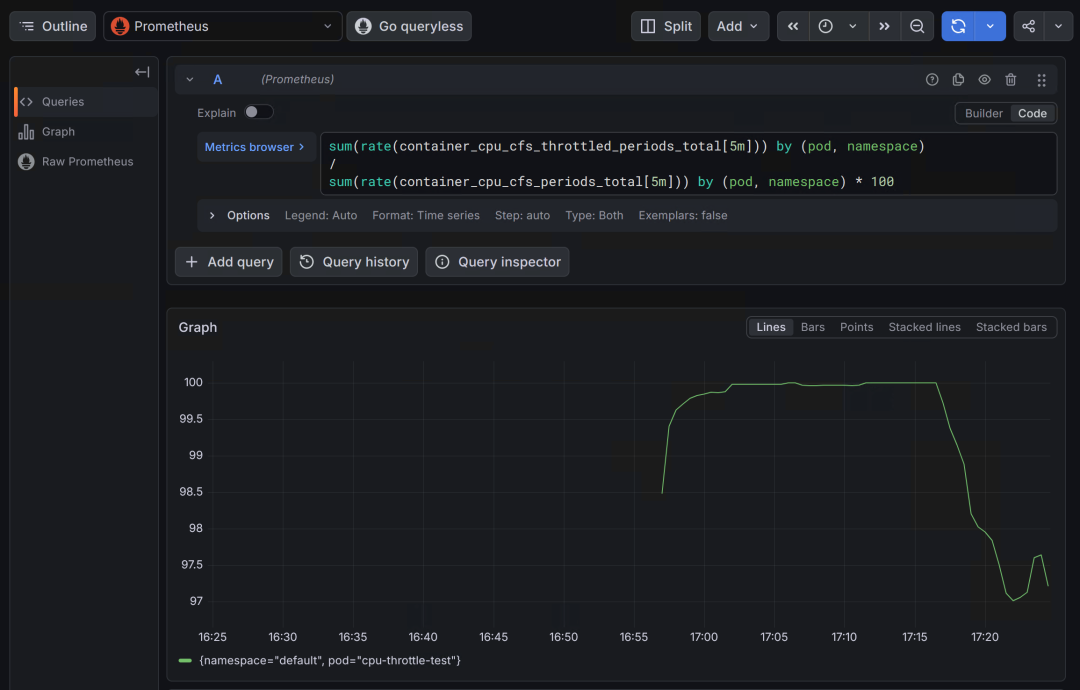
配图说明:上图为 CPU Throttling 限流比例监控图。图中
cpu-throttle-testPod 的限流比例长期维持在 99% 以上,说明其 CPU 使用需求远超 Limit 限制(500m),导致容器在每个调度周期几乎都被内核限流。在实际生产环境中,此类现象会导致应用响应延迟显著升高。 💡 调优建议:如果该比例持续超过 10%,说明该 Pod 已经遭遇了严重的 CPU 饥饿。哪怕整体 CPU 使用率不高,也必须立刻调大它的 Limits,或者优化代码中的多线程并发逻辑。
🔬 实验:创建一个会触发 CPU Throttling 的测试 Pod
apiVersion: v1
kind:Pod
metadata:
name:cpu-throttle-test
namespace:default
spec:
containers:
-name:stress
image:swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/polinux/stress:latest
command:["stress"]
args:["--cpu","2","--timeout","600"]
resources:
requests:
cpu:"200m"
limits:
cpu:"500m"
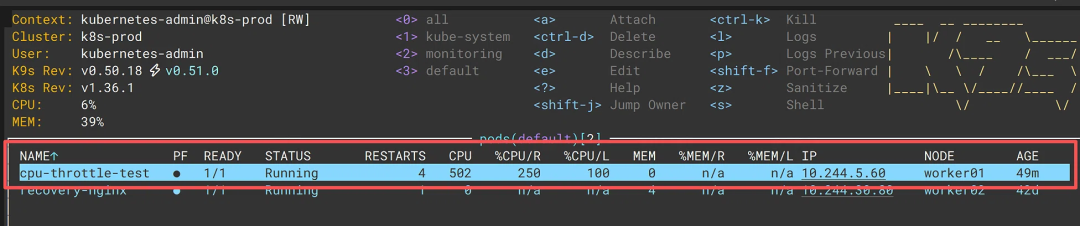
配图说明:在 K9s 中查看测试 Pod 的实时资源状态。可以看到
%CPU/L为 100%,说明该 Pod 已经耗尽了所有 CPU Limit 配额;%CPU/R为 250%,说明实际 CPU 使用量远超初始设置的 Request 值。结合RESTARTS=4的历史记录,进一步印证了该 Pod 长期处于资源紧张状态。
验证命令:
# 查看 Pod 是否在运行
kubectl get pod cpu-throttle-test
# 查看 CPU 使用情况
kubectl top pod cpu-throttle-test
# 查看限流统计(需要进入 Pod 所在节点,Pod id可以使用下面的命令获取)
kubectl get pod <pod-name> -n default -o jsonpath='{.metadata.uid}' # master节点获取 Pod id
cat /sys/fs/cgroup/cpu/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod<pod-id>/cpu.stat
# 使用 wathc 命令查看 nr_throttled 会持续增长

二、锁定游走在 OOM 边缘的 Pod:别看错了内存指标
如果说 CPU 设小了只是“变慢”,那内存(Memory)设小了就是“直接暴毙”。当容器内存超过 Limits 时,会被内核的 OOM Killer 直接物理消灭(OOMKilled)。
但很多同学在配置内存监控大盘时,经常选错指标,用了 container_memory_usage_bytes。这个指标包含了 Cached 缓存内存。在 Linux 的内存管理机制下,缓存文件页不会主动释放,导致监控曲线看起来永远接近 100%,从而频繁误报。
真正决定 Pod 生死的指标是:工作集内存(Working Set)。当 Working Set 触及 Limit 的那一刻,OOM 就会降临。
💡 说明:在实际生产环境中,如果希望稳定地观察内存 OOM 的监控曲线,通常需要通过持久化查询或预聚合来实现,而不是临时跑一个 PromQL 查询等待 OOM 发生。可以先用
kubectl describe pod确认 Pod 被 OOM Kill 的时间点,然后在 Grafana 中把时间范围调到那个时间段,查看历史数据曲线。如果你在生产环境中也遇到了同样的情况,可以试试这个思路。本文不展开讨论这部分,读者可以在实际排查时参考这个方法。
🔬 实验:创建一个会触发 OOM Kill 的测试 Pod
apiVersion: v1
kind:Pod
metadata:
name:memory-oom-test
namespace:default
spec:
containers:
-name:stress
image:swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/polinux/stress:latest
command:["stress"]
args:["--vm","1","--vm-bytes","600M","--timeout","60"]
resources:
requests:
memory:"256Mi"
limits:
memory:"512Mi"
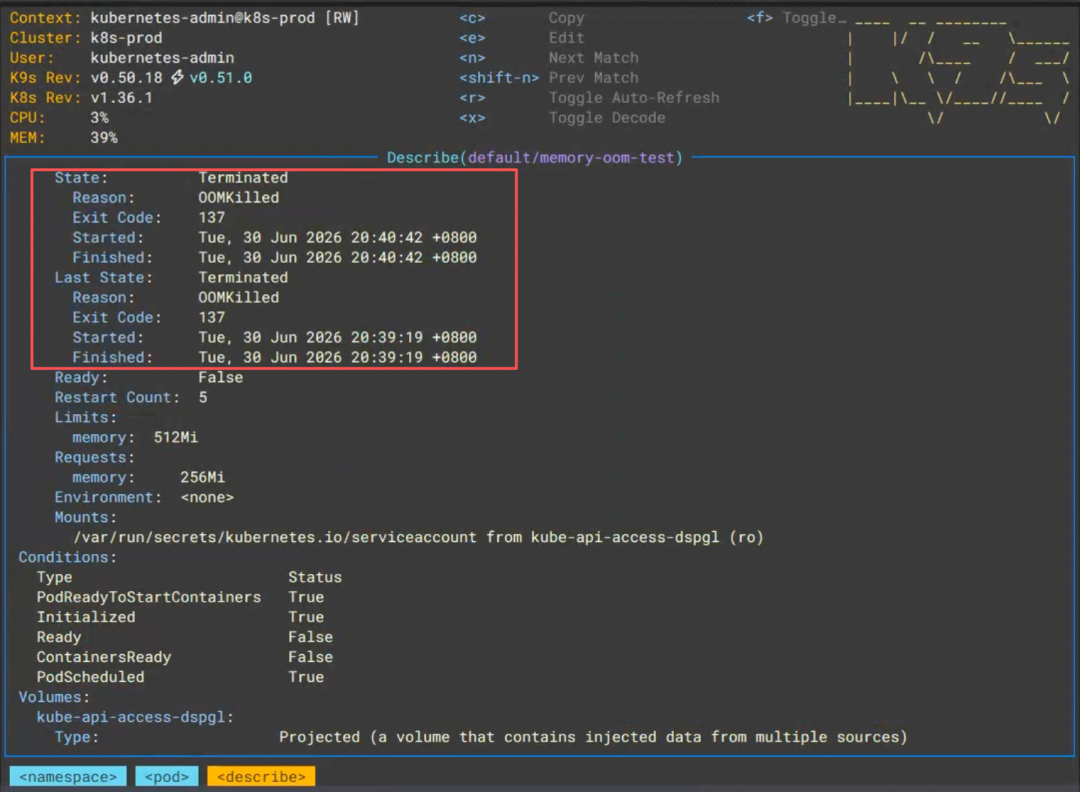
配图说明:在 K9s 中查看
memory-oom-testPod 的状态。可以看到该 Pod 已被 OOM Killer 终止(Reason: OOMKilled),退出码为 137,且已重启 5 次。这验证了当容器内存使用量超过 Limit 时,内核会直接将其杀死,不会像 CPU 那样进行节流。结合requests: 256Mi和limits: 512Mi的配置,容器尝试分配 600M 内存的行为直接触发了 OOM。
验证命令:
# 查看 Pod 状态
kubectl get pod memory-oom-test
# 查看详细事件
kubectl describe pod memory-oom-test
# 在 Events 中会看到: "OOMKilled"
三、曝光“占着茅坑不拉屎”的资源浪费大户
说完了被压榨的 Pod,我们再来看看公司最头疼的资源隐形杀手。
由于调度器在放置 Pod 时,只看 Requests。如果开发为了图省心,把 Requests 设得极大(比如 8 核),但平时业务实际连 0.5 核都用不到。这就导致节点明明还很空闲,但因为 Requests 被占满了,调度器再也无法把其他 Pod 塞进来。
这种现象叫“资源空转”,是企业 IT 成本居高不下的罪魁祸首。
🔬 实验:创建一个“资源浪费”的测试 Pod
apiVersion: v1
kind:Pod
metadata:
name:resource-waste-test
namespace:default
spec:
containers:
-name:nginx
image:swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:stable-alpine-linuxarm64
resources:
requests:
cpu:"1"
memory:"1Gi"
limits:
cpu:"2"
memory:"2Gi"
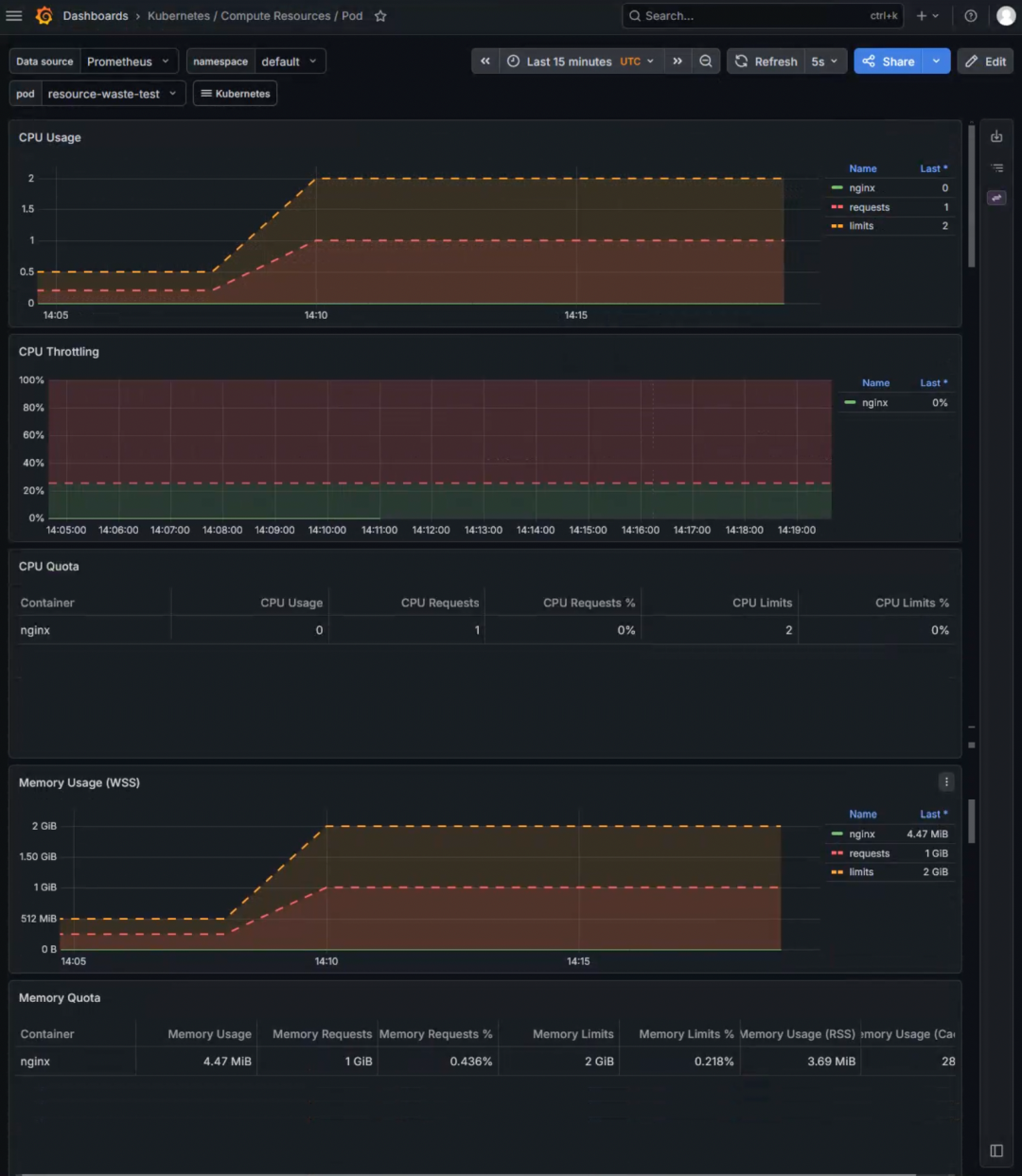
配图说明:上图为一个 Nginx 测试 Pod 的资源使用情况。该 Pod 申请了 1 核 CPU 和 1Gi 内存,但实际 CPU 使用量几乎为 0,内存使用仅为 4.47 MiB,不足申请量的 0.5%。这类过度申请的 Pod 会大量浪费集群资源,是导致 IT 成本居高不下的隐形杀手。借助监控数据,我们可以精准识别这类“败家子”,并指导开发下调 Requests。
验证命令:
# 查看 Pod 状态
kubectl get pod resource-waste-test
# 查看实际资源使用
kubectl top pod resource-waste-test
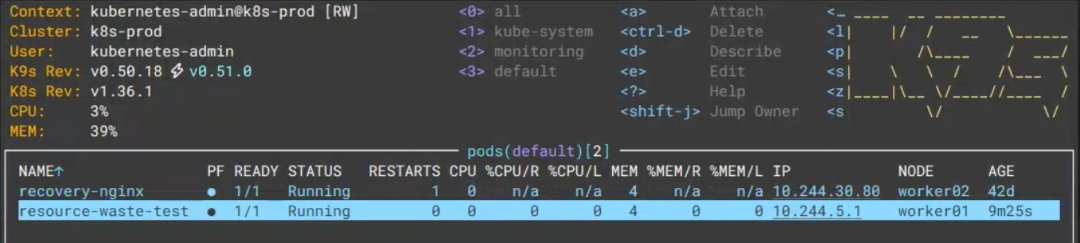
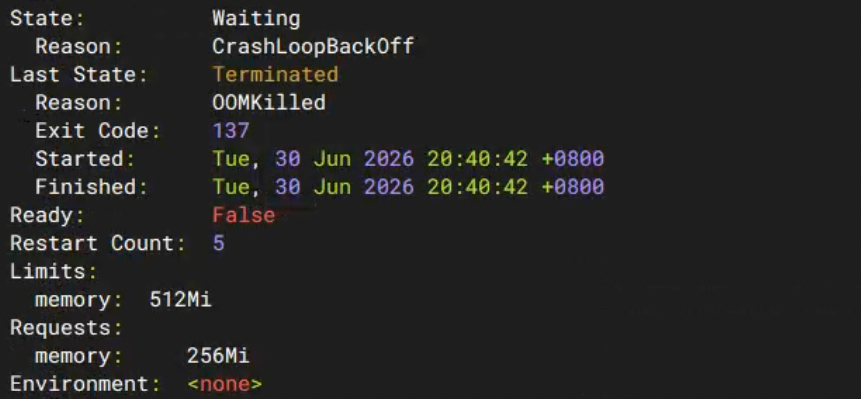
配图说明:在 K9s 中查看该 Pod 的实时资源状态。
CPU/R和MEM/R均为 0,说明该 Pod 的 CPU 和内存实际使用量几乎为 0%,而它却申请了远超实际需求的资源量。这种 Pod 在集群中越多,资源浪费就越严重,直接导致 IT 成本虚高。
四、搭建你的“K8s 资源运营全景大盘”
通过以上三个维度的分析,我们已经掌握了发现集群计算资源问题的方法。但每次手动执行 PromQL 查询毕竟不够高效,更好的方式是将这些核心指标固化到一个统一的 Grafana 看板中,实现常态化监控。
我们可以创建一个自定义的专属大盘,包含以下三个核心面板:
面板 | 监控目标 | 业务价值 |
|---|---|---|
面板一:CPU 限流刺头 | CPU Throttling 比例最高的 Top 5 Pod | 帮助开发定位性能瓶颈,及时扩容或优化代码 |
面板二:内存高危分子 | 内存工作集使用率 > 85% 的 Pod | 提前发现 OOM 风险,避免服务突然宕机 |
面板三:资源浪费大户 | Requests 与实际使用差值最大的 Top 10 容器 | 指导开发下调过度申请的资源,直接降本 |
有了这个看板,运维可以每周复盘一次,将“红榜”问题推送给对应开发团队优化,将“黑榜”问题纳入成本优化计划。运维不再靠感觉扯皮,开发也不再凭经验拍脑袋——一切让数据说话。
- 红榜(高危区):CPU Throttling Top 5 & 内存饱和度 > 85% 的 Pod(需要加资源/改 Bug)
- 黑榜(浪费区):Requests 与实际使用差值最大的 Top 10 容器(需要降本砍资源)
你的集群里是不是也藏着这样的“隐形刺头”或“高置信度败家子”?跟着下面的步骤,花几分钟把这张大盘搭起来看看吧。
如何配置这个“K8s 资源能效看板”
🚀 第一步:导入社区 Dashboard
我已经找到了一个非常合适的现成 Dashboard,它包含了 CPU 限流、内存使用、OOM 事件等核心监控面板,可以直接导入使用。
- 登录 Grafana,在左侧菜单栏点击
Dashboards - 点击
New按钮,选择Import - 在
Import via grafana.com输入框中填入 Dashboard ID:21584 - 点击
Load - 选择你的 Prometheus数据源,点击
Import
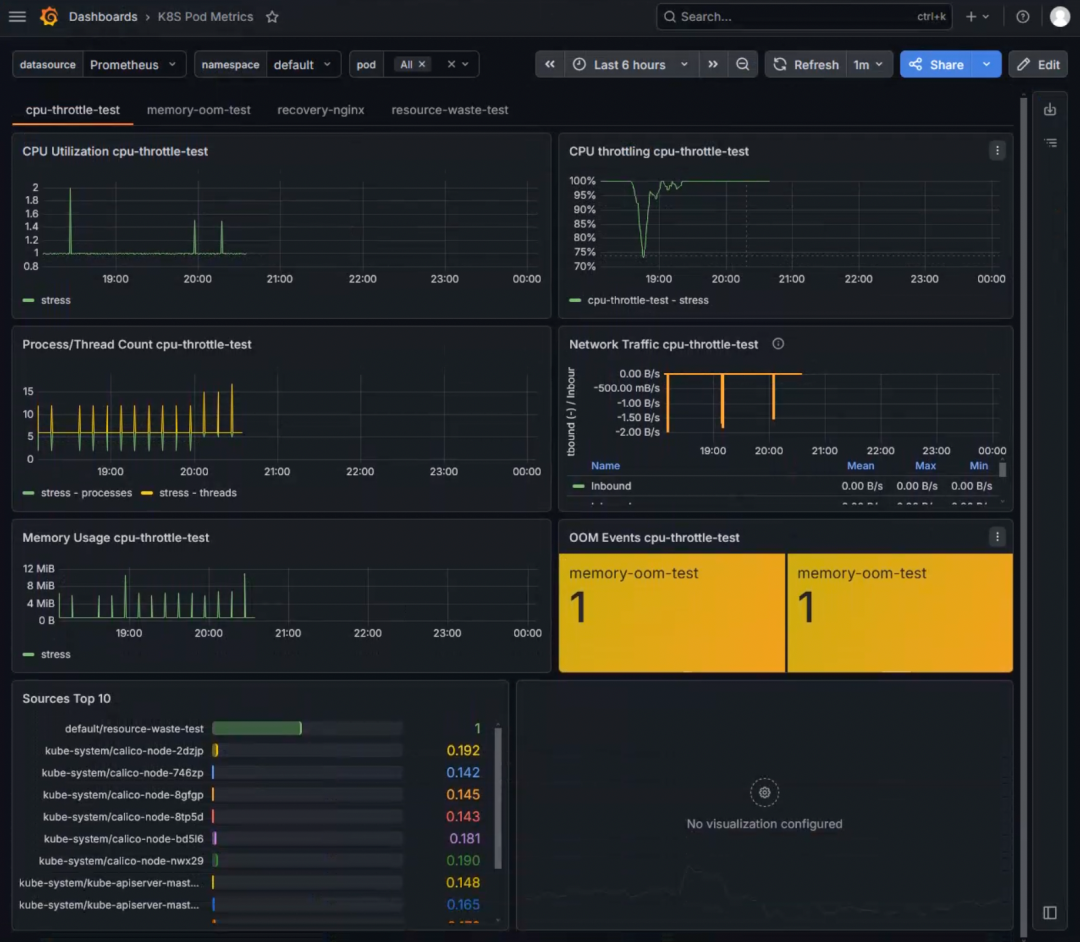
这个 Dashboard(K8S Pod Metrics)包含了 CPU Utilization、Memory Usage、CPU Throttling、OOM Events、Network Traffic 等多个面板,覆盖了我们需要的“高危区”监控场景。
✨ 第二步:配置筛选器查看目标 Pod
导入后,在 Dashboard 顶部可以通过筛选器查看特定命名空间或 Pod 的数据:
namespace下拉框:选择default,聚焦测试环境pod下拉框:选择All查看所有 Pod,或勾选cpu-throttle-test、memory-oom-test、resource-waste-test等特定 Pod 逐一对比
效果:筛选器切换后,所有面板会同步刷新,方便集中查看某一组 Pod 的资源状态。
🎨 第三步:补充“资源浪费”面板(可选)
社区 Dashboard 21584 默认不包含“资源浪费”类面板,如果你需要添加,可按以下步骤操作:
- 进入 Dashboard 编辑模式(右上角
Edit) - 点击
Add new element→ 选择Configure visualization - 在查询编辑器中粘贴以下 PromQL:
topk(10,
sum(kube_pod_container_resource_requests{resource="cpu"}) by (pod, namespace)
-
sum(rate(container_cpu_usage_seconds_total[5m])) by (pod, namespace)
)
- 可视化类型选择
Bar gauge或Table - Legend 填入
{{namespace}}/{{pod}} - 点击
Titile输入面板名称,然后保存 Dashboard
💾 第四步:保存仪表盘
所有面板配置完成后,点击右上角的 Save按钮即可。
写在最后
资源管理的本质,从来不是简单的“大一点好”或“省一点好”,而是在稳定性和成本之间找到那个最优的平衡点。
而找到这个平衡点的唯一途径,就是持续观察、持续优化、持续用数据驱动决策。
如果你在搭建看板的过程中遇到了什么问题,或者发现了更“离谱”的浪费大户,欢迎留言,一起吐槽、一起排坑。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号