05-DataProto-RL训练流水线里的集装箱

05-DataProto-RL训练流水线里的集装箱

anzhsoft
发布于 2026-07-01 21:08:35
发布于 2026-07-01 21:08:35
前四篇已经建立了这条主线:RLHF 不是一个训练脚本,而是一条训推闭环;HybridFlow 把它拆成高层 dataflow;single controller 保留阶段顺序;ResourcePool 和 WorkerGroup 把角色放到 GPU 集群上执行。这篇继续问一个更细的问题:这些角色之间到底传的是什么?
很多人会下意识回答“tensor batch”。这只说对了一半。后训练里的样本不仅有 input_ids、attention_mask,还会长出 response、reward、old logprob、ref logprob、value、advantage、return、uid、timing 和各种运行元信息。verl 用 DataProto把这批不断变胖的训练证据包成一个统一协议。
本文的核心判断是:DataProto 不是普通 dict,而是 controller、worker、rollout、reward、actor update 之间的数据契约。它让 PPO 主循环能清楚地写成 repeat -> union -> dispatch -> collect -> update,但也把字段增长、序列化、对象列和样本对齐风险集中到了一个协议边界上。
这张图先给出 DataProto 的三层结构。看图时重点看 batch 维度:tensor、object array 和 meta 信息都要围绕同一批样本对齐。
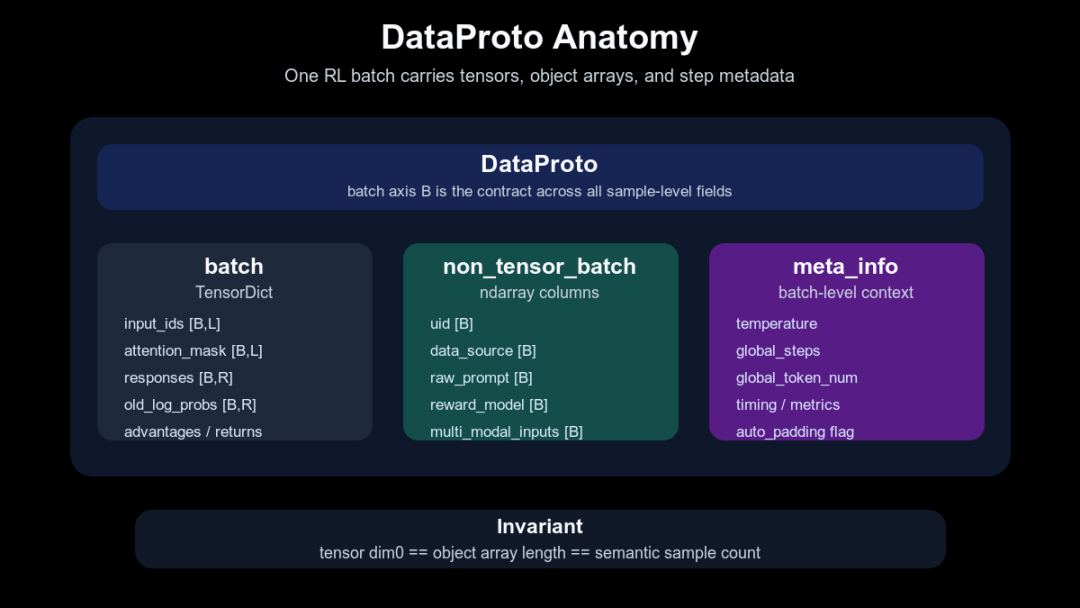
DataProto 的三层结构
源码里 DataProto是一个 dataclass,核心字段是 batch: TensorDict、non_tensor_batch: dict和 meta_info: dict(verl/protocol.py:317-328)。check_consistency()要求 batch只有一个 batch 维度,并要求 non_tensor_batch中每个 np.ndarray的第 0 维和 batch size 对齐(verl/protocol.py:454-478)。这就是 DataProto 最重要的隐含契约:不管字段来自 rollout、reward 还是 trainer,它们都必须描述同一批样本。
1. 三层结构分别解决三类数据
第一层 batch放 TensorDict,适合存 tensor 化、按样本对齐的数据:input_ids、attention_mask、responses、response_mask、old_log_probs、ref_log_prob、values、advantages、returns等。from_dict()会检查 tensor 的 batch 维是否一致,再构造成 TensorDict(verl/protocol.py:496-543)。
第二层 non_tensor_batch放按样本对齐但不适合 tensor 化的对象列。典型例子是 uid、raw prompt、data source、多模态对象、reward 额外信息、工具或环境相关字段。from_single_dict()会把 torch tensor 放进 batch,把 np.ndarray放进 non_tensor_batch(verl/protocol.py:479-493)。
第三层 meta_info放整批数据的控制信息和运行信息,例如 temperature、global step、global token number、timing、metrics、auto padding 标记。它不一定逐样本变化,但会影响后续阶段如何解释这批数据。
to_tensordict()进一步说明了这三层如何接回 worker 侧执行:tensor batch 先转成普通 dict,non-tensor 列会包装成 NonTensorStack,meta_info 会作为 non-tensor dict 合进 TensorDict(verl/protocol.py:1102-1126)。所以 DataProto 是 controller 侧协议,TensorDict 更像 worker 执行前的操作形态。
2. 一个 PPO batch 会在主循环里逐步长大
DataProto 只有放进 RayPPOTrainer.fit()才真正有意义。主循环开始时,dataloader 出来的 batch_dict被转成 DataProto.from_single_dict(batch_dict),然后写入 temperature,并给每条样本生成 uid(verl/trainer/ppo/ray_trainer.py:1330-1349)。
接下来 rollout 会让样本变多。trainer 先拿到 gen_batch,写入 global_steps,再按 rollout.n做 repeat();如果是 REMAX,还会把 sampled rollout 和 greedy baseline 拼成一个 combined batch(verl/trainer/ppo/ray_trainer.py:1351-1370)。生成完成后,主 batch 也会按 rollout.n repeat,再和 gen_batch_output做 union(),补上 responses 等新字段(verl/trainer/ppo/ray_trainer.py:1386-1407)。
下面这张图展示的是“batch 如何长大”,不是单个字段的来源。重点是:每个阶段都不是替换整批数据,而是在同一个 DataProto 语义空间里追加字段或更新 meta。
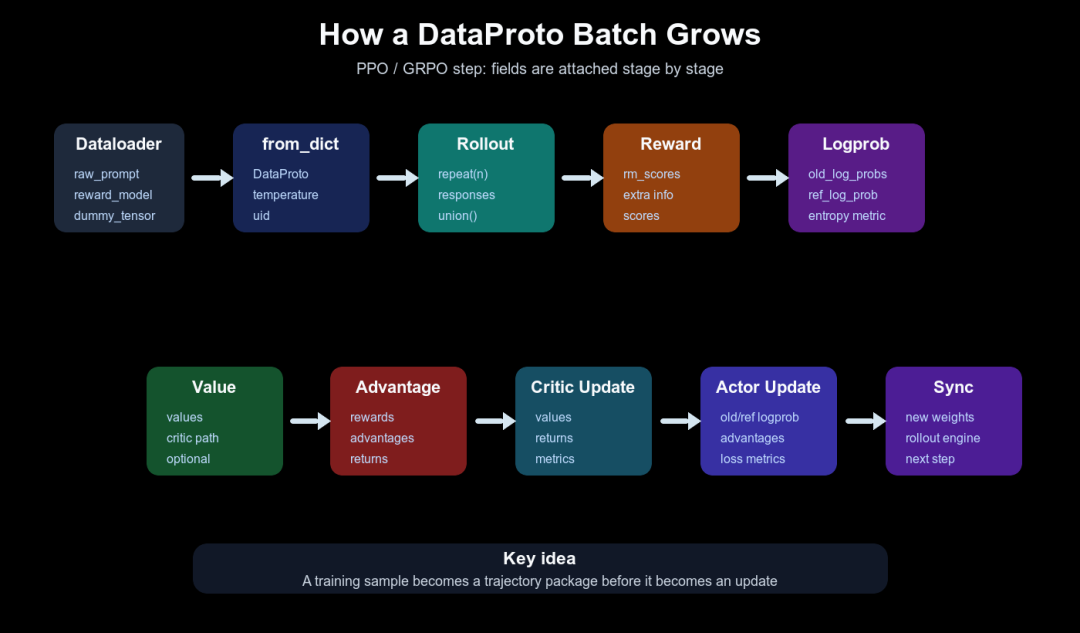
一个 DataProto batch 在 PPO/GRPO 主循环中逐步长大
生成之后,DataProto 继续变胖:reward 阶段可能 union()reward model 输出,old logprob 阶段 union()old_log_probs,reference 阶段 union()ref_log_prob,critic 阶段 union()values,advantage 阶段写入 token_level_scores、token_level_rewards、advantages、returns等字段(verl/trainer/ppo/ray_trainer.py:1426-1541)。最后 actor/critic update 消费的已经不是原始 batch,而是一批带完整训练证据的 DataProto。
这也解释了 uid为什么重要:一个 prompt 可能生成多条 response,样本顺序还可能被 balance 或 dispatch 改写。uid是后续 advantage、prefix grouping、诊断和样本追踪能继续认出“同一个原始 prompt”的关键列。
3. DataProto 的 API 是流水线操作,不是便利函数
union()是 PPO 主循环里最常见的合箱动作。它会分别合并 tensor batch、non_tensor_batch 和 meta_info;如果已有同名字段但内容不一致,就会触发一致性检查(verl/protocol.py:109-122,verl/protocol.py:188-199,verl/protocol.py:781-798)。这能防止不同阶段把同一个字段写成语义不一致的数据。
repeat()、slice()、select_idxs()、reorder()负责样本级变换,保证 tensor 列和 non-tensor 列一起变换(verl/protocol.py:635-719,verl/protocol.py:963-1013)。这点在 RLHF 里很实际:rollout.n 会扩展样本,batch balance 会重排样本,REMAX 会切出 baseline 区段,如果只处理 tensor 不处理对象列,样本语义就会错位。
chunk()和 concat()则直接服务于分布式边界。chunk()按 batch 维把 DataProto 切成 worker shard,并把 meta_info 传给每个 shard;concat()把多个 DataProto 沿 batch 维拼回,并对 metrics 做合并处理(verl/protocol.py:864-961)。这是 DataProto 能穿过 WorkerGroup 的基础。
4. 穿过 WorkerGroup 时,DataProto 必须可切、可合、可对齐
第三篇讲过,WorkerGroup 调用会经过 dispatch 和 collect。对 DataProto 来说,dispatch/collect 不只是传对象引用,而是要在 controller 和 workers 之间保持 batch 语义。
decorator.py里的 _split_args_kwargs_data_proto()会通过 BatchData(arg).chunk(chunks)切输入;带 auto padding 的版本会在 batch size 不能整除 worker 数时补齐样本,并把 padding size 放进 kwargs(verl/single_controller/base/decorator.py:71-117)。dispatch_dp_compute_data_proto()按 WorkerGroup world size 切分,collect_dp_compute_data_proto()再通过 BatchData(output).concat()合并输出(verl/single_controller/base/decorator.py:167-199)。
下面这张图要看的就是这个协议边界:controller 不只把一个对象发给 worker,而是先切成 shard;worker 返回后,collect 再合成一个 DataProto,PPO 主循环才能继续按完整 batch 往下走。
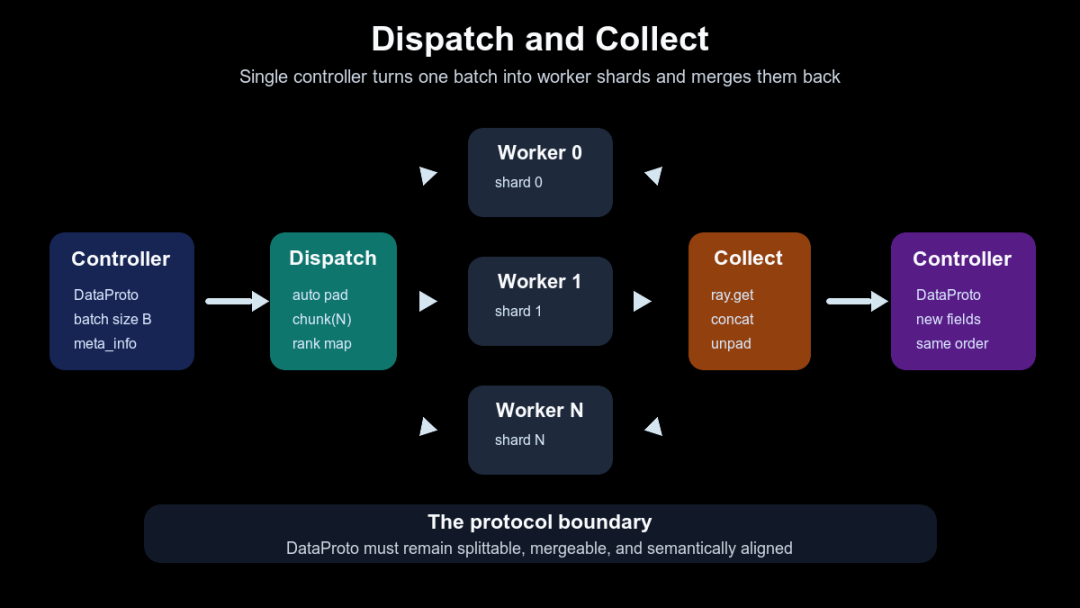
DataProto 如何在 controller 和 workers 之间切分与合并
当前训练 worker 常用的 ND dispatch 还会先查询 mesh 的 DP rank mapping,再按 DP 维度做分发和收集(verl/single_controller/base/decorator.py:202-304)。这说明 DataProto 的“集装箱”属性并不是比喻:它必须能被按 rank 拆箱、发货、收货、合箱,并且合回来后仍然保持样本对齐。
5. DataProto 的代价来自它越来越像系统总线
DataProto 让代码更清楚,但它不是免费抽象。
第一类成本是字段增长。一个 batch 从 prompt 出发,经过 rollout、reward、logprob、value、advantage 后,tensor 字段会越来越多,response length 又可能很长。print_size()专门统计 TensorDict 和 non_tensor_batch 的大小,说明这不是纯粹的语义问题(verl/protocol.py:436-452)。
第二类成本是序列化。__getstate__()默认会把 TensorDict consolidate 后通过 torch.save写入 buffer,也支持通过环境变量切换到 numpy 序列化(verl/protocol.py:377-424)。当 DataProto 频繁跨 Ray object store 或 controller/worker 边界时,序列化和反序列化会变成真实系统成本。
第三类成本是对象列和对齐风险。non_tensor_batch里可能有 raw prompt、多模态对象、工具参数、reward 诊断信息。这些字段很难像 tensor 那样被高效移动,但又必须跟样本第 0 维严格对齐。DataProto 的一致性检查能抓住一部分错误,但系统设计仍然要避免把过重对象长期挂在主 batch 上。
下面这张图把这些代价放在一起。它补充的是:DataProto 解决了“数据语义统一”的问题,但也可能成为 controller 内存、Ray object store 和字段对齐的压力点。
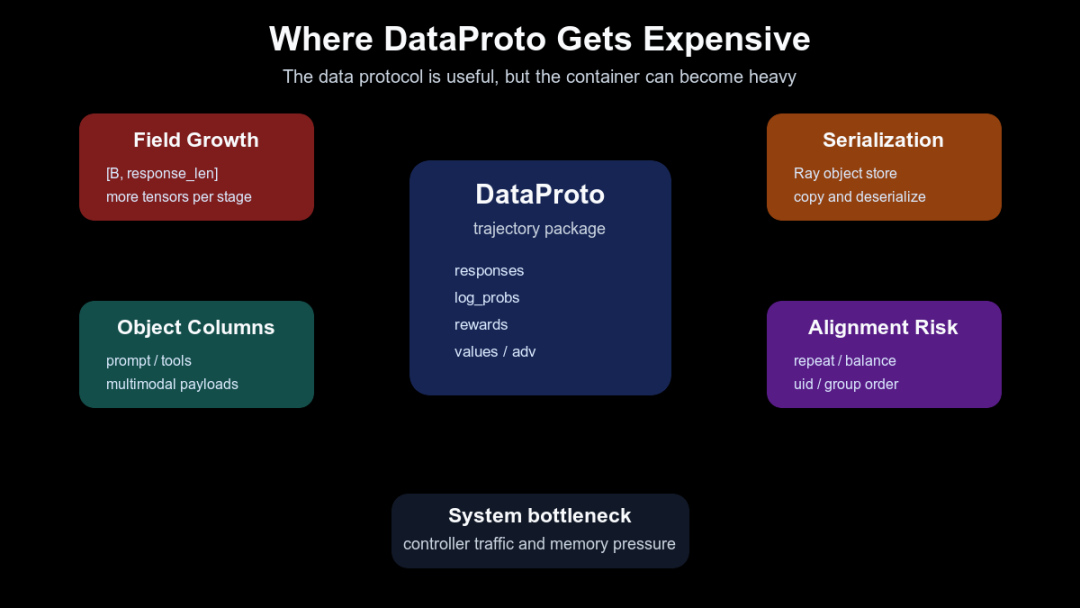
DataProto 的主要系统压力点
因此,优化 RLHF 数据流不能只问“这批 tensor 多大”。更完整的问题是:哪些字段必须留在主 DataProto 里,哪些可以只在某个阶段临时存在,哪些对象列应该提前压缩或延迟加载,哪些 metric 应该只回传摘要。DataProto 让这些问题有了统一落点。
小结:DataProto 是后训练系统的数据契约
到这里,第一组的第 2-5 篇可以连起来看:
HybridFlow 解释阶段
Single Controller 保留阶段顺序
ResourcePool / WorkerGroup 放置执行角色
DataProto 在角色之间搬运训练证据
DataProto 的价值是把不断变化的 RL batch 变成统一协议:tensor 字段、对象列和 meta 信息都围绕同一批样本流动。它的代价也来自这里:字段会增长,对象列会变重,dispatch/collect 必须保持可切分和可合并,controller 边界会承担序列化和聚合压力。
下一篇可以回到 PPO/GRPO step 本身:现在我们已经知道控制流在哪里、worker 放在哪里、数据怎么流动,就可以按 fit()逐段解释一轮 step 里每个阶段到底消费和产出什么。
本文源码索引
verl/protocol.py:317-328:DataProto的三层字段定义。verl/protocol.py:454-478:batch 与 non-tensor 列的一致性检查。verl/protocol.py:479-543:from_single_dict()和from_dict()如何构造 DataProto。verl/protocol.py:781-798:union()如何合并不同阶段产出的字段。verl/protocol.py:864-961:chunk()和concat()如何支撑分布式切分与合并。verl/protocol.py:971-1013:repeat()如何复制 batch 和 non-tensor 列。verl/protocol.py:1102-1126:to_tensordict()如何把 DataProto 转成 worker 可执行形态。verl/trainer/ppo/ray_trainer.py:1330-1407:PPO 主循环如何从 dataloader batch 变成 rollout 后的 DataProto。verl/trainer/ppo/ray_trainer.py:1426-1541:reward、logprob、value、advantage 如何继续给 batch 追加字段。verl/single_controller/base/decorator.py:71-117:DataProto dispatch 前的切分和 auto padding。verl/single_controller/base/decorator.py:167-199:DP DataProto dispatch/collect。verl/single_controller/base/decorator.py:202-304:ND mesh 下的 DataProto dispatch/collect。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号