10-KL-clip-entropy给模型更新装限速器

10-KL-clip-entropy给模型更新装限速器

anzhsoft
发布于 2026-07-01 21:09:48
发布于 2026-07-01 21:09:48
上一篇写 DAPO、Dr. GRPO 和长度偏置,说明 reward、advantage 和 loss 聚合会把 response 长度变成训练变量。这一篇继续问:当 reward 和 advantage 已经在推动 actor 更新时,系统靠什么防止一步更新跑得太远?
本文的核心判断是:KL、clip、entropy 是三类不同位置的限速器。reward-side KL 改写 token_level_rewards,PPO clip 限制 policy ratio 对 advantage 的放大,entropy 和 actor KL loss 则在 actor loss 上做正则。它们都服务稳定性,但源码合同不同,不能混成一个“惩罚项”。
先看总图。读这张图时重点看三条橙色路径:它们分别接入 reward、policy loss 和 actor loss,不是在同一个位置做同一件事。
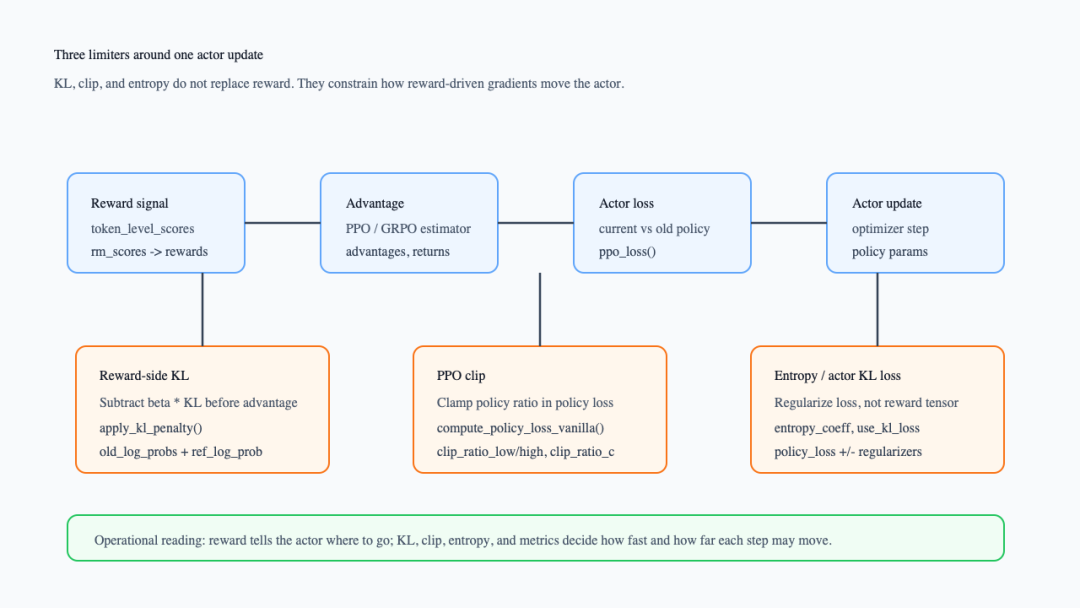
KL、clip、entropy 在 actor update 周围的位置
这张图对应 RayPPOTrainer.fit()的顺序:先拿到 reward tensor,再重算 old_log_probs,必要时计算 ref_log_prob,然后写入 token_level_rewards,最后进入 advantage 和 actor update(verl/trainer/ppo/ray_trainer.py:1426-1511)。限速器的位置决定了它改变的是 reward、advantage 之前的输入,还是 actor loss 本身。
1. KL 有两个位置:reward 里和 actor loss 里
第一种位置是 in-reward KL。apply_kl_penalty()读取response_mask、token_level_scores、old_log_probs和ref_log_prob,用core_algos.kl_penalty()计算 token 级 KL,再做token_level_scores - beta * kld,写回token_level_rewards;同时更新 KL controller 并记录actor/reward_kl_penalty和系数(verl/trainer/ppo/ray_trainer.py:75-114)。在fit()里,这一步只在algorithm.use_kl_in_reward为真时发生,否则token_level_rewards直接等于token_level_scores(verl/trainer/ppo/ray_trainer.py:1504-1511)。
第二种位置是 actor KL loss。ppo_loss()先用当前 actor forward 的 log_prob、batch 里的 old_log_probs、advantages和 response_mask计算 policy loss;如果 config.use_kl_loss为真,它会读取 ref_log_prob,再把 kl_loss * kl_loss_coef加进 policy_loss(verl/workers/utils/losses.py:57-144)。
下面这张图把两个 KL 位置分开。看图时不要只看都用了 ref_log_prob,而要看它们写回的目标不同:一个写 reward,一个写 loss。
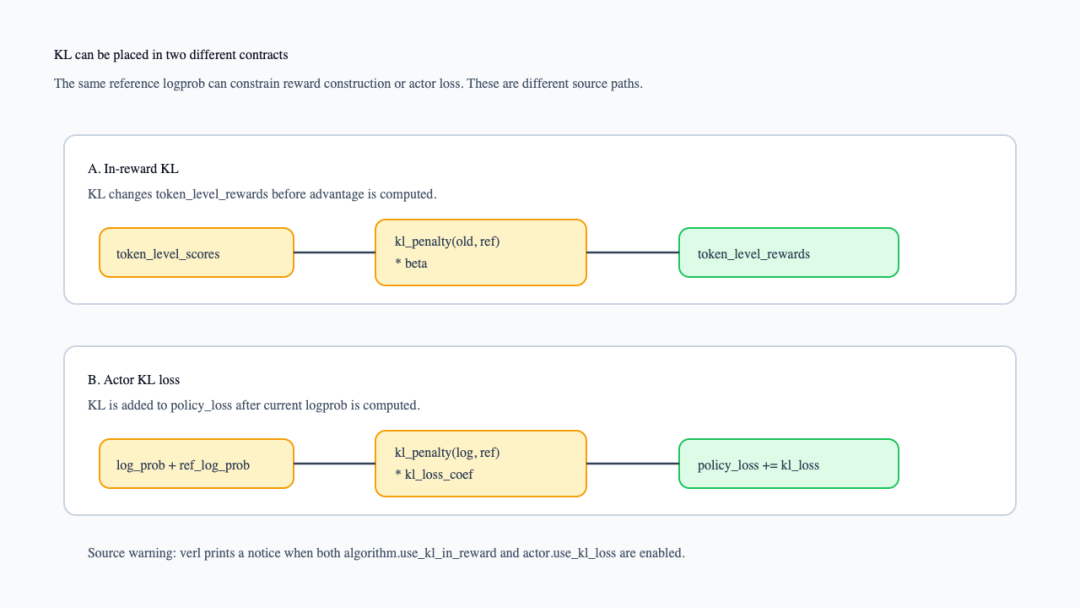
KL 的两个接入位置
源码上的边界也很明确。_compute_ref_log_prob()会从 reference policy 或 actor-without-LoRA 路径拿到 ref_log_prob(verl/trainer/ppo/ray_trainer.py:1144-1166)。_compute_old_log_prob()则从 actor rollout worker 拿到 old_log_probs和 entropy,用作 PPO ratio 的近端锚点(verl/trainer/ppo/ray_trainer.py:1168-1203)。配置层也提醒,如果同时打开 in-reward KL 和 actor KL loss,会打印 notice(verl/utils/config.py:169-170)。这不是说永远不能同时打开,而是说明读配置时必须知道自己开了两个不同位置的约束。
2. clip 限的是 policy ratio,不是 reward 分数
PPO clip 发生在 policy loss 里。compute_policy_loss_vanilla()先取 clip_ratio、clip_ratio_low、clip_ratio_high和 clip_ratio_c,再用 exp(log_prob - old_log_prob)得到 ratio。随后它把 ratio clamp 到 [1 - low, 1 + high],并在 advantage 为负且 ratio 过大时走 dual-clip 路径;最后输出 pg_loss、actor/pg_clipfrac、actor/ppo_kl和 actor/pg_clipfrac_lower(verl/trainer/ppo/core_algos.py:1279-1370)。
这张图补的是 clip 的字段合同。它说明 clip 不是 reward manager 的事,而是 actor 当前 logprob 与 old logprob 之间的更新幅度控制。
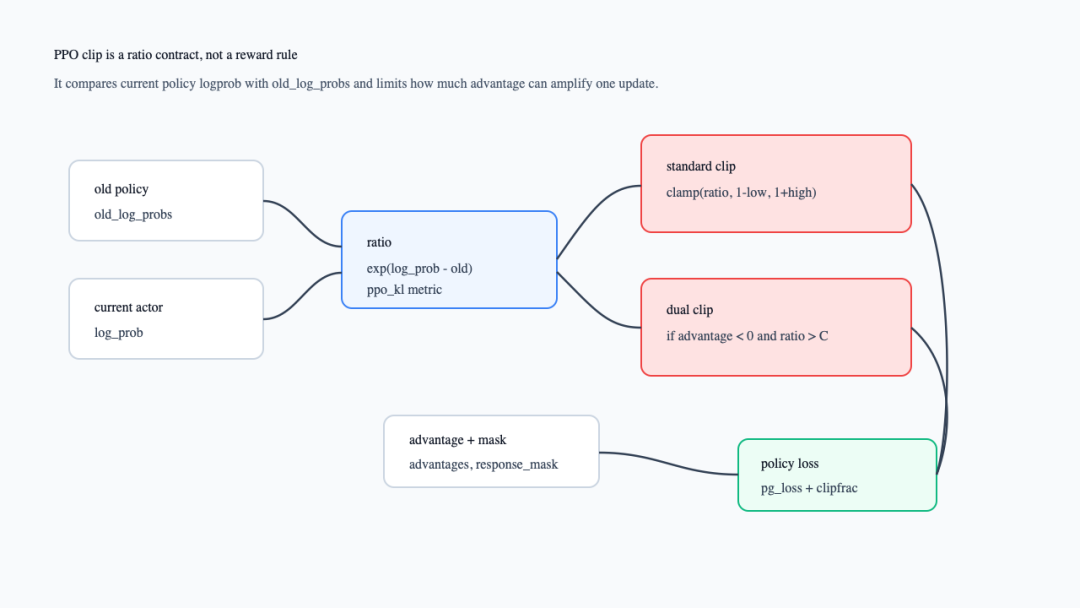
PPO clip 的 ratio 合同
actor 配置把这些旋钮显式暴露出来:默认 clip_ratio、clip_ratio_low、clip_ratio_high都是 0.2,clip_ratio_c默认为 3.0,loss_agg_mode也是 actor 配置的一等字段(verl/trainer/config/actor/actor.yaml:35-42,verl/trainer/config/actor/actor.yaml:78-82)。所以改 clip 不会改变 reward 本身,但会改变同一组 advantage 在 actor update 中被允许放大的范围。
3. entropy 是 actor loss 的探索正则,也是监控信号
entropy 的位置又不同。ppo_loss()如果拿到了 model output 里的 entropy,会对它做 agg_loss(),再执行 policy_loss -= entropy_coeff * entropy_loss,并记录 actor/entropy_loss(verl/workers/utils/losses.py:122-129)。旧接口里的 compute_entropy_loss()也说明 entropy 是从 logits 得到 token entropy,再按 response mask 聚合(verl/trainer/ppo/core_algos.py:2067-2081)。
下面这张图把 entropy 和指标放在一起。它要表达的是:稳定性不只靠一个 loss 值判断,而要看 KL、clip fraction、entropy 和 reward 指标是否一致。
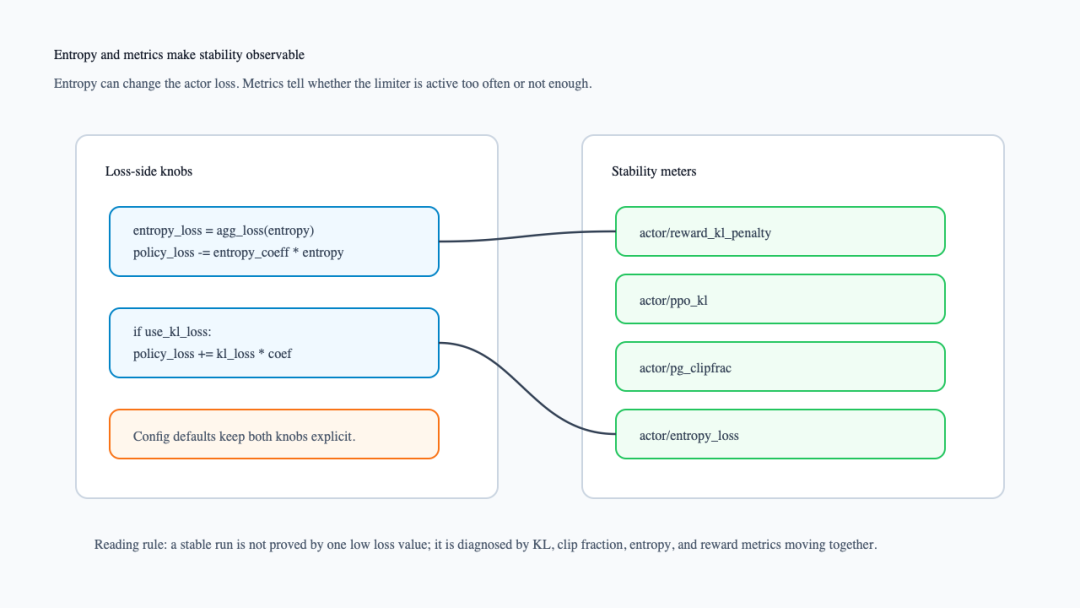
entropy 与稳定性指标面板
配置上,entropy_coeff默认是 0,calculate_entropy默认是 false;actor KL loss 也默认关闭,并有 kl_loss_coef和 kl_loss_type两个参数(verl/trainer/config/actor/actor.yaml:88-112)。这说明 entropy 和 actor KL loss 都是显式选择的训练约束。工程解释是:当模型更新过于保守、过于激进或过早坍缩时,单看 reward 往往不够,必须把 actor/ppo_kl、actor/pg_clipfrac、actor/reward_kl_penalty和 entropy 类指标一起看。
4. 三个限速器解决的是不同失控方式
reward-side KL 解决的是“actor 偏离 reference 后,reward 还是否可信”的问题。它在 advantage 之前生效,因此会改变后续 estimator 看到的 token reward。
clip 解决的是“同一批 advantage 会不会把 actor 推太远”的问题。它不需要知道 reward 怎么来的,只关心当前 actor 相对 old policy 的 ratio。
entropy 解决的是“actor 分布会不会过快收窄”的问题。它和 actor KL loss 一样,都在 actor loss 侧改变优化目标。
把这三件事分开,读配置才不会误判。例如 algorithm.use_kl_in_reward=True和 actor.use_kl_loss=True都需要 reference logprob,但一个改变 reward,一个改变 loss;clip_ratio再小,也不会修复 reward manager 的数据错误;entropy_coeff再大,也不能替代 group-relative advantage 或 value baseline。
小结:稳定性来自分层约束,不来自单个公式
第二组前几篇已经把 actor、critic、GRPO、DAPO 和长度偏置拆开了。这一篇补上更新稳定性:
reward / advantage 推动 actor 更新
-> reward-side KL 控制偏离 reference 后的 reward
-> PPO clip 控制 policy ratio
-> entropy / actor KL loss 调整 actor loss
-> metrics 判断限速器是否真的在工作
下一篇继续写 reward。因为当我们说 KL 和 clip 在限制 reward 驱动的更新时,还必须回答一个更基础的问题:reward 本身到底是怎么被系统算出来的,它为什么不只是一个 score(response)函数。
本文源码索引
verl/trainer/ppo/ray_trainer.py:75-114:apply_kl_penalty()如何把 KL 从token_level_scores中扣掉并写入token_level_rewards。verl/trainer/ppo/ray_trainer.py:1144-1166:reference logprob 的计算路径。verl/trainer/ppo/ray_trainer.py:1168-1203:old logprob 和 entropy 的计算路径。verl/trainer/ppo/ray_trainer.py:1426-1511:reward、old/ref logprob、KL reward penalty 在fit()中的顺序。verl/workers/utils/losses.py:57-144:actorppo_loss()如何接入 policy loss、entropy 和 actor KL loss。verl/trainer/ppo/core_algos.py:1279-1370:PPO ratio、clip、dual clip 和相关指标。verl/trainer/ppo/core_algos.py:2067-2081:entropy loss 的 token 聚合。verl/trainer/ppo/core_algos.py:2126-2168:KL penalty 的实现入口。verl/trainer/config/actor/actor.yaml:35-42:actor clip ratio 配置。verl/trainer/config/actor/actor.yaml:78-112:dual clip、loss aggregation、entropy 和 actor KL loss 配置。verl/utils/config.py:169-170:同时打开 in-reward KL 与 actor KL loss 时的 notice。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号