业务稳定造就大模型的降本增效?Claude 核心能力拆解(一)

业务稳定造就大模型的降本增效?Claude 核心能力拆解(一)

用户12057812
发布于 2026-07-01 21:23:40
发布于 2026-07-01 21:23:40
Claude 在陆续推出Skills、Cowork等产品功能后,国内外厂商快速对标。功能可以抄,但我认为Claude已经基于其扎实的底层能力建设,构建了一条能快速实现好用新功能的流水线,这是Claude背后的核心竞争力。
我计划用一个系列,系统拆解 Claude 官方披露的一些核心能力,为企业AI转型提供可参考的体系架构,帮助业务和数字化部门了解需要提前做好准备的工作。
第一篇我们从提示词缓存(Prompt Caching)开始。
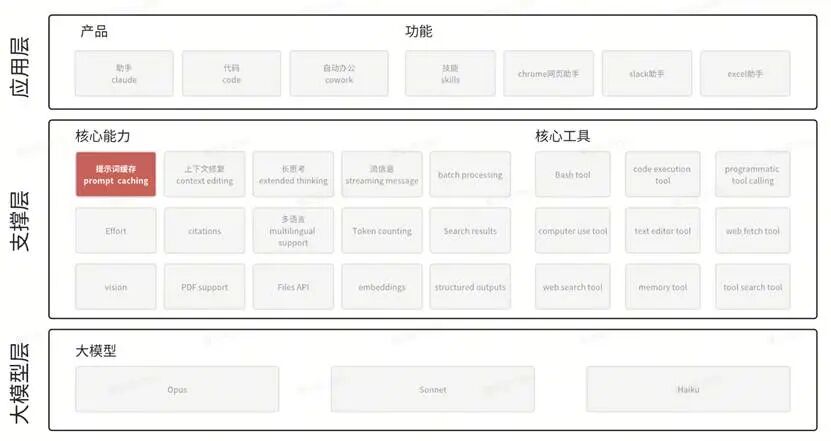
图形用户界面AI 生成的内容可能不正确。
一、提示词缓存解决的是什么问题
在大多数企业 AI 应用中,真正消耗资源的,并不是模型生成那几句话,而是模型在每一次调用中,都要重新“读懂”一整套业务背景。
这些背景往往高度重复:业务规则、流程说明、角色定义、判断标准几乎不变,真正变化的只是当前输入的少量业务数据。提示词缓存的核心价值在于避免模型在每一次请求中,重复完成同一件“理解背景”的工作。
有意思的是,虽然能力名叫提示词缓存,像是把提示词放进了缓存,但其实背后存储的并不是提示词本身。
我们可以把企业内的AI对话分为三个步骤:阅读题干 > 理解题干 > 回答题目。Claude发现,最昂贵和耗时最长的是理解题干的阶段:模型逐层构建上下文、形成判断基础的过程。在使用过程中,我们需要在提示词中设置缓存断点(cache breakpoint),系统将把模型在理解完这段稳定提示词后后形成的内部认知状态放入缓存使用。一旦这一步可以被复用,后续每次调用的成本和时延都会显著下降。
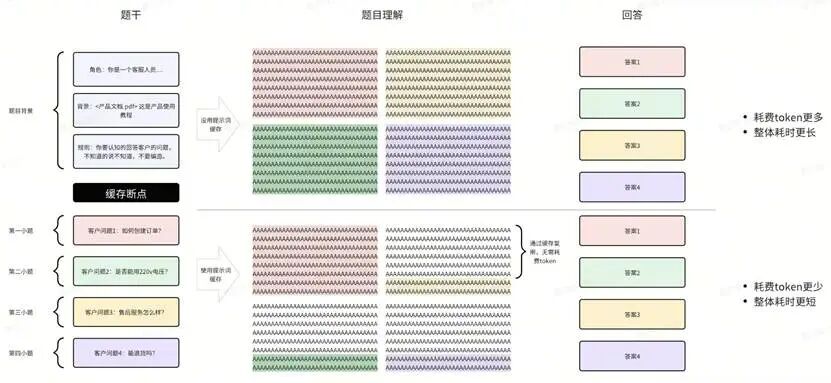
文本AI 生成的内容可能不正确。
二、提示词缓存是业务理解的显性化
抛开技术实现,提示词缓存背后是对业务内容稳定性的明确判断。
当IT团队开始思考哪些提示词和上下文值得设置为缓存断点时,真正被审视的是业务问题:哪些业务规则在可预见周期内不会频繁变化,哪些流程已经成为组织层面的共识,哪些判断逻辑不应该被每一个 AI 应用各自实现一遍等等。
从这个角度看,提示词缓存表面上是在做推理优化,实际上是在推动企业把长期依赖经验和隐性共识的业务理解,转化为可被 AI 使用的显性结构。
三、如何为未来少走弯路提前做好准备?
对业务而言,需要思考推动业务规则和判断逻辑的显性化与稳定化。如果规则本身长期处于模糊、口头化、依赖个人经验的状态,那么无论模型能力如何演进,AI 应用都很难从零散试点走向可复制、可规模化。
对AI架构而言,意味着提示词不应被视为前端交互的一部分,而应被纳入整体 AI 架构的设计范围之内,具备版本管理、复用机制和治理边界。否则,当 AI 应用数量逐步增加时,Prompt 本身很可能成为新的“隐形耦合点”,反而拖累整体演进。
提示词缓存只是技术实现,但他的存在为企业指向了一个清晰的方向:真正可规模化的 AI,一定建立在“不需要反复理解同一个业务世界”的基础之上。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号