Claude Opus 4.6「百万上下文」全量上线:价格不涨反降,但真正的杀手锏根本不是1M窗口!

Claude Opus 4.6「百万上下文」全量上线:价格不涨反降,但真正的杀手锏根本不是1M窗口!

用户1640761
发布于 2026-07-01 21:52:38
发布于 2026-07-01 21:52:38
图像
大家好,我是"不一样的猿生"。最近,Claude官方在X上一条帖子直接炸了圈:1百万上下文窗口正式全量上线,Opus 4.6和Sonnet 4.6直接标配,再也不用额外付费或加 beta header了!
这条消息一出,国内外开发者瞬间刷屏。有人直接截图说“GPT-4o长上下文直接跪了”,有人感慨“整个代码库塞进一个prompt的时代终于来了”。
但如果你只盯着“1M”这三个数字,那你就错过真正的大招了。
先说清楚官方放了什么“大招”
- • 上下文窗口:Opus 4.6 & Sonnet 4.6 全量1M tokens(约75万汉字、2000页PDF)
- • 定价:标准定价,无长上下文溢价!Opus 4.6还是25 per million tokens,Sonnet 4.6 15。以前长上下文要加钱,现在直接砍半(甚至更低)
- • 媒体上限暴增6倍:一张prompt最多塞600张图片或PDF页面(之前只有100)
- • 全平台可用:Claude Platform、Amazon Bedrock、Google Vertex AI、Microsoft Azure Foundry全支持
- • Claude Code默认1M:Max/Team/Enterprise用户直接开启,再也不用担心会话被压缩
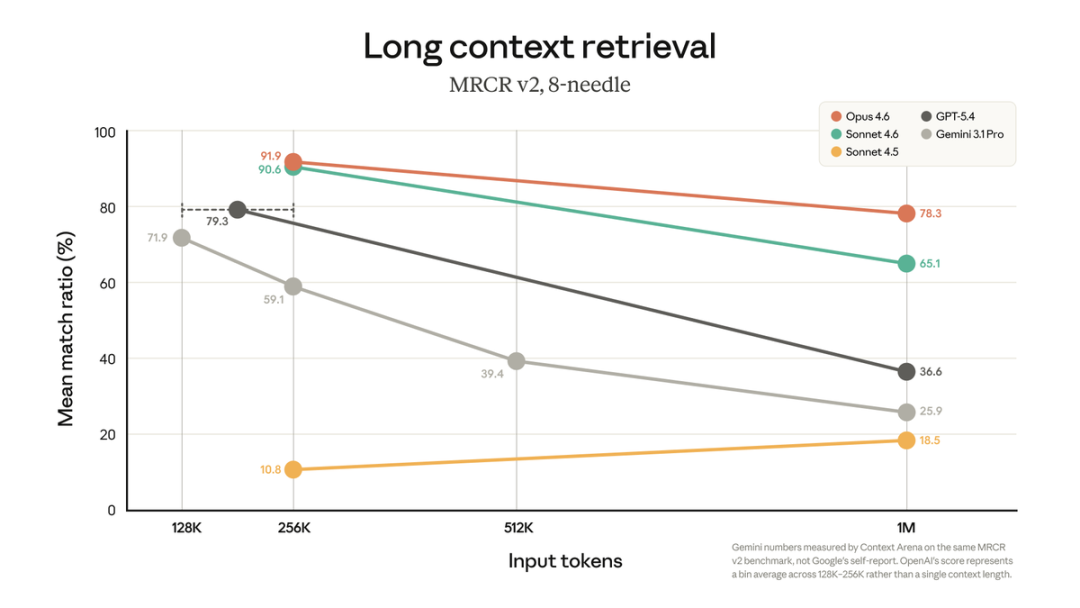
最硬核的数据来了:Opus 4.6在MRCR v2(百万上下文检索基准)上拿下78.3%,是目前所有前沿模型里最高的!
(官方X附的基准图表看得人热血沸腾:其他模型到1M时recall直接崩盘到30-40%,Claude几乎持平短上下文表现)
价格砍半只是开胃菜,真正的杀手锏在这里
很多人看到“1M”就高潮了,以为这就是王炸。
错!
真正让Claude这次把竞品甩开三条街的,是**“长上下文居然还能记得住、算得准”**。
以前的“长上下文”是什么样子?
- • GPT-4o:128K一到就忘前文,700页合同你得切成20段,中间还得自己写总结逻辑
- • 很多模型:token数吹得天花乱坠,实际recall一拉长就雪崩
Claude这次直接告诉你: 我不仅能塞下整个代码库、整个项目历史、整个Agent轨迹,我还能在1M位置精准把第17页的那个bug找出来,并且给出完整修复方案。
这才是开发者梦寐以求的:
- • 把整个Git仓库一次性丢进去,问“这个模块和3个月前的重构冲突在哪里”
- • 把700页法务合同全塞进去,问“第12条和第489条是否存在逻辑矛盾”
- • 把长达数小时的Agent运行日志全丢进去,让它自己总结哪里决策失误
以前你得写一堆RAG、分chunk、summarization、向量检索…… 现在?一个prompt就够了。
这对普通开发者意味着什么?
- 1. 代码审计效率起飞:以前审10万行代码要分10次,现在一次搞定
- 2. Agent真正“长记忆”:不再需要每隔几步就清上下文,连续运行几天都没问题
- 3. 多模态文档处理爆炸:600页PDF+图片直接吃,财报、专利、设计稿一次性分析
- 4. 成本直线下降:没有溢价 + 更少的prompt工程 = 真金白银省钱
写在最后
Claude这次的“百万上下文”GA,不仅仅是把数字从200K提到1M,而是把长上下文从“营销噱头”变成了“生产力武器”。
价格砍半只是甜头,真正杀人于无形的,是那个78.3%的recall + 零改动接入 + 6倍媒体容量。
当别人还在为“怎么把上下文切开”头疼的时候,Claude的用户已经开始把整个项目塞进一个对话框了。
你准备好拥抱这个新纪元了吗?
欢迎在评论区说说:
- • 你最想用1M上下文干啥?
- • 你觉得Claude这次会把GPT甩多远?
点赞+转发+关注"不一样的猿生"!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号